决策树 GBDT XGBoost LightGBM
一、决策树
1. 决策树有一个很强的假设:
信息是可分的,否则无法进行特征分支
2. 决策树的种类:
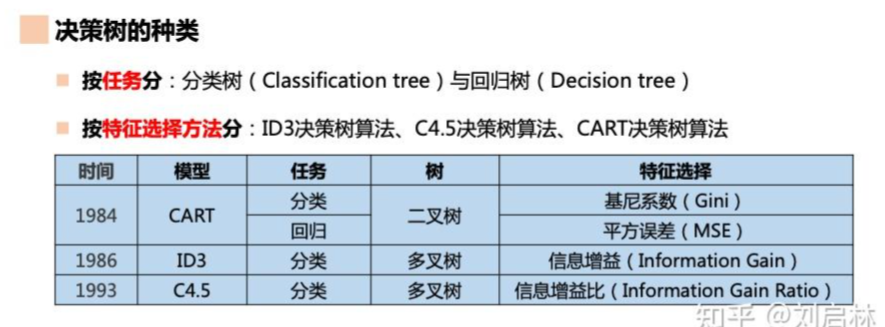
2. ID3决策树:
ID3决策树的数划分标准是信息增益:
信息增益衡量的是通过某个特征进行数据划分前后熵的变化量。但是,它没有考虑到特征本身的熵,因此容易偏向于取值较多的特征。
3. C4.5决策树:
C4.5决策树的数划分标准是信息增益比:
信息增益比则是 信息增益 除以 该特征自身的熵(也称为分裂信息)。这种方法旨在纠正信息增益对于取值较多特征的偏爱,通过将信息增益与特征自身的熵相除来惩罚那些拥有大量取值的特征。
C4.5并没有直接偏向于取值少的特征,而是通过分裂信息来调整信息增益,使得特征的基数大小影响其最终的选择概率。这种方式帮助算法避免了仅仅基于信息增益选择特征可能导致的过拟合问题,特别是当存在高基数特征时。
4. CART 回归树 和 分类树:
回归树:每个子树的输出是该子树节点值的均值:
步骤(1):选择最优切分变量和切分点

步骤(2):划分区域并决定输出值
根据特征jj和切分点ss将数据集划分为两个子区域
计算子区域内的样本目标值的平均值作为该区域的预测值
这两个步骤描述了递归地应用上述过程,直到满足停止条件,并最终生成决策树的过程。
5. CART 的参数:

6. CART 训练后的回归树常用属性:
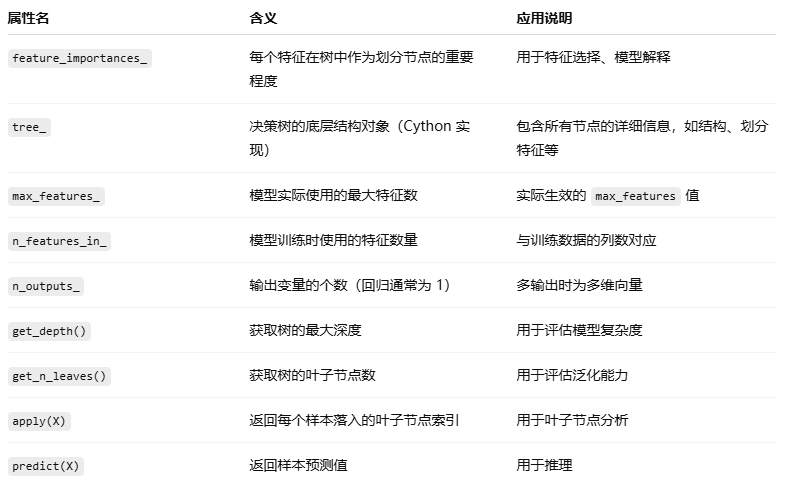
为什么获取树的叶子节点数 就可以用于评估泛化能力?
叶子节点数量越多,意味着决策树越复杂。每个叶子节点代表一个具体的预测规则或输出值。如果一棵树的叶子节点过多,说明它可能已经学习了训练数据中的很多细节甚至是噪音,这种现象通常被称为过拟合。过拟合模型在训练集上表现很好,但在未见过的数据(测试集)上的表现较差。
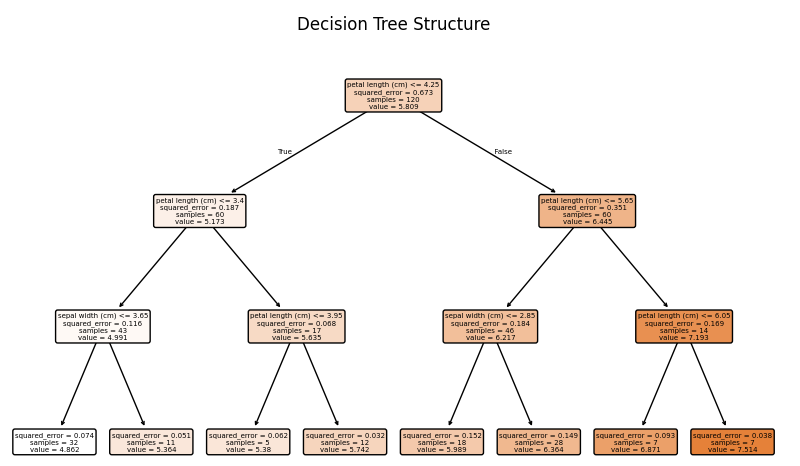
7. 回归树demo展示,可视化回归树:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeRegressor, plot_tree
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt# 1. 加载数据
data = load_iris()
X = data.data
y = X[:, 0] # 用 sepal length 做回归目标# 2. 数据划分
X_train, X_test, y_train, y_test = train_test_split(X[:, 1:], y, test_size=0.2, random_state=42)# 3. 建立模型
reg = DecisionTreeRegressor(max_depth=3, random_state=42)
reg.fit(X_train, y_train)# 4. 模型预测与评估
y_pred = reg.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"\n【模型评估】\n均方误差 MSE: {mse:.4f}")# 5. 打印常用属性
print("\n【模型属性展示】")
print("特征重要性 feature_importances_:", reg.feature_importances_)
print("使用特征数 n_features_in_:", reg.n_features_in_)
print("输出维度数 n_outputs_:", reg.n_outputs_)
print("实际使用的 max_features_:", reg.max_features_)
print("树最大深度 get_depth():", reg.get_depth())
print("叶子节点数 get_n_leaves():", reg.get_n_leaves())# 6. 可视化特征重要性
feature_names = data.feature_names[1:]
plt.figure(figsize=(6, 4))
plt.bar(feature_names, reg.feature_importances_, color='teal')
plt.title("Feature Importances")
plt.ylabel("Importance")
plt.grid(axis='y')
plt.tight_layout()
plt.show()# 7. 可视化树结构
plt.figure(figsize=(10, 6))
plot_tree(reg, feature_names=feature_names, filled=True, rounded=True)
plt.title("Decision Tree Structure")
plt.show()
8. 分类树:
sklearn 的模型参数:

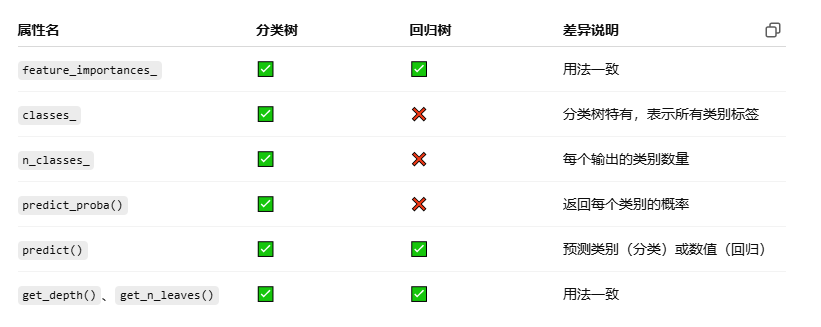
模型属性对比:
demo:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 1. 数据准备
iris = load_iris()
X = iris.data
y = iris.target# 2. 划分数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 3. 构建模型(使用信息增益)
clf = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=42)
clf.fit(X_train, y_train)# 4. 预测与评估
y_pred = clf.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print(f"准确率: {acc:.4f}")# 5. 展示分类专有属性
print("\n【分类树专有属性】")
print("类别标签 classes_:", clf.classes_)
print("类别数量 n_classes_:", clf.n_classes_)
print("每个测试样本的预测概率 predict_proba():\n", clf.predict_proba(X_test[:5]))
二、Boosting:
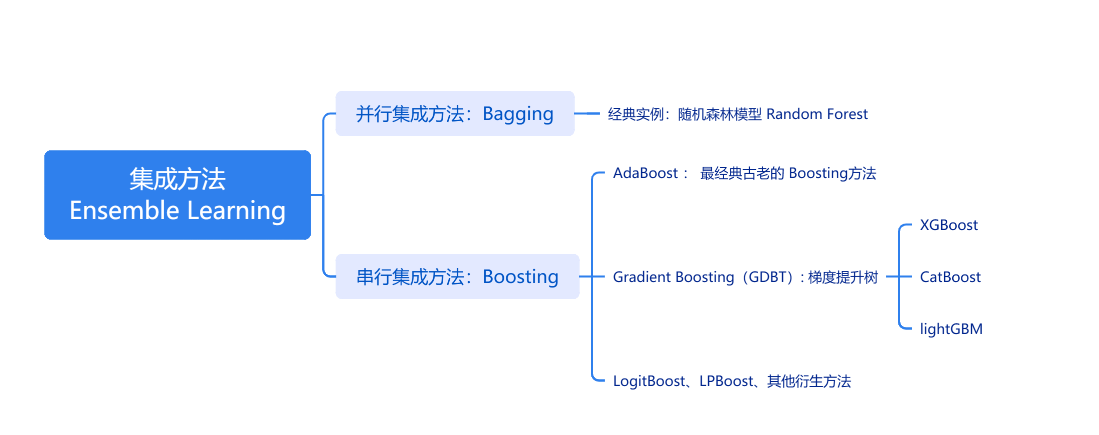
Boosting 中文是“提升方法”,是一种集成学习方法,它只是一个“策略思想”。
AdaBoost、GDBT、 XGBoost、LightGBM 都是这个思想的具体实现。
Boosting 将多个弱学习器(weak learner),如小决策树,串行地组合在一起,每一轮都“纠正”上一轮的错误,最终得到一个强大的集成模型。
Gradient Boosting:英文缩写 GDBT ,中文是“梯度提升树”或“提升树”、“提升树模型”。
(2)Gradient Boosting:英文缩写 GDBT ,中文是“梯度提升树”或“提升树”、“提升树模型”。
注意:提升树 ≈ GBDT(及其变种) ≠ AdaBoost
1. AdaBoost:
注意:不同于GDBT,AdaBoost 在第 t 轮不直接使用前一轮训练出的模型,而是通过样本权重的改变,间接地反映之前模型的表现。
AdaBoost 每一轮都是从头训练一个新的弱学习器 ,只是通过每次迭代将 训练样本分布进行调整,令错分样本权重更大
2. GDBT:
GBDT 是一种通过迭代拟合损失函数负梯度(即残差)的方式训练多个决策树并进行加权求和的Boosting 方法。GDBT使用回归树作为弱学习器(哪怕是分类任务)。
GBDT 的“Gradient”不是装饰,它真的是在做梯度下降,只是回归时,常用的损失函数是平方误差(MSE)的公式为:
对于MSE 的负梯度为:

MSE的负梯度刚好有一个可描述的名字,就是残差,因此可以理解为一种巧合hh
再举个例子:
GBDT 用于二分类,使用对数损失(Log Loss):
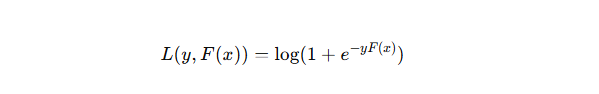
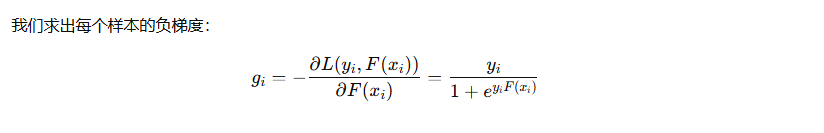
那么,在 GBDT 的每一轮中,就是用这些 负梯度 gi 作为新的“伪标签”来训练一个 回归树。在新的一轮迭代中,这个回归树试图学习xi → gi 。该回归树不是去做分类,而是用回归树去逼近这个负梯度值(伪残差)
你看到的是“残差”,其实它背后是“负梯度”;
这个巧合让 GBDT 在回归问题上看起来像“残差堆树”,但本质上是一种通用的函数空间梯度优化方法。

1. 集成学习:

2. Boosting 工作机制:
Boosting 的每一轮训练模型都试图学习 当前预测值与真实值之间的差值(残差),从而逐步缩小误差。
Boosting 不是一开始就拟合目标,而是每次都只拟合 还没学会的部分,就像学生每天复习昨天不会的题,反复训练,直到掌握。



提升树算法通过逐次拟合残差并不断优化模型,能够有效地提高模型的预测精度,且避免模型过拟合,具体来说,原因如下:
(1)逐步拟合残差,避免直接过拟合目标
每一步学习的目标是上一步的误差(残差),不是一次性“猜中全部”。
这种“加法模型”方式可以让模型以小步慢走的方式逐渐逼近真实目标。
(2)模型弱但组合强
Boosting 通常使用弱学习器(如深度很浅的决策树)。
单个模型能力弱,不容易过拟合,但组合起来又能表现强。
总结参考:
感谢大佬的无私分享,同时加入了一些自己的总结和理解,欢迎批评指正,相互交流~
决策树(ID3、C4.5、CART)的原理、Python实现、Sklearn可视化和应用 - 知乎