视觉语言多模态模型的优化
视觉语言多模态模型的偏好优化:案例与代码实现
目录
视觉语言多模态模型的偏好优化:案例与代码实现
1. 引言
2. 背景知识
2.1 视觉语言模型(VLM)
2.2 直接偏好优化(DPO)
DPO 的数学基础
2.3 TRL 库
3. 案例:使用 TRL 和 DPO 训练视觉语言模型
3.1 数据集准备
3.2 代码实现
3.2.1 环境依赖
3.2.2 加载数据集
3.2.3 数据预处理
3.2.4 初始化模型
3.2.5 DPO 训练
3.2.6 保存模型
4. 结果分析
4.1 训练过程
4.2 案例测试
5. 进阶优化
5.1 数据增强
5.2 模型架构优化
5.3 高效训练策略
6. 总结
1. 引言
在人工智能领域,视觉语言多模态模型(Visual Language Multimodal Models, VLMs)已成为连接计算机视觉与自然语言处理的重要桥梁。这类模型能够同时处理图像和文本输入,并生成符合人类语境的输出。然而,如何让模型的输出更贴近用户偏好,是当前多模态研究的核心挑战之一。
直接偏好优化(Direct Preference Optimization, DPO) 是一种无需显式奖励模型的强化学习方法,能够通过比较不同回答的用户偏好来优化模型参数。结合 TRL(Transformer Reinforcement Learning) 库,我们可以高效地对视觉语言模型进行偏好优化。本文将通过一个完整的案例,展示如何使用 TRL 和 DPO 对视觉语言模型进行训练,并提供详细的代码实现。
2. 背景知识
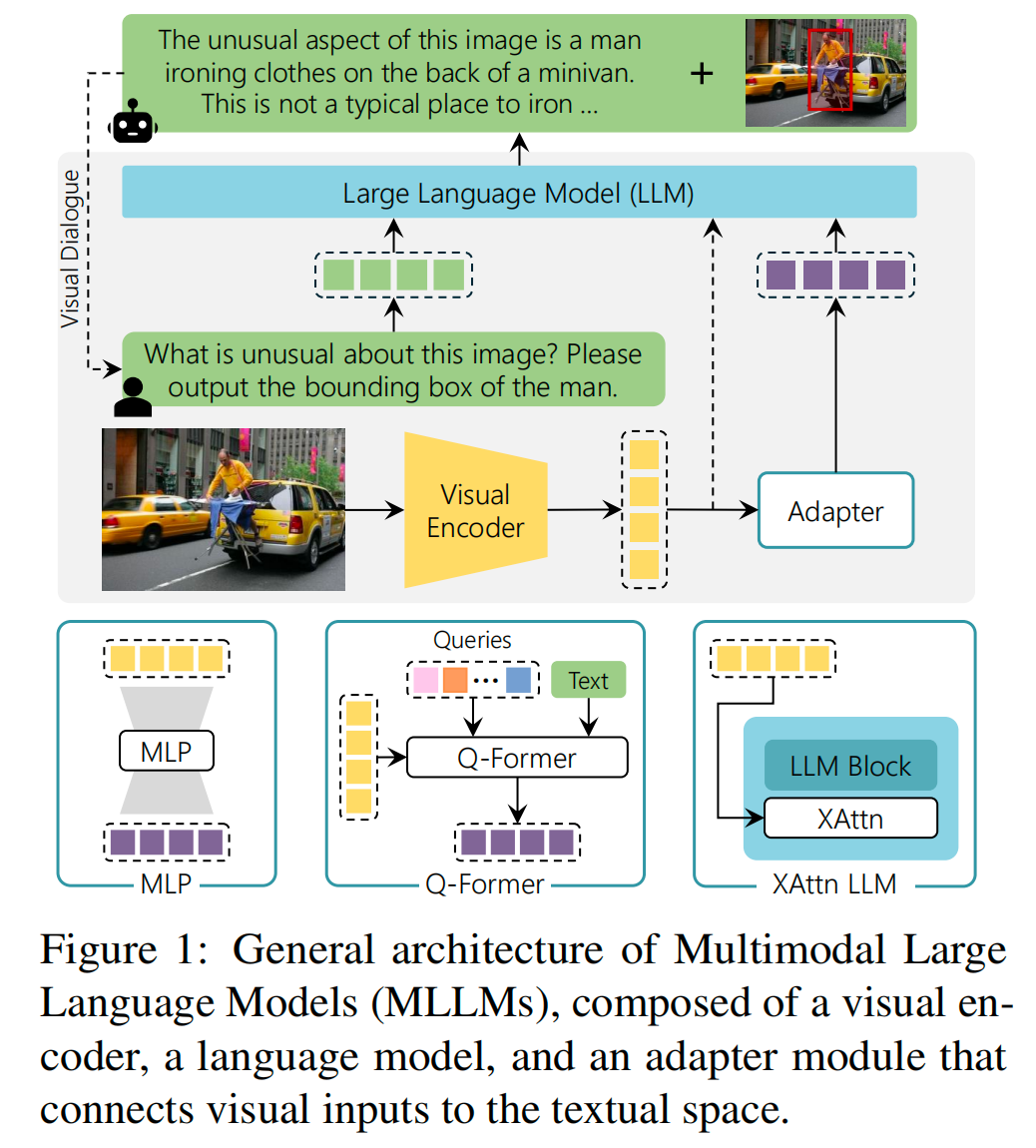
2.1 视觉语言模型(VLM)
视觉语言模型的核心目标是理解图像和文本之间的关系。典型的应用场景包括:
- 图像描述生成(Image Captioning)
- 可视问答(Visual Question Answering, VQA)
- 多模态对话系统
这类模型通常由以下组件构成:
- 视觉编码器:提取图像特征(如 ResNet、ViT)。
- 语言模型:处理文本并生成响应(如 BERT、LLaMA)。
- 多模态融合模块:整合视觉和语言特征(如交叉注意力机制)。
2.2 直接偏好优化(DPO)
DPO 是一种基于对比学习的强化学习方法,其核心思想是通过比较两个候选回答(选中 vs. 拒绝)来优化模型参数。与传统的 PPO(Proximal Policy Optimization)不同,DPO 不需要显式的奖励模型,而是直接利用偏好数据进行训练。
DPO 的数学基础
给定一个提示(Prompt)和两个候选回答(Chosen 和 Rejected),DPO 的目标是最大化选中回答的概率,同时最小化拒绝回答的概率。其损失函数定义为:
L = -\mathbb{E}_{(x, y_c, y_r) \sim \mathcal{D}} \left[ \log \frac{e^{f_\theta(y_c|x)}}{e^{f_\theta(y_c|x)} + e^{\beta f_\theta(y_r|x)}}} \right]
其中:
- xx 是输入(图像 + 文本)。
- ycyc 是选中回答。
- yryr 是拒绝回答。
- fθfθ 是模型的输出函数。
- ββ 是温度参数。
2.3 TRL 库
TRL 是 Hugging Face 开发的一个用于强化学习的库,支持多种训练方法(如 DPO、PPO)。其优势包括:
- 简洁的 API 设计。
- 与 Hugging Face Transformers 的无缝集成。
- 支持多模态输入(文本 + 图像)。