报告系统状态的连续日期 mysql + pandas(连续值判断)
本题用到知识点:row_number(), union, date_sub(), to_timedelta()……
目录
思路
pandas
Mysql
思路
链接:报告系统状态的连续日期

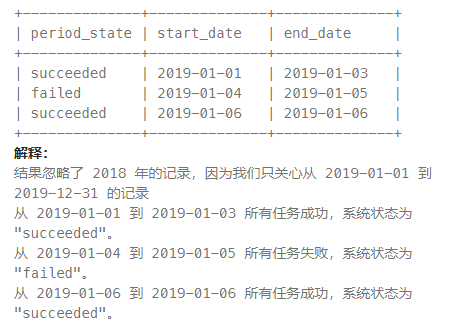
思路:
判断连续性常用的一个方法,增量相同的两个列的差值是固定的。
让日期与行号 * 天数相减,连续的区域就会的得到相同的结果。
不同的连续区域得到不同结果(因为来连续到不连续,中间出现了增量不为1的情况。但是行号总是增量为1,所以下一个连续区域与行号的差值与上一个连续区域不同。)
如:1~2 连续,7~8连续,但是与行号的差值tag并不相同。
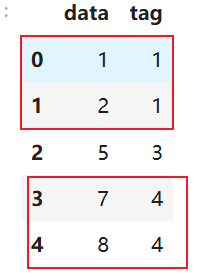
根据相同的tag分组后,找到分组种的最大最小时间分别作为开始时间和结束时间,
两个表都根据上述操作后之际纵向拼接后按照开始时间升序输出。
pandas
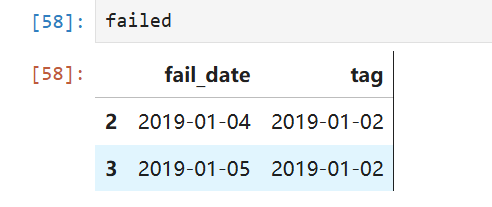
import pandas as pddef report_contiguous_dates(failed: pd.DataFrame, succeeded: pd.DataFrame) -> pd.DataFrame:f_date_vaild = (failed['fail_date'] >= '2019-01-01') & (failed['fail_date'] <= '2019-12-31')failed = failed[f_date_vaild]failed['tag'] = failed['fail_date'] - pd.to_timedelta(failed.index,unit='d')failed = failed.groupby(by='tag')['fail_date'].agg(start_date='min',end_date='max').reset_index()failed['tag'] = 'failed's_date_vaild = (succeeded['success_date'] >= '2019-01-01') & (succeeded['success_date'] <= '2019-12-31')succeeded = succeeded[s_date_vaild]succeeded['tag'] = succeeded['success_date'] - pd.to_timedelta(succeeded.index, unit='d')succeeded = succeeded.groupby(by='tag')['success_date'].agg(start_date='min', end_date='max').reset_index()succeeded['tag'] = 'succeeded'return pd.concat([succeeded,failed],axis=0).rename(columns={'tag':'period_state'}).sort_values(by='start_date',ascending=True)中间结果示例:failed表获取tag后
Mysql
pandas直接使用index作为行号,mysql则使用排名row_number()来获得固定增量的行号。
with f as
(
select fail_date,
row_number() over(order by fail_date asc) as rn from failed
where fail_date between '2019-01-01' and '2019-12-31')
,fg as
(
select 'failed' as period_state,
min(fail_date) as start_date,
max(fail_date) as end_date
from
(
select
fail_date,
date_sub(fail_date,interval rn day) as tag
from f
) t
group by tag
)
,
s as
(
select success_date,
row_number() over(order by success_date asc) as rn from succeeded
where success_date between '2019-01-01' and '2019-12-31'
)
,
sg as
(
select 'succeeded' as period_state,
min(success_date) as start_date,
max(success_date) as end_date
from
(
select
success_date,
date_sub(success_date,interval rn day) as tag
from s
) t
group by tag
)select * from
(
(select * from fg)union all (select * from sg)
) t
order by start_date asc