较为深入的了解c++中的string类(1)
较为深入的了解c++中的string类(1)
首先看:

这张图的意思其实就是告诉了我们, string不是直接定义出来的, 而是一个类模板的实例化. 这个类模板就是里面提到的:basic_string
大家可以点击进去看, 就可以看到下面这个东西:
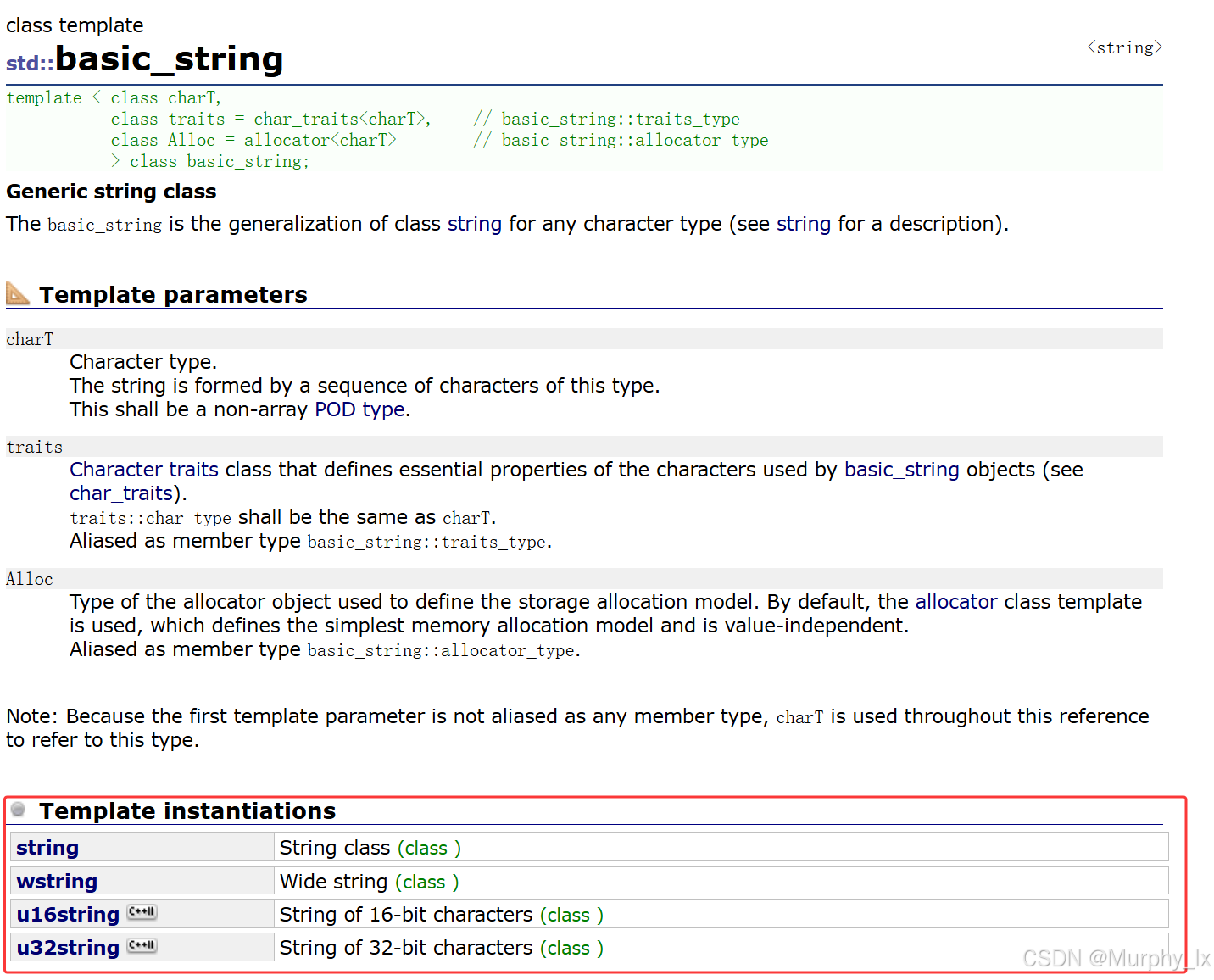
那么我们可以看到c++是通过这个basic_string类模板实例化了4份具体的类. (也就是我红色圈圈里面的那四个)
那么大家可能就会有这么一个问题: 为什么不直接写一个string类出来, 一个string类不就够了吗?
首先, 这些东西一开始是外国人写的, 他们使用的语言就是英文嘛. 其实一个他们的语言主要就是用多个字母(分大小写)组成一句话, 以及0~9的阿拉伯数字. 这是他们的文化.
其次在计算机里面, 计算机是无法理解字母昂什么的, 计算机只能理解0和1, 所以我们无法直接存储字母, 数字, 或者一些别的符号.
所以美国人呢就设计了一个ASCII 编码(American Standard Code for Information Interchange), 这个东西一开始就是美国人设计的, 英文名称就很明确了.
也就是下面这个东西:
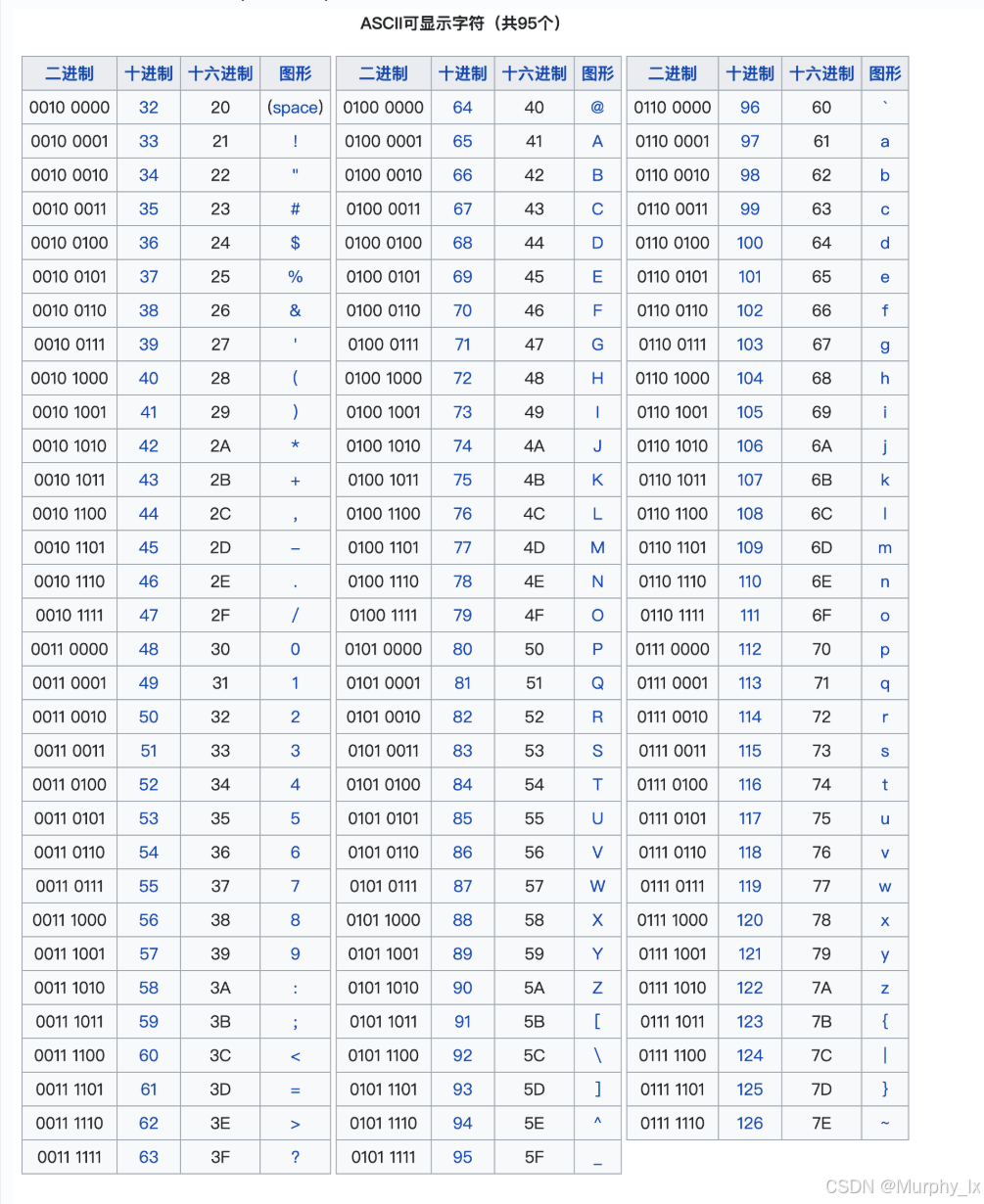
那么编码其实就是啥呢? 其实就是设置了一个信息对应表, 假设在计算机里面存的二进制码是0100 0001, 那么它实际就是代表大写字母A. 就通过这样的一种方式在计算机里面存储数据. 也就是说, 计算机里面存的其实不是真的A, 而是0100 0001. 来, 大家看下面这张图
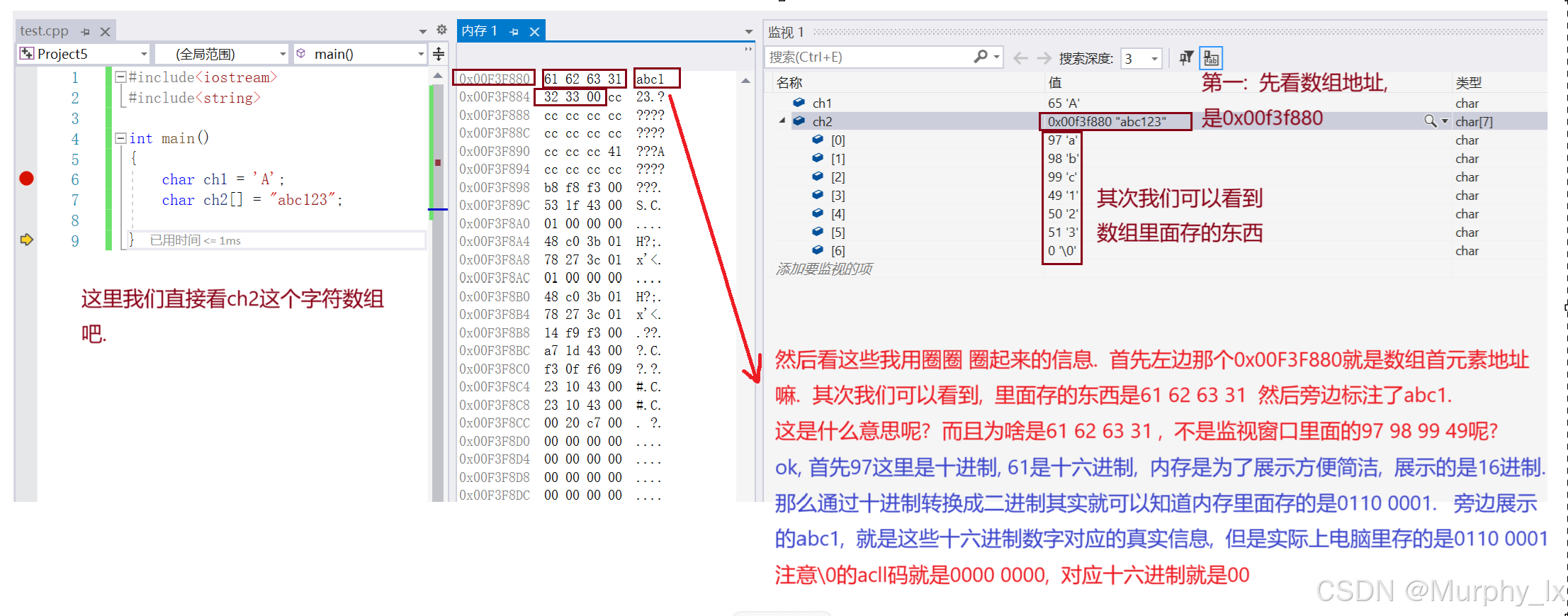
举个例子来说, 大家可以将编码想象成你和你好朋友之间约定的暗号(手势), 你们交流就用手势, 你们约定好了这个手势是啥意思, 那个手势是啥意思. 编码也是一样, 编码就是人和计算机约定好的暗号, 0100 0001是A的意思. 就是这么一个东西.
ASCII 编码特点就是单字节编码, 也就是说, 一个字节就可以代表一个单元信息(一个字母, 一个数字, 一个符号), 一个字节就是8个比特, 对应就是0000 0000到0111 1111 . 为啥不是到1111 1111呢, 因为英文单词就那么几个, 数字也是, 符号也没多少, 就用不着那么多, 所以 ASCII 编码里面就用了0000 0000到0111 1111 这个范围(转换成10进制就是0~127嘛), 编码了128个字符.
那么好, 我们学习的string类其实不就是管理字符数组的一个类嘛, 字符数组里面存的都是char类型的一个又一个字符嘛. 那么对于美国人来说, 单纯的只去实现一个string类就是ok了的, 完全够用了.
但是现在的问题就是世界不是只有一个美国或者只有欧美国家(使用英语的国家), 还有中国, 日本, 韩国等等国家, 这些国家又不用英文, 那么第一ASCII 编码就不管用了噢.
因为汉字什么的那么多, 还有简体繁体, 所以后面就又出现了很多新的编码: 比如我们国家的就是**GBK编码**, GBK编码就是双字节编码, 那么一个char类型就不顶用了噢. 需要两个字节来存一个汉字, 因为汉字多昂, 所以只能使用多字节存储才能尽可能的存储到完备的汉字信息. 因为单字节存储的范围最大不过0000 0000到1111 1111
转换成10进制就是0到255一共256个字符, 哪里够存汉字的? 所以就用了双字节存储汉字, 这样才能把一些常用汉字存储完备.
除了汉字还有其他的一些语言, 诸如日语昂, 韩语昂, 都需要用到不同的编码, (编码这里就不在细说了), 那么为了应对不同的编码规则, 就要有多个类似的string类, 因为这些string类只是参数类型不同(或者说编码规则不同), 其他的逻辑都是相同的, 写多份很明显就是多余了嘛, 所以c++就写了一个类模板basic_string, 然后用类模板实例化各种string类.
那么这里就说清楚了, 为啥string类不直接实现, 而是用的类模板实例化.