Linux详谈进程地址空间
目录
第一谈:简单了解
第二谈:与操作系统的联系
内核空间与用户空间
步骤1:用户态代码执行
步骤2:跳转到内核代码
步骤3:内核代码访问用户数据
步骤4:返回到用户态
对于操作系统的本质:基于时钟中断的一个死循环。
CPU
第三谈:二级页表
页框
总结
本篇文章主要是讲解进程地址空间与页表的关系,从简单到复杂,从一开始的简单原理到其各自的设计。
第一谈:简单了解
第一次了解进程地址空间的时候是在学习进程的时候了解到了其是先由物理内存,然后由一个变量而引申出来进程地址空间。
文章连接Linux进程概念-详细版(二)-CSDN博客
然后举了一个例子,大富翁与其孩子的案例。不了解的可以推荐看一下。
对其概念就不多说了,下面说一些比较偏底层的内容。直接开始第二谈。
第二谈:与操作系统的联系
内核空间与用户空间
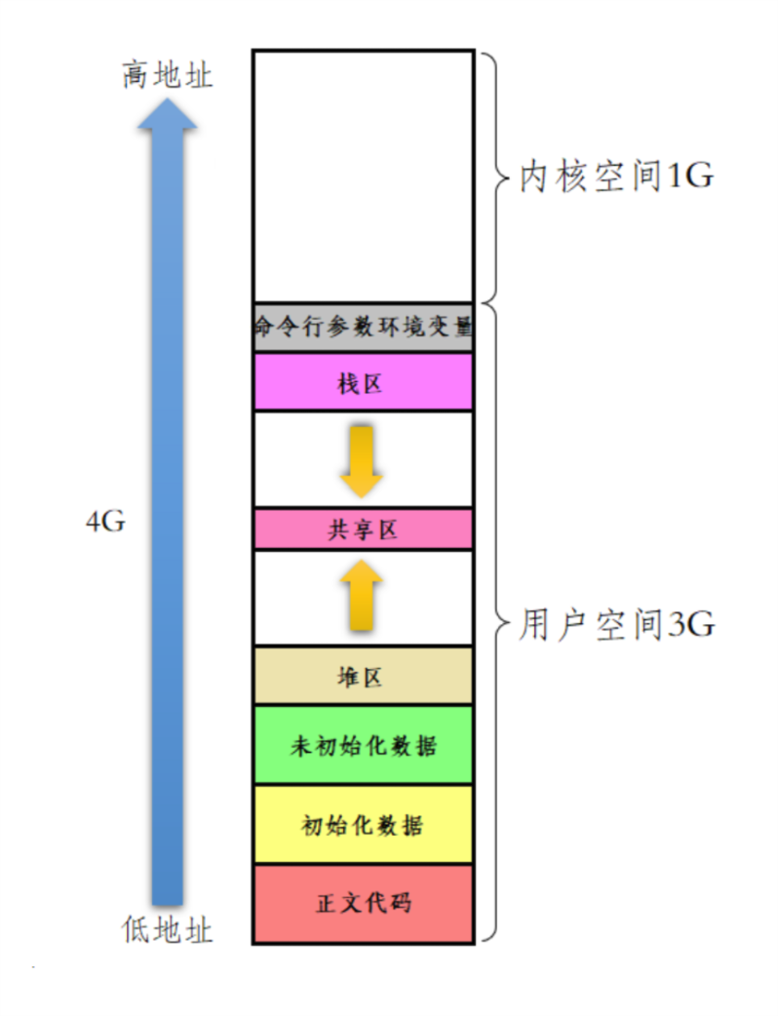
对于本图,大家在详细不过了,但我们一直是在简单的对其下部分的用户空间3G的空间进行谈,下面就对其整体在对其加深理解。
当不同进程的变量显示相同的虚拟地址(如 0x8048000)时,它们实际指向不同的物理内存。这是因为:
-
虚拟地址空间隔离:每个进程拥有独立的虚拟地址空间,由操作系统通过页表实现隔离。
-
页表的作用:进程的页表将虚拟地址映射到物理地址,不同进程的页表使得相同的虚拟地址指向不同的物理页帧。
示例:进程A和进程B的变量
var均位于虚拟地址0x1234,但通过各自的页表映射到物理地址0xAAAA和0xBBBB,互不干扰。
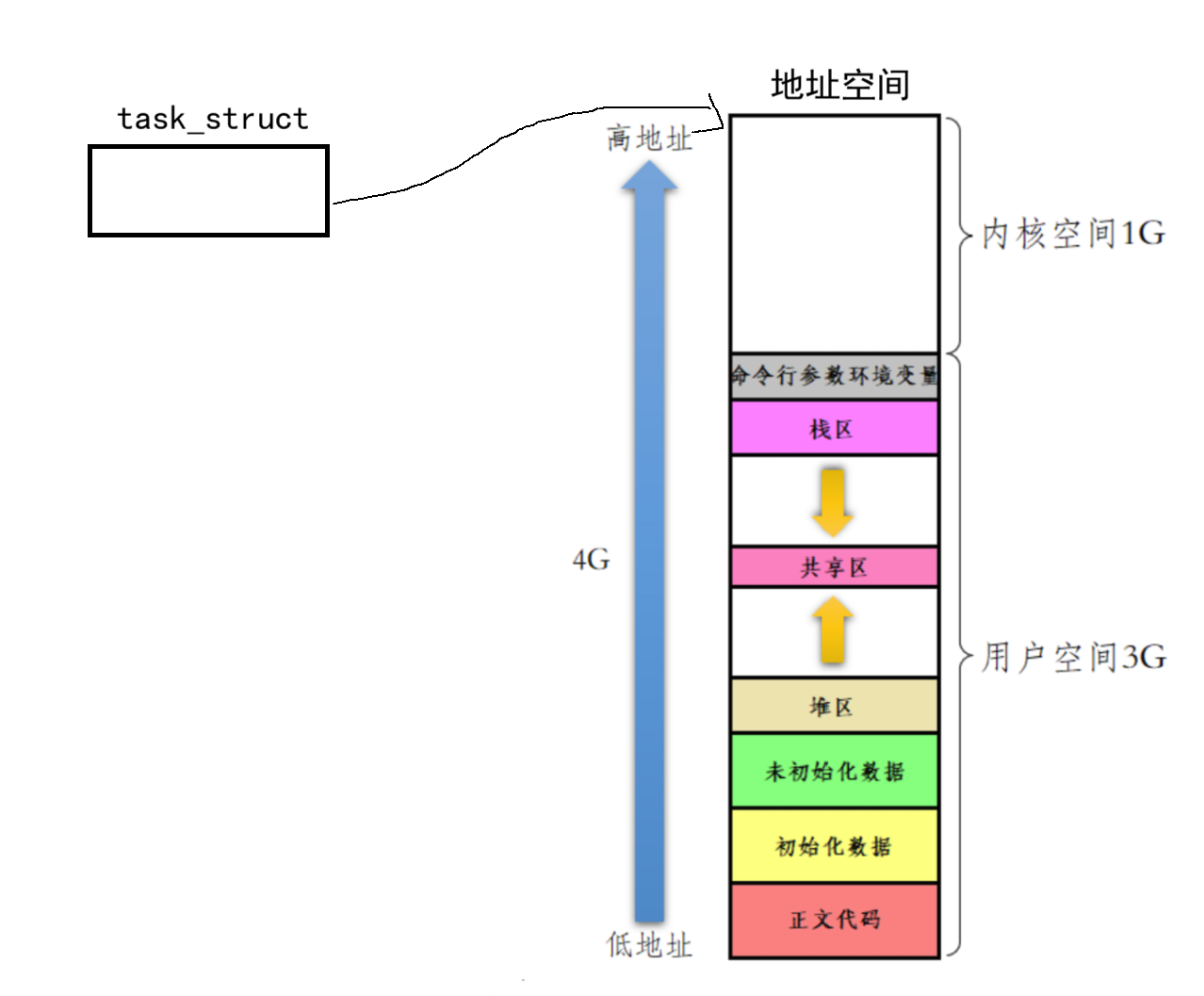
但对于一个进程,其不仅仅有用户级页表,其还存在内核级页表。
但与用户级页表不同的是其并不具有虚拟地址空间隔离,简单的来说就是对于不同进程是没有隔离性的。所有进程共享内核地址空间(如 0xC0000000 以上的高端内存)。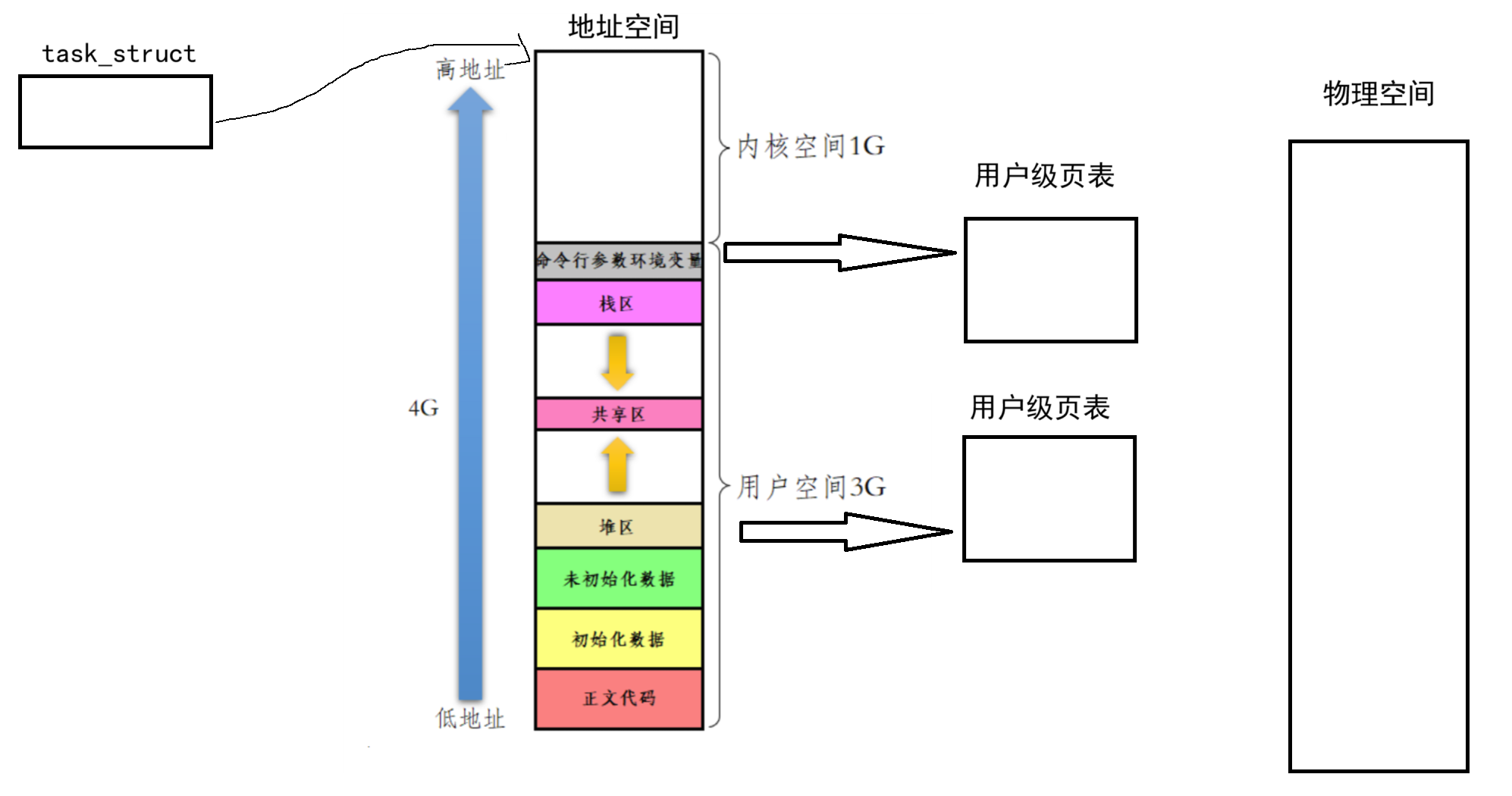
也就是说:在整个系统中
- 有几个进程,那么就有几个用户级页表(因为进程具有独立性)。
- 无论有几个进程,只有一个内核级页表。
- 无论进程怎么切换,进程地址空间的3G-4G的内容是始终不变的。
那么我们把角色换为进程的视角,当进程在调用系统中的方法的时候(如 write() 或 fork())是什么过程呢?(这里不讨论内核态与用户态的转换)
步骤1:用户态代码执行
-
进程A的代码段(用户空间)通过自己的用户级页表,将虚拟地址(如
0x8048000)翻译为物理地址,CPU正常执行指令。 -
当遇到
write系统调用时,CPU会执行一条特殊指令(如int 0x80或syscall),触发软中断。
步骤2:跳转到内核代码
-
关键点:此时CPU仍在进程A的上下文,但需要执行内核代码(如
sys_write)。 -
地址空间切换:
-
CPU通过内核级页表(所有进程共享)将内核代码的虚拟地址(如
0xFFFFFFFF80001000)翻译到物理地址。 -
注意:虽然进程A有自己的用户级页表,但内核代码的虚拟地址在所有进程中是一致的,因此无需切换
CR3寄存器(x86)——内核页表的映射已预先固定在每个进程的页表中(内核空间部分)。
-
步骤3:内核代码访问用户数据
-
内核需要读取进程A的用户空间数据(如
buf的内容):-
内核通过进程A的用户级页表临时翻译用户虚拟地址(
buf)到物理地址。 -
依赖机制:内核虽运行在高特权级,但仍需借用当前进程的页表访问其用户空间数据(否则会触发缺页或权限错误)。
-
步骤4:返回到用户态
-
系统调用结束后,CPU切换回用户态,继续通过进程A的用户级页表执行用户代码。
所以在进程的角度来说,我们在调用系统的方法的时候,其实就是在其自己的地址空间中执行的。
无论什么情况下,都会在第一时间先打开一个进程,那就是操作系统。其也就是说其会在我们计算机启动的第一时间就会将操作系统的代码与数据会第一时间存放在物理空间,那也就是其最小的地址。
所以就保证了,我们任意时刻,只要有想要运行的进程,那么我们就可以随意执行操作系统的代码。
对于直接映射的内核内存(如物理内存管理、设备寄存器),进程可以通过 虚拟地址 - 固定偏移 计算出对应的物理地址。但内核代码和核心数据结构的虚拟地址是固定的,不依赖偏移计算,而是由页表直接映射。
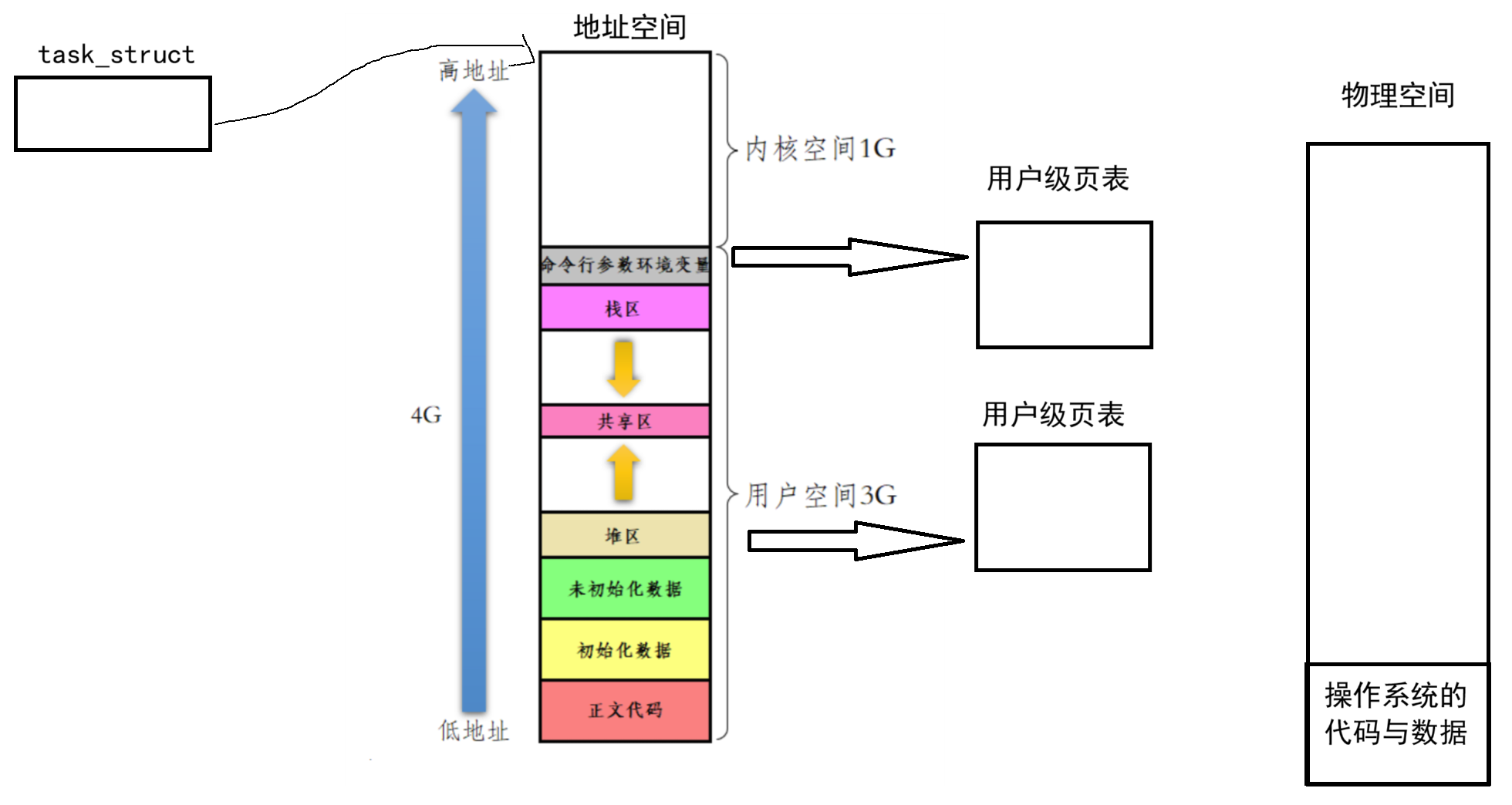
对于操作系统的本质:基于时钟中断的一个死循环。
我们常常把操作系统(OS)想象成一个神秘的黑盒子,管理着CPU、内存、文件、网络……但它的核心,其实只是一个被各种中断唤醒的无限循环。没有中断,操作系统就会“沉睡”;而中断的到来,让它不断做出决策,决定CPU该执行谁、内存该给谁、数据该存到哪里。
今天,我们就来拆解这个“无限循环”,看看操作系统到底是如何运转的。
如果没有时钟中断,操作系统会怎样?
答案很简单:某个进程可能会永远霸占CPU,其他程序饿死。
时钟中断(Timer Interrupt)就像是操作系统的“心跳”,每隔几毫秒(例如Linux默认10ms)就强制打断当前任务,让CPU回到内核。这时,操作系统会:
-
检查是否有更重要的任务要运行(比如交互式进程、高优先级服务)。
-
更新系统时间、统计CPU占用率。
-
决定是否切换进程(时间片用完了吗?有更高优先级的任务吗?)。
“时间片轮转”调度(Round-Robin) 就是基于时钟中断实现的——每个进程分到一小段CPU时间,超时就被换下。
其中有一个时钟芯片的硬件,每隔很短的时间,会向计算机发送时钟中断。
而计算机就可以通过时钟中断的次数,从而计算得出开机时间。
除此之外,还有别的硬件根据同样的道理,保证了即使你的电脑关机一段时间,再次开机,时间还是正确的。但不考虑长时间关机,导致此硬件没电,而导致再次开机时间不对。
在Linux的底层代码也可以看出,其实就是一个for循环。

总结:操作系统的本质
-
一个无限循环:从开机到关机,永不停止。
-
由中断驱动:时钟、系统调用、硬件中断……是它们让操作系统“活”起来。
-
核心任务:调度与管理:决定CPU该执行谁,内存该给谁,数据该存到哪里。
所以,我们将进程加载到内存后,它并不会自动运行,而是由操作系统的调度机制决定何时执行。这是因为操作系统在调度,操作系统也是一个软件,操作系统也不是闲着没事干就去调度别人,其后面还有硬件还在推着操作系统在跑。这就叫做时钟中断。
所以操作系统在启动的时候,其本身也是一个特殊的进程,只不过其就是执行pause,后来呢,时钟中断一来,操作系统就在自己的地址空间找到内核级页表,执行其代码然后开始调度,调度的时候,当前进程在CPU,每隔一段时间,操作系统就会触发一次检测,如果有任务处理了,就进行任务切换。
这个过程就像学校的下课铃——即使老师(进程)还想继续讲课,铃声(时钟中断)一响,CPU就得换人。
CPU
在CPU内,有各种不同的寄存器,比如说CR3寄存器,CR3是x86架构中控制页表基址的关键寄存器。存储内容:当前活跃页表的物理内存地址。现在我们可以理解为它存储的就是当前CPU调度进程页表的物理地址。
这里简单描述一下其切换进程时的工作:
当操作系统决定从进程A切换到进程B时:
保存进程A的CR3值:存入进程A的
task_struct.mm->pgd加载进程B的CR3值:从进程B的
task_struct中取出页表基址写入CR3寄存器:通过
mov cr3, reg指令触发:
立即刷新TLB(Translation Lookaside Buffer)
后续内存访问使用新页表
除此之外还有ecs寄存器。在信号一篇文章中,我们了解Linux系统下的CPU有两种状态:内核态与用户态。但我们指向用户态时,ecs寄存器就会指向用户态执行的代码,当我们处于内核态时,其就会指向内核态执行的代码。而这些都不是最重要的,其该寄存器的低两比特位,我们称之为标志位。该两位共有四种组合方式 00, 01, 10, 11。 其中我们将0表示为内核态,将3表示为用户态。所以但我们想要切换CPU的状态,就首先要将其低两位设置为0/3。这就叫做进入内核态/用户态,就允许你访问其数据,比方说如果当前是3,你想要访问操作系统的代码与数据时,那么操作系统就会拦截,不让你访问。所以总结的来说,当前是在用户态还是内核态还是由CPU的ecs寄存器来说。
所以如果我们要切换状态到内核态,那么一定要用CPU所提供的方法,该方法就是int 80(陷入内核)
当用户程序调用int 0x80时,CPU自动完成以下操作:
1. **权限提升** - 将CS的低2位从`11`(用户态)改为`00`(内核态)- 同时加载内核代码段描述符(__KERNEL_CS)2. **上下文保存** - 用户态SS/ESP压入内核栈- EFLAGS、返回地址(EIP)等自动保存3. **跳转执行** - 从IDT(中断描述符表)获取中断处理函数地址- 开始执行内核代码(如系统调用处理程序)关键硬件行为:
-
CPU会拒绝用户态直接修改CS寄存器(若尝试
mov cs, ax会触发#GP异常),必须通过中断/异常等安全门机制切换。
当然整个过程不是这么简单,其实更为复杂。
除此之外还有内核通过iret指令返回用户态时:
; 内核态准备返回用户态的示例
push 0x23 ; 用户态数据段选择子(低2位=11)
push user_esp ; 用户栈指针
pushf ; EFLAGS
push 0x1b ; 用户态代码段选择子(低2位=11)
push user_eip ; 返回地址
iret ; 硬件自动恢复CPL=3第三谈:二级页表
我们以32位的Linux平台为例。
在32位的平台下,一共有个地址,那么这也就意味着就存在特殊情况页表要对
个地址都要映射。
如果我们单单认为页表就是我们日常想象的一张表,那么我们这张表就要建立这个虚拟地址和物理地址之间的映射关系,即这张表一共有
个映射表项。
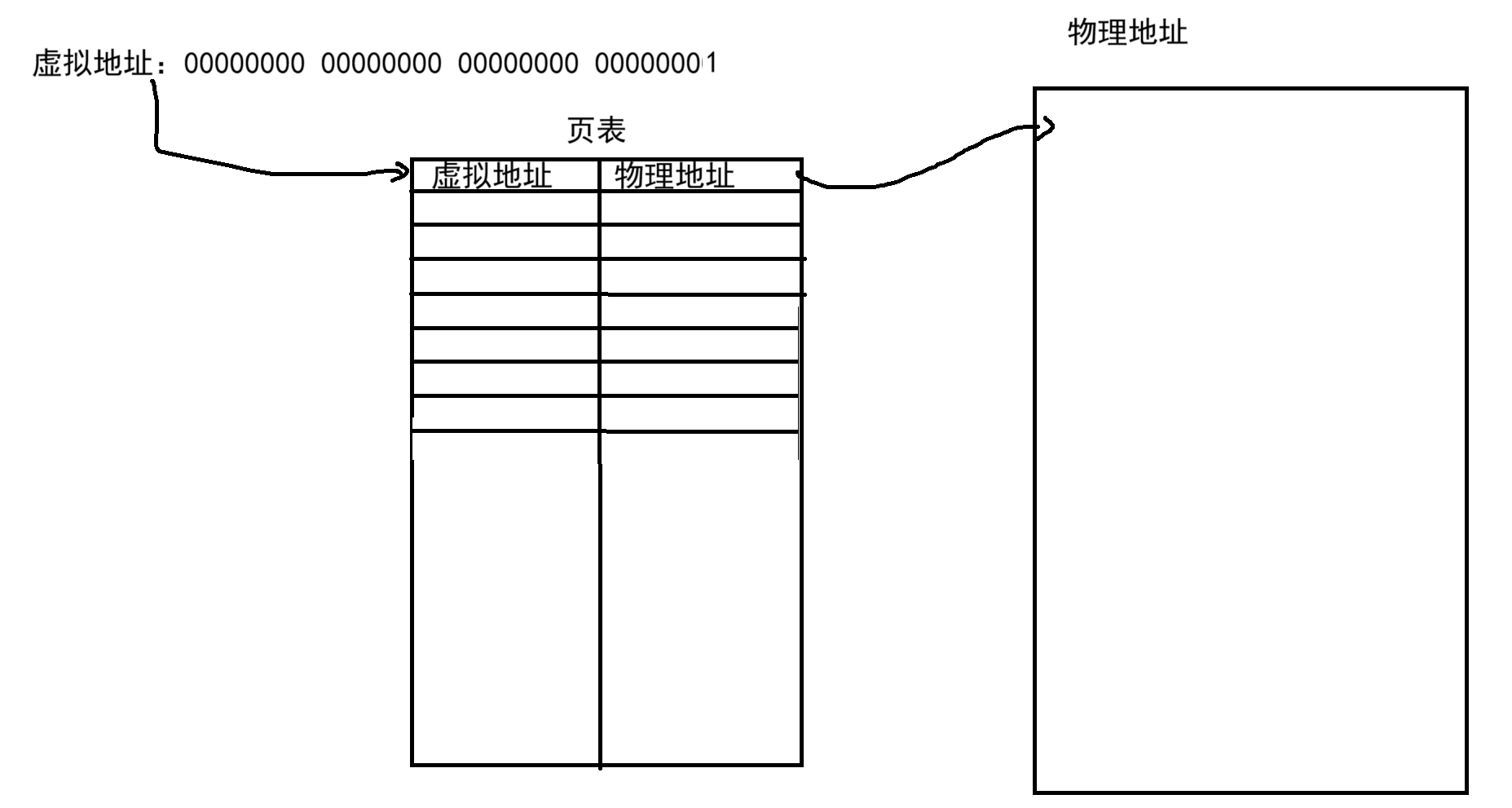
当然除此之外,页表也不单单是只存储两项内容,实际上还存在着一些权限相关的信息,比如说我们所说的用户级页表和内核级页表,实际就是通过权限进行区分的。
注意:虽然我们在介绍用户级页表时画的图是表示内核级页表和用户级页表是物理上完全独立的两套页表,但实际上上并非如此,上面的那样画图仅仅是为了方便理解。
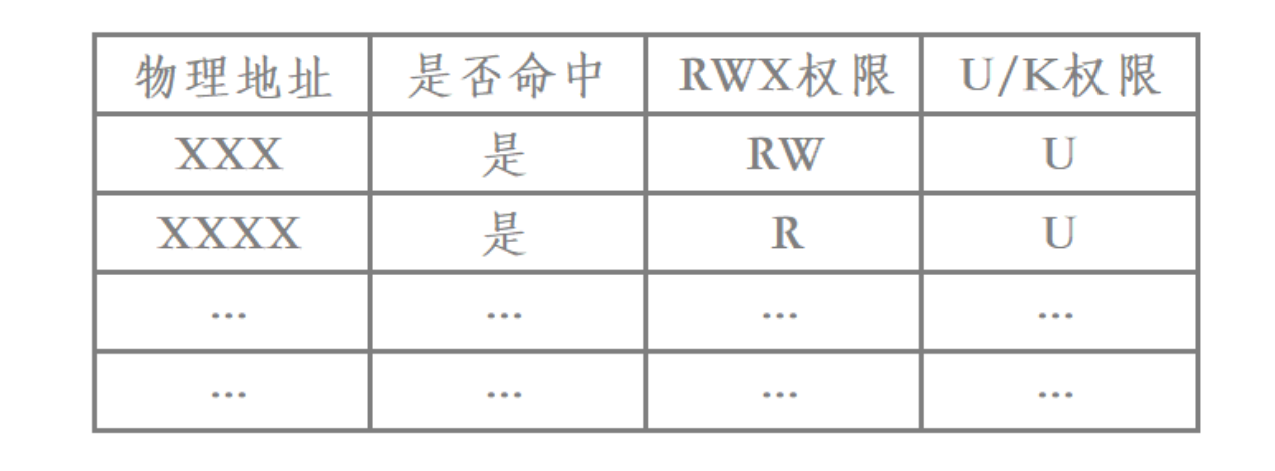
那么一个页表中每一个页表项都至少存储着一个物理地址和一个虚拟地址,到这就至少8字节了,考虑到还需要包含一些权限相关的各种信息,所以说至少要大于10字节。这里为了方便计算就按10字节来计算。
在特殊情况下,就要有个表项,这也就意味着这张页表至少要使用
*10字节。计算下来就是40GB(
=1024,1024字节 = 1KB,1024KB = 1 MB, 1024 MB = 1 GB)。显然这很不合理,在32位平台下我们的内存可能一共就只有4GB,也就是说我们根本无法存储这样的一张页表。
因此所谓的页表并不是单纯的一张表。
页框
这里引入新的概念:页框。
我们在学C语言的时候,就知道了一字节对应一地址,并且每个字节对应唯一的地址。
但物理内存实际上是被划为为一个个4KB大小的页框,而磁盘上的程序也是被划分成一个个4KB大小的页帧的,当内存和磁盘进行数据交换时也就是以4KB大小为单位进行加载和保存的。
所以实际上计算机访问内存并不是以一字节为单位进行访问的,而是以4KB为单位进行访问的,同样页表映射的单位也是以4KB为单位进行映射。
4KB实际上就是个字节,也就是说一个页框中有
个字节,而访问内存的基本大小是1字节,因此一个页框中就有
个地址。
所以在实际上页表需要映射的其实就是1024 * 1024个表项(也就是个)。这样算下来就是: 10 *
字节 = 10 MB,小的多了。到这里肯定会有疑问,但还请保留疑惑,看完下面对二级页表的介绍,就清楚了。
还是以32位平台为例,我们添加新的属性:页目录,页目录就是一个表,其映射的是页表的物理地址,目的就是找到对应的页表。
其页表的映射过程如下:
- 选择虚拟地址的前10个比特位在页目录当中进行查找,找到对应的页表。
- 再选择虚拟地址的10个比特位在对应的页表当中进行查找,找到物理内存中对应页框的起始地址。
- 最后将虚拟地址中剩下的12个比特位作为偏移量从对应页框的起始地址处向后进行偏移,找到物理内存中某一个对应的字节数据。
对于第三步简单说明一下,4KB = 字节,单个页框对应的就是正好4KB,虚拟地址剩下的12位正好对应其偏移量,从页框的起始地址处开始向后进行偏移,从而找到物理内存中某一个对应字节数据。
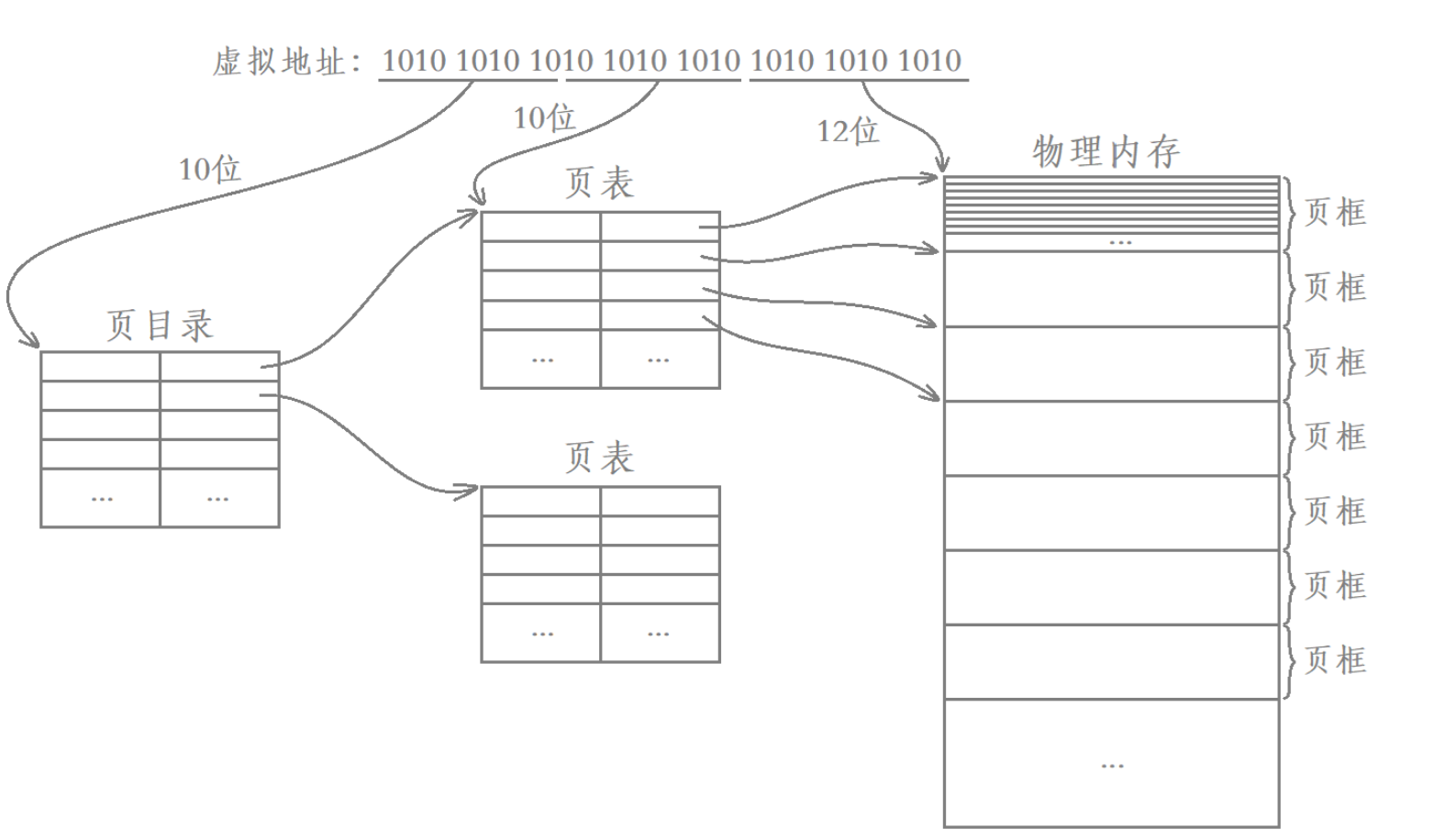
这实际上就是我们所谓的二级页表,其中页目录项是一级页表,页表项是二级页表。刚才我们也计算了,每一个表项按10字节,二级页表要映射 1024 * 1024 个表项,换算下来也就个二级页表,而对应单个进程只有1个一级页表,总共算下来大概就是10MB,内存消耗并不高,因此Linux中实际就是这样映射的。
而二级页表的存在,也就保证了内存可以保证映射完所有的虚拟地址。
上面所说的所有映射过程,都是由MMU(MemoryManagementUnit)这个硬件完成的,该硬件是集成在CPU内的。页表是一种软件映射,MMU是一种硬件映射,所以计算机进行虚拟地址到物理地址的转化采用的是软硬件结合的方式。
同样操作系统还是很聪明的,它会固定给每个进程分配一个一级页表,然后通过特定的操作,统计出大概要分配多少个二级页表,而不是固定分配1024个二级页表,也不是说固定存在1024个二级页表,所有进程共同使用,保证任何情况下都可以映射完4GB物理内存。
所以总结的说:
- 二级页表通常是进程私有的(某些共享内存场景除外)。每个进程的虚拟地址空间独立,其二级页表仅映射该进程的虚拟地址范围,不同进程的二级页表一般不共享(内核空间除外,如内核页表可能被所有进程共享)。
-
二级页表是动态分配的,并非预先分配1024个。只有当进程实际访问的虚拟地址范围需要新的二级页表时,操作系统才会分配物理页并在一级页表中建立映射。
-
理论上,1024个二级页表(每个映射4MB = 1024×4KB)可以覆盖整个4GB虚拟地址空间,但实际几乎不会这样分配。操作系统的设计目标是仅维护实际需要的映射。例如,一个仅占用几十MB的进程,可能只需几十个二级页表。
总结
操作系统通过以下策略优化页表管理:
-
固定分配一级页表(每个进程一个)。
-
动态分配二级页表(按虚拟地址访问需求)。
-
共享物理页(只读代码段、内存映射文件等),但页表结构本身是进程私有的。
-
惰性分配(如缺页中断触发页表项填充)。