Fine-tuning:微调技术,训练方式,LLaMA-Factory,ms-swift
1,微调技术
| 特征 | Full-tuning | Freeze-tuning | LoRA | QLoRA |
|---|---|---|---|---|
| 训练参数量 | 全部 | 少量 | 极少 | 极少 |
| 显存需求 | 高 | 低 | 很低 | 最低 |
| 模型性能 | 最佳 | 中等 | 较好 | 接近 LoRA |
| 模型修改方式 | 无变化 | 局部冻结 | 插入模块 | 量化+插入模块 |
| 多任务共享 | 不便 | 较便 | 非常适合 | 非常适合 |
| 适合超大模型微调 | ❌ | ✅ | ✅ | ✅(最优) |
1.1,Full-tuning
Full-tuning(全参数微调):对模型的全部参数进行微调。训练过程中,所有层的权重都会被更新。
加载预训练模型;
所有参数设为可训练;
使用下游任务的数据继续训练整个模型。
📈 优点:
最大化模型性能;
可适配大幅度任务转变;
简单直接,无结构变化。
📉 缺点:
资源消耗大:内存和显存使用高;
训练时间长;
在多任务场景下缺乏参数复用;
不适合频繁变更的小任务定制(每次都得保存整套参数)。
✅ 适用场景:
对模型效果要求极高;
拥有大量训练资源;
任务和原始预训练任务差别较大。
1.2,Freeze-tuning
Freeze-tuning(冻结微调):冻结预训练模型的部分或全部参数,仅微调某些新增模块(如分类头)或少数层。
加载预训练模型;
冻结大部分参数(如 Transformer encoder);
仅微调一小部分,如最后几层或添加的下游任务层。
📈 优点:
节省计算资源;
防止过拟合;
训练速度快;
对原始模型破坏小。
📉 缺点:
性能提升有限;
表达能力受限,难以适配大跨度任务;
调参难度大(决定哪些层冻结、哪些不冻结)。
✅ 适用场景:
轻量级部署;
任务与预训练相似;
快速原型验证。
1.3,LoRA
LoRA(Low-Rank Adaptation):使用低秩矩阵插入到原始模型权重的更新路径中,只训练这些额外的低秩参数,而不更新原始参数。
- 不修改原始权重矩阵
,而在其前后插入两个较小的可训练矩阵
,构造为:
其中:
- 进训练
📈 优点:
极大减少可训练参数数量(可减少至原来的 0.1%~1%);
内存占用显著降低;
适合多任务共享大模型,仅保存不同任务的低秩参数。
📉 缺点:
微调能力有限;
可能无法达到 Full-tuning 的最优精度;
在某些任务上收敛较慢。
✅ 适用场景:
多任务微调(如一个大模型服务多个业务);
边缘设备或存储受限场景;
希望在多个微调版本之间快速切换。
1.4,QLoRA
QLoRA(Quantized LoRA):在 LoRA 的基础上,将原始模型进行 量化(Quantization)(通常是 4-bit 量化),结合 LoRA 插件模块进行微调。
使用 4-bit 量化将大模型压缩到极小显存占用;
原始权重被量化,但仍然保持冻结状态;
LoRA 模块保持 float32/float16 精度进行训练;
利用量化感知训练技术减少精度损失。
📈 优点:
显存占用极低(单卡 24GB GPU 可微调 65B 模型);
准确率接近 LoRA;
支持 CPU/GPU 微调;
无需对全模型解冻,训练负担极小。
📉 缺点:
量化带来一定的数值不稳定性;
性能略逊于全精度微调;
对部署系统需支持混合精度和量化运算。
✅ 适用场景:
极端显存受限的环境;
想在消费级设备(如笔记本、消费级 GPU)微调大模型;
用于实验、原型开发和模型压缩部署。
2,训练方式
| 阶段 | 是否涉及标签 | 是否使用人类偏好 | 是否使用强化学习 | 典型方法/目标 |
|---|---|---|---|---|
| Pre-Training | ❌ | ❌ | ❌ | 学习语言通用能力 |
| Supervised Fine-Tuning | ✅ | ❌ | ❌ | 执行指令、完成任务 |
| Reward Modeling | ✅(对比标签) | ✅ | ❌ | 构造奖励函数 |
| PPO | ❌ | ✅ | ✅ | 提升人类偏好表现 |
| DPO | ✅(对比标签) | ✅ | ❌(间接) | 更高效的人类偏好训练 |
| KTO | ✅(对比标签) | ✅ | ❌ | 用 KL 优化拟合偏好分布 |
| ORPO | ✅ | ✅ | ❌ | 离线优化,有效融合监督与偏好学习 |
| SimPO | ✅ | ✅ | ❌ | 极简偏好优化方式 |
2.1,Pre-Training
Pre-Training(预训练):预训练是整个语言模型生命周期的第一阶段,其目标是让模型掌握语言的基本结构、语义关系和常识知识。
使用大规模无标签语料(如网页、图书、维基百科等);
模型通常采用自监督学习目标,如:
Masked Language Modeling(BERT 系列):预测被遮盖的词;
Causal Language Modeling(GPT 系列):预测下一个词。
目标:学习词法、句法、语义、语言结构等通用能力,为下游任务打下基础。
特点:
数据量最大;
训练时间最长;
不依赖人工标注。
2.2,Supervised Fine-Tuning
Supervised Fine-Tuning(有监督微调):在预训练模型基础上,使用有标签的数据集对模型进行微调,使其适配特定任务,如问答、摘要、分类等。
⚙️ 方法:
数据来源于人工标注或规则生成;
常用损失函数为 Cross-Entropy;
多用于 Instruct 模型训练(例如指令跟随数据,如 "请翻译以下句子")。
目标:让模型“听得懂”任务指令,具备基础的任务执行能力。
特点:
通常比预训练快;
微调数据越高质量,模型行为越稳定;
是 RLHF 流程的第一步。
2.3,Reward Modeling
Reward Modeling(奖励建模):Reward Modeling 是强化学习前的关键步骤,用于训练一个奖励模型(Reward Model, RM),模拟人类偏好。
输入:模型输出的多个候选答案;
标签:由人类评审者对答案进行排序或打分;
模型学习:预测哪个答案更好(即更符合人类偏好)。
目标:用一个可训练的模型替代人工打分,供后续强化学习优化使用。
特点:
训练的是一个新模型,不是语言模型本体;
训练数据来源于人类偏好对比;
是 RLHF(强化学习人类反馈)流程的桥梁环节。
2.4,PPO Training
PPO Training(Proximal Policy Optimization):PPO 是一种常见的强化学习算法,广泛用于 LLM 微调中的 RLHF 阶段,使模型生成更符合人类期望的响应。
使用奖励模型作为环境;
模型作为策略网络,尝试生成更高分的回答;
引入“剪切项”防止训练不稳定。
目标:在不显著破坏原模型的语言能力前提下,优化生成结果的人类偏好分数。
特点:
引入强化学习思想;
训练复杂、稳定性要求高;
是 ChatGPT 等对齐性模型的重要步骤。
2.5,DPO Training
DPO Training(Direct Preference Optimization):DPO 是一种无需训练奖励模型的新方法,直接优化模型使其偏向于人类更喜欢的回答,是对 RLHF 的简化。
直接用人类偏好对比(好 vs 差)训练语言模型;
不需要额外的 Reward Model;
目标函数基于“人类偏好答案比非偏好答案概率高”。
目标:简化 RLHF 流程,提高训练效率和稳定性。
特点:
更容易实现;
效果接近 PPO;
越来越受研究社区关注。
2.6,KTO Training
KTO Training(Kullback-Leibler Preference Optimization):KTO 是一种在 DPO 基础上发展的方法,通过 KL 散度更精确地拟合人类偏好分布,进一步提升模型对齐性。
构建基于 KL 散度的目标函数;
训练使模型生成的分布更接近于偏好更高的样本。
目标:在对齐能力和训练效率之间取得更好的平衡。
特点:
相较 DPO 提供更细粒度的控制;
数学上更严谨;
适用于人类偏好数据不充分的情况。
2.7,ORPO Training
ORPO Training(Offline RL with Preference Optimization):ORPO 是一种使用离线数据进行偏好优化的方法,融合了监督学习和偏好强化学习的优势。
不依赖交互式环境;
利用已存在的偏好标注对模型进行偏好学习;
通常和行为克隆(Behavior Cloning)结合使用。
目标:避免在线 RL 的不稳定性,使用偏好数据离线优化生成行为。
特点:
更易部署;
更稳定;
适合偏好数据多但不能实时交互的场景。
2.8,SimPO Training
SimPO Training(Simplified Preference Optimization) :SimPO 是一种对 DPO 的进一步精简版,采用更简单的结构实现相近的偏好优化效果。
利用简单的正负样本对比训练;
可看作是 DPO 的轻量变种。
目标:以极简实现替代复杂 RL 训练流程,适用于低资源环境。
特点:
非常轻量;
效果仍然优于纯监督微调;
实现快速、适配性强。
3,LLaMA-Factory
参考:
3步轻松微调Qwen3,本地电脑就能搞,这个方案可以封神了!【喂饭级教程】
12 大模型学习——LLaMA-Factory微调_llama factory-CSDN博客
3.1,项目安装
依赖安装:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory pip install -e ".[torch,metrics]" --no-build-isolation必需项 至少 推荐 python 3.9 3.10 torch 2.0.0 2.6.0 torchvision 0.15.0 0.21.0 transformers 4.45.0 4.50.0 datasets 2.16.0 3.2.0 accelerate 0.34.0 1.2.1 peft 0.14.0 0.15.1 trl 0.8.6 0.9.6Gradio 启动:
llamafactory-cli webui
模型名称:
- Base 版本(如 Qwen3-1.7B-Base)
- 基础预训练模型
- 没有经过指令微调
- 适合继续搞预训练或从头开始指令微调
- 通常情况下输出质量不如 Instruct 版本
- Instruct 版本(如 Qwen3-1.7B-Instruct)
- 经过指令微调的模型
- 更适合直接对话和指令遵循
- 已经具备基本的对话能力
- 更适合用来进一步微调
微调方法:lora
检查点路径:在长时间训练大模型的时候会经常用,主要作用是把训练过程中的阶段性结果进行保存,这里是设置指定的保存地址的。这样如果训练过程意外中断,可以从检查点开始继续训练,不用从头再开始训练。若不设置,则默认保存在 LLaMA-Factory 的 /saves文件中
微调前可以加载模型 进入chat模型,看模型能否正常加载。
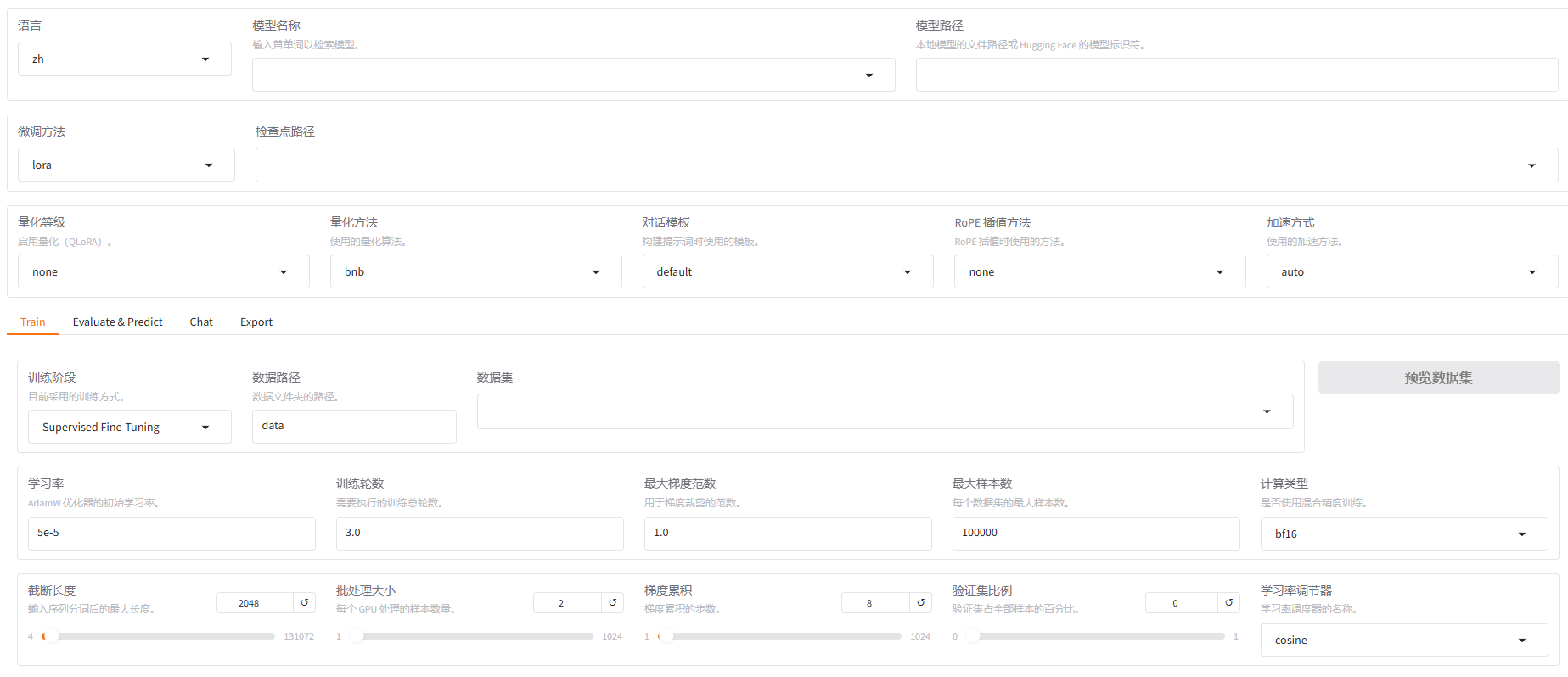
3.2,量化
【量化等级】用于指定是否对模型权重进行量化以减少内存使用:
- none:不启用量化,使用原始全精度模型(如 FP16 或 BF16)。
- 8:8比特量化(int8),在大多数场景下能提供不错的精度与性能平衡。
- 4:4比特量化(int4),更大幅度地压缩模型大小,适合资源受限设备,精度会有所下降。
👉 QLoRA(Quantized LoRA)结合了量化和LoRA(低秩适配)技术,常用于在消费级显卡上进行大模型微调。
【量化方法】用于指定具体的量化实现库或算法:
- bnb:BitsAndBytes(Meta 的实现),支持 int8 和 int4,兼容 HuggingFace。
- hqq:HQQ(High Quality Quantization),一种高保真度的量化方法,强调量化后精度保持。
- eetq:EETQ(Efficient and Effective Transformer Quantization),侧重性能与部署效率。
【对话模板】用于指定对话格式模板,影响 prompt 格式化,适配不同训练数据结构。
【RoPE 插值方法】用于扩展模型上下文长度:
- none:不启用插值,只使用默认的 RoPE。
- linear:线性插值法,广泛用于上下文扩展(如从 2K 扩展到 8K、32K)。
- yam:Yarn-Aware Method,Yarn 插值的衍生方法。
- llama3:LLaMA3 模型使用的插值方案,已被验证性能优秀。
- dynatic:动态调整的插值方案(Dynamic RoPE Interpolation),提升长上下文效果。
【加速方法】
- auto:自动选择最优的加速方法。
- flashattn2:FlashAttention v2,显著提高 Transformer 中注意力模块的速度和效率。
- unsloth:用于极高效训练,尤其配合 LoRA 等技术,适用于 consumer GPU。
- liger_kernel:专为 NVIDIA GPU 优化的 kernel 级推理加速,速度极快。

3.3,数据集
llama-factory目前只支持两种格式的数据集:Alpaca格式和Sharegpt格式
Alpaca 格式(单单轮指令跟随任务):每条数据是一个 JSON 对象。
{"instruction": "请写一篇关于气候变化的短文。","input": "","output": "气候变化是指由于自然因素和人类活动导致的气候系统的长期变化..." }ShareGPT 格式(多轮对话训练):通常是一个列表,每条数据是一个对话(dialogue),每个对话是多轮消息的列表。
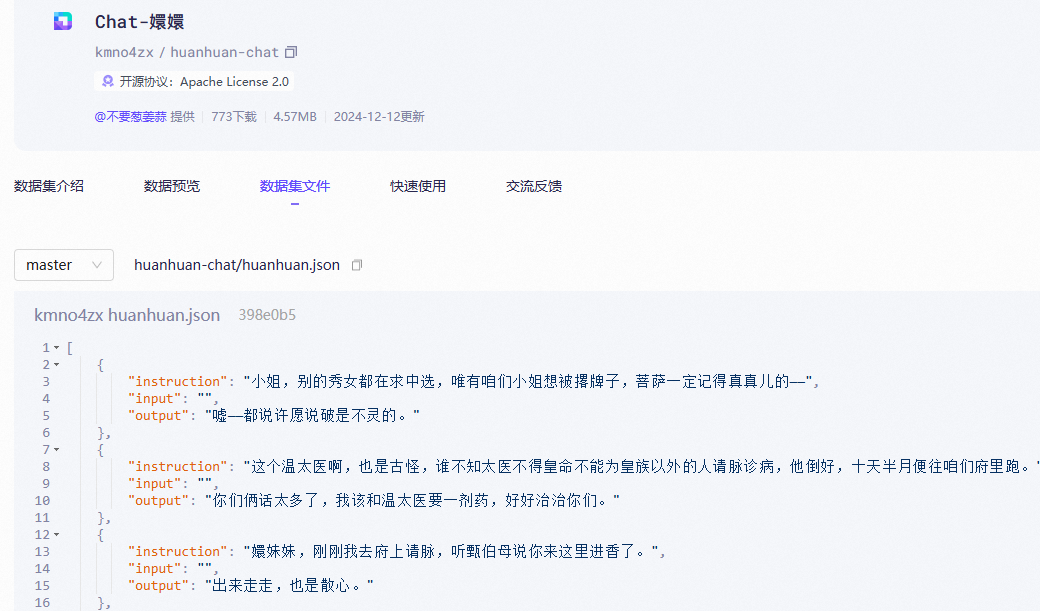
[{"conversations": [{"from": "human","value": "你好,你是谁?"},{"from": "gpt","value": "你好!我是由OpenAI训练的大语言模型,很高兴为你服务。"},{"from": "human","value": "你能告诉我关于机器学习的基础知识吗?"},{"from": "gpt","value": "当然可以!机器学习是人工智能的一个子领域,主要研究如何让计算机通过数据自动学习和改进..."}]} ]【甄嬛数据集】魔搭社区
modelscope download --dataset kmno4zx/huanhuan-chat
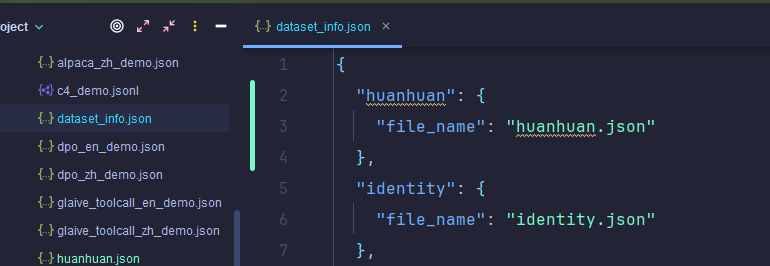
【适配 LLaMA】
- 将下载的数据集放在项目根目录的data文件夹下:
- 修改:dataset_info.json
- 保存之后,webui那边会实时更新,不需要重启


3.4,训练
学习率:可以不用修改
训练轮数:可以选择1轮,会快一些(如果后面发现效果不理想,可以多训练几轮),我这里最终选择了3轮,因为我发现仅1轮效果不佳。
最大梯度范数:防止梯度爆炸的一种技术,称为 梯度裁剪(Gradient Clipping)。
最大样本数:根据数据集大小和训练需求设置。主要是防止数据量过大导致的内存溢出问题
计算类型:
- fp16:GPU 推理、训练等,NVIDIA 的 Tensor Core 使用该格式(混合精度训练)。节省内存带宽,能更快训练神经网络(尤其是 CNN)。
- bf16:精度虽然比 fp16 更低,但动态范围更大,不易梯度爆炸/消失,更适合在 大模型训练 中替代 fp32。
截断长度:由于我们的数据集都是一些短问答,可以把截断长度设置小一点,为1024(默认是2048)
批处理大小:每个 GPU 处理的样本数量。
梯度累计:设置为4
验证集比例:验证集占全部样本的百分比。
学习率调节器:学习率调度器的名称。

日志间隔:多久输出日志信息
保存问题:多久保存权重,这里不是按轮次保存
预热步数:是学习率预热采用的步数,通常设置范围在2-8之间,这里配置4。

lora秩越大(可以看作学习的广度),学习的东西越多,微调之后的效果可能会越好,但是也不是越大越好。太大的话容易造成过拟合(书呆子,照本宣科,不知变通)。
lora缩放系数(可以看作学习强度),越大效果可能会越好,对于一些用于复杂场景的数据集可以设置更大一些,简单场景的数据集可以稍微小一点。
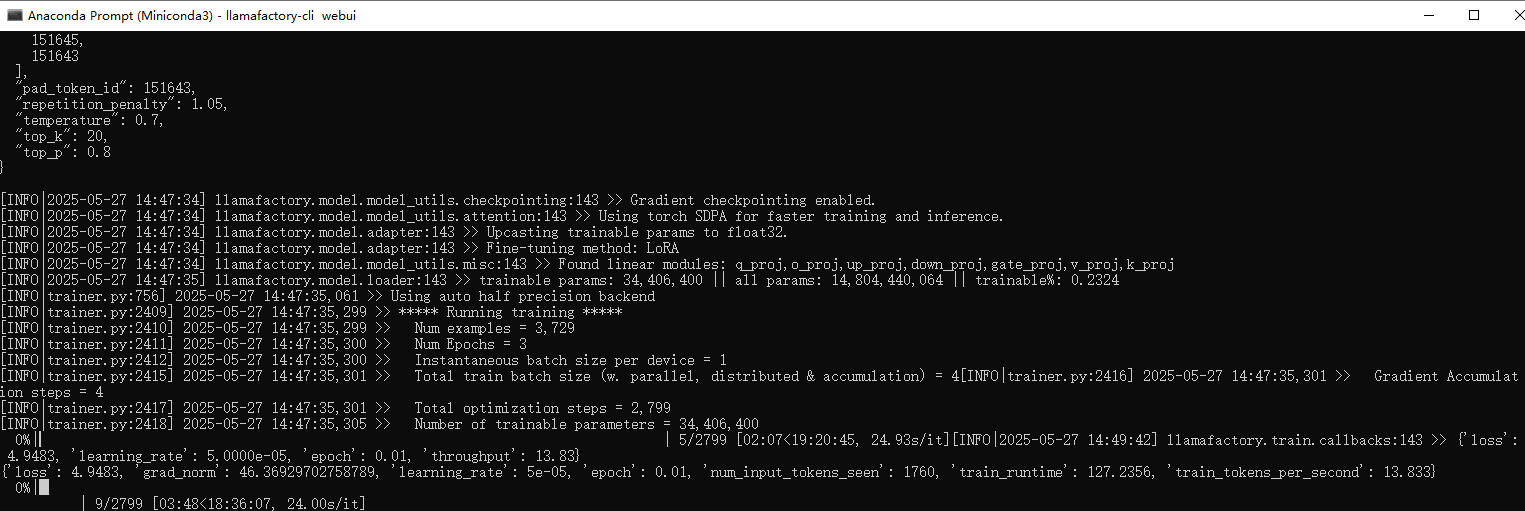
一轮接近24小时,在个人设备考虑微调小参数模型,这里14B的耗时实在是太久了。
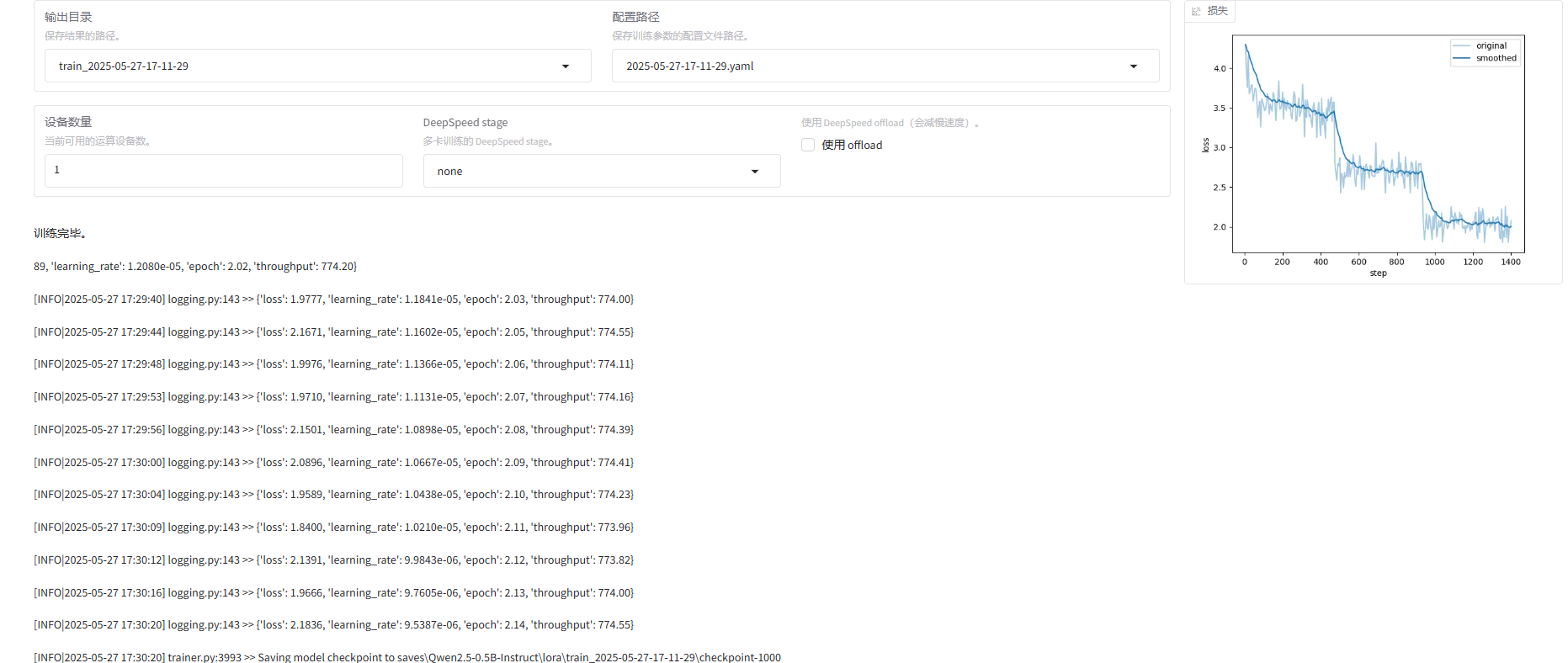
训练结束:
如果想重新微调,记得改一下下面两个值


3.5,测试
微调成功后,在检查点路径这里,下拉可以选择刚刚微调好的模型:
把窗口切换到chat,点击加载模型:


【模型导出】切换到export,填写导出目录 /app/output/qwen2-0.5b-huanhuan
D:\app\output\qwen2-0.5b-huanhuanfrom modelscope import AutoModelForCausalLM, AutoTokenizermodel_name = "D:\\app\\output\\qwen2-0.5b-huanhuan"model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto" ) tokenizer = AutoTokenizer.from_pretrained(model_name)prompt = "你好啊,请问你是谁" messages = [{"role": "system", "content": "你是甄嬛"},{"role": "user", "content": prompt} ] text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True ) model_inputs = tokenizer([text], return_tensors="pt").to(model.device)generated_ids = model.generate(**model_inputs,max_new_tokens=512 ) generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids) ]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0] print(response) ====================== 我是甄嬛,家父是大理寺少卿甄远道。