人脸口罩识别
本节课将提供数据集和实现lenet-5模型从代码到训练的过程
通过百度网盘分享的文件:人脸口罩项目.zip
链接:https://pan.baidu.com/s/1A7qqsRYP4MD1hKInQeAL_Q?pwd=cwy4
提取码:cwy4
--来自百度网盘超级会员V2的分享
Conda activate -n tf_gpu_face python=3.8
conda activate tf_gpu_face
图像预处理
运行图像预处理.py
每次只能用一个程序,也就是你在用demo1的时候需要将demo2注释掉,因为show只能显示一个窗口,和cv2是有些区别的。
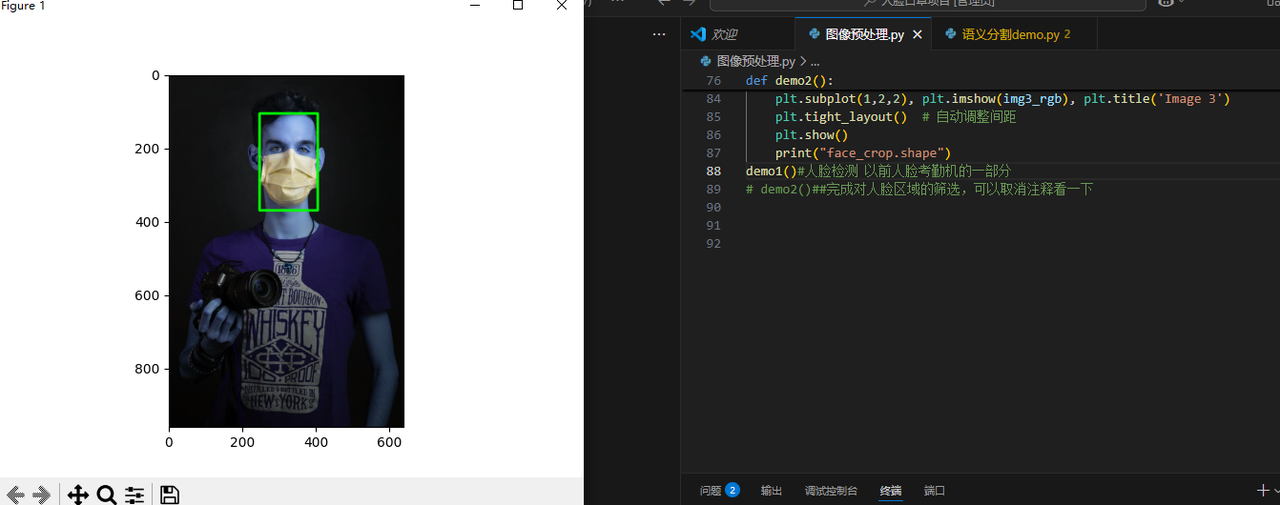
demo1()是用人脸检测模型对图像的人脸区域进行检测,是以前人脸考勤机项目的一部分
demo2()是对人脸区域进行保留,只保留人脸区域,为后续训练做准备
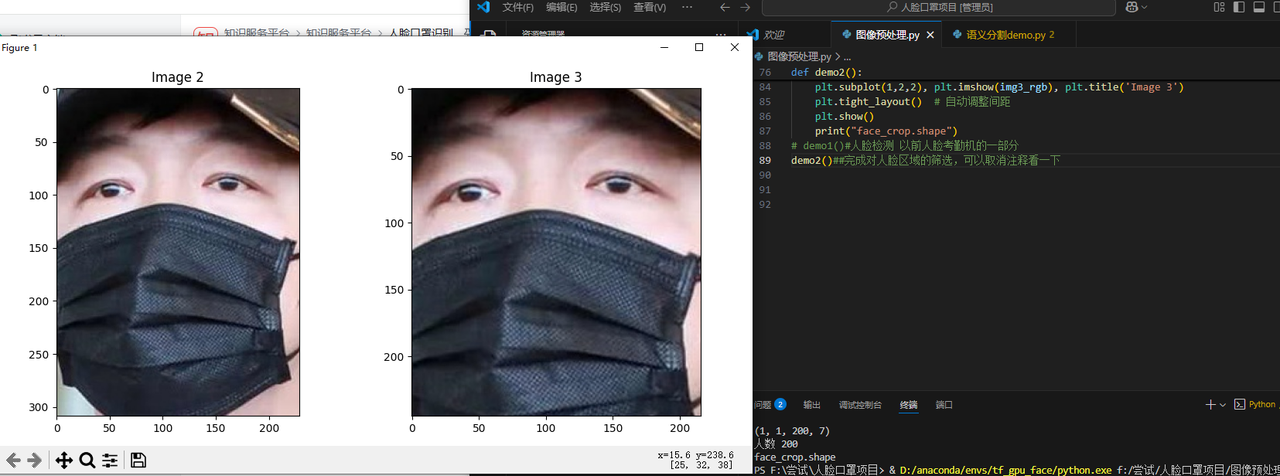
demo3()#完成对人脸的筛选和进行预处理
demo4()#进度条显示所有label处理进度 并存储numpy中

cnn简单回顾
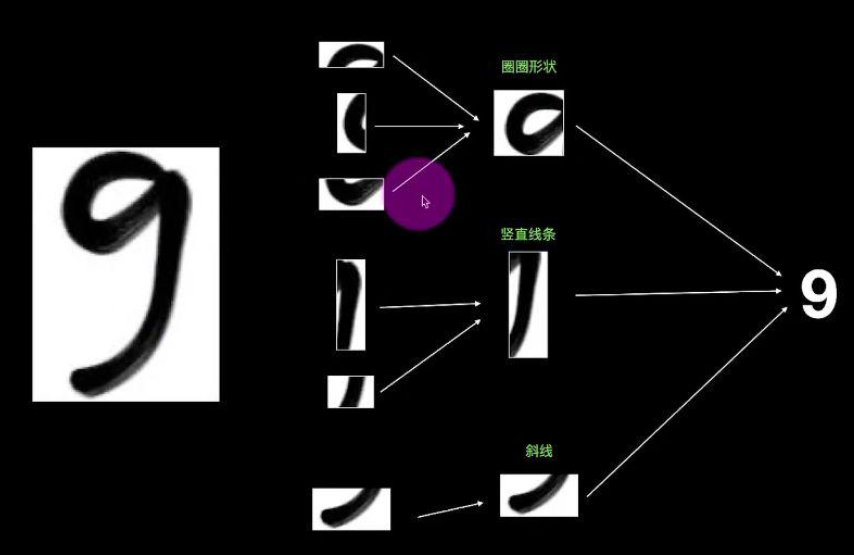
cnn是如何识别猫的
按人脑是通过识别猫的眼睛鼻子耳朵拼凑在一起,然后大脑判断这是猫

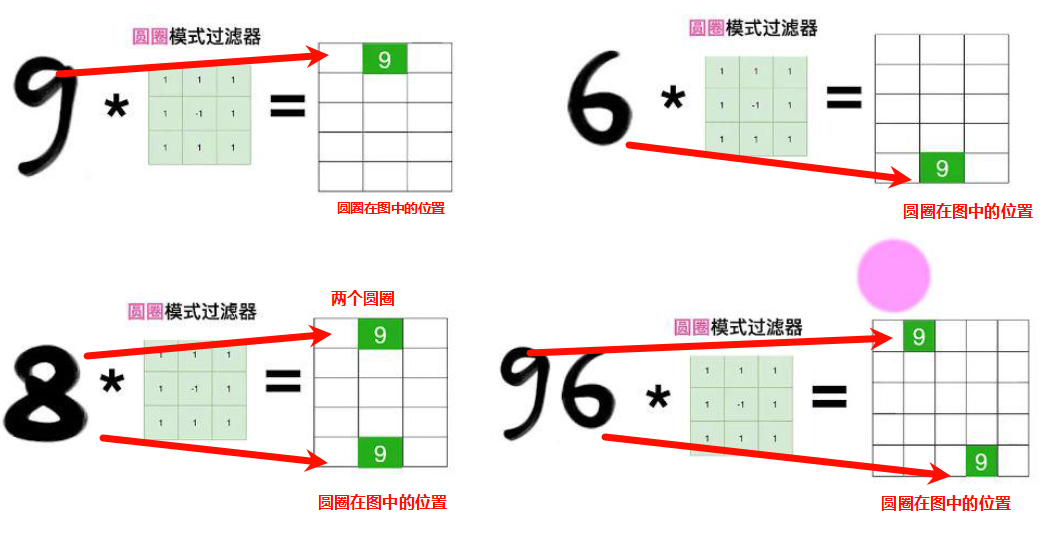
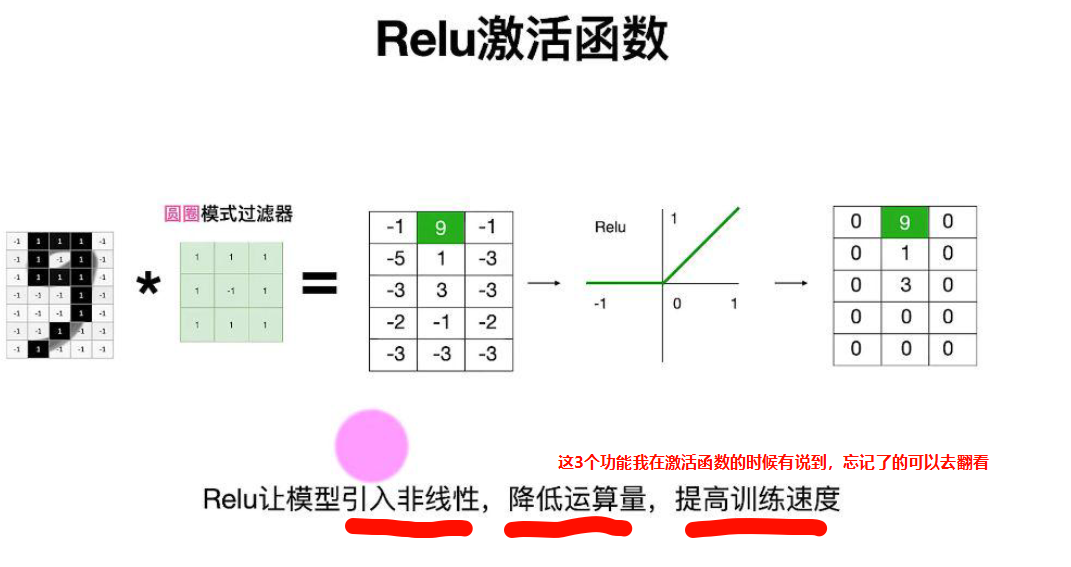
假设识别一个数字9,我们可以用同样的方法,识别一个圆圈,竖线,斜线在途中的位置,然后将这3个特征在途中的位置对应起来,就是我们的数字9.
卷积层
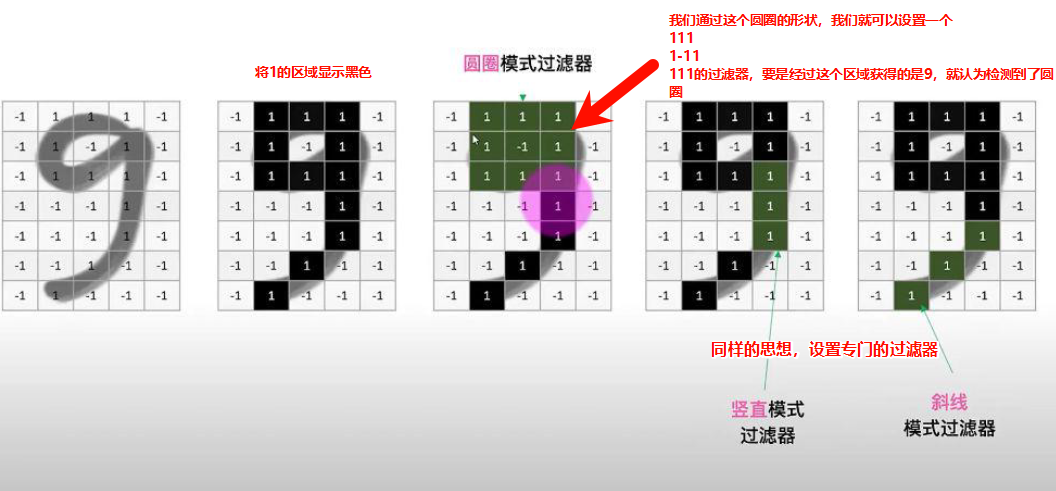
根据图片9的数据形状,我们对圆圈、竖线、斜线的过滤器进行了定义,在CNN中这些过滤器是自动完成的,不需要人为去设置,他会自动根据目标的现状去设置最合适的过滤器,所以说神经网络是端到端的模型。而在我们前面学习的机器学习svm中就需要手动设置这些过滤器,比如SVM-HOG,HOG就是那个过滤器,然后才能通过HOG获取特征,然后用SVM去训练。

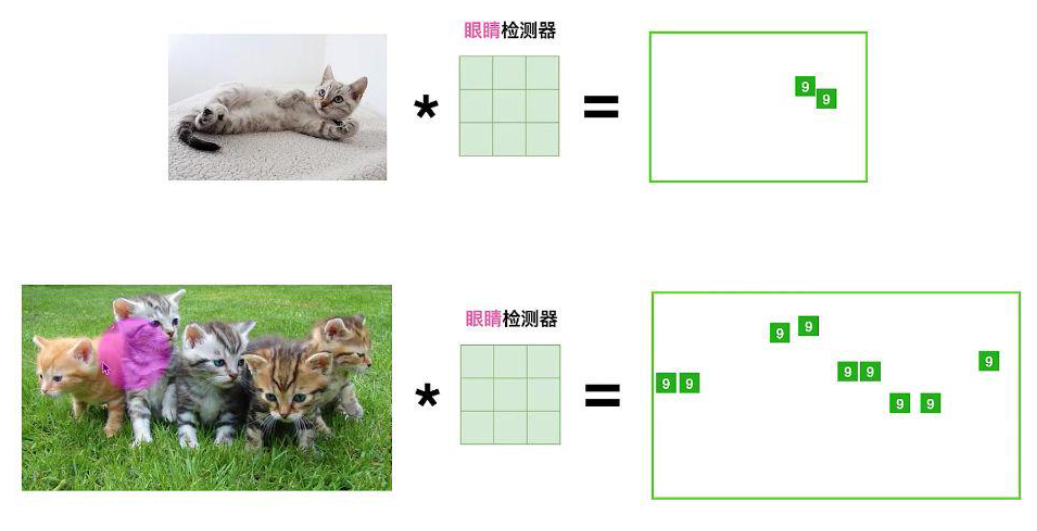
所以识别猫也一样,我们通过cnn设置一个眼镜鼻子耳朵的过滤器,然后检测这3个特征图中的位置,然后将眼睛鼻子耳朵拼凑在一起就是猫的头了。
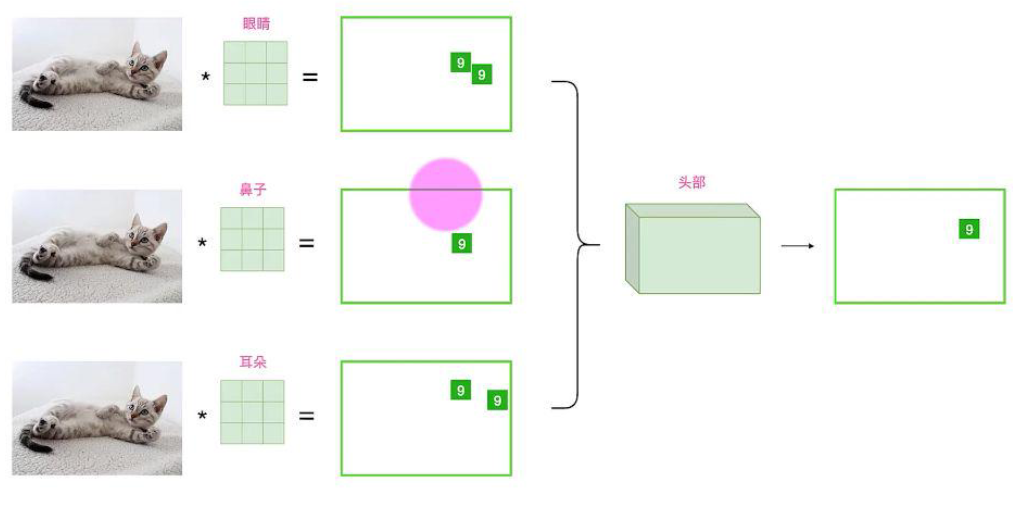
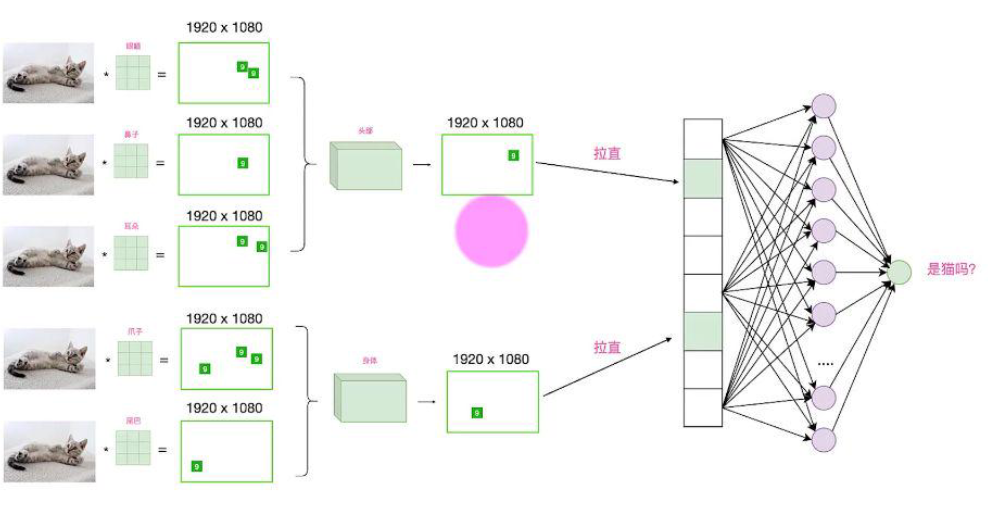
最后将所有的特征进行组合就能判断这个区域是不是猫
激活函数
池化层
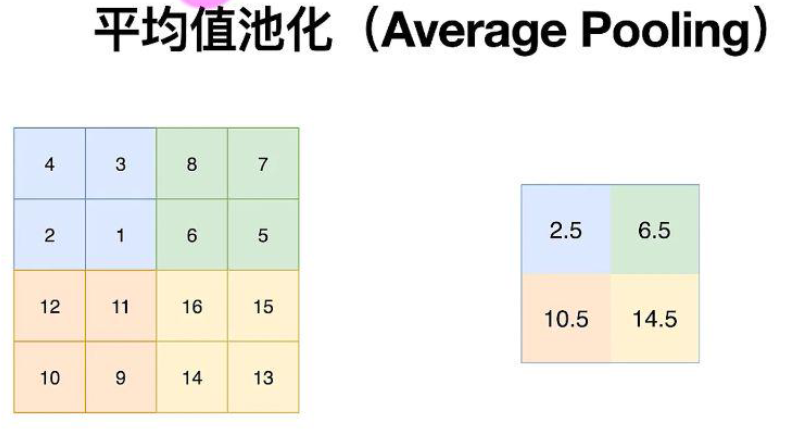
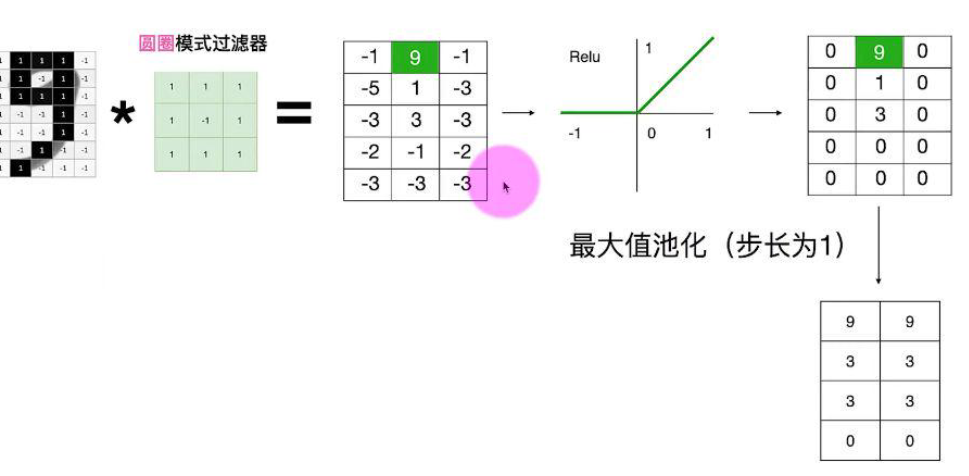
讲完卷积层,接下来说说池化层,池化层的作用是降低图像复杂度,就是减少计算量

设置cnn模型
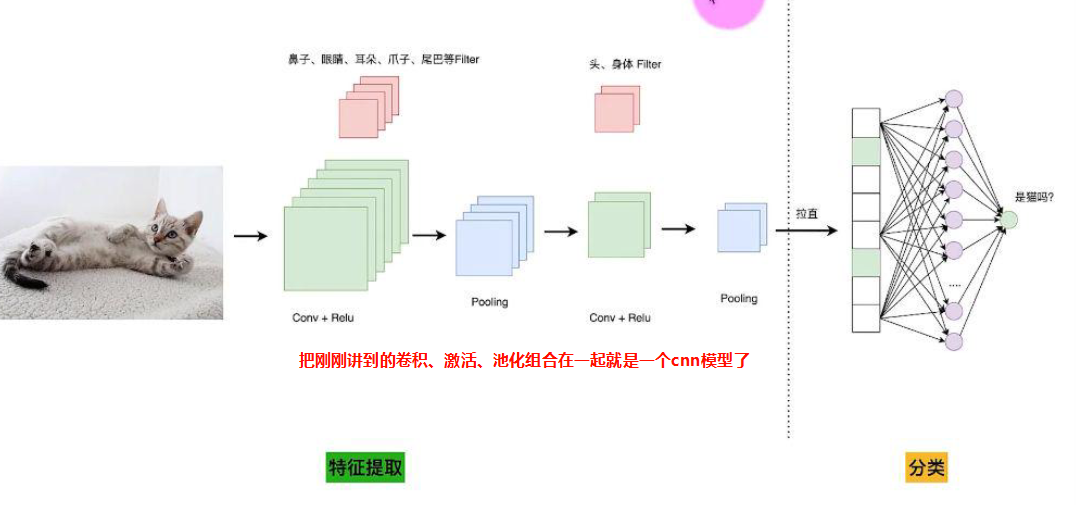
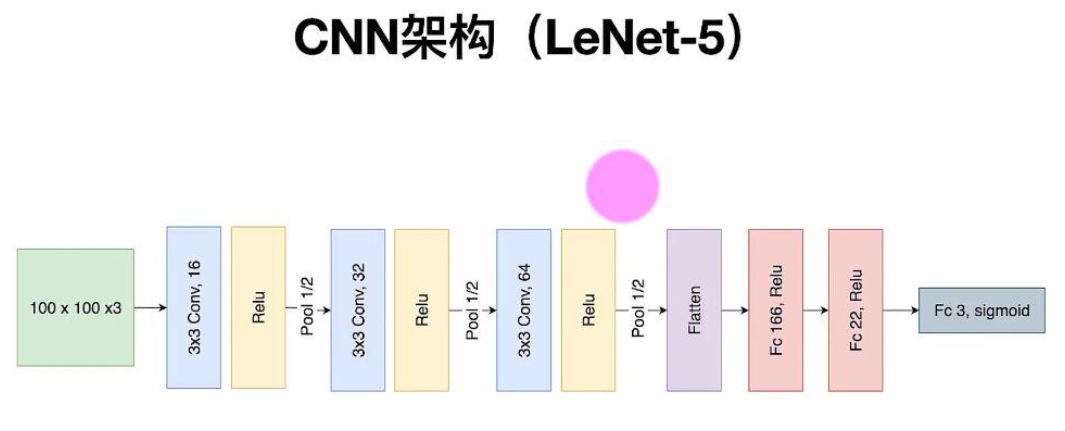
这里我使用的是leNet-5,我们通过这个模型来学习cnn,通过lenet-5的架构可以看出和我们前面设置的卷积、激活、池化好像差不多,只是后面有个flatten、fc166relu、fc22relu、fc3sigmoid,fc是全连接层的意思,flatten是将卷积拉长为一维,但是我们口罩识别只有3个类别,所以拉长为一维和3个类别(正常佩戴、未佩戴、佩戴不标准)不匹配,我们需要用fc金字塔架构进行浓缩,这里用了3个fc最后浓缩到了3个类别。
代码介绍
运行模型训练.py
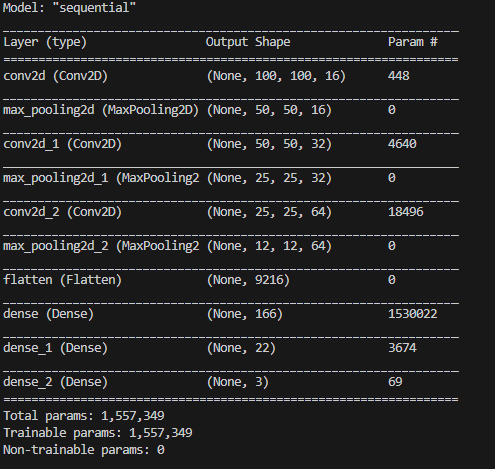
根据程序安装对应的包,最后训练完口罩识别模型
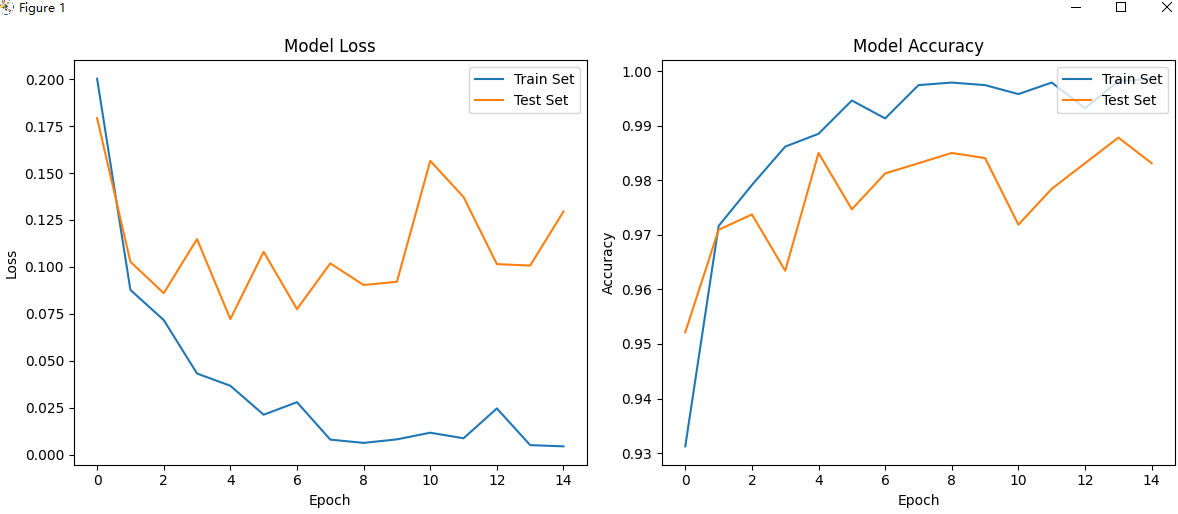
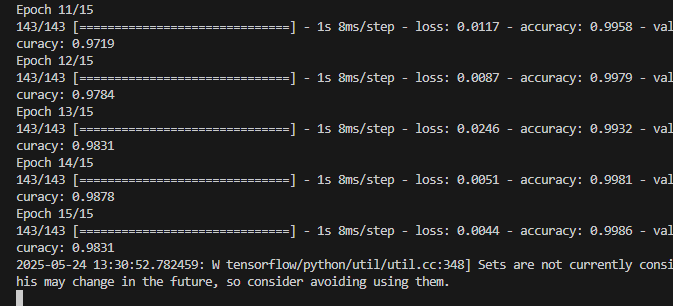
准确率还是挺高的
运行测试模型.py程序
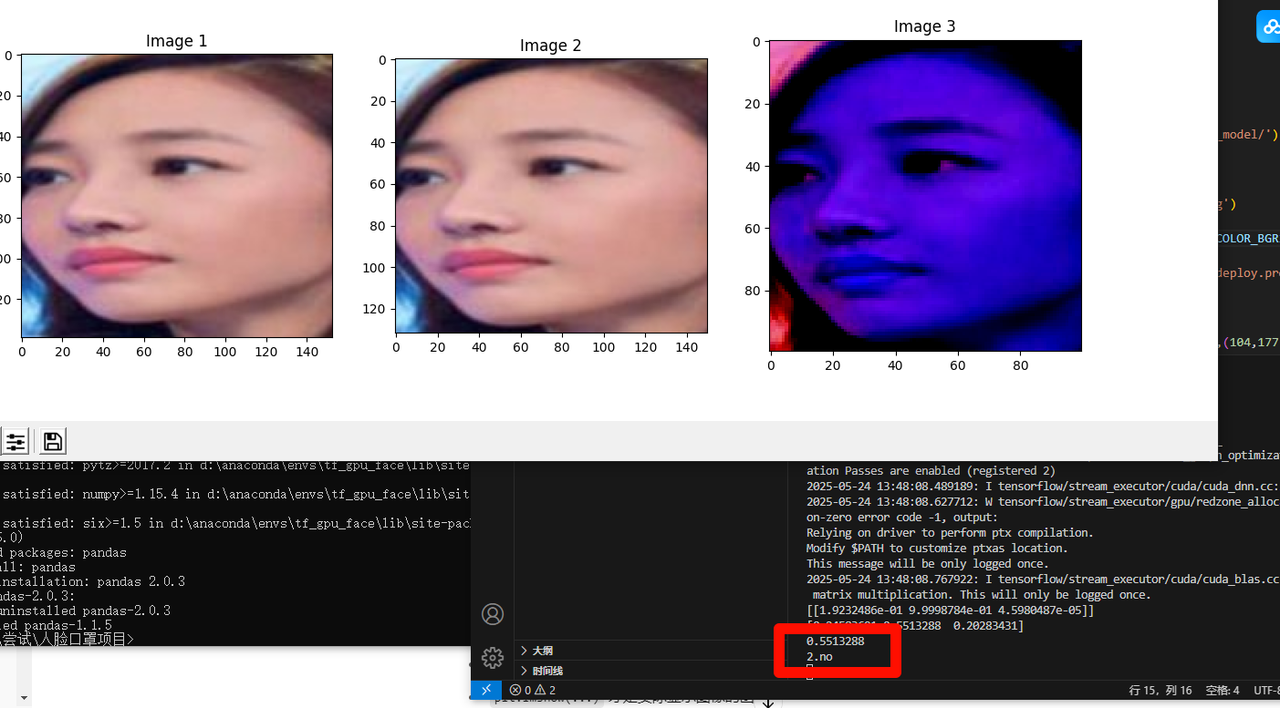
我在窗口打印了类别和识别率
接着运行demo.py,由于视频分辨率问题,识别的效果可能没那么好,你那把输入改成摄像头
cap = cv2.VideoCapture(0)#效果可能会好一点

口罩识别先进行到这里,后续将开发在树莓派上跑口罩识别
树莓派上运行模型
树莓派的安装环境请参考环境安装
先配置好opencv和tflite,估计要花个一天
通过网盘分享的文件:人脸口罩树莓派版.zip
链接: https://pan.baidu.com/s/1kJ9Urta_qNY7nXdGEXk-xw?pwd=47ye 提取码: 47ye
--来自百度网盘超级会员v2的分享
然后就可以把我的demo程序拉到你的树莓派上,然后python3 rasp_fast.py
如果是python rasp_fast.py是会报错的,需要python3运行。
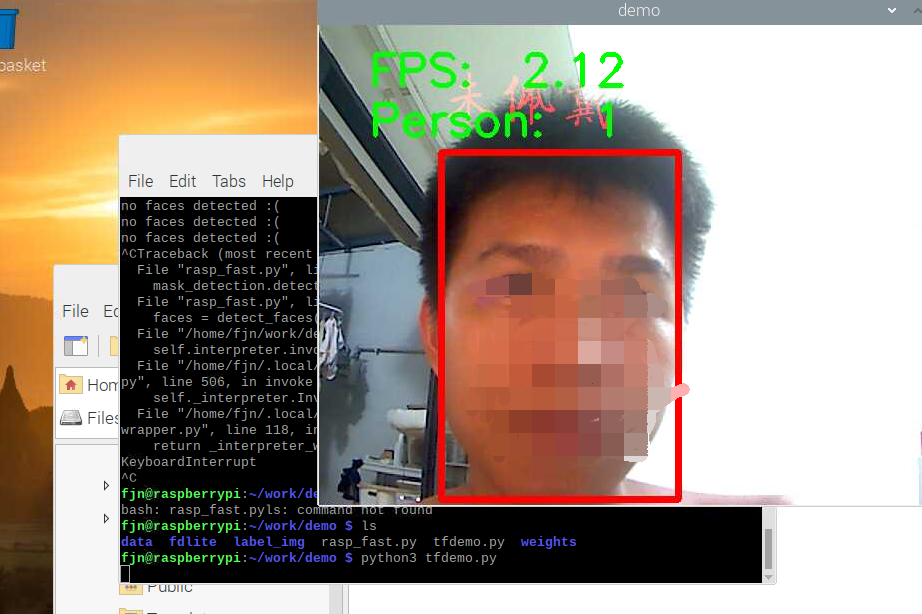
这个是tfdemo.py的运行情况,只有2fps
这个是rasp_fast.py的运行情况,有8fps
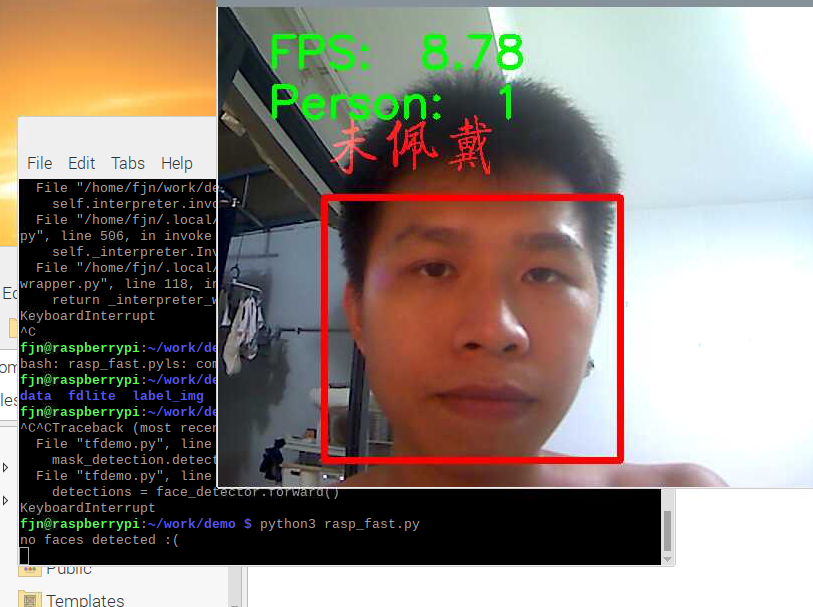
rasp_fast.py:
-
使用的
fdlite采用了轻量级的模型,专门针对边缘设备(如树莓派)设计,因此计算量较小,运行速度更快。
tfdemo.py:
-
OpenCV 的 DNN 模型(如 Caffe 模型)通常较为复杂,需要更多的计算资源。尽管 OpenCV 在大多数平台上很高效,但在像树莓派这样的设备上,复杂的模型可能会导致处理速度变慢。