理解解释器架构:原理、组成与运行机制全解析
目录
- 前言
- 1. 什么是解释器架构
- 2. 解释器的基本组成
- 2.1 被解释执行的程序
- 2.2 解释器引擎
- 2.3 解释器内部状态
- 2.4 程序执行的当前状态
- 2.5 存储器模型
- 3. 解释器的工作原理
- 3.1 解析源代码
- 3.2 初始化运行环境
- 3.3 逐条执行语法结构
- 3.4 维护程序状态
- 3.5 内存管理与变量作用域
- 4. 举例:简单表达式解释器
- 5. 解释器架构的优势与限制
- 6. 应用场景与发展方向
- 结语
前言
解释器是许多现代编程语言背后的重要执行机制,尤其在动态语言(如 Python、JavaScript、Lisp)中,解释器架构为程序提供了灵活性与可移植性。它不仅是编程语言实现的基石之一,在规则引擎、教学语言、脚本执行器、虚拟机等场景中也广泛应用。
本文将围绕解释器架构进行深入剖析,详细讲解其基本组成、内部状态管理、执行流程与内存模型,帮助读者系统理解解释器的运作机制,特别适合有一定编程基础、希望了解语言实现机制的开发者与架构师。
1. 什么是解释器架构
解释器架构是一种软件架构风格,它通过逐条解释程序中的指令(或语法结构)来执行代码。在这种架构中,源代码首先被解析为中间形式,如抽象语法树(AST)或字节码,然后由解释器引擎按照预定义语义一条条执行这些中间表示。
与编译器架构不同,解释器不将程序一次性翻译为机器码,而是在运行时边读边执行。这种特性使解释器具有高度的灵活性和更强的动态能力,但通常以牺牲运行效率为代价。
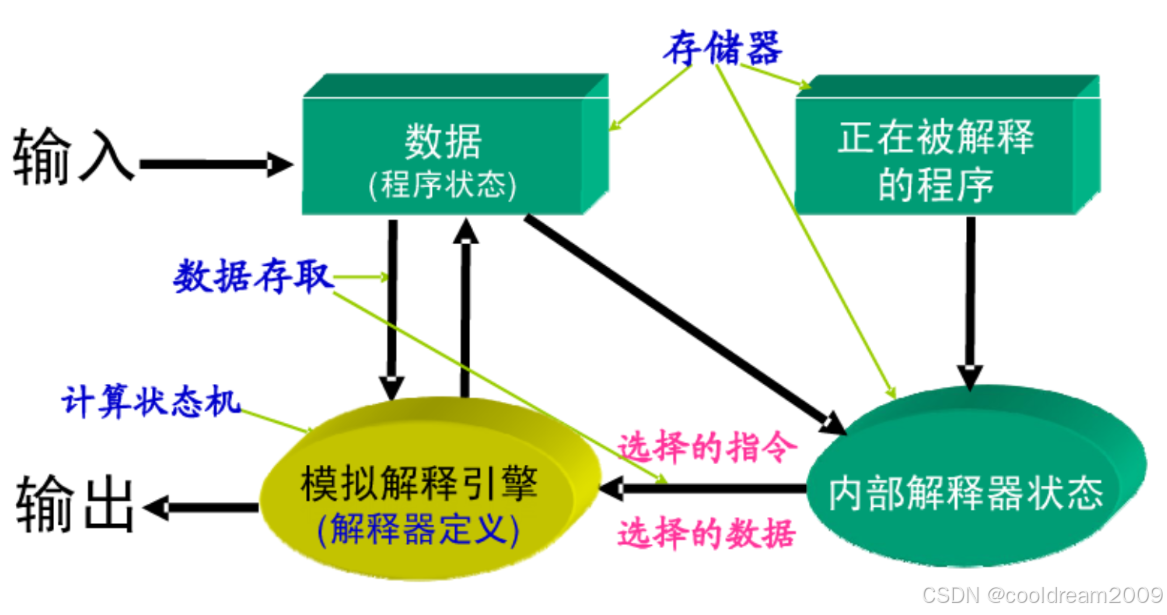
2. 解释器的基本组成
解释器系统由多个关键组件协作运行,它们共同构成了解释器的运行时环境。理解这些模块,有助于掌握整个架构的运行逻辑。
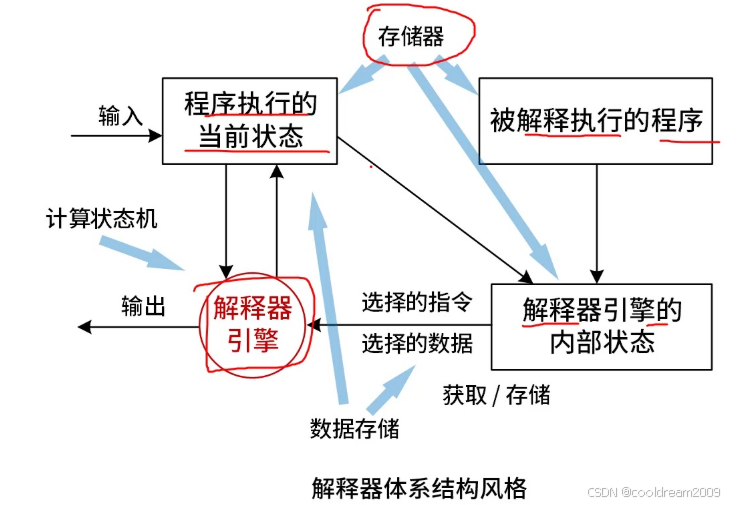
2.1 被解释执行的程序
被解释执行的程序,通常是源代码在经过词法分析和语法分析之后,形成的结构化表示。例如,一段代码 x = 3 + 4 会被解析成一个赋值语句节点,其中包含一个加法子节点。这个结构通常以抽象语法树(AST)或中间代码(Intermediate Representation, IR)的形式存在。
2.2 解释器引擎
解释器引擎是核心执行模块,它负责遍历中间表示,并根据语言定义的语义规则,逐步解释和执行每一个语法节点。引擎通常具备递归执行机制(适合AST)或字节码指令执行循环(适合字节码解释器),是实现程序语义的中心组件。
2.3 解释器内部状态
解释器在运行过程中会维护一些内部状态信息,例如当前执行到的语句位置(程序计数器)、调用栈、当前作用域等。这些状态对于控制执行流程、函数调用、异常处理等至关重要。
2.4 程序执行的当前状态
除了解释器自身的内部状态,解释过程还需要维护程序的执行状态。这个状态包含了当前正在执行的函数调用、局部变量上下文、返回地址等信息。每次函数调用通常会创建一个新的“执行帧”,并压入调用栈中。
2.5 存储器模型
解释器需要有一个运行时存储系统来管理程序中用到的变量、对象、临时值等。通常分为栈(stack)和堆(heap):栈用于管理函数调用和临时变量,堆用于存储动态分配的对象和结构体等。
3. 解释器的工作原理
了解解释器如何“解释”执行程序,是理解其本质的关键。一个标准的解释器执行流程包含如下几个阶段:
3.1 解析源代码
首先,解释器会将源代码输入送入词法分析器,将其分解为一系列的词法单元(token)。接着,语法分析器根据语言的语法规则构建出抽象语法树(AST),或转换成更底层的中间表示(如字节码)。
3.2 初始化运行环境
在开始解释之前,解释器通常会初始化一个全局环境(Environment),用于存储变量绑定信息。比如,在执行 x = 3 + 4 之前,环境是空的,执行之后,环境中将新增 x → 7 的绑定关系。
3.3 逐条执行语法结构
解释器引擎开始遍历 AST 或指令序列。对每一个语法节点,执行以下过程:
- 判断节点类型(如加法、变量、赋值等)。
- 递归解释子节点,获得操作数的值。
- 根据语义规则执行操作,并返回结果。
- 如有必要,更新环境或内存状态。
例如,对节点 Add(Number(3), Number(4)),解释器会先解释左右子节点得到数值 3 和 4,然后执行加法操作并返回结果 7。
3.4 维护程序状态
解释器在整个执行过程中,会持续维护内部状态:
- 程序计数器指向当前执行位置。
- 每次函数调用会创建一个新的执行帧,并入栈。
- 异常处理机制会依赖于栈信息,定位错误源。
这些机制让解释器可以支持复杂的语言结构,如递归函数、异常捕获、闭包等。
3.5 内存管理与变量作用域
变量的值和对象都存储在运行时内存中。解释器根据作用域规则查找变量绑定:
- 在当前环境查找变量;
- 若未找到,向外层作用域继续查找;
- 若最终仍未找到,抛出未定义错误。
对于对象、数组等复杂结构,解释器通常通过堆内存进行管理,并使用引用语义传递。
4. 举例:简单表达式解释器
为帮助理解,下面通过一个简单的表达式语言的解释器示意代码,展示其执行过程:
假设我们有一个表达式 x = 3 + 4,它被解析成如下 AST:
Assign(name='x',value=Add(Number(3), Number(4))
)
解释器解释这个语法树的过程可以表示为如下函数:
def eval(node, env):if node.type == 'number':return node.valueelif node.type == 'add':return eval(node.left, env) + eval(node.right, env)elif node.type == 'assign':value = eval(node.value, env)env[node.name] = valuereturn value
这个解释器维护了一个环境 env 用来保存变量绑定,并通过递归调用来实现语法树的执行。
5. 解释器架构的优势与限制
解释器架构由于其逐条执行、结构简单的特性,在许多领域都有广泛应用。然而,它也存在一些固有限制。
解释器的优势包括:
- 实现相对简单,适合快速开发语言原型。
- 支持动态特性,如运行时定义函数或修改语法结构。
- 便于调试和错误定位,因为执行是逐步进行的。
但它的限制也不容忽视:
- 性能通常较低,尤其在大规模程序中表现不如编译型架构。
- 对于频繁使用的函数或表达式,没有优化机制,重复计算多。
现代解释器(如 PyPy 或 V8)通常采用 JIT(即时编译)技术,在解释基础上引入运行时优化策略,弥补性能短板。
6. 应用场景与发展方向
解释器架构广泛应用于以下领域:
- 脚本语言实现(Python、Ruby、Lua 等)
- DSL(领域特定语言)解释器,如规则引擎中的规则执行器
- 教学语言平台,用于帮助学生学习语言原理
- 虚拟机设计的初级阶段或调试模式
随着 JIT 和 AOT 编译技术的发展,解释器与编译器的边界日益模糊。未来的语言实现常常采用“混合架构”,在解释器之上集成运行时优化和编译器工具链,以达到灵活性和性能的平衡。
结语
解释器作为程序语言实现的一种基本架构形式,不仅是编程语言理论的重要实践载体,也在工程中发挥着不可替代的作用。理解解释器架构,能够帮助开发者深入语言的本质,构建自己的语言工具或定制脚本系统。