应用于分子生成的免训练引导多模态流模型 - TFG-Flow 评测
TFG-Flow (Training-Free Guidance Flow Model)是一个新颖的无训练引导的多模态生成流模型,它基于给定的无条件生成模型和目标性质预测器,旨在在没有额外训练的情况下生成具有期望目标性质的分子样本。这是一种高效的技术,用于将生成模型导向灵活的输出。
注:虽然文章中作者给出了基于口袋的分子生成性能对比,但是在github中,并未提供相应的代码。导致基于口袋的分子生成能力并未测试。因此,只能针对github上的代码运行测试,以下内容仅供大家参考。
一、背景介绍
TFG-Flow 来源于清华大学智能产业研究院副研究员马剑竹为通讯作者的文章:《TFG-FLOW : Training-Free Guidance in Multi-Modal Generative Flow》。文章链接:https://arxiv.org/pdf/2501.14216 。TFG-Flow 的作者包括来自北京大学 (Peking University) 的 Haowei Lin 和 Yitao Liang,卡内基梅隆大学 (Carnegie Mellon University) 的 Shanda Li 和 Yiming Yang,以及 斯坦福大学 (Stanford University) 的 Haotian Ye 和 Stefano Ermon,和 清华大学 (Tsinghua University) 的 Jianzhu Ma。该模型以预印本的形式发布在 arXiv 上,发布于 2024 年 2 月。

给定一个无条件生成模型和一个目标属性的预测器(例如分类器),免训练引导的目标是在无需额外训练的情况下生成具有理想目标属性的样本。作为一种高效引导生成模型实现灵活结果的技术,免训练引导在扩散模型中日益受到关注。然而,现有方法仅能处理连续空间的数据,而许多科学应用同时涉及连续和离散数据(称为多模态)。另一个新兴趋势是,简单通用的流匹配框架在构建生成基础模型中的应用日益增长,但其引导生成机制仍未被充分探索。为此,作者提出了TFG-Flow —— 一种面向多模态生成流的新型免训练引导方法。该方法在保持离散变量引导过程中无偏采样特性的同时,有效应对维度灾难问题。作者在四个分子设计任务上验证了 TFG-Flow 的性能,结果表明该方法通过生成具有所需性质的分子,在药物设计领域展现出巨大潜力。
二、TFG-Flow 模型简介
2.1 前言
生成式基础模型的最新进展展现了其在多个领域日益增强的能力。特别是基于扩散的基础模型,如 Stable Diffusion 和 SORA ,已取得显著成功,推动了艺术与科学领域的新一轮应用浪潮。随着这些模型的普及,一个关键问题浮现:如何在推理过程中引导这些基础模型实现特定属性?
基于分类器引导或无分类器引导是当前主流方向,但这类方法通常需要为每个约束信号(如噪声条件分类器或文本条件去噪器)训练专用模型。这种资源密集且耗时的过程极大限制了其应用范围。近期,针对扩散模型的免训练引导技术引发关注,该方法允许用户直接使用现成的可微分目标预测器引导生成过程,无需额外模型训练。目标预测器可以是任何用于评估生成样本质量的分类器、损失函数或能量函数,为生成式 AI 领域提供了灵活高效的定制化生成方案。
尽管生成模型取得重大进展,现有免训练引导技术主要面向处理连续数据(如图像)的扩散模型。然而,将生成模型扩展到同时处理离散与连续数据的多模态数据,仍是科学领域广泛应用的关键挑战。这种扩展的必要性源于现实问题(如分子设计)往往涉及原子类型(离散)与 3D 坐标(连续)的联合建模。为此,近期生成式基础模型越来越多采用流匹配框架,该框架因对两类数据的普适性而备受青睐。Campbell 等人提出的 Multiflow 通过连续时间马尔可夫链为多模态生成提供了新思路。
然而,由于连续与离散数据引导的本质差异,流匹配框架下的引导生成研究仍处于初级阶段。TFG-Flow 解决了高维度数据带来的维度灾难问题,同时在引导离散变量 (如原子类型) 时保持无偏采样。该模型的核心思想是在多模态生成流框架内实现无训练的性质引导。其技术细节包括对 SO(3) 不变 3D 分子进行建模,并利用 多模态流模型 进行生成。TFG-Flow 的创新点在于实现了无需额外训练即可根据目标性质引导分子生成,克服了维度灾难,并保证了离散变量引导的无偏性。
2.2 主要创新点
TFG-Flow 的主要创新点在于其无训练的性质引导方法,以及解决高维离散变量引导中维度灾难和保持无偏采样方面的技术:
(1)无训练的性质引导 (Training-Free Property Guidance):这是 TFG-Flow 最核心的创新。与需要为特定目标性质重新训练生成模型的条件生成模型不同,TFG-Flow 无需任何额外的训练,即可根据预先训练好的目标性质预测器引导分子生成;使其能够应用于各种不同的目标性质,而无需耗时的重新训练过程。
(2)一致的蒙特卡洛采样用于离散引导 (Consistent Monte-Carlo Sampling for Discrete Guidance):为了解决高维离散变量(如原子类型组合)引导中出现的维度灾难问题,TFG-Flow 提出了一种一致的蒙特卡洛采样方法。通过采样 K 个蒙特卡洛样本来估计引导的速率矩阵,该方法将离散引导的复杂度从指数级别降低到对数级别 ,这使得模型能够有效地引导具有大量原子和原子类型的分子生成。
(3)基于重要性采样的无偏离散引导 (Importance Sampling Based Unbiased Discrete Guidance):传统的连续变量引导方法不适用于离散变量。TFG-Flow 为离散变量设计了基于重要性采样的引导机制,该方法不是直接修改离散状态,而是通过对从模型中采样的离散状态进行加权,来间接地引导生成过程朝着期望的目标性质靠近。这避免了直接修改离散变量状态可能引入的偏差,保证了采样的无偏性 。引导的速率矩阵 Rt(at, b|c) 通过对条件分布 p1|t(a1|at,c) 的期望来计算,该条件分布与目标预测器 fc(G1) 成正比。
(4)多模态处理能力 (Multimodal Processing Capability):TFG-Flow 继承了 Multiflow 处理连续和离散数据的能力,使其能够自然地处理分子结构中不同类型的信息,并实现基于性质的引导。
在多个基准数据集上系统地验证了 TFG-Flow 的性能表现:使用 QM9 数据集评估量子性质引导能力(包括单一和复合性质)和结构相似性引导;使用 GEOM-Drug 数据集测试结构相似性引导;通过 CrossDocked2020 数据集评估靶标感知的药物设计质量。实验结果表明,在量子性质引导任务中,TFG-Flow 在平均绝对误差 (MAE) 等指标上显著优于需要标签数据训练的条件流模型 (Cond-Flow)。在结构相似性引导方面,TFG-Flow 在 QM9 和 GEOM-Drug 数据集上获得了 0.208 的 Tanimoto 相似度,较无条件采样结果 (0.170) 有显著提升。特别地,在 CrossDocked2020 数据集上,TFG-Flow 取得了 -7.65 的 Vina 评分,展现出优异的靶标感知药物设计能力。这些成果证实了 TFG-FFlow 作为免训练性质优化工具的潜力,为分子生成和药物设计提供了高效的新方法。
TFG-Flow 的创新点主要体现在:采用免训练的性质引导策略,并通过蒙特卡洛采样与重要性采样结合的无偏离散引导方法,在基础流模型上有效地克服了高维离散变量引导的难题,为分子设计提供了灵活高效的解决方案。
2.3 模型结构简介
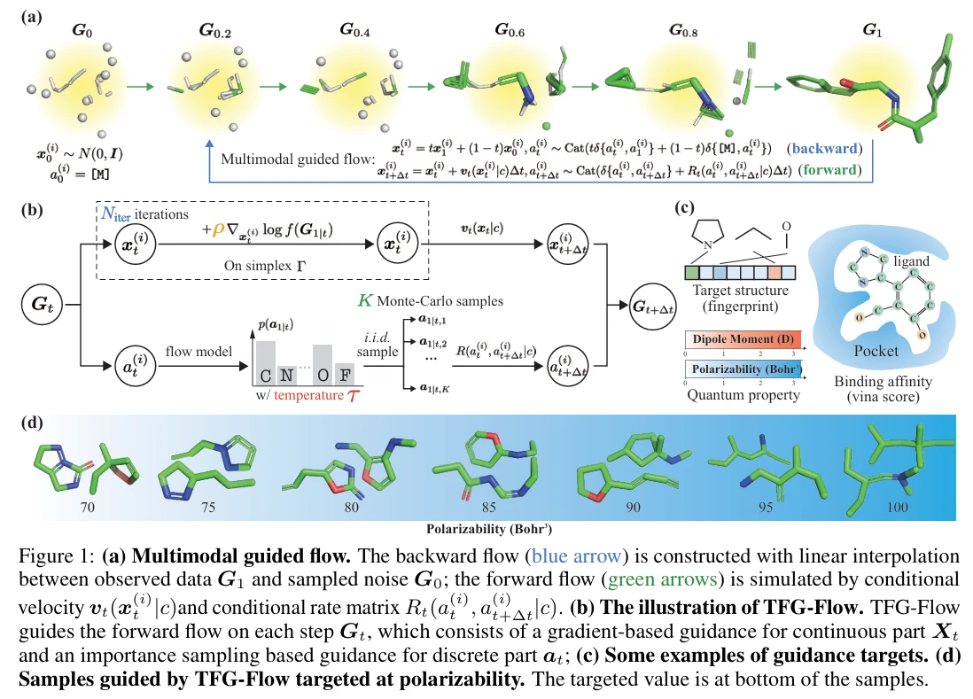
TFG-Flow 是一个在多模态生成流框架 (Multimodal Generative Flow Framework) 内实现的模型,基于 Multiflow 模型进行构建,旨在同时处理分子中的连续变量 (如原子坐标) 和离散变量 (如原子类型),其核心结构包括:
(1)SO(3) 不变 3D 分子建模 (SO(3) Invariant 3D Molecule Modeling):TFG-Flow 使用 Equivariant Graph Neural Networks (EGNNs) 对 3D 分子进行建模,实现旋转平移不变形。
(2)多模态流模型 (Multimodal Flow Model):TFG-Flow 继承了 Multiflow 的框架,通过构建概率流 pt(Gt) 将简单的噪声分布 p0(G0) 转换到复杂的数据分布 p1(G1)。这个流被分解为原子数量和模态的乘积,pt|1(Gt|G1) := ∏ᵢ pt|1(xᵢᵗ|xᵢ¹)pt|1(aᵢᵗ|aᵢ¹)。连续变量和离散变量的条件流 pt|1(xᵢᵗ|xᵢ¹) 和 pt|1(aᵢᵗ|aᵢ¹) 被定义为将噪声分布线性地传输到数据分布。
(3)引导流 (Guided Flow):TFG-Flow 的核心在于引入了无训练的性质引导。它构建了一个引导流 pt(Gt|c) 来生成具有目标性质 c 的分子,这个引导流的关键在于引导速度 (guided velocity) vt(xt|c) 和引导速率矩阵 (guided rate matrix) Rt(at, b|c),它们分别控制连续变量和离散变量的演变。
(4)目标性质预测器 (Target Property Predictor):TFG-Flow 利用一个预先训练好的、与时间无关的性质预测函数 fc(G1) 来指导生成过程。这个预测器可以是任何能够根据分子结构预测目标性质的模型。引导的目标是使生成的分子 G1 具有期望的性质 c,这通过能量函数 f(G) = exp(−∥E(G)− c∥²₂) 来定义,其中 E 是性质预测网络
(5)采样过程 (Sampling Process):在推理阶段,首先从噪声分布中采样 G0,然后通过模拟引导流生成一系列 Gt 值,最终得到生成的分子 G1。对于连续部分 Xt,使用基于梯度的引导,对于离散部分 at,使用基于重要性采样的引导。
三、TFG-Flow 评测
TFG-Flow 提出了一种创新的免训练引导框架,用于多模态生成流,可在无需重新训练的情况下实现跨多种模态的受控生成。TFG-Flow 在 QM9 量子化学数据集上实现了分子属性引导生成的前沿性能,支持对 6 个关键分子属性的精确控制,分别是:
- Alpha(极化率)
- Cv(热容)
- Gap(HOMO-LUMO能隙)
- Homo(最高占据分子轨道)
- Lumo(最低未占分子轨道)
- Mu(偶极矩)
TFG-Flow 的核心特性包括:(1)免训练引导:无需模型重训练即可调整生成行为;(2)多模态生成流:在分子生成领域实现多模态流式生成。
复制代码项目:
git clone https://github.com/linhaowei1/TFG-Flow.git3.1 安装环境
根据说明文档,安装项目运行环境,命令如下:
# Create and activate conda environment
conda create -n TFG_Flow python=3.10 -y
conda activate TFG_Flow # Install PyTorch
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia# install dependencies
pip install -r requirements.txt至此,环境安装完成。
注:QM9数据集在第一次运行的时候,会自动下载。
3.2 模型训练
模型训练包括三个部分,分别是:
- 基础流模型(Base Flow Model):学习潜在的数据分布。
- 引导分类器(Guidance Classifier):估计梯度的最大条件概率。
- 预言模型(Oracle Model):提供目标属性预测。
对应这三个部分,项目分别提供训练脚本,训练命令如下:
# 1. Train Base Flow Model
bash scripts/train_flow.sh
# 2. Train Guidance Classifier
bash scripts/train_guide_clf.sh
# 3. Train Oracle Model
bash scripts/train_oracle.sh 项目提供预训练的模型,在 ./storage/ 文件夹中,目录如下,分别对应三个部分预训练的 checkpoint 。
.
|-- flow_model.pth
|-- guide_clf_ckpt.zip
`-- oracle_clf_ckpt.zip0 directories, 3 files解压压缩包并删除压缩包
unzip guide_clf_ckpt.zip
unzip oracle_clf_ckpt.ziprm guide_clf_ckpt.zip
rm oracle_clf_ckpt.zip此时的目录如下,项目提供了多个模型,名字中包含了 best_loss 的值。
.
|-- flow_model.pth
|-- guide_clf_ckpt
| |-- best_loss=0.0017945603752836663.pth
| |-- best_loss=0.0019835512804612524.pth
| |-- best_loss=0.0030602489901830746.pth
| |-- best_loss=0.0604787247697512.pth
| |-- best_loss=0.12717216682434093.pth
| `-- best_loss=0.20151185317914316.pth
`-- oracle_clf_ckpt|-- best_loss=0.0017926631986916373.pth|-- best_loss=0.0021804291078696644.pth|-- best_loss=0.003081417501829565.pth|-- best_loss=0.05778919728199628.pth|-- best_loss=0.13345399435361235.pth`-- best_loss=0.18175863907186626.pth2 directories, 13 files3.2.1 训练基础流模型(Base Flow Model)
训练命令如下:
bash scripts/train_flow.shscripts/train_flow.sh 脚本的具体内容如下:
cuda_visible_devices=0
for seed in 42 43 44;
do
cmd="CUDA_VISIBLE_DEVICES=$cuda_visible_devices python train_flow.py \--seed $seed \--num_layers 9 \--epoch 1200 \--max_len 9 \--cls_embed_size 64 \--e_embed_size 256 \--h_embed_size 256 \--dataset qm9 \--wandb False"
echo $cmd
eval $cmd &
cuda_visible_devices=`expr $cuda_visible_devices + 1`
done
wait因为我们的机器只有一个 GPU ,修改为:
cuda_visible_devices=0 # 固定使用第一个 GPU(ID=0)
for seed in 42 43 44;
docmd="CUDA_VISIBLE_DEVICES=$cuda_visible_devices python train_flow.py \--seed $seed \--num_layers 9 \--epoch 1200 \--max_len 9 \--cls_embed_size 64 \--e_embed_size 256 \--h_embed_size 256 \--dataset qm9 \--wandb False"echo $cmdeval $cmd # 去掉 `&`,改为顺序执行(不后台并行)
done
wait在后台执行训练命令,训练过程中的输出内容保存在 train_flow.log 中,命令如下:
nohup bash -c "bash ./scripts/qm9/train_flow.sh" > train_flow.log 2>&1训练设置了三个随机种子,分别是 42,43,44 。每个随机数训练 1200 个 epoch,训练过程中显存占用约为 2 GB 。测试训练过程中,每 20 个 epoch 保存一次模型,保存在 ./storage/ckpts/storage/logs 文件夹中,里面的模型文件如下所示,文件名中记录了第几个 epoch 和对应的 loss 值。训练耗时约 30 个小时。
.
|-- epoch=0+loss=2.4023484706878664.pth
|-- epoch=0+loss=2.431406593322754.pth
|-- epoch=0+loss=2.454540665944417.pth
...
|-- epoch=980+loss=1.9518458286921183.pth
|-- epoch=980+loss=2.0219187180201215.pth
`-- epoch=980+loss=2.128681429227193.pth0 directories, 180 files3.2.2 训练引导分类器(Guidance Classifier)
训练命令如下:
bash scripts/train_guide_clf.shscripts/train_guide_clf.sh 脚本的具体内容如下。训练脚本中按照不同的属性("alpha" "cv" "gap" "mu" "homo" "lumo")分别训练引导分类器。
for seed in 42 43 44;
do
cuda_visible_devices=2
for property in "alpha" "cv" "gap" "mu" "homo" "lumo";
docmd="CUDA_VISIBLE_DEVICES=$cuda_visible_devices python train_classifier.py \--seed $seed \--num_layers 6 \--epoch 1200 \--max_len 9 \--cls_embed_size 64 \--e_embed_size 128 \--h_embed_size 128 \--log_dir guide_classifier \--target_property $property \--dataset qm9 \--wandb False"echo $cmdeval $cmd &cuda_visible_devices=`expr $cuda_visible_devices + 1`
done
wait
done因为我们的机器只有一个 GPU ,修改为顺序执行,具体内容如下:
cuda_visible_devices=0 # 固定使用第一个 GPU(ID=0)
for seed in 42 43 44;
dofor property in "alpha" "cv" "gap" "mu" "homo" "lumo";
docmd="CUDA_VISIBLE_DEVICES=$cuda_visible_devices python train_classifier.py \--seed $seed \--num_layers 6 \--epoch 20 \--max_len 9 \--cls_embed_size 64 \--e_embed_size 128 \--h_embed_size 128 \--log_dir guide_classifier \--target_property $property \--dataset qm9 \--wandb False"echo $cmdeval $cmd # 去掉 `&`,改为顺序执行(不后台并行)
done
wait
done在后台执行训练命令,训练过程中的输出内容保存在 train_flow.log 中,命令如下:
nohup bash -c "time bash ./scripts/qm9/train_guide_clf.sh" > train_guide_clf.log 2>&1
训练设置了三个随机种子,分别是 42,43,44 。每个随机数训练 20 个 epoch,训练过程中显存占用约为 1 GB ,花费时间约 4 个小时。每个属性分别使用不同的随机种子测试训练了三次,训练好的模型文件保存在 ./storage/ckpts 文件夹中,目录如下:
.
|-- guide_classifier+target_name=['alpha']
|-- guide_classifier+target_name=['cv']
|-- guide_classifier+target_name=['gap']
|-- guide_classifier+target_name=['homo']
|-- guide_classifier+target_name=['lumo']
|-- guide_classifier+target_name=['mu']
|-- oracle_classifier+target_name=['alpha']
|-- oracle_classifier+target_name=['cv']
|-- oracle_classifier+target_name=['gap']
|-- oracle_classifier+target_name=['homo']
|-- oracle_classifier+target_name=['lumo']
`-- oracle_classifier+target_name=['mu']12 directories, 0 files以第一个文件夹 guide_classifier+target_name=['alpha'] 为例,查看保存的模型文件,如下所示,这三个文件分别是使用不同的随机种子,针对 alpha 属性训练好的模型文件。
.
|-- best_loss=2.710612346569697.pth
|-- best_loss=4.371461240212123.pth
`-- best_loss=4.538997871915499.pth0 directories, 3 files3.2.3 训练预测模型(Oracle Model)
./scripts/qm9/train_oracle.sh 是项目提供预测模型(Oracle Model)的训练脚本,具体内容如下:
for seed in 42 43 44;
do
cuda_visible_devices=2
for property in "alpha" "cv" "gap" "mu" "homo" "lumo";
docmd="CUDA_VISIBLE_DEVICES=$cuda_visible_devices python train_classifier.py \--seed $seed \--num_layers 6 \--epoch 1200 \--max_len 9 \--cls_embed_size 64 \--e_embed_size 128 \--h_embed_size 128 \--log_dir oracle_classifier \--target_property $property \--dataset qm9 \--wandb False"echo $cmdeval $cmd &cuda_visible_devices=`expr $cuda_visible_devices + 1`
done
wait
done我们的机器只有一个 GPU,所以把并行训练改为顺序训练,脚本内容修改为:
cuda_visible_devices=0 # 固定使用第一个 GPU(ID=0)
for seed in 42 43 44;
dofor property in "alpha" "cv" "gap" "mu" "homo" "lumo";
docmd="CUDA_VISIBLE_DEVICES=$cuda_visible_devices python train_classifier.py \--seed $seed \--num_layers 6 \--epoch 20 \--max_len 9 \--cls_embed_size 64 \--e_embed_size 128 \--h_embed_size 128 \--log_dir oracle_classifier \--target_property $property \--dataset qm9 \--wandb False"echo $cmdeval $cmd # 去掉 `&`,改为顺序执行(不后台并行)
done
wait
done在后台执行训练命令,训练过程中的输出内容保存在 train_oracle.log 中,命令如下:
nohup bash -c "time bash ./scripts/qm9/train_oracle.sh" > train_oracle.log 2>&1
训练设置了三个随机种子,分别是 42,43,44 。每个随机数训练 20 个 epoch,训练过程中显存占用约为 1 GB ,花费时间约 4 个小时。同样也是针对不同的属性分别使用不同的随机种子测试训练了三次,训练好的模型保存在 ./storage/oracle_clf_ckpt 文件夹中,具体文件如下:
.
|-- best_loss=0.0017926631986916373.pth
|-- best_loss=0.0021804291078696644.pth
|-- best_loss=0.003081417501829565.pth
|-- best_loss=0.05778919728199628.pth
|-- best_loss=0.13345399435361235.pth
`-- best_loss=0.18175863907186626.pth0 directories, 6 files模型文件保存的时候默认以最好的 loss 作为文件名,没有区分不同的属性,自己训练的时候需要修改脚本的文件命名。
三部分的模型经过测试,脚本运行都没有报错。
3.3 引导式推理生成(QM9_homo)
生成具有特定属性目标的分子的命令如下:
bash scripts/qm9/guidance/qm9_homo.shscripts/qm9/guidance/qm9_homo.sh 文件的具体内容如下:
cuda_visible_devices=3taus=(0.000005 0.00001 0.00002 0.00004)
rhos=(0.5 1.0 2.0 4.0)
for temperature in ${taus[@]};
do
for rho in ${rhos[@]};
do
for seed in 42 43 44;
docmd="CUDA_VISIBLE_DEVICES=$cuda_visible_devices python sample_mols.py \--seed $seed \--num_layers 9 \--epoch 1200 \--max_len 9 \--cls_embed_size 64 \--e_embed_size 256 \--h_embed_size 256 \--sample_bs 128\--sample_tot_num 4096 \--flow_ckpt ../flow_models/best.pth \--target_property homo \--dataset qm9 \--wandb False \--k 512 \--temperature $temperature \--n_iter 4 \--n_recur 1 \--rho $rho \--mu $rho \--gamma 0.0 \--num_eps 1 \--guidance_weight 1 \--wandb False"echo $cmdeval $cmdcuda_visible_devices=`expr $cuda_visible_devices + 1`
done
done
done该 shell 脚本用于自动化运行多个分子生成实验,每个实验使用不同的超参数组合和 GPU 设备。以下是逐层解释:
(1)GPU 设置:cuda_visible_devices=3 初始指定使用索引为 3 的GPU。
(2)超参数定义:taus 和 rhos 分别为温度参数和 rho 参数的数组,用于调节分子生成过程。
(3)三重嵌套循环:
- 外层循环:遍历不同的温度值 (temperature)。
- 中层循环:遍历不同的 rho 值 (rho)。
- 内层循环:遍历随机种子 (seed),确保实验可重复性。
(4)命令构建与执行:每次循环动态生成 cmd 命令,调用 sample_mols.py 脚本,传入当前参数(如种子、温度、rho 等)。eval $cmd 执行生成的命令,启动分子生成任务。每执行完一次命令,cuda_visible_devices 递增 1,尝试将下一个任务分配到后续 GPU 上。
(5)关键参数说明:
- flow_ckpt: 指定预训练的流模型路径,用于分子生成。
- target_property: 目标属性设为 homo(最高占据分子轨道),指导生成具有特定性质的分子。
- dataset: 使用 QM9 数据集。
- wandb False: 禁用实验跟踪工具 Weights & Biases 。
我们测试的机器只有一个 24 GB 的 3090 ,所以将 cuda_visible_devices=3 改为 cuda_visible_devices=0,始终使用第一个GPU。移除 cuda_visible_devices=expr $cuda_visible_devices + 1 避免索引溢出。脚本按顺序执行所有参数组合(共 4 温度 x 4 rho x 3 种子 = 48 次实验),无需担心 GPU 冲突。修改后的脚本内容如下,--flow_ckpt ./storage/flow_model.pth 指定模型提供的流模型。
cuda_visible_devices=0 # 固定使用第一个GPU(索引0)taus=(0.000005 0.00001 0.00002 0.00004)
rhos=(0.5 1.0 2.0 4.0)
for temperature in ${taus[@]};
do
for rho in ${rhos[@]};
do
for seed in 42 43 44;
docmd="CUDA_VISIBLE_DEVICES=$cuda_visible_devices python sample_mols.py \--seed $seed \--num_layers 9 \--epoch 1200 \--max_len 9 \--cls_embed_size 64 \--e_embed_size 256 \--h_embed_size 256 \--sample_bs 256 \--sample_tot_num 4096 \--flow_ckpt ./storage/flow_model.pth \--target_property homo \--dataset qm9 \--wandb False \--k 512 \--temperature $temperature \--n_iter 4 \--n_recur 1 \--rho $rho \--mu $rho \--gamma 0.0 \--num_eps 1 \--guidance_weight 1 \--wandb False"echo $cmdeval $cmd# 移除 GPU 递增逻辑(避免溢出)
done
done
done命令运行时,根据机器的配置情况,需要安装一些模块:
pip install einopsconda install openbabel 新版本的 pybel 不再作为单独的模块存在,不需要单独导入,而是需要从 openbabel 直接导入。对导入部分进行修改,把 ./dataloader/fingerprints.py 脚本中的:
import pybel改成:
from openbabel import pybel
同时,加载的模型checkpoint的路径不对,需要查看模型的实际路径。./utils/env_utils.py 中记录了每个模型的路径,具体内容如下。里面的路径和实际路径不符,也会导致模型加载错误。
predictor_ckpt = {'qm9': {'alpha': "./storage/ckpts/guide_classifier+target_name=['alpha']/best_loss=0.12717216682434093.pth",'homo': "./storage/ckpts/guide_classifier+target_name=['homo']/best_loss=0.0019835512804612524.pth",'lumo': "./storage/ckpts/guide_classifier+target_name=['lumo']/best_loss=0.0017945603752836663.pth",'mu': "./storage/ckpts/guide_classifier+target_name=['mu']/best_loss=0.20151185317914316.pth",'cv': "./storage/ckpts/guide_classifier+target_name=['cv']/best_loss=0.0604787247697512.pth",'gap': "./storage/ckpts/guide_classifier+target_name=['gap']/best_loss=0.0030602489901830746.pth"}
}
oracle_ckpt = {'qm9': {'alpha': "./storage/ckpts/oracle_classifier+target_name=['alpha']/best_loss=0.13345399435361235.pth",'homo': "./storage/ckpts/oracle_classifier+target_name=['homo']/best_loss=0.0021804291078696644.pth",'lumo': "./storage/ckpts/oracle_classifier+target_name=['lumo']/best_loss=0.0017926631986916373.pth",'mu': "./storage/ckpts/oracle_classifier+target_name=['mu']/best_loss=0.18175863907186626.pth",'cv': "./storage/ckpts/oracle_classifier+target_name=['cv']/best_loss=0.05778919728199628.pth",'gap': "./storage/ckpts/oracle_classifier+target_name=['gap']/best_loss=0.003081417501829565.pth"}
}在此,把 ./utils/env_utils.py 中的路径修改为实际的模型路径,具体如下:
predictor_ckpt = {'qm9': {'alpha': "./storage/guide_clf_ckpt/best_loss=0.12717216682434093.pth",'homo': "./storage/guide_clf_ckpt/best_loss=0.0019835512804612524.pth",'lumo': "./storage/guide_clf_ckpt/best_loss=0.0017945603752836663.pth",'mu': "./storage/guide_clf_ckpt/best_loss=0.20151185317914316.pth",'cv': "./storage/guide_clf_ckpt/best_loss=0.0604787247697512.pth",'gap': "./storage/guide_clf_ckpt/best_loss=0.0030602489901830746.pth"}
}
oracle_ckpt = {'qm9': {'alpha': "./storage/oracle_clf_ckpt/best_loss=0.13345399435361235.pth",'homo': "./storage/oracle_clf_ckpt/best_loss=0.0021804291078696644.pth",'lumo': "./storage/oracle_clf_ckpt/best_loss=0.0017926631986916373.pth",'mu': "./storage/oracle_clf_ckpt/best_loss=0.18175863907186626.pth",'cv': "./storage/oracle_clf_ckpt/best_loss=0.05778919728199628.pth",'gap': "./storage/oracle_clf_ckpt/best_loss=0.003081417501829565.pth"}
}创建 ./check_qm9.ipynb 查看数据集。
from datasets import load_dataset# 直接加载单个 Parquet 文件
dataset = load_dataset("parquet",data_files="./storage/datasets/data/train-00000-of-00001-baa918c342229731.parquet",split="train" # 如果文件是训练集分片
)# 查看数据集结构
print(dataset)# 查看第一条数据
print(dataset[0])# 转换为 Pandas DataFrame
df = dataset.to_pandas()打印结果如下。数据集中包括原子数目(num_atoms)、元素符号(atomic_symbols)、原子坐标(pos)、电荷(charges)等特征信息。
Dataset({features: ['num_atoms', 'atomic_symbols', 'pos', 'charges', 'harmonic_oscillator_frequencies', 'smiles', 'inchi', 'A', 'B', 'C', 'mu', 'alpha', 'homo', 'lumo', 'gap', 'r2', 'zpve', 'u0', 'u', 'h', 'g', 'cv', 'canonical_smiles', 'logP', 'qed', 'np_score', 'sa_score', 'ring_count', 'R3', 'R4', 'R5', 'R6', 'R7', 'R8', 'R9', 'single_bond', 'double_bond', 'triple_bond', 'aromatic_bond'],num_rows: 133885
})
{'num_atoms': 5, 'atomic_symbols': ['C', 'H', 'H', 'H', 'H'], 'pos': [[-0.0126981359, 1.0858041578, 0.0080009958], [0.002150416, -0.0060313176, 0.0019761204], [1.0117308433, 1.4637511618, 0.0002765748], [-0.540815069, 1.4475266138, -0.8766437152], [-0.5238136345, 1.4379326443, 0.9063972942]], 'charges': [-0.535689, 0.133921, 0.133922, 0.133923, 0.133923], 'harmonic_oscillator_frequencies': [1341.307, 1341.3284, 1341.365, 1562.6731, 1562.7453, 3038.3205, 3151.6034, 3151.6788, 3151.7078], 'smiles': 'C', 'inchi': 'InChI=1S/CH4/h1H4', 'A': 157.7118, 'B': 157.70997, 'C': 157.70699, 'mu': 0.0, 'alpha': 13.21, 'homo': -0.3877, 'lumo': 0.1171, 'gap': 0.5048, 'r2': 35.3641, 'zpve': 0.044749, 'u0': -40.47893, 'u': -40.476062, 'h': -40.475117, 'g': -40.498597, 'cv': 6.469, 'canonical_smiles': 'C', 'logP': 0.6361, 'qed': 0.3597849378839701, 'np_score': 0.0, 'sa_score': 7.3284153846153846, 'ring_count': 0, 'R3': 0, 'R4': 0, 'R5': 0, 'R6': 0, 'R7': 0, 'R8': 0, 'R9': 0, 'single_bond': 0, 'double_bond': 0, 'triple_bond': 0, 'aromatic_bond': 0}
修改读取数据集的代码,从本地读取下载好的数据集。把 ./dataloader/datasets/qm9.py 脚本中的:
data = load_dataset('yairschiff/qm9')修改为:
data = load_dataset("parquet",data_files="./storage/datasets/data/train-00000-of-00001-baa918c342229731.parquet", )注:因为设备的原因,可能还有更多的运行报错,大部分处理起来比较简单。我们设备的详细包错及其处理过程见附件《TFG-Flow 完整测评文档+可运行代码》
在后台运行生成测试的脚本,同时记录输出内容到 qm9_homo.log,以便后续查看。
nohup bash scripts/qm9/guidance/qm9_homo.sh > qm9_homo.log 2>&1 &生成测试脚本运行显存占用 19 GB,生成过程的记录文件保存在 ./storage/logs 文件夹,内容如下:
.
|-- dataset=qm9+k=512+temperature=1e-05+rho=0.5+mu=0.5+n_iter=4+target=['homo']+seed=42
|-- dataset=qm9+k=512+temperature=1e-05+rho=0.5+mu=0.5+n_iter=4+target=['homo']+seed=43
|-- dataset=qm9+k=512+temperature=1e-05+rho=0.5+mu=0.5+n_iter=4+target=['homo']+seed=44
...
|-- dataset=qm9+k=512+temperature=5e-06+rho=4.0+mu=4.0+n_iter=4+target=['homo']+seed=43
`-- dataset=qm9+k=512+temperature=5e-06+rho=4.0+mu=4.0+n_iter=4+target=['homo']+seed=4448 directories, 0 files每个实验文件夹中包含一个 json 文件,以第一个文件夹为例,内容如下所示:
{"validity": 0.83642578125, "uniqueness": 0.9929947460595446,
"novelty": 0.8745281911036552, "mol_stability": 0.93408203125,
"atom_stability": 0.9919434562562004, "connectivity": 0.75830078125,
"mae_1": 0.013706149271456525, "mae_2": 0.0}记录了该次实验的评估结果,包括有效性、唯一性、新颖性、分子稳定性、原子稳定性、化学键连接等评价指标。
这 48 个 json 文件中都包含了类似的评价指标数据的平均值。
3.4 批量生成
for property in alpha cv gap homo lumo mu; dobash scripts/qm9/guidance/qm9_${property}.sh
done注:哈特里(Hartree)与毫电子伏(meV)能量单位换算:
1 Hartree = 27211.4 meV # 适用于 homo, lumo, gap 属性注:这里的批量生成没有测试,只测试了 homo 属性的代码,其他脚本是类似的只是改了不同的属性。这一部分就不再测试了。