字节流操作:InputStream类 读取文件的操作(三种 read 方法)
字节流操作:InputStream类 和 OutputStream类
文章目录
- 字节流操作:InputStream类 和 OutputStream类
- 观前提醒:
- InputStream类 读取文件的操作(三种 read 方法)
- 1. 不带参数的 read( )方法,返回值是:int 类型
- 例子1(以英文字符为例):
- 例子2(以中文字符为例):
- 总结:
- 2. 带 byte[ ] 参数的 read( )方法,返回值是:int
- 此方法的注意事项:
- 输出型参数:
- 带 byte[ ] 参数的 read( )方法的读取演示:
- 3. 带 三个参数的 read( )方法,返回值是:int
- 演示:
- 4. 读取文件的操作(三种 read方法)的简单总结
- 总结:
观前提醒:
这篇博客是从 Java 文件操作 和 IO(3)-- Java文件内容操作(1)-- 字节流操作 这篇博客分离出来的,目的是减少博客字数。
如果你是第一次点击进来的,需要你将上面这个博客,阅读到这篇博客的连接,再点击进来看这篇文章。
InputStream类 读取文件的操作(三种 read 方法)
读取文件的最核心方法,就是:read方法
对于 InputStream类 ,Java提供了三种 read方法:
1. 不带参数的 read( )方法,返回值是:int 类型

这个方法的作用是:调用一次,读取一个字节。
关于返回值的解释:返回的是int,不是 byte,当返回值为 -1 时,表示文件已经读取完毕。
例子1(以英文字符为例):
现在在我本人的java项目路径当中,存在 test.txt 文件,文件当中,写的是 hello ,现在我使用循环,使用字节读取的方式,将里面的内容读取出来:
演示代码:
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;public class demo1 {public static void main(String[] args) throws IOException {try(InputStream inputStream = new FileInputStream("./test.txt")) {// 读取文件操作:while (true) {int data = inputStream.read();// 返回 -1 ,说明文件内容已经读取完毕if (data == -1) {break;}System.out.println(data);}}}
}
运行结果演示:
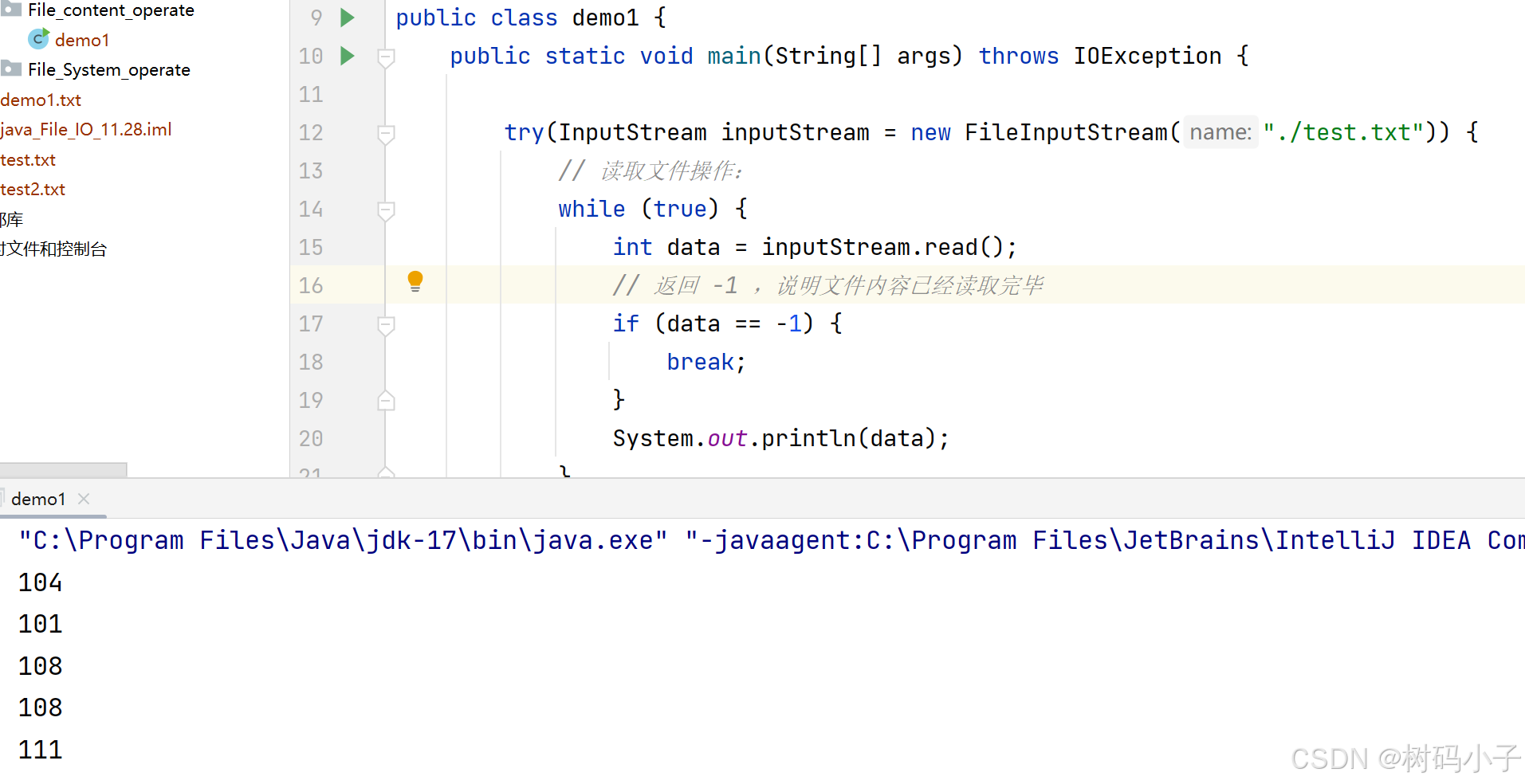
相信你读到这样的结果,肯定会有疑惑:不是哥们,我文件里明明写的是 hello 啊,怎么给我输出的是 104,101… …这样的数字呢?
原因的话,就是说:我们这里是按照 字节的方式进行读取的,同时根据程序代码,是一个一个字节读取出来,分别进行打印的,而每个字节的范围,是:0 ~ 255。
hello 是由五个英文字母构成的,一个英文字母在计算机中的存储大小为1个字节(byte)。所以,每个英文字母有对应的一个字节码,所以显示出来的就是五个字节码(数字)。
而 hello 是纯英文的方式,是根据 ASCII码 进行编码的。我们可以查一下 ASCII码表,看看 h 在其中的表示:
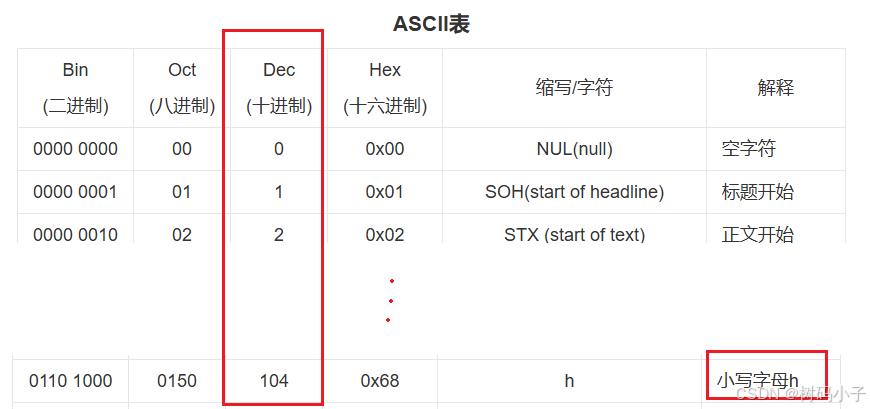
至于其他的,你可以自己去 百度 搜查 ASCII码表,然后对照一下,运行结果中的那5个十进制数字,就正好是 hello 的对应的 ASCII码。
特别提醒一下:
10 进制是正常的
8 进制是 0 开头的
16 进制是 0x 开头的
例子2(以中文字符为例):
现在在我本人的java项目路径当中,存在 test.txt 文件,文件当中,写的是 “你好” ,现在我使用循环,使用字节读取的方式,将里面的内容读取出来:
演示代码,还是例子1 的那个代码:
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;public class demo1 {public static void main(String[] args) throws IOException {try(InputStream inputStream = new FileInputStream("./test.txt")) {// 读取文件操作:while (true) {int data = inputStream.read();// 返回 -1 ,说明文件内容已经读取完毕if (data == -1) {break;}System.out.println(data);}}}
}
运行结果:
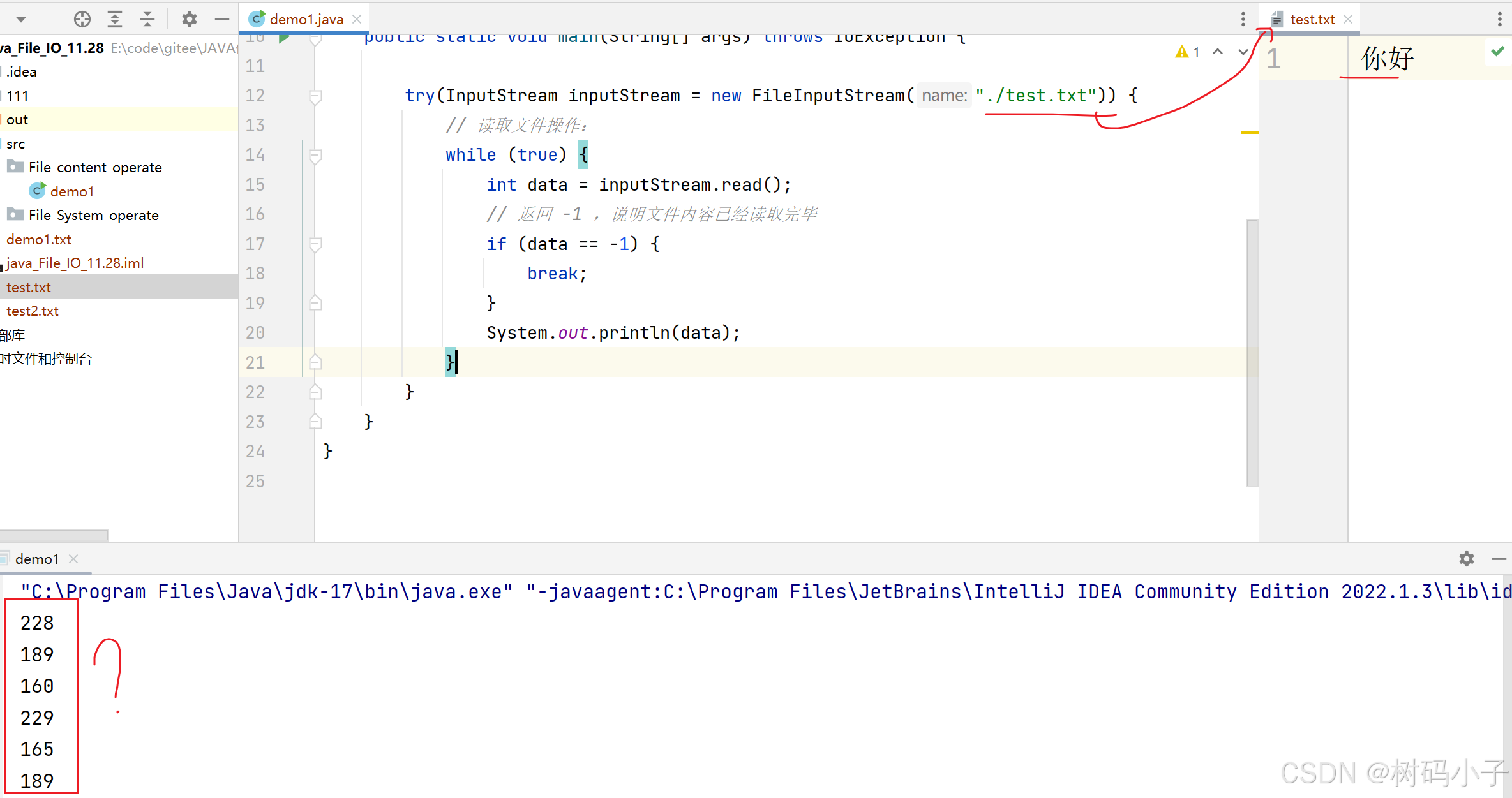
这里显示的有 6 个字节,而我的文件里面写的只有 2 个汉字,所以,可以知道, 1 个汉字占 3 个字节。
一个汉字占三个字节,是属于 utf-8 的编码集。
我们可以看看 utf-8 的码表,去对比一下。
通过这个网站:查看字符码表 UTF-8,可以查看到 utf-8 码表中,对应汉字的字节码构成。
在码表,输入 你好 ,进行查询,结果:

三个字节是放到一起的,不是分开的显示,不是像我们程序当中,是分开显示的,所以,不好观察。我们可以使用 16 进制,进行打印,然后对比。
十六进制,一个十六进制数字,表示 4 个 bit(比特位),两个十六进制的数字,表示 8 个bit(比特位),就是 1 个字节。
那么,问题来了:Java里面,怎么打印 十六进制?
答:使用 C语言当中的 printf( ),%x 或者 %X 表示的是十六进制的占位符。这两个占位符,也是有区别的。
%x :小写的字母 x,表示输出出来的十六进制数中,英文字符,全部都以小写形式出现
%X:大写的字母 X,表示输出出来的十六进制数中,英文字符,全部都以大写形式出现
为了与网站上查到的字符的十六进制相等,我们下面就是用 %X 来进行演示结果:
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;public class demo1 {public static void main(String[] args) throws IOException {try(InputStream inputStream = new FileInputStream("./test.txt")) {// 读取文件操作:while (true) {int data = inputStream.read();// 返回 -1 ,说明文件内容已经读取完毕if (data == -1) {break;}// 以十六进制的方式,打印读取到的字节数// \n 表示的是换行符// %x 表示的是十六进制的占位符System.out.printf("%X\n",data);}}}
}
运行结果:
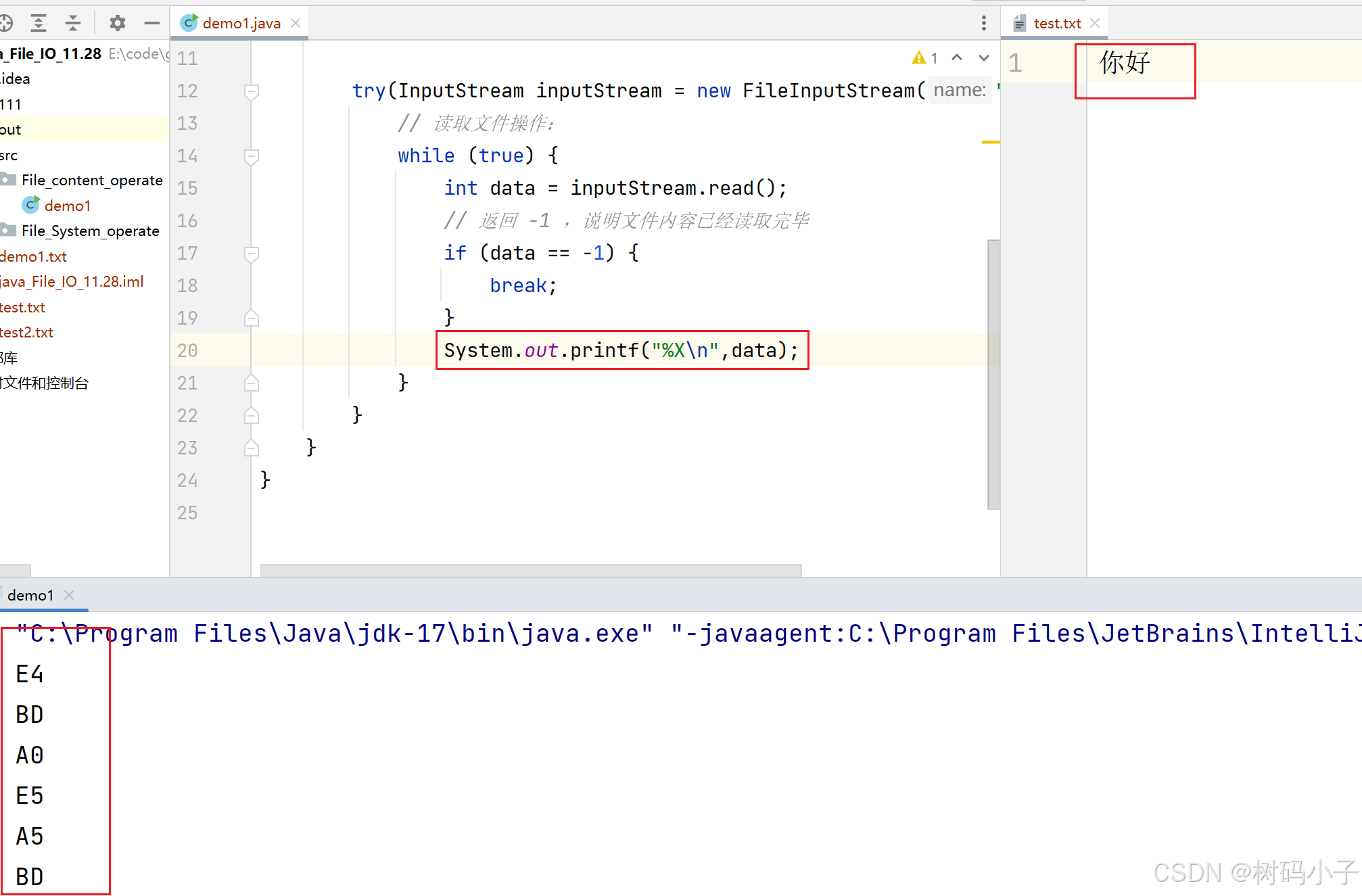
与网站上查到的十六进制编码进行比较:

通过对比发现,代码输出的结果的六个十六进制数字,和网上 UTF-8 编码表中,你好两个汉字所对应的十六进制数字,是一样的!!!
总结:
- 读取英文字符的时候,按照一个一个字节读出来的,打印的结果,是 英文字符所代表的 ASCII码。
- 读取中文字符的时候,按照字节读取,结果以十六进制的形式表示,可以证明,是 UTF-8 字符集 中所表示的汉字。
2. 带 byte[ ] 参数的 read( )方法,返回值是:int

这个方法的作用:调用一次,读取若干个字节,读取到的数据放到定义的 字节数组 当中。
此方法的注意事项:
- 首先,此 read( ) 方法,带有 byte[ ] b 参数,使用之前,我们需要先定义一个这样的字节数组对象。
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class demo2 {public static void main(String[] args) throws IOException {try(InputStream inputStream = new FileInputStream("./test.txt")) {while (true) {//读取文件操作//一次读取多个字节,字节数组的长度,自行定义byte[] bytes = new byte[1024];
// 这个代码里面,有两个返回值,一个是 n,一个是 bytes数组(输出型参数)int n = inputStream.read(bytes);}}}
}
定义的这个字节数组的长度,根据自己的需要来进行自定义就可以了。
进行读操作的时候,会尽可能的把这个字节数组(字节数组的长度需要自定义)给填满,填不满的话,能填几个就是几个!
- 返回值,是 int 类型的数据
当返回值为 -1 时,表示文件已经读取完毕
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class demo2 {public static void main(String[] args) throws IOException {try(InputStream inputStream = new FileInputStream("./test.txt")) {while (true) {//读取文件操作//一次读取多个字节,字节数组的长度,自行定义byte[] bytes = new byte[1024];
// 这个代码里面,有两个返回值,一个是 n,一个是 bytes数组(输出型参数)int n = inputStream.read(bytes);}}}
}
以这一句代码为例子,此处的 n 表示,实际 read()方法 读取到的字节数,比如,读取了 6 个字节,n 的结果就是 6;
- 这个read( )方法,使用 参数 作为方法的返回值,有两个返回值
第一个返回值:第二点讲到的 n (int类型的返回值)
第二个返回值:括号里面的参数,读取到的字节数据,会放到read( )方法括号里的字节数组引用指向的字节数组。
输出型参数:
这种写法,叫做“ 输出型参数 ” ,在 Java 当中,并不是很常见,在 C++ 中比较常见。
什么意思呢?
不知道你们对于 Java 当中的方法(也就是 C语言 中的函数)是怎么理解的?
一般来说,我们可以把 函数/方法 想象成一座工厂,参数就是原材料,返回值就是产品。
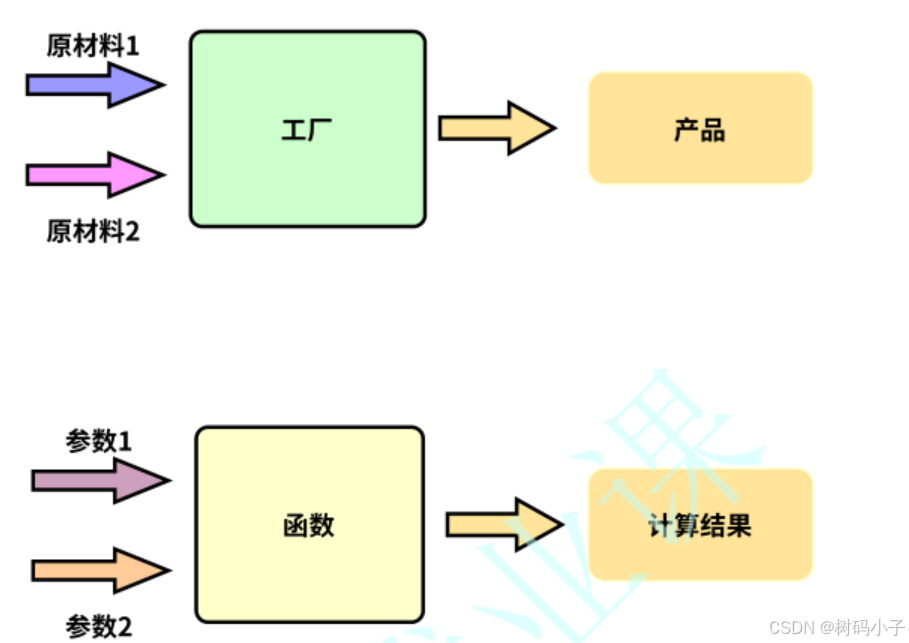
可以根据上面这个图,对方法(也可以称为 函数)进行理解。
函数的参数,是原材料,函数的返回值,是输出的产品。
对于输出型参数来说:有的时候,我们也会使用参数来接收返回值。
在java中,如果参数是引用类型(数组,String,自定义类等),方法内部修改对象内容,能够影响到方法的外部。
在 C语言 当中,最典型的例子就是:交换两个变量的值。
如果你直接传入的是数值,形参是实参的拷贝,直接交换,就只会在方法内部生效,方法外没有影响。故而有了指针,可以传入该变量的指针,交换变量的指针所指向的值,就可以在方法外部也生效,真正实现了两个变量的值。
在Java中,没有指针了,但是有引用的概念,对于引用类型,有这么个语法特点:方法内部的修改,可以影响到方法外部 你所指向的对象。
正是由于这样的语法特点,使得引用类型的参数,可以作为输出型参数
以上,你能理解多少就理解多少,上面所述,只是扩展,哪怕你理解不了,你只需要记住:
第一个返回值:n,记录的是 read( ) 方法,这一次的读取,读到了多少个字节
第二个返回值:bytes,是数组的引用,既是参数,也是方法执行结束后,存放了读取数据的字节数组的引用。
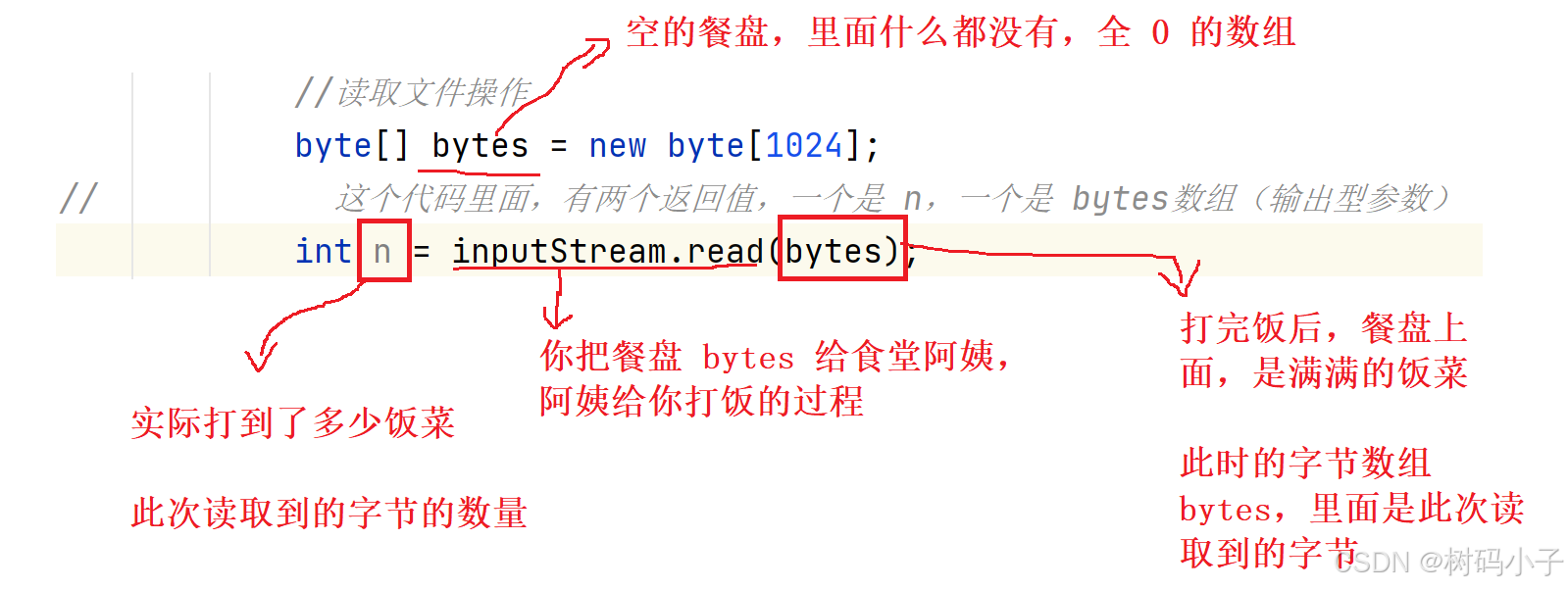
再举一个例子:这个过程有点像 食堂打饭!!
食堂打饭,就是你拿个空的餐盘,来到窗口,你把空的餐盘递给打饭阿姨,让阿姨给你打饭,打完饭以后,餐盘给你,餐盘里面,还有饭菜。
//读取文件操作
byte[] bytes = new byte[1024];
//这个代码里面,有两个返回值,一个是 n,一个是 bytes数组(输出型参数)
int n = inputStream.read(bytes);
就拿这两句代码来进行举例:
byte[] bytes = new byte[1024];
bytes就相当于一个空餐盘
int n = inputStream.read(bytes);
inputStream.read()相当于阿姨给你打饭,你把空餐盘bytes,递给阿姨inputStream.read(bytes),打完饭后,阿姨给你的是盛满了饭菜的餐盘bytes,n表示的就是你餐盘饭菜的量。
输出型参数的出现,本质上来说,还是语法上有限制。
Java,C++ 中,硬性要求:一个方法,只能有一个返回值,如果希望返回多个数据
(上述read()方法,就是希望同时返回,长度 和 内容数组),就只能通过引用类型的参数来凑了。
但是,同样的问题,在 Python 和 Go语言 上,就没有这样的限制了,他们都支持,一个方法,返回多个值。
带 byte[ ] 参数的 read( )方法的读取演示:
仍然是以 test.txt 文件,文件当中的 “你好” ,来进行读取打印:
具体思路:带 byte[ ] 参数的 read( )方法,可以一次读取多个字节,所以,每读一次,就需要循环遍历 bytes 数组一次,格式化输出里面的字节System.out.printf("%X\n",data),直至读取到的字节数 n 为 -1,表示文件数据已经读完,跳出 while()循环,结束读取文件操作。
这里有一个注意的点,遍历读取 bytes 数组内容的时候,不是使用 bytes.length去当作循环条件,而是使用 n,因为 n 才是真正反映此次读取到的有效字节数。
演示代码:
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;public class demo2 {public static void main(String[] args) throws IOException {try(InputStream inputStream = new FileInputStream("./test.txt")) {while (true) {//读取文件操作byte[] bytes = new byte[1024];
// 这个代码里面,有两个返回值,一个是 n,一个是 bytes数组(输出型参数)int n = inputStream.read(bytes);
// 判断文件是否已经读取完毕if (n == -1) {break;}for (int i = 0; i <n; i++) {System.out.printf("%X\n",bytes[i]);}}}}
}
运行结果:
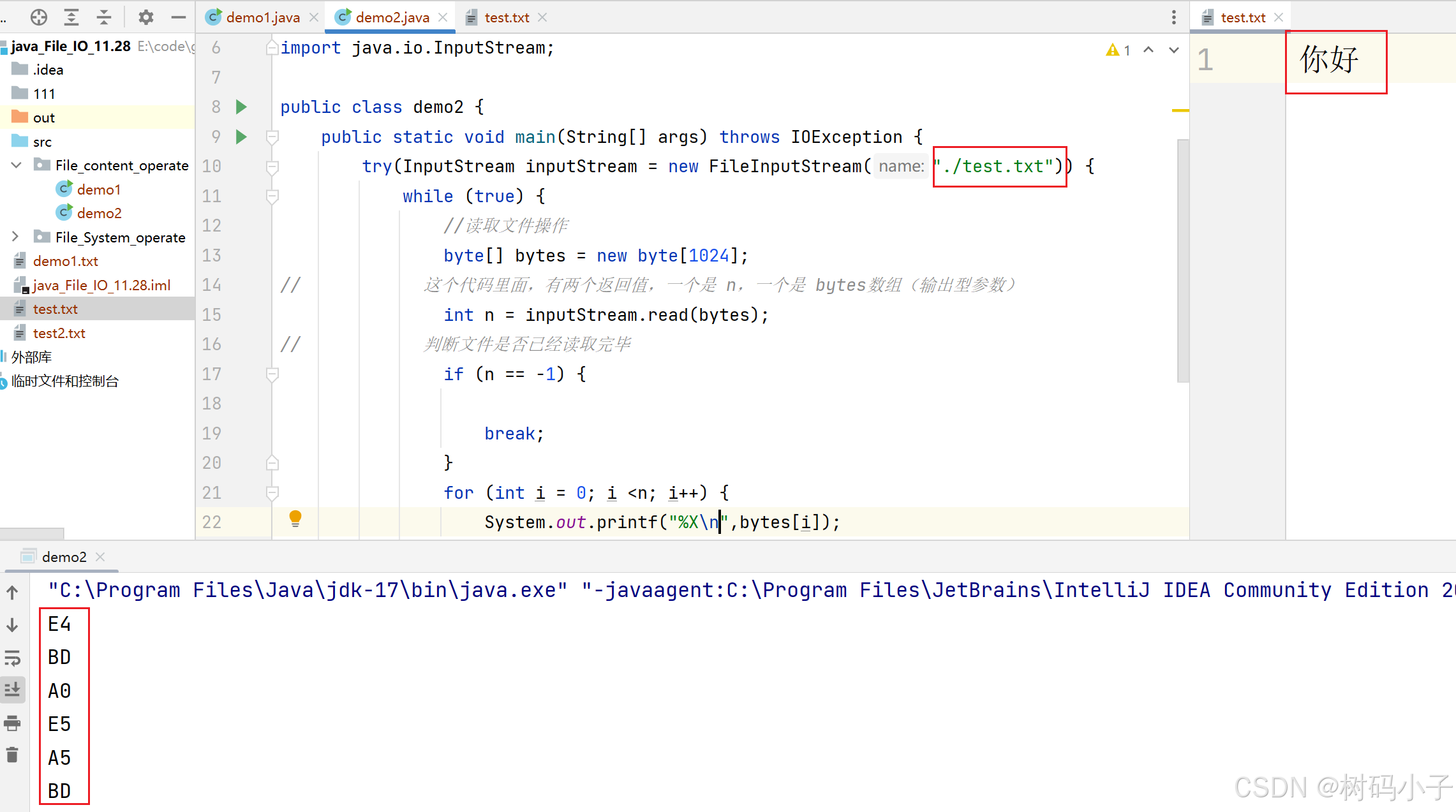
这里显示的就是 你好,所对应的 UTF-8 编码中,对应的十六进制数。
我们之前说,这个read()方法,会尽可能的去读取文件中的数据,放到你所定义的空白字节数组里面,读取到的字节数据的大小,取决于你空白字节数组的大小,现在,我们上面代码所定义的空白字节数组 bytes 的大小,由 1024 改为 3 ,同时,输出字节的时候,我们加个分隔符,以便进行区分。
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;public class demo2 {public static void main(String[] args) throws IOException {try(InputStream inputStream = new FileInputStream("./test.txt")) {while (true) {//读取文件操作byte[] bytes = new byte[3];
// 这个代码里面,有两个返回值,一个是 n,一个是 bytes数组(输出型参数)int n = inputStream.read(bytes);
// 判断文件是否已经读取完毕if (n == -1) {break;}for (int i = 0; i <n; i++) {System.out.printf("%X\n",bytes[i]);}System.out.println("======================");}}}
}
运行结果:
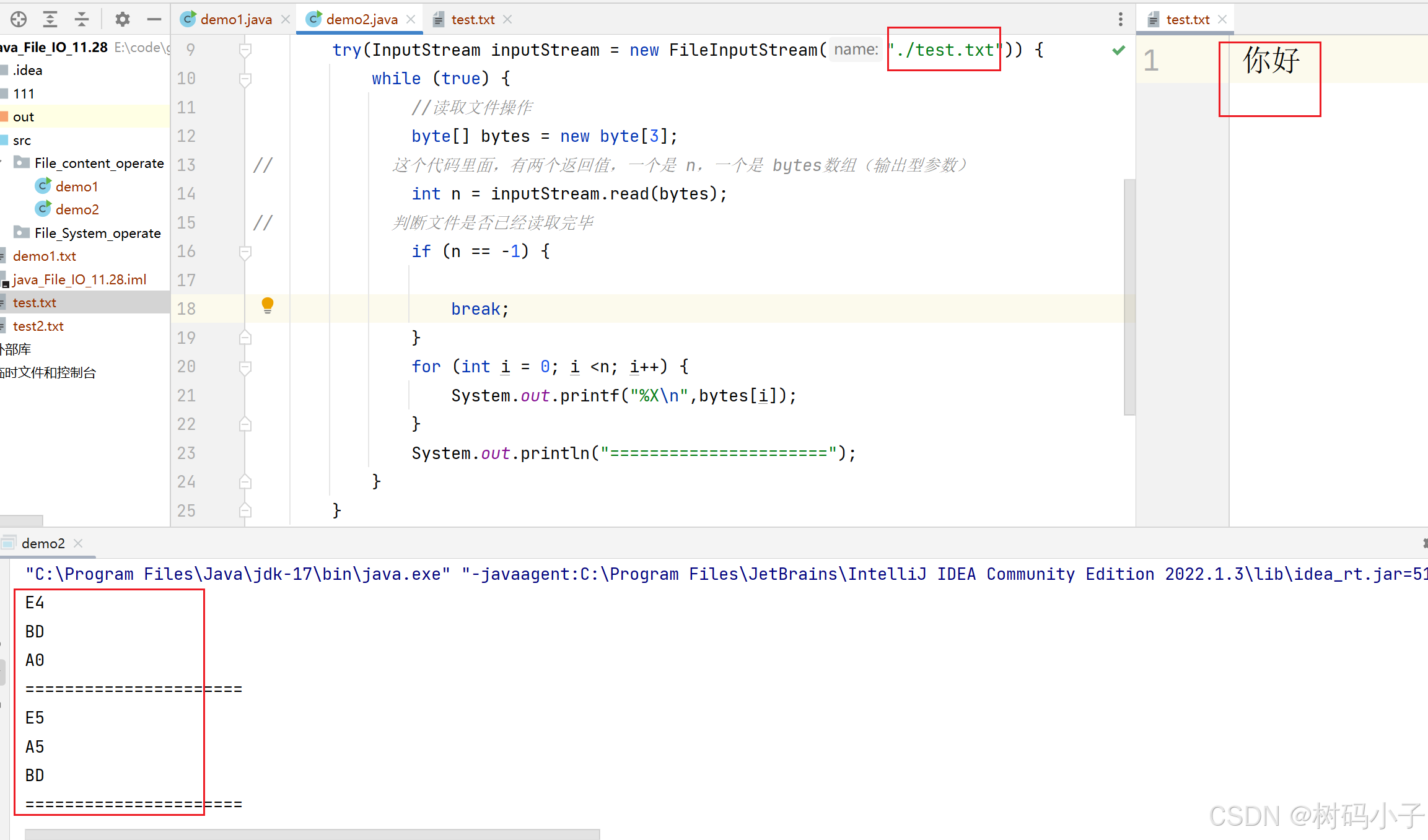
所以,这个 read()方法,一次能读取到多少个字节,跟你自己定义的空白字节数组的大小是有关系的。
3. 带 三个参数的 read( )方法,返回值是:int

对这三个参数进行解释:
byte[ ] b :就是你定义的空白字节数组,调用 read()方法,后,读取到的字节,存放到这个数组里面。
int off :off --> offset 表示的是 偏移量(数组下标),本次读取到的字节数据,从空白字节数组的 off下标 开始存放,限制了存放的起始位置。
int len :表示你本次读取,想读取多少个字节往空白字节数组 b 中的哪个起始位置 off开始存放,限制了你本次可以读取到的字节,len 往往会和返回值的大小(本次读取到了多少个字节)是一样的。
所以这个read()方法的作用就是:想读取多少(len)个字节往空白字节数组 b 中的哪个起始位置 off下标 开始存放
这个方法的使用场景通常是:你有一个非常大的字节数组,每次读操作,都把数据放到数组的某个部分,就会使用到这个 带有三个参数的 read()方法。
演示:
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;public class demo3 {public static void main(String[] args) throws IOException {
//使用 try with resource 的语法,打开文件,并程序结束的时候,自动执行 close()方法try(InputStream inputStream = new FileInputStream("./test.txt")) {while (true) {
// 操作文件
// 定义空白字节数组byte[] bytes = new byte[1024];// 读取文件int n = inputStream.read(bytes,0,3);
// 查看你本次读取到了多少个字节System.out.println("n = " + n);
// 判断是否已经读取结束if (n == -1) {break;}
// 输出读取后,存放到字节数组中的内容for (int i = 0; i < n; i++) {System.out.printf("%X\n",bytes[i]);}System.out.println("===================");}}}
}
运行结果:
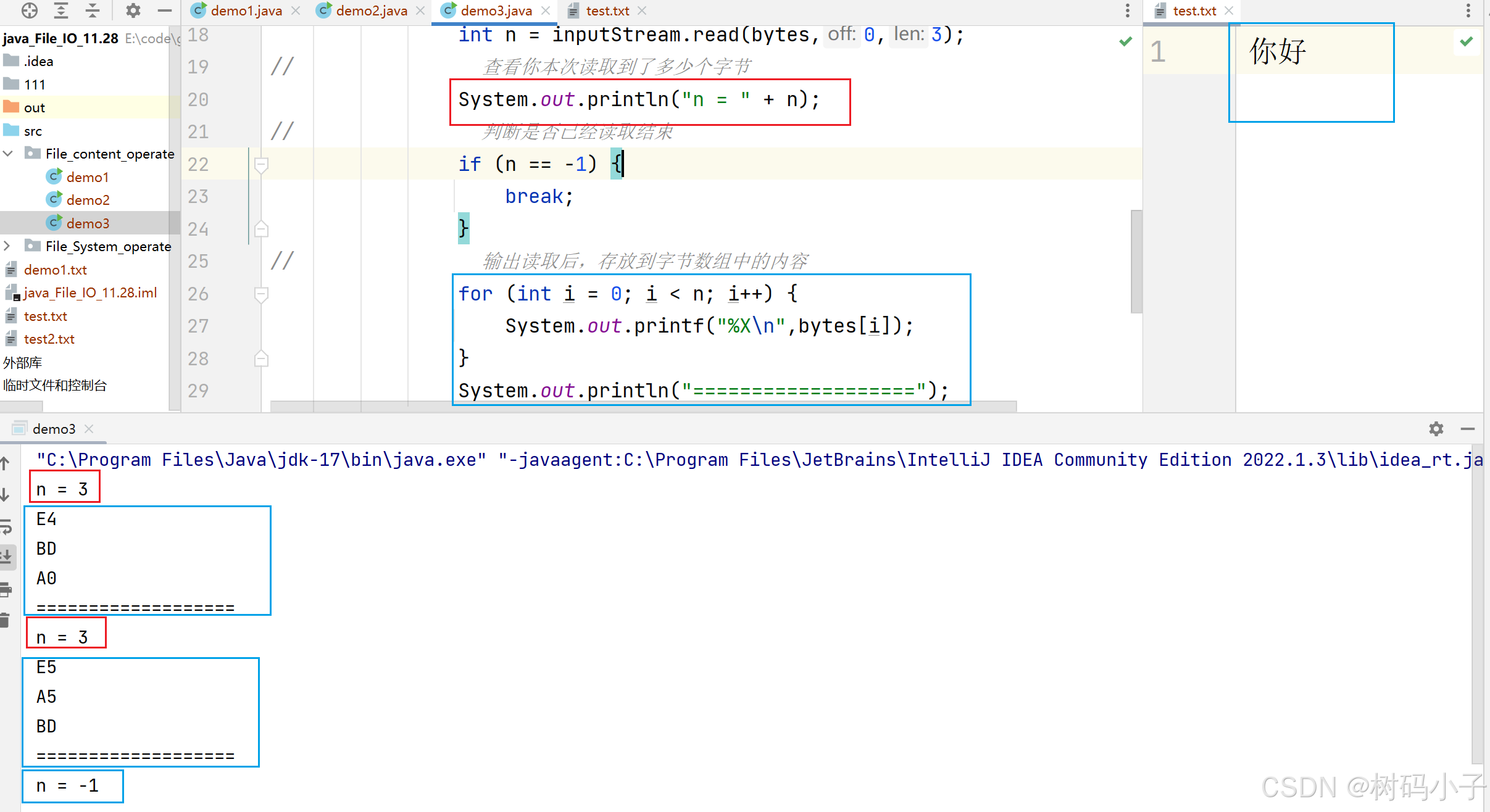
代码的解释:
首先,我们还是先定义一个空白字节数组,大小为 1024个字节。
然后读取文件,使用带有三个参数的 read(bytes,0,3)方法,表示:把读取到的字节,存放到空白字节数组里面去,从字节数组的 0 下标,开始存放,同时 len 为 3,也就是,限制每一个读取的字节的数量为 3,哪怕你空白字节数组一次性能装下 1024 个字节,len 的大小,和 返回值 n 的大小是一样的,都是 3,从输出结果可以看出。
最后,当 n 等于 -1 时,表示文件已经读取完毕,结束while循环,整个java程序结束。
4. 读取文件的操作(三种 read方法)的简单总结
其实,文件内容操作,就那么几个步骤:打开文件,操作文件中的内容(读或者写),关闭文件
在实际开发过程当中,这三种read方法需要根据具体的情况来进行使用。
总结:
这篇博客,主要是讲解 使用字节流操作:InputStream类 读取文件的操作(三种 read 方法)。
看完这篇博客,请点击这个链接:Java 文件操作 和 IO(3)-- Java文件内容操作(1)-- 字节流操作
继续学习 OutputStream类 写数据的操作(三种 write 方法)。
最后,如果这篇博客能帮到你的,请你点点赞,有写错了,写的不好的,欢迎评论指出,谢谢!