深入解析Google多线程环境下的空间配置器——TCMalloc
深入解析Google多线程环境下的空间配置器——TCMalloc

tcmalloc原码
模拟实现
一、引言
操作系统提供了如Linux中brk和sbrk等直接操作堆内存的接口,但频繁的系统调用会带来显著的性能损耗。为此,空间配置器应运而生,其核心思想是通过内存池化技术减少对操作系统的直接调用。例如,Glibc中的Ptmalloc便是经典实现,而Google开发的**TCMalloc(Thread-Caching Malloc)**则在多线程场景下展现出更强的优势。
从Go语言的内存分配机制可见一斑:它放弃传统的malloc接口,转而基于TCMalloc实现内存管理。TCMalloc通过将内存划分为不同尺寸的块,结合多级缓存架构(线程缓存、中心缓存、页缓存),在多线程环境下实现了高效的内存分配与回收。本文将深入剖析其设计原理与实现细节。
二、空间配置器与内存池基础
2.1 空间配置器的本质
空间配置器是管理内存分配与释放的核心组件,其核心目标是:
- 减少系统调用开销:避免频繁调用操作系统接口(如
malloc/free)。 - 降低内存碎片:通过预分配和复用机制优化内存使用。
- 支持多线程安全:在并发场景下实现高效的资源管理。
2.2 内存池与定长内存池
**内存池(Memory Pool)**通过预分配大块内存,按需切分小块供应用层使用,回收时仅标记为可用而非立即释放,本质是“资源复用”。
定长内存池是其简化实现,针对固定大小的内存块进行管理:
- 申请逻辑:优先从空闲链表中获取,若无则从大块内存中切分。
- 释放逻辑:将内存块直接归还到空闲链表(头插法)。
// 定长内存池实现(简化版)
template <class T>
class ObjectPool {
private:char* _memory; // 预分配的大块内存起始地址size_t _remain_bytes; // 剩余可用内存大小void* _free_list; // 空闲内存块链表(通过地址前4/8字节存储next指针)public:T* New() {if (_free_list) { // 从空闲链表获取void* next = *(void**)_free_list;T* obj = static_cast<T*>(_free_list);_free_list = next;return obj;}// 无空闲块则切分大块内存if (_remain_bytes < sizeof(T)) { /* 扩容逻辑 */ }T* obj = reinterpret_cast<T*>(_memory);_memory += sizeof(T);_remain_bytes -= sizeof(T);new(obj) T(); // 定位new初始化对象return obj;}void Delete(T* obj) {obj->~T(); // 显式调用析构函数*(void**)obj = _free_list; // 头插法归还内存块_free_list = obj;}
};
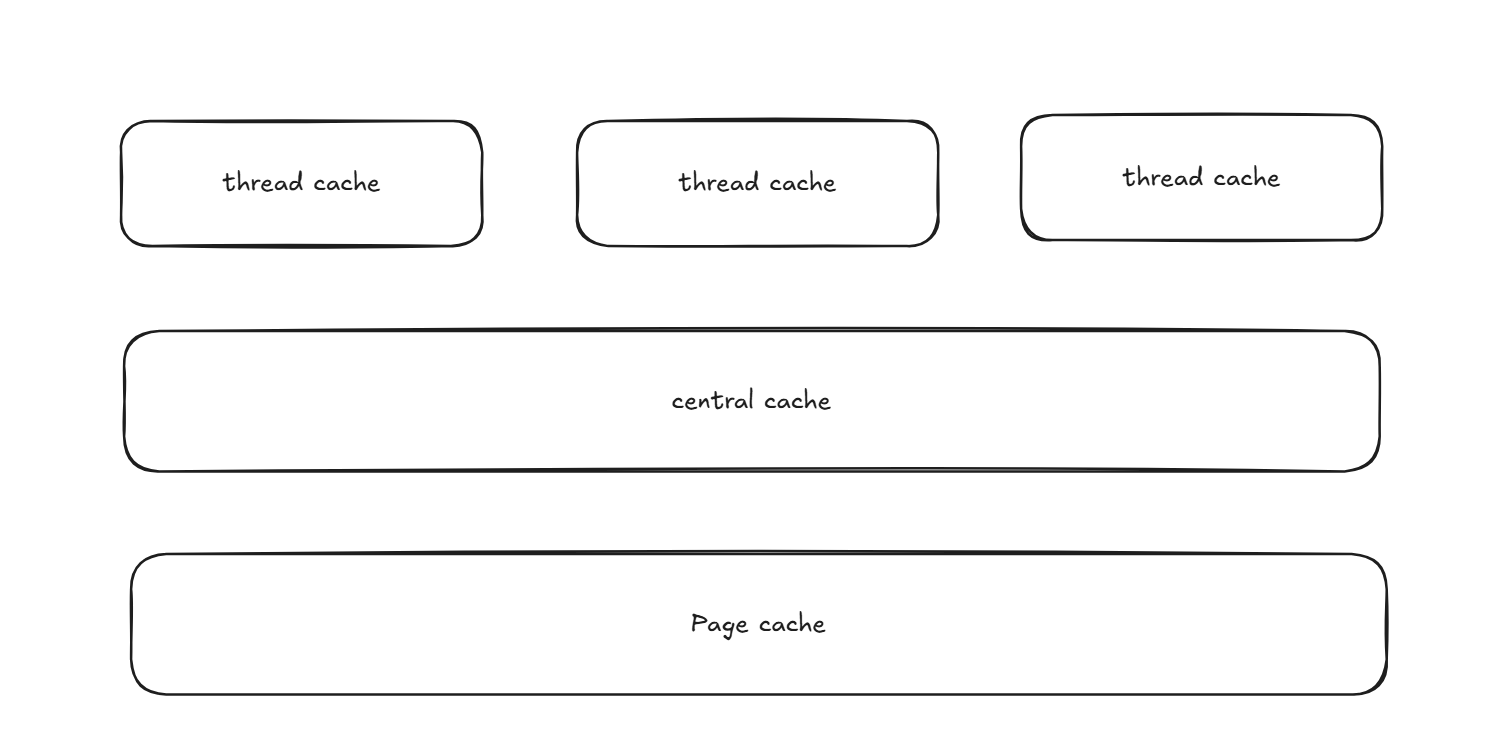
三、TCMalloc的核心架构:三级缓存体系
TCMalloc将内存分配分为线程缓存(Thread Cache)、中心缓存(Central Cache)、**页缓存(Page Cache)**三层,逐层处理不同规模的内存请求,如图所示:
3.1 线程缓存(Thread Cache)

设计目标
利用**线程局部存储(TLS)**技术,为每个线程提供独立的内存缓存,避免多线程竞争。仅处理≤256KB的小内存块,实现无锁快速分配。
线程局部存储(TLS)是一种内存管理方法,它允许每个线程在多线程进程中分配特定于线程的数据存储位置。TLS 使得在多线程环境中,每个线程可以拥有自己的全局变量副本,从而避免了线程之间的数据竞争和同步问题。
内存对齐与哈希表管理
- 内存对齐:将用户请求的任意字节数对齐到预设的规格化尺寸,减少哈希表桶的数量。
对齐规则:- ≤128B:按8B对齐(如10B→16B)。
- ≤1KB:按16B对齐。
- ≤8KB:按128B对齐。
- ≤64KB:按1KB对齐。
- ≤256KB:按8KB对齐。
static inline size_t roundUpHelper(size_t bytes, size_t alignNum){return ((bytes + alignNum - 1) & ~(alignNum - 1));}
static inline size_t roundUp(size_t size){if (size <= 128){return roundUpHelper(size, 8);}else if (size <= 1024){return roundUpHelper(size, 16);}else if (size <= 8 * 1024){return roundUpHelper(size, 128);}else if (size <= 64 * 1024){return roundUpHelper(size, 1024);}else if (size <= 256 * 1024){return roundUpHelper(size, 8 * 1024);}else // 以page对齐{return roundUpHelper(size, 1 << PAGE_SHIFT);}}
如果我们申请空间的时候Thread Cache没有对应的内存块,这个时候,就要引入我们的Central Cache(中心缓存)
- 哈希表结构:以对齐后的尺寸为键,维护对应尺寸的空闲块链表。申请时直接取链表头部,释放时头插回链表,全程无锁。
3.2 中心缓存(Central Cache)
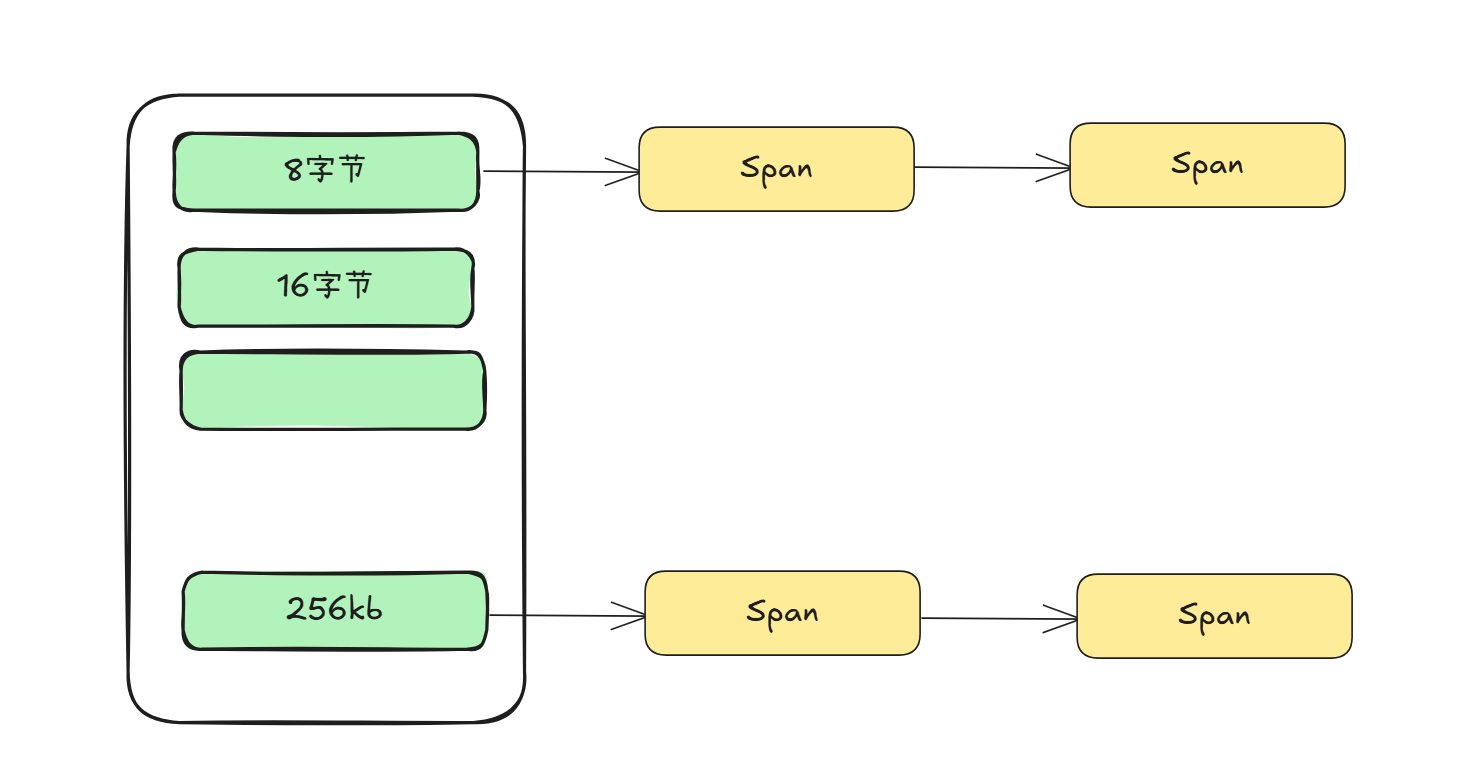
核心作用
作为线程缓存的“供给站”,管理跨线程的内存块复用,解决线程缓存间的资源不均衡问题。
数据结构:Span与桶锁
- Span结构:
表示一组连续的页(Page),是内存块分配的基本单位。例如,8B内存块对应的Span可能由1个页(4KB)切分而来,包含512个8B块。struct Span {PAGE_ID id; // 页起始地址标识size_t n; // 页数量void* free_list; // 空闲内存块链表size_t use_count; // 已分配给线程缓存的块数Span* next, *prev; // 双向链表指针 }; - 桶锁机制:
每个规格化尺寸对应一个桶(Bucket),桶内维护Span链表,并配备独立的锁(桶锁)。线程缓存向中心缓存申请内存时,仅需锁定对应桶,而非全局锁,降低锁竞争。
交互流程
- 线程缓存申请:当线程缓存无空闲块时,向中心缓存对应桶申请一批内存块(批量获取以减少锁开销)。
- 中心缓存分配:找到对应桶的Span,从
free_list中取出一批块返回给线程缓存,更新use_count。 - 线程缓存释放:释放的块先归还到线程缓存链表,当链表长度超过阈值时,批量归还到中心缓存,解锁后合并到Span的
free_list。
3.3 页缓存(Page Cache)
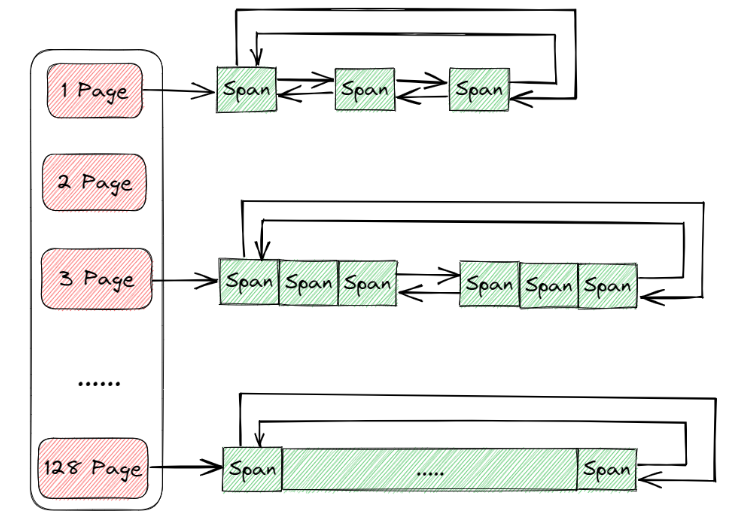
定位与功能
作为内存分配的“底层数据源”,直接与操作系统交互,管理以页(通常4KB)为单位的大块内存。负责:
- 向操作系统申请/释放内存(通过
brk)。 - 为中心缓存提供Span(切分大页块为小页块)。
- 合并相邻空闲页,减少内存碎片。
实现细节
- 全局锁与页链表:
页缓存使用全局锁保证线程安全,维护不同页数的Span链表(如1页、2页、3页…)。 - 内存分配逻辑:
当中心缓存需要新的Span时,页缓存执行以下步骤:- 查找对应页数的Span链表,若有空闲Span则直接分配。
- 若无,向后查找更大页数的Span(如申请2页时,查3页Span),切分为目标页数和剩余页数的Span,分别挂入对应链表。
- 若所有链表均无可用Span,向操作系统申请一大块内存(如128页),拆分为多个小Span。
- 内存回收逻辑:
当Span完全空闲时,尝试与相邻空闲Span合并,合并后挂入更大页数的链表,超过阈值时释放回操作系统。
四、TCMalloc的多线程优化关键点
- 无锁线程缓存:
每个线程独立管理小规模内存块,避免锁竞争,适用于高频小内存分配场景。 - 分级锁策略:
中心缓存使用桶锁(按尺寸分桶),页缓存使用全局锁,平衡锁粒度与实现复杂度。 - 批量操作减少开销:
线程缓存与中心缓存之间批量申请/释放内存块(如一次申请64个块),降低锁获取次数。 - 内存碎片管理:
通过Span的合并机制(页缓存层)和规格化尺寸(线程/中心缓存层),减少外部碎片与内部碎片。
五、总结
TCMalloc通过三级缓存架构与精细化锁策略,在多线程环境下实现了高效的内存管理:
- 线程缓存解决高频小内存的无锁快速分配。
- 中心缓存平衡线程间内存资源,避免饥饿。
- 页缓存对接操作系统,处理大块内存的分配与回收。
这种设计不仅显著降低了多线程竞争带来的性能损耗,还通过内存对齐、Span管理和批量操作等技术,优化了内存利用率与分配速度。