[yolov11改进系列]基于yolov11引入可改变核卷积AKConv的python源码+训练源码
[可改变核卷积AKConv介绍]
AKConv的主要思想:AKConv(可变核卷积)主要提供一种灵活的卷积机制,允许卷积核具有任意数量的参数和采样形状。这种方法突破了传统卷积局限于固定局部窗口和固定采样形状的限制,从而使得卷积操作能够更加精准地适应不同数据集和不同位置的目标。
AKConv的改进点:
- 灵活的卷积核设计:AKConv允许卷积核具有任意数量的参数,这使得其可以根据实际需求调整大小和形状,从而更有效地适应目标的变化。
- 初始采样坐标算法:针对不同大小的卷积核,AKConv提出了一种新的算法来生成初始采样坐标,这进一步增强了其在处理各种尺寸目标时的灵活性。
- 适应性采样位置调整:为适应目标的不同变化,AKConv通过获得的偏移量调整不规则卷积核的采样位置,从而提高了特征提取的准确性。
- 减少模型参数和计算开销:AKConv支持线性增减卷积参数的数量,有助于在硬件环境中优化性能,尤其适合于轻量级模型的应用。
个人总结:总的来说,AKConv通过其创新的可变核卷积设计,为卷积神经网络带来了显著的性能提升。其能够根据不同的数据集和目标灵活调整卷积核的大小和形状,从而实现更高效的特征提取。
图片展示了AKConv结构的详细示意图
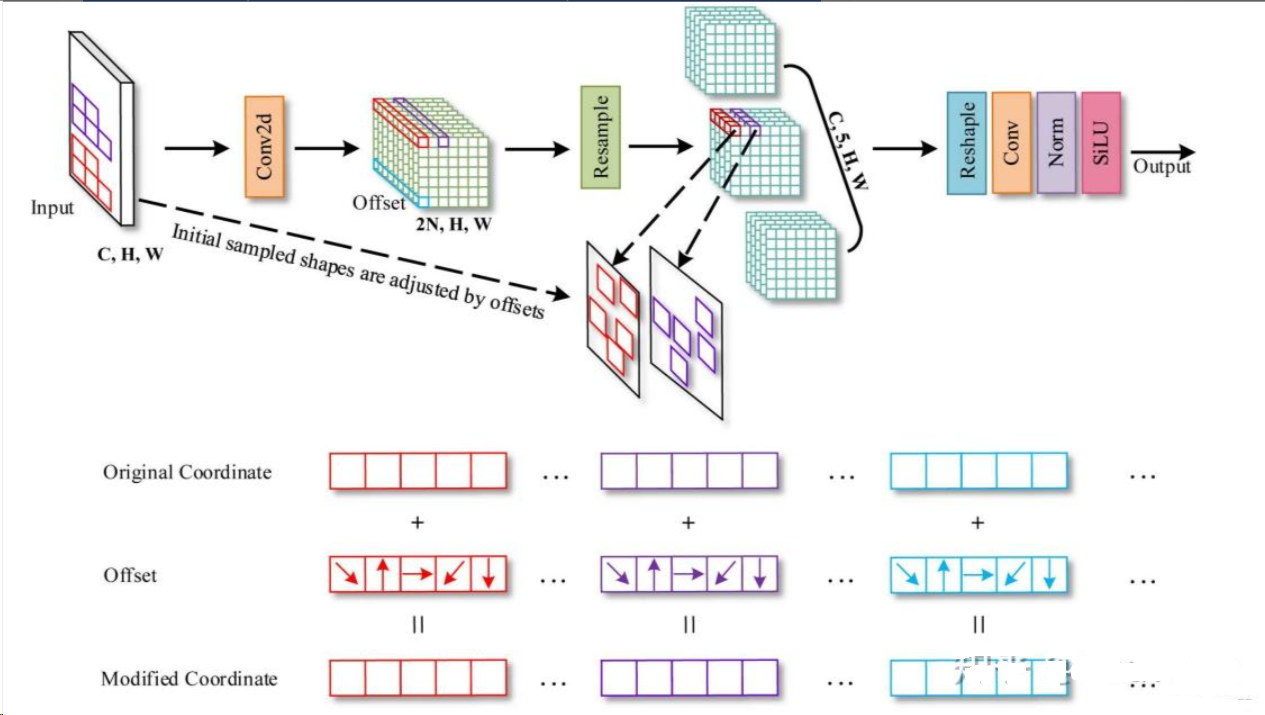
1. 输入:输入图像具有维度(C, H, W),其中C是通道数,H和W分别是图像的高度和宽度。 2. 初始采样形状:这一步是AKConv特有的,它给出了卷积核的初始采样形状。 3. 卷积操作:使用Conv2d对输入图像执行卷积操作。 4. 偏移:通过学习得到的偏移量来调整初始采样形状。这一步是AKConv的关键,允许卷积核形状动态调整以适应图像的特征。 5. 重采样:根据调整后的采样形状对特征图进行重采样。 6. 输出管道:重采样后的特征图经过重塑、再次卷积、标准化,最后通过激活函数SiLU输出最终结果。
底部的三行展示了采样坐标的变化:
- 原始坐标:显示了卷积核在没有任何偏移的情况下的初始采样位置。
- 偏移:展示了学习到的偏移量,这些偏移量将应用于原始坐标。
- 修改后的坐标:应用偏移后的采样坐标。
总结:官方这个图说明了AKConv如何为任意大小的卷积分配初始采样坐标,并通过可学习的偏移调整采样形状。与原始采样形状相比,每个位置的采样形状都通过重采样进行了改变,这使得AKConv可以根据图像内容动态调整其操作,为卷积网络提供了前所未有的灵活性和适应性。
【yolov11框架介绍】
2024 年 9 月 30 日,Ultralytics 在其活动 YOLOVision 中正式发布了 YOLOv11。YOLOv11 是 YOLO 的最新版本,由美国和西班牙的 Ultralytics 团队开发。YOLO 是一种用于基于图像的人工智能的计算机模
Ultralytics YOLO11 概述
YOLO11 是Ultralytics YOLO 系列实时物体检测器的最新版本,以尖端的精度、速度和效率重新定义了可能性。基于先前 YOLO 版本的令人印象深刻的进步,YOLO11 在架构和训练方法方面引入了重大改进,使其成为各种计算机视觉任务的多功能选择。
Key Features 主要特点
- 增强的特征提取:YOLO11采用改进的主干和颈部架构,增强了特征提取能力,以实现更精确的目标检测和复杂任务性能。
- 针对效率和速度进行优化:YOLO11 引入了精致的架构设计和优化的训练管道,提供更快的处理速度并保持准确性和性能之间的最佳平衡。
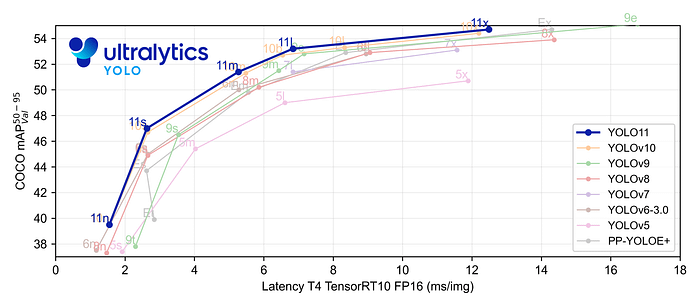
- 使用更少的参数获得更高的精度:随着模型设计的进步,YOLO11m 在 COCO 数据集上实现了更高的平均精度(mAP),同时使用的参数比 YOLOv8m 少 22%,从而在不影响精度的情况下提高计算效率。
- 跨环境适应性:YOLO11可以无缝部署在各种环境中,包括边缘设备、云平台以及支持NVIDIA GPU的系统,确保最大的灵活性。
- 支持的任务范围广泛:无论是对象检测、实例分割、图像分类、姿态估计还是定向对象检测 (OBB),YOLO11 旨在应对各种计算机视觉挑战。

与之前的版本相比,Ultralytics YOLO11 有哪些关键改进?
Ultralytics YOLO11 与其前身相比引入了多项重大进步。主要改进包括:
- 增强的特征提取:YOLO11采用改进的主干和颈部架构,增强了特征提取能力,以实现更精确的目标检测。
- 优化的效率和速度:精细的架构设计和优化的训练管道可提供更快的处理速度,同时保持准确性和性能之间的平衡。
- 使用更少的参数获得更高的精度:YOLO11m 在 COCO 数据集上实现了更高的平均精度(mAP),参数比 YOLOv8m 少 22%,从而在不影响精度的情况下提高计算效率。
- 跨环境适应性:YOLO11可以跨各种环境部署,包括边缘设备、云平台和支持NVIDIA GPU的系统。
- 支持的任务范围广泛:YOLO11 支持多种计算机视觉任务,例如对象检测、实例分割、图像分类、姿态估计和定向对象检测 (OBB)
【测试环境】
windows10 x64
ultralytics==8.3.0
torch==2.3.1
【改进流程】
1. 新增AKConv.py实现模块(代码太多,核心模块源码请参考改进步骤.docx)然后在同级目录下面创建一个__init___.py文件写代码
from .AKConvimport *
2. 文件修改步骤
修改tasks.py文件
创建模型配置文件
yolo11-AKConv.yaml内容如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 2 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, AKConv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 1, AKConv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)- [-1, 1, AKConv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
3. 验证集成
使用新建的yaml配置文件启动训练任务:
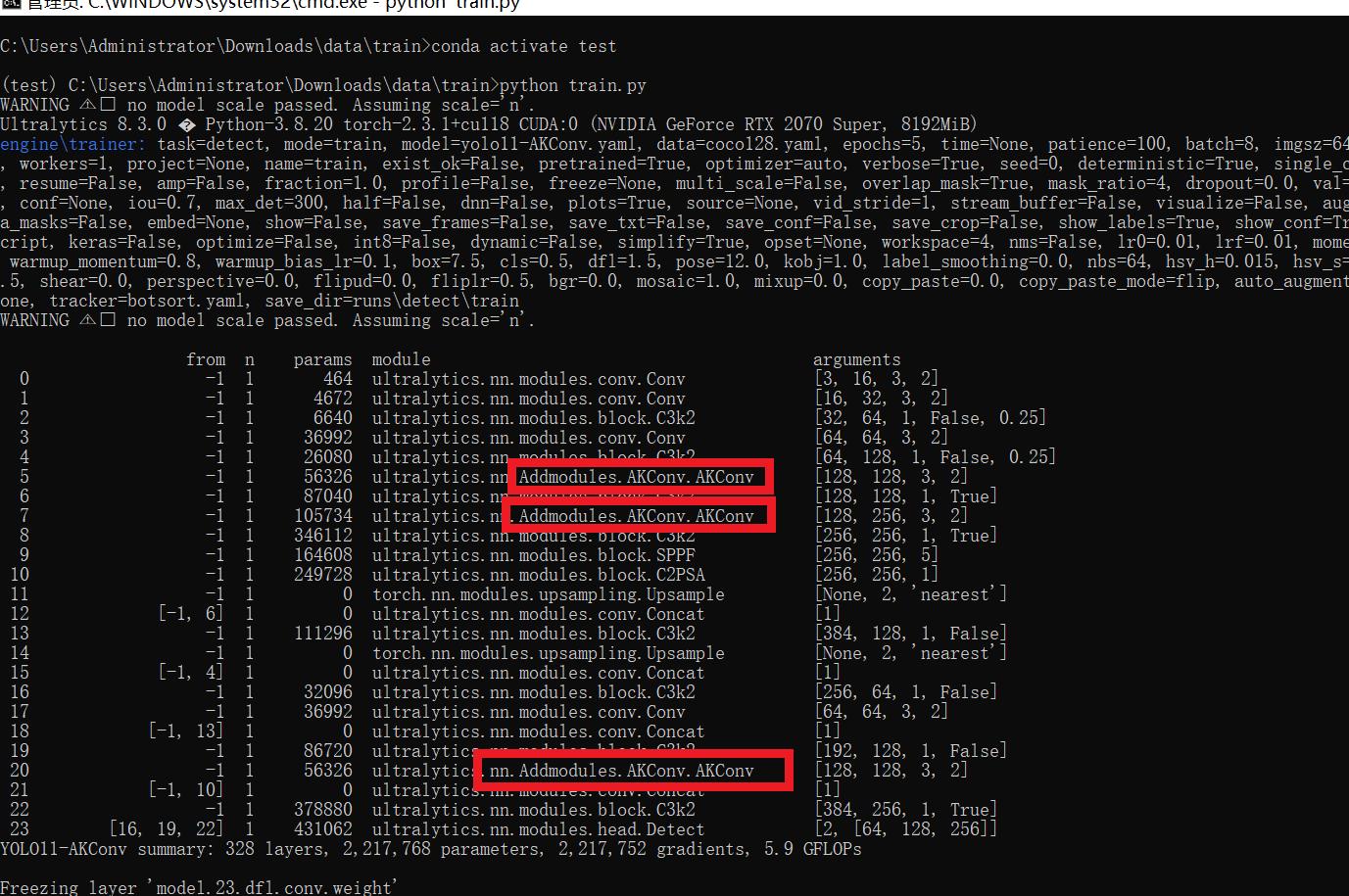
from ultralytics import YOLOif __name__ == '__main__':model = YOLO('yolo11-AKConv.yaml') # build from YAML and transfer weights# Train the modelresults = model.train(data='coco128.yaml',epochs=100, imgsz=640, batch=8, device=0, workers=1, save=True,resume=False)成功集成后,训练日志中将显示AKConv模块的初始化信息,表明已正确加载到模型中。
【训练说明】
第一步:首先安装好yolov11必要模块,可以参考yolov11框架安装流程,然后卸载官方版本pip uninstall ultralytics,最后安装改进的源码pip install .
第二步:将自己数据集按照dataset文件夹摆放,要求文件夹名字都不要改变
第三步:分别打开train.py,coco128.yaml和模型参数yaml文件修改必要的参数,最后执行python train.py即可训练
【提供文件】
├── [官方源码]ultralytics-8.3.0.zip
├── train/
│ ├── coco128.yaml
│ ├── dataset/
│ │ ├── train/
│ │ │ ├── images/
│ │ │ │ ├── firc_pic_1.jpg
│ │ │ │ ├── firc_pic_10.jpg
│ │ │ │ ├── firc_pic_11.jpg
│ │ │ │ ├── firc_pic_12.jpg
│ │ │ │ ├── firc_pic_13.jpg
│ │ │ ├── labels/
│ │ │ │ ├── classes.txt
│ │ │ │ ├── firc_pic_1.txt
│ │ │ │ ├── firc_pic_10.txt
│ │ │ │ ├── firc_pic_11.txt
│ │ │ │ ├── firc_pic_12.txt
│ │ │ │ ├── firc_pic_13.txt
│ │ └── val/
│ │ ├── images/
│ │ │ ├── firc_pic_100.jpg
│ │ │ ├── firc_pic_81.jpg
│ │ │ ├── firc_pic_82.jpg
│ │ │ ├── firc_pic_83.jpg
│ │ │ ├── firc_pic_84.jpg
│ │ ├── labels/
│ │ │ ├── firc_pic_100.txt
│ │ │ ├── firc_pic_81.txt
│ │ │ ├── firc_pic_82.txt
│ │ │ ├── firc_pic_83.txt
│ │ │ ├── firc_pic_84.txt
│ ├── train.py
│ ├── yolo11-AKConv.yaml
│ └── 训练说明.txt
├── [改进源码]ultralytics-8.3.0.zip
├── 改进原理.docx
└── 改进流程.docx 【常见问题汇总】
问:为什么我训练的模型epoch显示的map都是0或者map精度很低?
回答:由于源码改进过,因此不能直接从官方模型微调,而是从头训练,这样学习特征能力会很弱,需要训练很多epoch才能出现效果。此外由于改进的源码框架并不一定能够保证会超过官方精度,而且也有可能会存在远远不如官方效果,甚至精度会很低。这说明改进的框架并不能取得很好效果。所以说对于框架改进只是提供一种可行方案,至于改进后能不能取得很好map还需要结合实际训练情况确认,当然也不排除数据集存在问题,比如数据集比较单一,样本分布不均衡,泛化场景少,标注框不太贴合标注质量差,检测目标很小等等原因
【重要说明】
我们只提供改进框架一种方案,并不保证能够取得很好训练精度,甚至超过官方模型精度。因为改进框架,实际是一种比较复杂流程,包括框架原理可行性,训练数据集是否合适,训练需要反正验证以及同类框架训练结果参数比较,这个是十分复杂且漫长的过程。