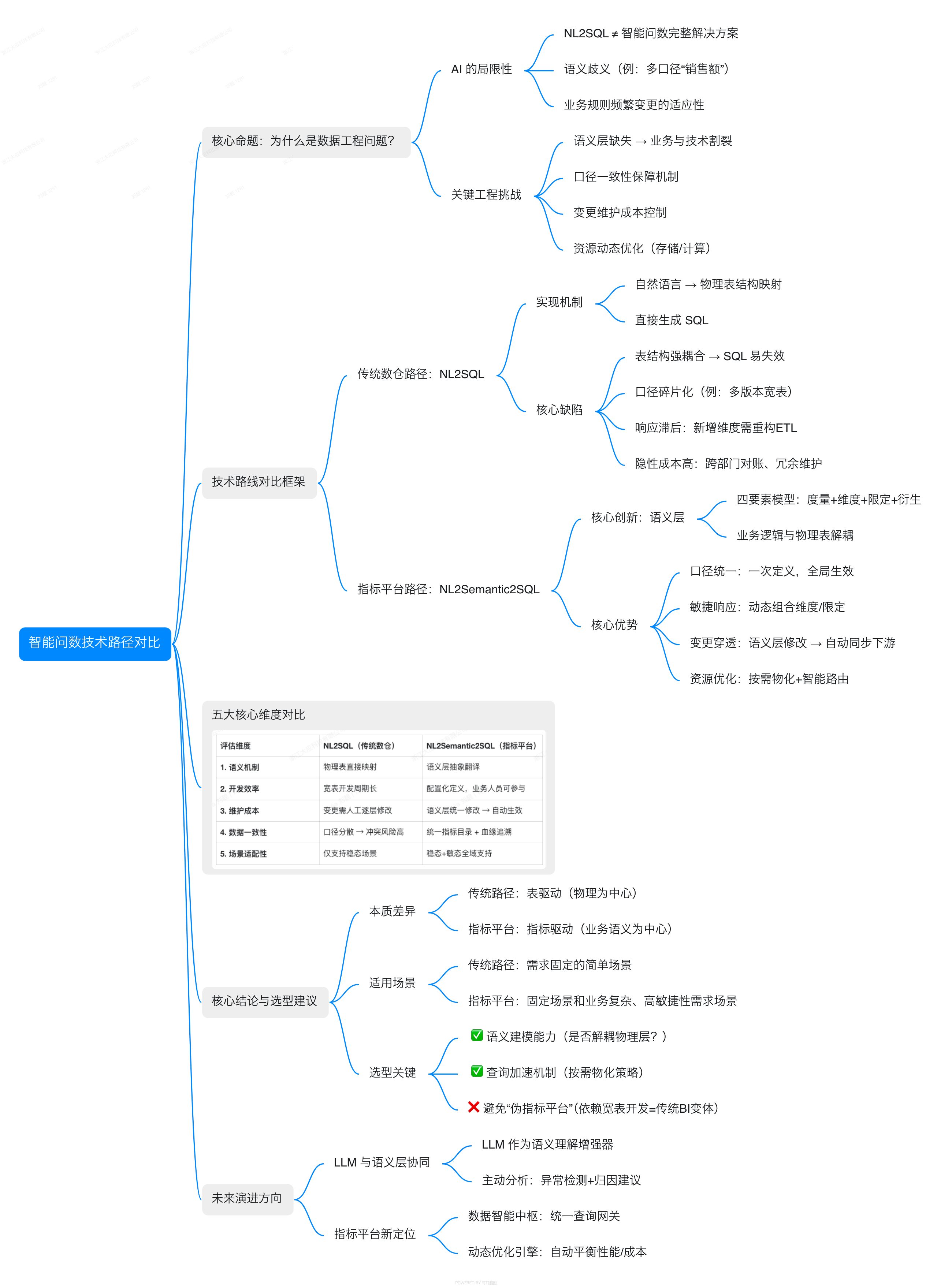
智能问数技术路径对比:NL2SQL vs NL2Semantic2SQL
在人工智能浪潮席卷数据分析领域的当下,“智能问数”凭借其自然语言交互的便捷性,迅速成为企业提升数据民主化与决策效率的焦点。大语言模型(LLM)展现出的强大语言理解和生成能力,无疑为这一愿景启动了引擎。
然而,一个普遍的误解是将智能问数简单地等同于“自然语言转 SQL”(NL2SQL)的 AI 问题——仿佛只要接入一个强大的 LLM,就能让业务人员轻松获得准确、一致且可解释的数据洞察。
现实远非如此理想。智能问数面临的真正瓶颈,往往不在于 LLM 理解自然语言本身的能力,而深藏于其背后庞大而复杂的数据基础设施之中。如何将用户模糊、多变的业务意图(“上季度华东地区高价值客户的净销售额趋势如何?”)精准、高效地映射到企业纷繁复杂的物理数据资产中?如何确保不同用户在不同场景下问到同一指标时能返回一致的结果?如何在业务规则频繁迭代时,避免牵一发而动全身的维护噩梦?如何在满足实时性需求的同时,平衡海量数据查询带来的资源开销?
这些问题的本质,是数据工程问题,而非单纯的 AI 问题。员工在工作中遇到的数据“找不到”和“取不出”的问题,Agent 一样会遇到。
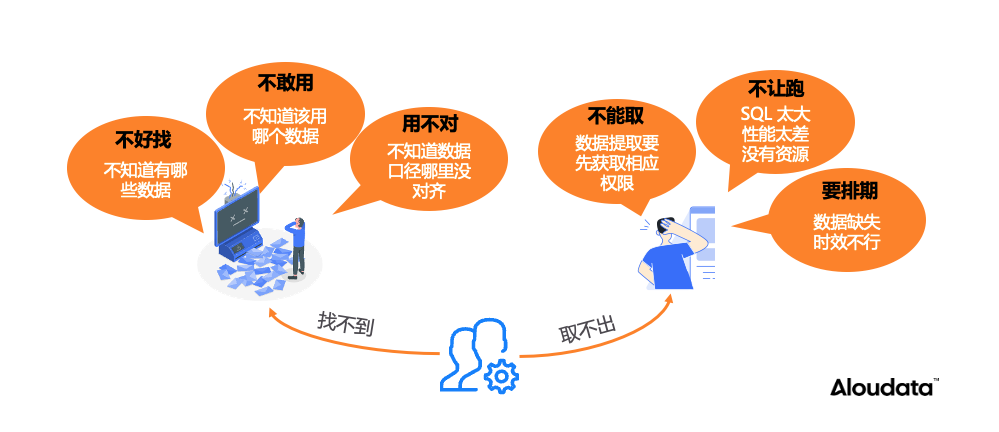
因此,智能问数系统的成败,高度依赖于其底层数据架构是否具备:
1、统一的业务语义抽象层,作为机器和业务人员共同理解的“数据语言”;
2、强大的元数据管理与血缘追踪,确保指标定义的唯一性、透明性和可追溯性;
3、灵活高效的查询生成与优化机制,智能地将用户意图转化为最优(或次优)的物理查询执行计划,有效平衡性能与成本;
4、敏捷的变更管理与影响控制,最小化变更成本,确保下游查询的持续可用性和准确性。
因此,本文的核心并非仅仅探讨 LLM 在自然语言转换中的技巧,而是深入剖析支撑智能问数落地的两种关键数据工程技术路径:基于传统物理数仓的 NL2SQL 方案与基于指标平台的 NL2Semantic2SQL / NL2MQL2SQL(MQL:Metrics Query Language)方案。
我们将重点揭示,后者如何通过构建强大的“语义层”这一数据工程核心组件,系统性解决上述挑战,为企业实现真正可用、可信、可持续的智能问数能力提供坚实的数据工程基础。理解这两种路径的差异,对于企业在数智化转型中做出明智的技术选型至关重要。
一、语义理解与转换机制的差异
NL2SQL 技术路线直接基于物理表结构进行自然语言到 SQL 的转换。这种机制依赖于对表名、字段名和表间关联关系的精确映射,将用户意图直接转化为数据库查询语言。由于语义与物理表紧耦合,当表结构发生变化时,已有的 SQL 查询可能失效,需要重新调整。这种直接映射的方式虽然实现了快速查询,但在处理复杂业务逻辑时存在局限性。例如,同一个“销售额”指标可能在不同业务场景下有不同的计算口径(如是否包含退货、是否考虑汇率因素等),而 NL2SQL 往往需要为每种口径单独建模/建表或编写不同的 SQL 语句,增加了维护复杂度。
相比之下,NL2Semantic2SQL 技术路线引入了语义层作为中间抽象。指标平台通过将数据封装为“度量”和“维度”两大要素,并利用“基础度量”、“业务限定”、“时间限定”和“衍生方式”四大要素来灵活定义和组合出具有明确业务含义的指标,构建了一个统一的语义模型。自然语言查询首先被转换为语义表示,再由系统根据语义模型生成最优 SQL 查询。这种语义与表的解耦设计使系统能够理解指标的业务含义而非仅表结构,从而保证了不同场景下同一指标口径的一致性。当业务规则变化时,只需修改语义定义,而无需调整所有相关表或查询,大大提高了系统的灵活性和适应性。
语义层的引入是 NL2Semantic2SQL 相比 NL2SQL 的核心优势,它不仅提升了查询的准确性,还增强了系统的可解释性和业务人员的自助能力。通过构建统一的业务语义模型,指标平台能够跨越技术与业务之间的鸿沟,使业务人员能够直接理解和使用数据,而无需深入掌握 SQL 语法。
二、开发效率与维护成本的对比
基于传统物理数仓的 NL2SQL 路线在应对业务变化时,常常面临开发效率、数据质量与维护成本难以兼顾的挑战。在开发效率方面,每当业务需求变化或新增维度时,都需要 IT 工程师重新排期开发宽表或汇总表,流程长且响应慢。例如,管理层驾驶舱中若需新增一个维度,传统方式通常需要回到数仓重新开发(涉及 ETL、建模、测试、发布等环节),流程冗长,响应滞后,严重影响业务决策时效性。此外,不同业务部门可能独立开发相同指标的不同版本,导致重复建设,占用大量存储计算资源。
基于指标平台的 NL2Semantic2SQL 路线则通过语义化封装和自动化能力,显著提升了开发效率并降低了维护成本。在开发阶段,指标平台通过配置化界面(如模板点选、表达式编辑器)降低了定义指标的技术门槛,使分析师和具备一定数据知识的业务人员也能参与或主导指标的创建和维护,减少对 IT 工程师的依赖,提升业务用数的自主性。基于预定义的语义模型(包含指标的业务逻辑和表间关联关系),系统能够解析用户查询的语义,并自动生成正确的 SQL,避免了人工开发的繁琐过程。同一指标的不同维度只需进行一次性定义,便可在下游所有应用中复用,避免了重复开发。
在维护成本方面,指标平台的自动化物化加速机制大大减少了人工操作负担。数据工程师可以预先指定需要加速的指标、维度组合、加速方式(如明细加速、汇总加速、结果加速)以及数据更新策略(如上游更新后 API 通知、定时更新、周期更新或手动更新)。系统根据这些配置,自动完成物化视图的创建、更新任务编排与生命周期管理。这种基于配置的自动化机制,有效降低了人工维护成本,并在既定策略下优化了存储和计算资源的使用。
此外,语义层统一管理指标口径,避免了因逻辑分散在多个物理表或 ETL 脚本中而产生的维护负担。当业务规则变化时,只需在语义层更新指标定义,平台将自动根据新规则重构生成查询 SQL,并在变更发布前自动提示所有下游影响(含下游指标和加速方案),确保变更维护没有遗漏。所有依赖该指标的下游查询和应用将自动获取更新后的计算结果,确保了口径的一致性和准确性。
传统数仓虽然初期开发简单,但长期会因口径冲突和表冗余导致隐性成本快速上升。例如,跨部门数据对账、ETL 任务维护、表结构变更的逐层更新等,都需要投入大量人力物力。而指标平台虽需前期投入建立标准化语义模型,但长期来看可显著降低重复开发和维护成本,实现了“一次定义、处处使用”、“一次变更,处处生效”的价值主张。
三、数据一致性与口径管控的机制差异
数据一致性与口径管控是数据分析领域的核心挑战。传统物理数仓的 NL2SQL 路线由于依赖人工 ETL 开发宽表和汇总表,导致指标定义分散在不同表中,口径难以统一。例如,“GMV”这一关键指标可能在不同部门、不同场景下有不同定义(如是否包含优惠券、是否考虑退款订单等),当各部门向管理层汇报时,可能出现数据矛盾,导致决策失误。
指标平台的 NL2Semantic2SQL 路线通过语义层标准化沉淀指标逻辑,从根本上解决了口径冲突问题。指标平台通过预定义的“基础度量”作为核心,并结合可选的“业务限定”、“时间限定”以及“衍生方式”等要素来灵活组合定义指标,并在语义层中强制统一管理和发布。 例如,“销售额”指标可定义为“订单金额”这个基础度量。用户或分析师在查询时,可以通过语义层提供的“业务限定”(如选择排除退款订单作为“有效订单”的限定)和“时间限定”(如选择“2025 年 Q1”)来动态组合查询。而“订单金额”本身及其关联的业务限定逻辑,在语义层中被标准化定义和存储,确保了无论查询时如何组合限定条件,核心计算逻辑都保持一致。
在管控机制方面,指标平台提供了统一的指标目录,实现指标口径的统一沉淀,使用户能够在其中快速查找和消费他们需要的指标。同时,平台提供指标定义的详细依赖关系和指标的多版本管理,实现了指标加工逻辑的全链路透明化,并保存指标历史变更记录,便于追溯和审计。此外,系统通过解析语义层中预定义的指标计算逻辑,能够清晰呈现指标间的依赖关系,有效避免重复建设和口径不一致的问题。
传统数仓则依赖人工协调和文档管理来确保数据一致性,这种方式不仅效率低下,还容易出现人为错误和遗漏。例如,当底层订单表发生结构变更(如字段重命名或表拆分)时,工程师需要人工逐层排查并修改所有直接依赖该物理表的 ETL 脚本、汇总表、视图以及最终报表中的 SQL 查询逻辑。这个过程极易遗漏依赖项,且修改点分散,维护成本高、风险大。
在指标平台中,虽然语义层同样需要更新以适应底层表变更(例如重新映射字段或调整表关联),但其集中化的元数据管理大幅简化了这一过程:
1、依赖影响分析:平台可基于语义层血缘,快速定位所有受影响的核心指标、业务限定和衍生逻辑,无需人工搜索;
2、统一修改入口:工程师只需在语义层集中调整表/字段的映射关系或计算逻辑,无需修改下游应用代码;
3、自动 SQL 更新:语义层修改后,所有基于该层生成的查询 SQL 将自动适配新表结构,确保下游查询立即恢复正常。
这种机制显著降低了变更的影响范围、定位成本和实施风险,从整体上提升了架构的适应性和治理效率。
四、资源成本平衡与应用场景适配性
在资源成本平衡方面,两种技术路线各有侧重。
传统物理数仓通过反范式化设计减少了 JOIN 操作,提高了查询性能,但以牺牲存储空间为代价,导致数据冗余,增加了存储成本和 ETL 维护成本。例如,同一个维度信息可能在多个宽表中重复存储,造成资源浪费。此外,ETL 过程需要持续维护大量宽表和汇总表,随着数据量增长,存储和计算成本将进一步上升。
指标平台则通过逻辑模型复用底层明细表,按需物化视图,在存储上减少了冗余。例如,大数据量和高频查询可通过配置进行物化,而小数据量和低频查询则直接基于明细数据计算,避免了不必要的存储消耗。系统自动对查询请求进行命中判断和路由改写,充分提升了物化视图的复用性,避免了物理表数量的无序膨胀。
传统数仓的 NL2SQL 路线依赖预定义宽表,仅能较好支持需求固定的稳态场景(如固定周期报表)。当面对业务部门的临时分析、多维快速切换等敏态需求时,需重新开发宽表或即席查询接口,导致响应延迟。
指标平台的 NL2Semantic2SQL 路线通过统一语义层,天然适配全场景分析需求:
1、稳态场景: 预配置的物化加速策略可保障报表级性能(如管理层驾驶舱);
2、敏态场景: 业务人员通过语义层直接动态组合维度与限定条件,无需 IT 介入即可实现实时探索(如运营多维分析);
3、全域一致性: 无论稳态还是敏态查询,均基于同一套语义化指标定义生成 SQL,彻底规避因场景割裂导致的口径偏差。
同时,平台支持复杂指标定义(如跨域关联计算),并通过统一的语义模型确保结果准确。在亿级数据分析中,基于规则的物化加速机制可针对性优化性能,而传统数仓需人工设计宽表,灵活性和时效性不足。
指标平台实现了从 “分场景物理开发”(表驱动)到“全域逻辑定义” (指标驱动)的范式升级,使数据开发更聚焦于业务价值而非技术实现:
● 技术侧: 将反范式的物理建模转换为范式的语义建模,平衡查询性能与存储成本;
● 业务侧: 将开发焦点从“表结构维护”转向“指标价值呈现”,通过单一可信源支撑稳态报表与敏态探索,从根源上解决口径统一难题;
● 治理侧: 变更只需语义层一次修改,即可同步生效于所有场景,大幅降低协作复杂度。
这为企业的数智化转型提供了兼具高效性、灵活性及一致性的数据基础设施。
五、技术路线融合与未来发展趋势
随着智能问数推动企业数据需求进一步向实时化、场景化演进,以指标平台为核心的 NL2Semantic2SQL 技术路线正成为主流范式。其通过语义层统一业务逻辑、自动化生成查询的能力,在保障口径一致性的同时,天然适配稳态与敏态全场景需求。未来技术演进将围绕以下方向深化:
1、大语言模型与语义层的深度协同大语言模型(LLM)不再是简单的 NL2SQL 转换器,而是与语义层形成双向增强:
○ 语义理解精准化:LLM 基于标准化的指标、维度、限定词元数据,更准确解析用户意图;
○ 主动分析智能化:结合语义层业务规则,LLM 可主动识别数据异常、归因波动、推荐下钻路径;
○ 决策支持场景化:基于指标血缘和业务上下文,生成可解释的分析结论与决策建议。
2、架构定位:从“可选组件”到“核心中枢”指标平台将演进为企业数据智能的神经中枢:
○ 统一语义枢纽:所有分析请求(无论来自 LLM、BI 工具或 API)均通过语义层生成可信 SQL;
○ 动态优化引擎:根据查询模式自动调整物化策略,平衡性能与成本;
○ 变更控制中心:业务规则迭代只需语义层一次修改,全链路查询自动同步更新。
总结来看,传统 NL2SQL 依赖人工宽表的模式,因维护成本高、口径碎片化难以适应敏捷需求。而基于指标平台的 NL2Semantic2SQL 路线代表了数据分析领域的进化方向,它通过语义层解耦物理表结构与业务逻辑,破解了"效率-质量-成本"三角困境,成为数据规模大、业务复杂度高企业的首选架构,并逐步向中小场景渗透。指标平台与 LLM 的深度集成将进一步释放其价值,推动企业从“被动查询”转向“主动数据智能”。
从落地实践的角度,我们建议企业将语义层建设视为数智化基础设施的核心,优先构建高可用的指标平台。初期可保留部分宽表用于极端性能场景,但需通过语义层统一映射,避免口径分裂。当语义层建设相对完备之后,再结合 LLM 的能力构建准确、全面、智能的数据分析智能体。
从指标平台选型的角度,我们推荐企业重点考察指标平台语义建模能力与查询加速能力,确保可以真正基于 DWD 层明细数据实现反范式的语义建模,这样才能真正避免传统宽表开发导致的各种问题。依然依赖数仓宽表开发的指标平台,同基于 BI 数据集和报表的 Chat BI 方案无本质区别,无法为智能问数场景提供准确、完整、快速的数据查询体验。
以下是为这篇技术博客设计的思维导图,供简要回顾。