李沐《动手学深度学习》 | 4.5-4.6 正则化技术:权重衰退与Dropout
文章目录
- 正则化
- 权重衰退:常用抑制过拟合的方法
- 总结:权重衰退抑制过拟合的机制
- 权重衰减代码演示
- Q&A
- Dropout丢弃法
- 重新审视过拟合
- 扰动的稳健性
- 丢弃法:在层之间加入噪音 - 正则化技术
- 无偏向的方式注入噪声
- 在训练过程中的dropout
- 推理中(预测)的丢弃法
- 代码实现
- 简洁实现
- Q&A
正则化
过拟合指的是只能拟合训练数据,但不能很好地拟合不包含在训练数据中的其他数据。
机器学习的目标是提高泛化能力,即便是没有包含在训练数据里的未观测数据,也希望模型可以进行正确的识别。
过拟合的原因主要
- 模型拥有大量参数、表现力强
- 训练数据少
正则化定义:通过约束模型复杂度来抑制过拟合
说明:正则项只在训练时使用,只对权重产生影响。
权重衰退和dropout都是正则化技术
权重衰退:常用抑制过拟合的方法
权值衰退:通过在学习的过程中对大的权重进行惩罚,来抑制过拟合。
很多过拟合原本就是因为权重参数值过大才发生的。假设权重 w w w特别大,则特征 x i x_i xi的微小变化会被放大,导致输出剧烈波动。=> 实际影响:模型会过度关注训练数据中的噪声,而非数据中的整体规律
解释:若数据中存在噪声或局部异常值,复杂模型需通过大权重调整输出,使其剧烈弯曲以穿过这些点。大权重使模型函数在某些区域呈现高频震荡,完美拟合训练噪声,但无法泛化到新数据。
使用均方范数作为硬性限制
通过限制参数值的选择范围来控制模型的容量。
神经网络学习目的是减少损失函数的值 min l ( w , b ) \min\;l(w,b) minl(w,b),在最小化损失值的时候,我们加入一个限制 ∣ ∣ w ∣ ∣ 2 ≤ θ ||w||^2 \leq \theta ∣∣w∣∣2≤θ,小的 θ \theta θ意味着更强的正则项。
一般不会使用这个作为优化函数,因为优化起来很麻烦。
使用均方范数作为柔性限制
对每个 θ \theta θ,都可以找到 λ \lambda λ使得之前的目标函数等价于 min w , b l ( w , b ) + λ 2 ∣ ∣ w ∣ ∣ 2 \min_{w,b} l(w,b) + \frac{\lambda}{2}||w||^2 minw,bl(w,b)+2λ∣∣w∣∣2=> 我们需要找到一个同时最小化原始损失函数和权重的大小的参数值。
- 原损失项 l ( w , b ) l(w,b) l(w,b):衡量模型预测值与真实值的误差
- 正则项 λ 2 ∣ ∣ w ∣ ∣ 2 \frac{\lambda}{2}||w||^2 2λ∣∣w∣∣2:惩罚 权重的平方和 ∥ w ∥ 2 = w 1 2 + w 2 2 + ⋯ + w n 2 ∥w∥^2=w_1^2+w_2^2+⋯+w_n^2 ∥w∥2=w12+w22+⋯+wn2,其中超参数 λ \lambda λ控制了正则项的重要程度, λ \lambda λ设置的越大,对大的权重施加的惩罚就越重。
- 当 λ \lambda λ增大时,正则项 λ 2 ∣ ∣ w ∣ ∣ 2 \frac{\lambda}{2}||w||^2 2λ∣∣w∣∣2 在目标函数中的权重增加。优化过程会优先降低权重的平方和,迫使模型选择较小的权重。
- 如果某个权重 w i w_i wi 较大,其平方值 w i 2 w_i^2 wi2 会显著增大正则项的值。较大的 λ \lambda λ会放大这种惩罚,直接抑制权重的增长。
情况分析
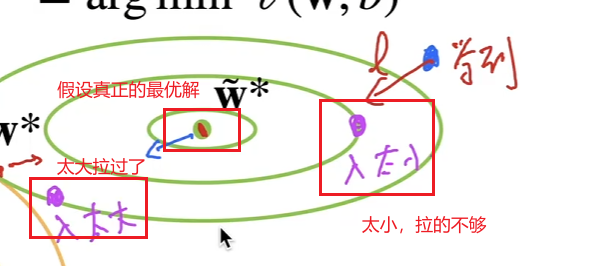
当 λ = 0 \lambda = 0 λ=0,目标函数退化为为原始损失 m i n l ( w , b ) min\;l(w,b) minl(w,b),模型只关注最小化训练误差,可能学习到复杂的权重组合,导致过拟合。
当 λ = 10 \lambda=10 λ=10,正则项占主导地位,模型必须显著减小权重以最小化目标函数。权重被迫趋近于0,模型退化为简单函数,可能欠拟合。如果 λ − > ∞ \lambda -> \infty λ−>∞,那么 w ∗ − > 0 w^* ->0 w∗−>0。

优化过程
在梯度下降中,时间t的权重更新公式为: w t + 1 ← w t − η ( ∂ l ( w t , b ) ∂ w t + λ w t ) = ( 1 − η λ ) w t − η ∂ l ( w t , b ) ∂ w t w_{t+1}←w_t−η(\frac{∂l(w_t,b)}{∂w_t}+λw_t) = (1-η\lambda)w_t - η\frac{∂l(w_t,b)}{∂w_t} wt+1←wt−η(∂wt∂l(wt,b)+λwt)=(1−ηλ)wt−η∂wt∂l(wt,b)
每次更新时,权重会被主动削减(减去 λ w λw λw)。 λ λ λ 越大,削减力度越强,权重衰减越快。
通常 η λ < 1 η\lambda<1 ηλ<1, λ \lambda λ的引入使得每次更新参数时将当前的权重 w t w_t wt进行了缩小(看作一次衰退),所以在深度学习中通常叫做权重衰退。
总结:权重衰退抑制过拟合的机制
- 过拟合的成因
当模型参数数量过多或数值过大时,模型具备足够的“容量”去拟合训练数据中的噪声和无关细节,而非学习数据背后的真实规律。
- 模型的参数数量多:影响模型的理论容量(可能表示复杂函数)
- 参数数值大:实际利用这种容量去拟合噪声
核心:即使参数数量多,若参数值被限制为小量,模型的实际复杂度仍可控制。
- 权重衰退可以抑制过拟合的原因
原理:通过限制参数值的选择范围来控制模型容量
权重衰退(L2正则化)通过在损失函数中增加惩罚项 λ 2 ∥ w ∥ 2 \frac{λ}{2}∥w∥^2 2λ∥w∥2,直接限制权重的大小。
优化目标变为:在降低训练误差和保持小权重之间权衡。
λ \lambda λ是控制模型复杂度的超参数, λ \lambda λ越大,权重的最优值 w ∗ w^* w∗越小
- 降低模型实际复杂度的思路
权重衰退→参数值小→模型输出平滑→实际复杂度降低→过拟合风险减少
权重衰减代码演示
案例:高维线性回归
- 生成人工数据集
y = 0.05 + ∑ i = 1 d 0.01 x i + ϵ w h e r e ϵ N ( 0 , 0.1 2 ) y=0.05+\sum_{i=1}^{d}0.01x_i+\epsilon \;\;\;where\;\epsilon~N(0,0.1^2) y=0.05+∑i=1d0.01xi+ϵwhereϵ N(0,0.12),其中偏差b为0.05,权重为0.01,噪声 ϵ \epsilon ϵ。
为了使过拟合的效果更加明显,我们可以将问题的维数增加到 d = 200 d=200 d=200, 并使用一个只包含20个样本的小训练集。
# 训练集样本数n_train为20
# num_inputs 为输入的特征维度
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
# 生成一个全为1的张量,生成一个形状为 (num_inputs, 1) 的权重向量。所有元素初始化为 0.01。
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
# 生成合成训练数据
train_data = d2l.synthetic_data(true_w, true_b, n_train)
# 将数据转换为 PyTorch 的 DataLoader
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
- 初始化模型参数
def init_params():w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)b = torch.zeros(1, requires_grad=True)return [w, b]
- 定义 L 2 L_2 L2范数惩罚
∥ w ∥ 2 = w 1 2 + w 2 2 + ⋯ + w n 2 ∥w∥^2=w_1^2+w_2^2+⋯+w_n^2 ∥w∥2=w12+w22+⋯+wn2,这里还没有写 λ \lambda λ,我们将 λ \lambda λ写在后面。
def l2_penalty(w):return torch.sum(w.pow(2)) / 2
- 定义训练代码实现
lambda X: d2l.linreg(X, w, b):创建一个匿名函数,接受输入x作为参数,并返回d2l.linreg的计算结果。
torch.norm(w)计算张量w的 L 2 L_2 L2范数,数学公式是 ∥ w ∥ 2 = ( w 1 2 + w 2 2 + ⋯ + w n 2 ∥w∥_2=\sqrt{(w_1^2+w_2^2+⋯+w_n^2} ∥w∥2=(w12+w22+⋯+wn2,
PyTorch 张量包含梯度信息及设备信息(如 CPU/GPU),直接打印会显示冗余信息,.item将单元素张量转换为 Python 标量
# 超参数lambd
def train(lambd):w, b = init_params()# 等价于#def net(X):# return d2l.linreg(X,w,b)# loss是均方损失net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_lossnum_epochs, lr = 100, 0.003animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',xlim=[5, num_epochs], legend=['train', 'test'])for epoch in range(num_epochs):for X, y in train_iter:# 增加了L2范数惩罚项,# 广播机制使l2_penalty(w)成为一个长度为batch_size的向量l = loss(net(X), y) + lambd * l2_penalty(w)# 将损失张量求和为标量后,进行反向传播以计算梯度。l.sum().backward()d2l.sgd([w, b], lr, batch_size)if (epoch + 1) % 5 == 0:animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),d2l.evaluate_loss(net, test_iter, loss)))print('w的L2范数是:', torch.norm(w).item())
- 结果观察
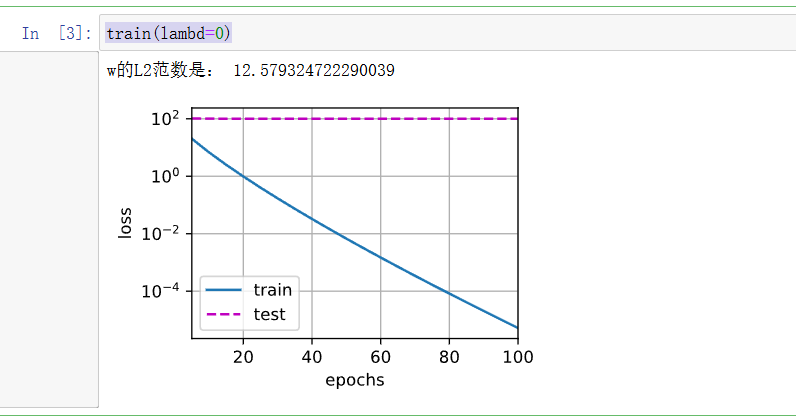
忽略正则化直接训练
我们现在用lambd = 0禁用权重衰减后运行这个代码。
可以发现模型发生了欠拟合现象,在训练集上表现很好,但是在测试集上误差没有减少。
train(lambd=0)
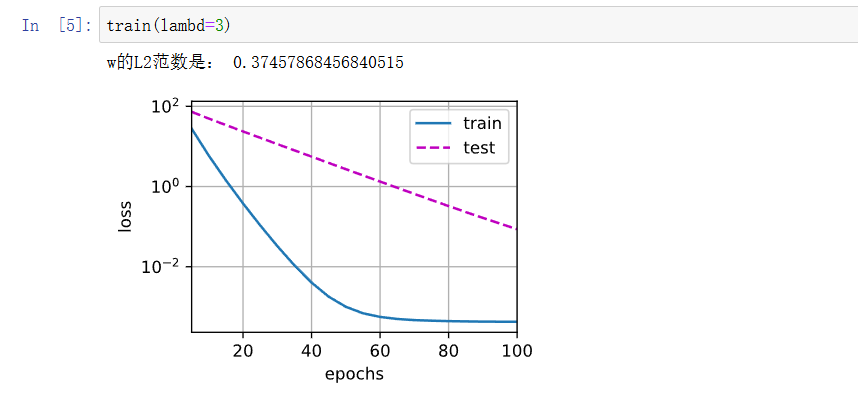
使用权重衰减
虽然还是存在一定程度上的过拟合,但是可以看出测试误差是在减小的。
train(lambd=3)
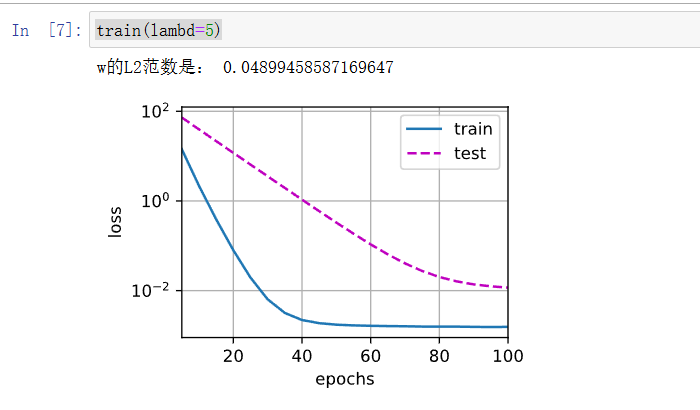
增强 λ \lambda λ的值, w w w的范数会趋近于0
简洁实现
为权重参数 net[0].weight 设置 L2 正则化,weight_decay=wd 等价于在损失函数中添加 w d 2 ∥ w ∥ 2 \frac{wd}{2}∥w∥^2 2wd∥w∥2, w d wd wd是传入的超参数。
nn.Linear(in_features, out_features, bias=True)
in_features:输入数据的特征维度(输入神经元的数量)。out_features:输出数据的特征维度(输出神经元的数量)。bias:是否启用偏置项(默认为True)。
def train_concise(wd):net = nn.Sequential(nn.Linear(num_inputs, 1))# .normal_() 将参数初始化为均值为 0、标准差为 1 的正态分布。 for param in net.parameters():param.data.normal_()loss = nn.MSELoss(reduction='none')num_epochs, lr = 100, 0.003# 偏置参数没有衰减trainer = torch.optim.SGD([{"params":net[0].weight,'weight_decay': wd},{"params":net[0].bias}], lr=lr)animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',xlim=[5, num_epochs], legend=['train', 'test'])for epoch in range(num_epochs):for X, y in train_iter:trainer.zero_grad()l = loss(net(X), y)# .mean() 将批次损失平均为标量l.mean().backward()trainer.step()if (epoch + 1) % 5 == 0:animator.add(epoch + 1,(d2l.evaluate_loss(net, train_iter, loss),d2l.evaluate_loss(net, test_iter, loss)))print('w的L2范数:', net[0].weight.norm().item())
Q&A
问题1:实践中权重衰减的值一般设置为多少?在跑代码的时候总感觉权重衰减的效果并不那么好?
解答:权重衰退的效果有限(并不会带来太大的改善),通常取 1 − 2 、 1 − 3 1^{-2}、1^{-3} 1−2、1−3
问题2:为什么要把 w w w往小的拉?如果最优解的 w w w就是比较大的数,那权重衰减是不是会有反作用?
解答: λ \lambda λ其实就是控制模型怎么处理噪声,控制 w w w往下拉的目的是让模型尽可能少的去拟合噪声。我们希望学习到的模型更平滑一点,让模型更关注数据中的 普遍规律,而非 噪声或偶然细节。。
无关于 w w w本身的大小,这里往小的拉是个相对值,如果最优解 w w w本身是一个比较大的数,但其实学习到的 w w w更大,往小的拉让它更接近最优解而已。
Dropout丢弃法
重新审视过拟合
偏差-方差权衡
泛化性和灵活性之间的权衡呗描述为偏差-方差权衡
- 偏差: 模型预测值与真实值的系统性偏离
- 导致高偏差的原因:模型过于简单,无法捕捉数据规律。
- 方差:模型对训练数据微小变化的敏感性
- 导致方差高的原因:模型过于复杂,过度拟合噪声
偏差-方差权衡核心矛盾
- 降低偏差需要增加模型复杂度
- 降低方差需要简化模型或增加正则化(如减少参数数量、添加 L 2 L_2 L2惩罚项)
- 正则化技术:Dropout、 L 2 L_2 L2正则化
线性模型:高偏差,低方差
当面对更多特征而样本不足时,线性模型往往会过拟合。线性模型的参数数量等于特征数(每个特征对应一个权重)。当特征数 d d d远大于样本数 n n n时,模型自由度(参数数量)过高,容易记住噪声而非真实规律。所以如果样本数量足够多,可以缓解过拟合问题。
线性模型忽略了特征之间的交互作用,对于每个特征,线性模型必须指定正的或负的权重,而忽略其他特征。线性模型的形式为 y = w 1 x 1 + w 2 x 2 + ⋯ + w d x d + b y=w_1x1_+w_2x_2+⋯+w_dx_d+b y=w1x1+w2x2+⋯+wdxd+b,无法直接包含如 x 1 x 2 x_1x_2 x1x2 的交互项。
- 高偏差:线性模型特征与目标呈线性关系,无法表示非线性或特征交互关系。比如用线性模型拟合抛物线数据 y = x 2 y=x^2 y=x2,无论数据多少,始终存在系统性误差。
- 低方差:模型结构简单,对训练数据中的噪声不敏感
神经网络:低偏差,高方差。
- 低偏差:不局限于单独查看每个特征,而是学习特征之间的交互。 神经网络通过非线性激活函数(如 ReLU)和多层结构,能够逼近任意复杂函数,所以神经网络偏差低。
- 高方差:模型复杂,容易过拟合噪声,不同训练集上可能得到差异大的结果。
即使我们有比特征多得多的样本,深度神经网络也有可能过拟合。
扰动的稳健性
好的预测模型
- 简单模型更易泛化,因其假设空间有限,不易过度拟合噪声。
- 好的模型应对输入的微小变化不敏感,即函数具有平滑性(对输入扰动的鲁棒性)
=> 训练的时候就使用具有噪声的训练数据,效果等价于Tikhonov正则化(正则化的效果就是抑制权重大小,避免一定过拟合)
深度网络中的内部注入噪音
斯里瓦斯塔瓦等人提出想法(dropout):在训练过程中,他们建议在计算后续层之前向网络的每一层注入噪声。 因为当训练一个有多层的深层网络时,注入噪声只会在输入-输出映射上增强平滑性。
dropout:在前向传播过程中,计算每一内部层的同时注入噪声,这已经成为训练神经网络的常用技术。
问题:为什么要在深层网络的每一层注入噪声?
解答:在多层网络中,仅对输入层添加噪声(如Bishop的方法)无法有效约束隐藏层中的复杂交互,模型仍可能通过深层非线性变换过拟合数据。在每一层注入噪声,迫使网络从底层到高层逐步学习对扰动鲁棒的特征表示,从而防止神经元之间形成固定依赖关系(防止共适应性)以及使网络对输入的微小变化不敏感(增强平滑性),提高泛化能力。
- 共适应性:指神经元之间形成固定的依赖关系,例如某些神经元必须同时激活才能有效检测某个特征。
- 平滑性:模型对输入的微小变化不敏感,即输入扰动不会导致输出剧烈波动。
问题:如何理解droptout可以防止共适应性和增强平滑性
解答
- 某些神经元会形成固定组合,这种固定组合会导致模型过度依赖训练数据中的特定模式,而非学习通用特征。随机丢弃神经元破坏了这种固定组合,迫使剩余的神经元独立或与其他神经元动态组合。
案例:假设训练图像中的“猫耳”特征由神经元A和B共同激活
无Dropout:A和B始终共同激活,模型依赖这一固定组合,若测试时“猫耳”被遮挡,预测失败。
有Dropout:A或B可能被随机丢弃,模型被迫学习其他神经元(如C检测“胡须”、D检测“眼睛”)作为补充,从而不再依赖单一组合。
- 在训练中,每层输出的随机扰动等效于对模型施加噪声,前面证明增加噪声相当于正则化,所以可以增加平滑性。
案例:假设输入图像添加轻微噪声
无Dropout:模型可能对噪声敏感,导致分类错误。
有Dropout:模型在训练时已习惯神经元随机丢失,对输入噪声具有鲁棒性,输出变化较小.
丢弃法:在层之间加入噪音 - 正则化技术
核心思想:在神经网络的隐藏层中注入噪声,以增强模型的泛化能力。
无偏向的方式注入噪声
描述
对于输入 x x x加入噪声得到扰动点 x ′ = x + ϵ x'=x +\epsilon x′=x+ϵ,希望 E ( x ′ ) = x E(x')=x E(x′)=x
噪声 ϵ \epsilon ϵ需要满足均值 E ( ϵ ) = 0 E(\epsilon)=0 E(ϵ)=0,这样 E ( x ′ ) = E ( x + ϵ ) = E ( x ) + E ( ϵ ) = x + 0 = x E(x′)=E(x+ϵ)=E(x)+E(ϵ)=x+0=x E(x′)=E(x+ϵ)=E(x)+E(ϵ)=x+0=x可以保持数据分布中心不变。
添加噪声的目的是增加模型对输入扰动的鲁棒性,而非改变数据的核心特征。
在概率论中,期望是随机变量的理论平均值
在统计学中,均值是数据样本的算数平均值
具体实现
丢弃法对每个元素进行如下扰动, x i x_i xi是原始输入。给定一个概率p,让输入变成 x i ′ = 0 x'_i=0 xi′=0。其余情况,让输入 x i ′ = x i 1 − p x'_i=\frac{x_i}{1-p} xi′=1−pxi,让原始输入变大一点。
x i ′ = { 0 概率为 p x i 1 − p 其余情况 x'_i=\begin{cases} 0 & 概率为p \\ \frac{x_i}{1-p} & 其余情况 \end{cases} xi′={01−pxi概率为p其余情况, E ( x i ′ ) = 0 ∗ p + x i 1 − p ( 1 − p ) = x i E(x'_i) = 0*p + \frac{x_i}{1-p}(1-p)=x_i E(xi′)=0∗p+1−pxi(1−p)=xi
任何随机的、不可预测的输入变化都可以视为噪声,这里的噪声是乘性且结构化的噪声,而不是传统的高斯加性噪声。
丢弃概率是控制模型复杂度的超参数,常取0.5、0.1、0.9。
操作方式
在训练过程中,随机将当前层的部分神经元的输出置零(丢弃),未被丢弃的神经元的输出会被放大以保持期望值不变。
在训练过程中的dropout
dropout操作通常作用在多层感知机隐藏全连接层的输出上
最初的论文是每一个迭代周期采样一些神经元做子神经网路,后续的研究发现从实验上来看效果很符合正则项的结果,现在主流是将dropout看成正则项。
案例:假设有1个隐藏层和5个隐藏单元的多层感知机, 当我们将暂退法应用到隐藏层,以 p p p的概率将隐藏单元置为零时, 结果可以看作一个只包含原始神经元子集的网络。
每次训练迭代中,Dropout随机生成不同的子网络,比如第一次仅保留神经元1、3、4,第二次保留2、3、4
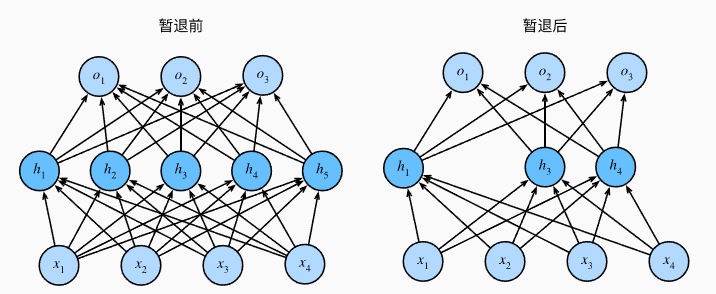
第一个隐含层输出 h = σ ( W 1 x + b 1 ) h=\sigma(W_1x+b_1) h=σ(W1x+b1)
在第一个隐藏层上使用dropout,则 h ′ = d r o p o u t ( h ) h' = dropout(h) h′=dropout(h)
输出层 o = W 2 h ′ + b 2 o=W_2h'+b_2 o=W2h′+b2,将输出进行softmax操作 y = s o f t m a x ( o ) y=softmax(o) y=softmax(o)
推理中(预测)的丢弃法
dropout是一个正则项,正则项只在训练中使用。
正则项只在训练中使用,将影响模型参数的更新。
而在推理(预测)中,丢弃法直接返回输入 h = d r o p o u t ( h ) h=dropout(h) h=dropout(h)。
代码实现
- 实现
dropout操作
dropout_layer 函数以dropout的概率丢弃张量输入X中的元素。
当dropout的概率在0~1之间时,通过生成一个随机’掩码’矩阵,决定哪些神经元被保留,哪些神经元被丢弃。
torch.rand(X.shape)生成一个与输入x形状相同的随机矩阵,每个元素的值在[0,1)之间均匀分布。然后将矩阵中的每个随机数与dropout概率比较,得到一个布尔矩阵,最后将布尔矩阵转换为浮点数矩阵(True->1.0,False-> 0.0)。通过这种方式实现丢弃概率为dropout。
import torch
from torch import nn
from d2l import torch as d2ldef dropout_layer(X, dropout):# 确保丢弃概率dropout在0~1assert 0 <= dropout <= 1# 在本情况中,所有元素都被丢弃if dropout == 1:return torch.zeros_like(X)# 在本情况中,所有元素都被保留if dropout == 0:return Xmask = (torch.rand(X.shape) > dropout).float()return mask * X / (1.0 - dropout)
- 定义模型参数
使用Fashion-MNIST数据集,假设多层感知机拥有2个隐藏层,每个隐藏层包含256个单元
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
- 定义模型
在前向传播时,第1个全连接层 H = X W + b H=XW+b H=XW+b,输入数据X,输出数据是H,将H执行激活函数ReLu操作后得到最终的输出 H 1 H_1 H1。
训练模型时,在每一个层上使用dropout,则 h ′ = d r o p o u t ( h ) h' = dropout(h) h′=dropout(h)
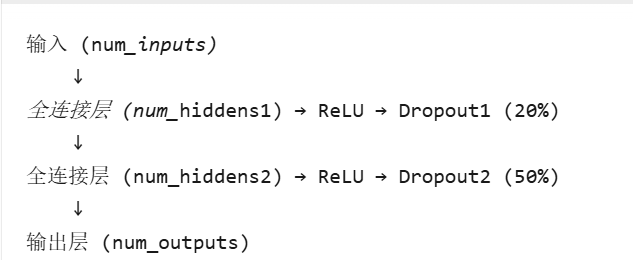
dropout1, dropout2 = 0.2, 0.5class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training = True):# 继承父类nn.Module的初始化方法super(Net, self).__init__() self.num_inputs = num_inputsself.training = is_training# 第1个全连接层 self.lin1 是一个 nn.Linear 类的实例# lin1调用的输入必须是一个二维张量(batch_size,num_inputs)self.lin1 = nn.Linear(num_inputs, num_hiddens1)# 第2个全连接层self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)# 输出层self.lin3 = nn.Linear(num_hiddens2, num_outputs)# 定义激活函数self.relu = nn.ReLU()def forward(self, X):H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))# 只有在训练模型时才使用dropoutif self.training == True:# 在第一个全连接层之后添加一个dropout层H1 = dropout_layer(H1, dropout1)H2 = self.relu(self.lin2(H1))if self.training == True:# 在第二个全连接层之后添加一个dropout层H2 = dropout_layer(H2, dropout2)out = self.lin3(H2)return outnet = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
- 训练和测试
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
新版本的d2l里没有train_ch3,但这个函数又经常被使用,我们将其封装在train.py文件里,然后抛出train_ch3。
train_ch3训练模型,在每一次迭代周期里
- 按批次循环数据,每一个周期里扫完所有的数据
- 将输入数据通过网络计算输出 y ^ \hat y y^
- 用
loss函数计算预测值与真实值的差异。 - 自动计算梯度,然后使用优化器更新模型的参数
# -----train.py(文件名)--------
import torch
from torch import nn
from d2l import torch as d2l# ------------------ 私有函数和类(外部不可见)---------------------
# 返回y_hat与y元素比较的结果数组
def accuracy(y_hat, y):if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum())# 常用的变量累计类
class Accumulator: #@savedef __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]
# 每个epoch的训练过程
def train_epoch(net, train_iter, loss, updater): # @saveif isinstance(net, torch.nn.Module):net.train()metric = Accumulator(3)for X, y in train_iter:y_hat = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.mean().backward()updater.step()else:l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())return metric[0] / metric[2], metric[1] / metric[2]
# 计算在指定数据集上的精准度,返回准确率
def evaluate_accuracy(net, data_iter): # @saveif isinstance(net, torch.nn.Module):net.eval()metric = Accumulator(2)with torch.no_grad():for X, y in data_iter:metric.add(accuracy(net(X), y), y.numel())return metric[0] / metric[1]# ------------------ 公开接口 ---------------------
__all__ = ['train_ch3'] # 定义可导出函数def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):train_metrics = train_epoch(net, train_iter, loss, updater)test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,))
使用方法
# 可以正常调用训练函数
train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
简洁实现
from train import train_ch3
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),# 在第一个全连接层之后添加一个dropout层nn.Dropout(dropout1),nn.Linear(256, 256),nn.ReLU(),# 在第二个全连接层之后添加一个dropout层nn.Dropout(dropout2),nn.Linear(256, 10))def init_weights(m):# 只初始化全连接层if type(m) == nn.Linear:# 权重从N(0, 0.01^2)采样,偏置默认初始化为0nn.init.normal_(m.weight, std=0.01)net.apply(init_weights);num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
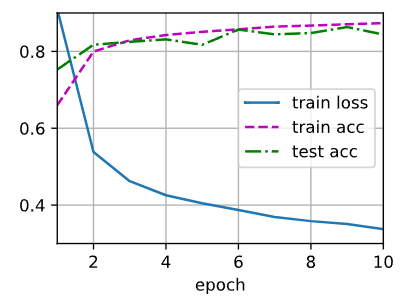
train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)Q&A
问题1:丢弃法是每次迭代一次,随机丢弃一次吗?
解答:每一层在调用前向运算时,都会丢弃一次。比如上述案例的神经网络中有两个Dropout层,那么就会丢弃两次。
问题2:dropout和权重衰退都属于正则,为何dropout效果更好更常用呢?
解答:dropout只在全连接层用,权重衰退更常用适用范围更广,dropout效果好是因为更好调参。