AdaCtrl:自适应可控Reasoning,可降10~90%推理长度!!
摘要:现代大型推理模型通过运用复杂的推理策略展示了令人印象深刻的解决问题能力。然而,它们常常难以平衡效率和有效性,经常为简单问题生成不必要的冗长推理链。在本研究中,我们提出了AdaCtrl,这是一个新颖的框架,支持基于难度感知的自适应推理预算分配以及用户对推理深度的显式控制。AdaCtrl根据自我评估的问题难度动态调整推理长度,同时允许用户手动控制预算,以优先考虑效率或有效性。这是通过一个两阶段训练流程实现的:首先是一个冷启动微调阶段,以培养模型自我感知难度和调整推理预算的能力,随后是一个基于难度感知的强化学习(Reinforcement Learning, RL)阶段,该阶段根据模型在在线训练过程中不断发展的能力来完善其自适应推理策略,并校准其难度评估。为了实现直观的用户交互,我们设计了显式的长度触发标签,作为预算控制的自然接口。实证结果表明,AdaCtrl能够根据估计的难度调整推理长度。与同样包含微调和强化学习的标准训练基线相比,它在需要复杂推理的更具挑战性的AIME2024和AIME2025数据集上实现了性能提升,同时分别将响应长度减少了10.06%和12.14%;在只需要更简洁回答的MATH500和GSM8K数据集上,响应长度分别减少了62.05%和91.04%。此外,AdaCtrl还能够实现对推理预算的精确用户控制,从而提供满足特定需求的定制化回答。进一步的分析还揭示了AdaCtrl能够准确估计问题难度,并根据这些评估分配推理预算。
本文目录
一、背景动机
二、核心贡献
三、实现方法
3.1 长度触发标签
3.2 冷启动微调
3.3 基于难度感知的强化学习
3.4 推理阶段
四、实验结论
4.1 性能和效率提升
4.2 AdaCtrl 的可控性
4.3 难度估计准确性
五、总结
一、背景动机
论文题目:https://arxiv.org/pdf/2505.18822
论文地址:https://arxiv.org/pdf/2505.18822
现有推理模型(如 DeepSeek R1 和 OpenAI O1)在解决复杂问题时表现出色,但它们通常在简单问题上也会生成冗长的推理链,导致不必要的计算开销和延迟。尽管已有研究通过监督微调(SFT)和强化学习(RL)来优化推理效率,但这些方法大多只关注减少推理长度,而没有动态调整推理深度的能力,也无法让用户根据具体需求控制推理预算。
该文章提出了一种新的自适应和可控的推理框架AdaCtrl ,通过动态调整推理预算来平衡效率和效果。它通过两阶段训练流程使模型能够根据问题难度自适应调整推理长度,并通过长度触发标签为用户提供显式的推理预算控制。
二、核心贡献
- AdaCtrl 框架:提出了一种新的框架,支持基于问题难度的自适应推理预算分配和用户对推理深度的显式控制。
- 两阶段训练流程:设计了一个包含冷启动微调和基于难度感知的强化学习的两阶段训练流程,使模型能够根据自身能力评估问题难度,并据此调整推理预算。
- 长度触发标签:引入了“[Easy]”和“[Hard]”两种长度触发标签,作为用户控制推理预算的自然接口。
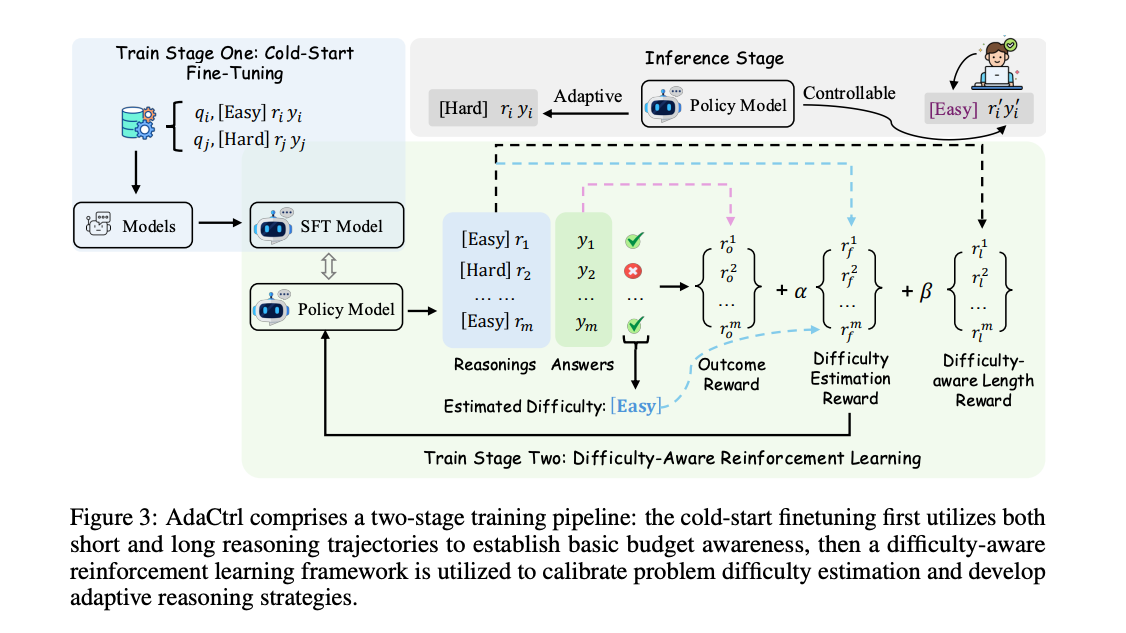
三、实现方法
3.1 长度触发标签
AdaCtrl 引入了两种特殊的长度触发标签:“[Easy]”和“[Hard]”,作为控制推理预算的接口。
-
[Easy]:指示模型生成简短的推理过程,适用于简单问题。
-
[Hard]:指示模型生成详细的推理过程,适用于复杂问题。
-
使用方式:在生成响应时,模型会根据问题的难度估计或用户指定的标签来选择合适的推理长度。用户可以通过在输入中添加这些标签来显式控制推理预算。
3.2 冷启动微调
冷启动微调阶段的目标是为模型提供初始能力,使其能够根据问题难度生成相应长度的推理轨迹。
-
数据准备
-
从 DeepMATH 数据集中选择简单问题(难度等级 ≤ 5)和复杂问题(难度等级 > 5)。
-
对于简单问题,使用 Qwen2.5-7B-Instruct 模型生成简短的推理轨迹。
-
对于复杂问题,使用强大的推理模型(如 Deepseek R1)生成详细的推理轨迹。
-
筛选出正确答案的推理轨迹,分别标记为“[Easy]”和“[Hard]”。
-
-
训练过程
-
使用上述数据对模型进行监督微调(SFT),使模型能够根据长度触发标签生成相应长度的推理轨迹。
-
这一阶段的目标是让模型学会在简单问题上生成简短的推理,在复杂问题上生成详细的推理。
-
3.3 基于难度感知的奖励设计
-
结果准确性奖励(Outcome Accuracy Reward):评估生成响应的正确性。如果生成的答案正确,则奖励为 +1.0;否则为 -1.0。
-
难度估计校准奖励(Difficulty Estimation Calibration Reward):通过多个 rollout 的准确性来校准模型对问题难度的估计。如果模型的 rollout 准确性超过预设阈值 δ,则将问题标记为“简单”;否则标记为“复杂”。奖励根据模型生成的长度触发标签与实际难度标签的一致性来计算。
-
基于难度的长度奖励(Difficulty-Aware Length Reward):鼓励模型在简单问题上生成更短的响应,而在复杂问题上保持较长的推理链。对于标记为“[Easy]”的问题,奖励随着生成长度的增加而减少。
3.4 推理阶段
在推理阶段,AdaCtrl 支持三种模式
-
自适应模式(Adaptive Mode):模型根据自身对问题难度的估计自动选择推理长度。
-
简单模式(Easy Mode):用户指定“[Easy]”标签,模型生成简短的推理过程。
-
复杂模式(Hard Mode):用户指定“[Hard]”标签,模型生成详细的推理过程。
四、实验结论
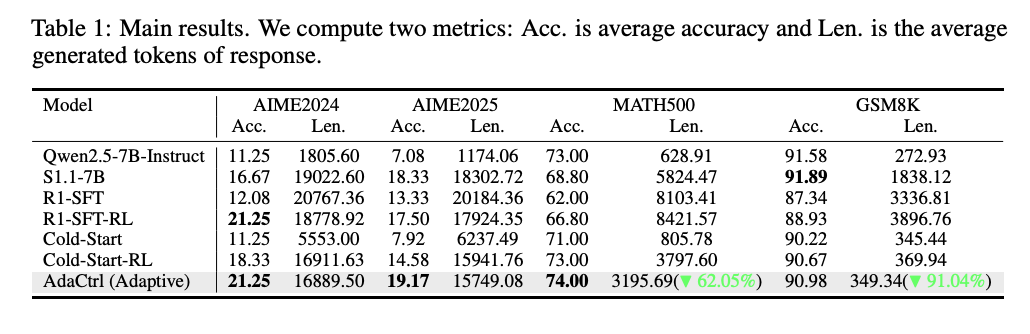
4.1 性能和效率提升
-
性能提升
-
AdaCtrl 在 AIME2025 数据集上性能提升了 1.67%,在 MATH500 数据集上提升了 7.20%,在 GSM8K 数据集上提升了 2.05%。
-
与标准 SFT + RL 基线相比,AdaCtrl 在 AIME2024 数据集上性能相当,但在其他数据集上均有所提升。
-
-
响应长度减少
-
在 AIME2024 和 AIME2025 数据集上,AdaCtrl 的响应长度分别减少了 10.06% 和 12.14%。
-
在 MATH500 和 GSM8K 数据集上,响应长度分别减少了 62.05% 和 91.04%。
-
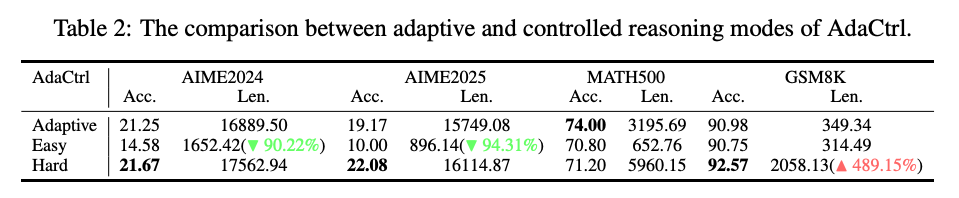
4.2 AdaCtrl 的可控性
-
通过“[Easy]”和“[Hard]”标签,用户可以显式控制推理预算。
-
在“[Easy]”模式下,AdaCtrl 在 AIME2024 和 AIME2025 数据集上的响应长度分别减少了 90.22% 和 94.31%。
-
在“[Hard]”模式下,AdaCtrl 在 MATH500 和 GSM8K 数据集上的响应长度分别增加了 86.51% 和 489.15%。
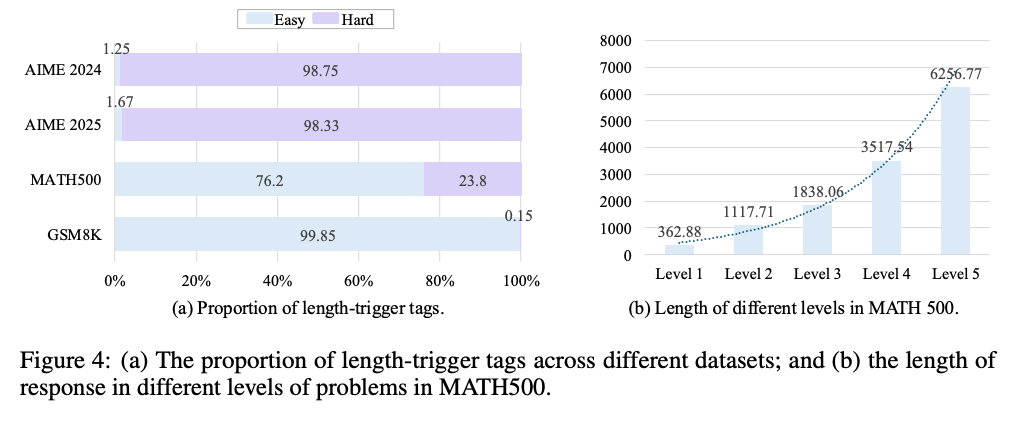
4.3 难度估计准确性
AdaCtrl 在不同数据集上的长度触发标签分布与数据集的实际难度一致。
-
在 AIME2024 和 AIME2025 数据集中,大部分问题被标记为“[Hard]”。
-
在 MATH500 数据集中,76.2% 的问题被标记为“[Easy]”。
-
在 GSM8K 数据集中,超过 99% 的问题被标记为“[Easy]”。
五、总结
AdaCtrl 提出了一种新的自适应和可控的推理框架,通过动态调整推理预算来平衡效率和效果。它通过两阶段训练流程使模型能够根据问题难度自适应调整推理长度,并通过长度触发标签为用户提供显式的推理预算控制。实验结果表明,AdaCtrl 在多个基准数据集上均表现出色,能够显著减少响应长度,同时保持或提升性能。