Rag技术----项目博客(六)
RAG
定义:检索增强生成(Retrieval Augmented Generation),简称 RAG,已经成为当前最火热的LLM应用方案。
目的:通过提供相关领域数据库通过问题检索信息,将相关信息合并到Prompt中,增强模型的专业性。
深入浅出RAG技术:
RAG=检索技术+LLM提示
//LLM提示就是之前文章中提到过的promt工程,这里不再赘述,主要理解检索技术
检索技术
2019年,Faiss就实现了基于嵌入的向量搜索技术,但是 RAG 推动了向量搜索领域的发展。比如 chroma、weaviate.io和 pinecone这些基于开源搜索索引引擎(主要是 faiss 和 nmslib)向量数据库初创公司,最近增加了输入文本的额外存储和其他工具。
向量化是将文本数据转化为向量矩阵的核心过程,通常使用embedding模型来实现,常用的模型:
| 模型名称 | 描述 |
| ChatGPT-Embedding | ChatGPT-Embedding由OpenAI公司提供,以接口形式调用。 |
| ERNIE-Embedding V1 | ERNIE-Embedding V1由百度公司提供,依赖于文心大模型能力,以接口形式调用。 |
| M3E | M3E是一款功能强大的开源Embedding模型,包含m3e-small、m3e-base、m3e-large等多个版本,支持微调和本地部署。 |
| BGE | BGE由北京智源人工智能研究院发布,同样是一款功能强大的开源Embedding模型,包含了支持中文和英文的多个版本,同样支持微调和本地部署。 |
本项目使用的模型为BAAI/bge-large-zh-v1.5BAAI/bge-small-zh,特点是体积小且适合中文。
向量数据库:数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程,适用于RAG场景的数据库包括:FAISS、Chromadb、ES、milvus等,本项目选择的数据库为FAISS。
当我们要在数据库中寻找与问题相关的数据时常用的方法:
常见计算方法:k-临近
数据距离计算方法:欧式距离、曼哈顿距离、明科夫斯基距离。
RAG工作原理:
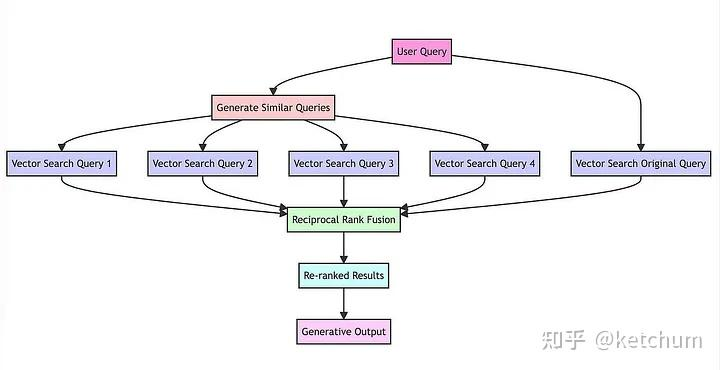
数据库构建并应用
前期准备
环境
有两个最著名的基于 LLM 的管道和应用程序的开源库——LangChain 和 LlamaIndex,受 ChatGPT 发布的启发,它们在 2022 年 10 月和 11 月创立,并在 2023 年获得大量采用。
本项目使用的开源库为LangChain。
数据积累
数据来源:https://github.com/LawRefBook/Laws
该项目目的是收集各类法律法规、部门规章、案例等,并将其按照章节等信息进行了处理。
项目提供了request.py 脚本,支持从 BAAI/bge-large-zh-v1.5 爬取最新的法律法规。
数据库构建
目录结构
读取数据
# 遍历 Markdown 文件
docs = []
root_dir = Path("data/Laws-master/LAWS")
md_files = {}
for dir_name in os.listdir(root_dir):dir_path = os.path.join(root_dir, dir_name)if os.path.isdir(dir_path): # 确保是文件夹md_files[dir_name] = {}for file_name in os.listdir(dir_path):if file_name.endswith(".md"):选择分词器并加载嵌入模型
embedding_model = HuggingFaceEmbeddings(model_name="../models/BAAI/bge-small-zh")
splitter = MarkdownTextSplitter(chunk_size=500, chunk_overlap=50)构建数据库
file_path = os.path.join(dir_path, file_name)loader = TextLoader(str(file_path), encoding='utf-8')raw_docs = loader.load()split_docs = splitter.split_documents(raw_docs)docs.extend(split_docs)
vectorstore = FAISS.from_documents(docs, embedding_model)
vectorstore.save_local("faiss_index")数据库应用
def rag_ask(question, top_k=2):# 检索相关法条docs = db.similarity_search(question, k=top_k)# print(docs)#生成前k个相关的问题context = "\n\n".join([doc.page_content for doc in docs])print(context)prompt = f"""你是中国法律助手,请根据以下法条内容回答问题:
【法条内容】:
{context}【用户问题】:{question}
【回答】:
"""print(prompt)response = pipe(prompt, max_new_tokens=512)[0]['generated_text']print(response[len(prompt):].strip())
效果展示
prompt

回答结果
