字节跳动GPU Scale-up互联技术白皮书
在人工智能与机器学习技术爆发式发展的浪潮中,AI模型的规模与复杂度呈指数级增长,推动GPU集群向更大规模、更高性能的方向演进。AI训练和推理任务对数据处理能力的需求不断突破极限,不仅要求GPU集群能够处理海量数据、训练更深层次的神经网络,还需在降低任务执行延迟与提升系统整体效率之间实现平衡。这一背景下,GPU集群的Scale-up网络架构成为关键瓶颈——如何在机架级乃至多机架级规模下,实现GPU之间低延迟、高带宽的数据互联,成为业界亟待解决的核心挑战。
以太网技术凭借其标准化生态、持续迭代的高速链路(如单芯片带宽每18个月翻倍的摩尔定律)以及大规模部署的成本优势,成为构建下一代AI集群互联架构的理想基石。当前,行业组织正基于以太网探索AI集群专用的Scale-up网络技术,试图通过协议优化与硬件创新,突破传统互联方案在语义支持、传输效率与可扩展性上的局限。
字节跳动深耕AI基础设施领域,针对GPU架构特性与AI应用场景需求,推出自研的EthLink以太网互联方案。该方案基于以太网技术栈,创新性地融合Load/Store与RDMA语义,实现了对小块控制数据与大块模型数据的差异化高效传输,同时通过协议栈优化、网络拓扑设计与可靠性机制,构建了低延迟、高带宽且可扩展的GPU集群互联架构。本文将系统解析GPU架构与互联需求,阐述下一代Scale-up网络的设计逻辑,并详细介绍EthLink方案的技术细节,为AI集群的网络架构演进提供实践参考与技术洞察。
今年4月29日,字节跳动对外发布了《字节跳动 GPU Scale-up 互联技术白皮书》,针对GPU架构和GPU互联的基础原理总结得非常好,这里节选部分内容推荐给各位读者。可以直接点击文章底部“阅读原文”获取完整版本。

1. GPU基础架构
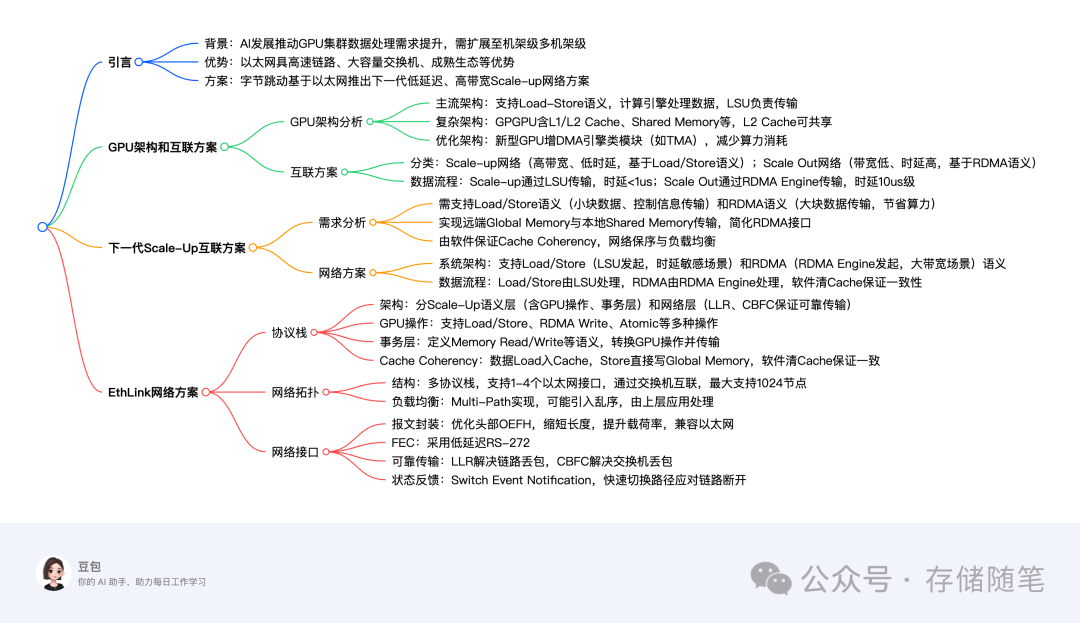
目前主流的 GPU 架构都支持 Load-Store 语义,如下图所示,GPU 的计算引擎从寄存器中读写数据并完成数据的处理,LSU(Load-Store Unit)通过 Load/Store 指令在寄存器和 Device Memory 之间,以及 Device Memory 和外部 Memory 之间完成数据传输。
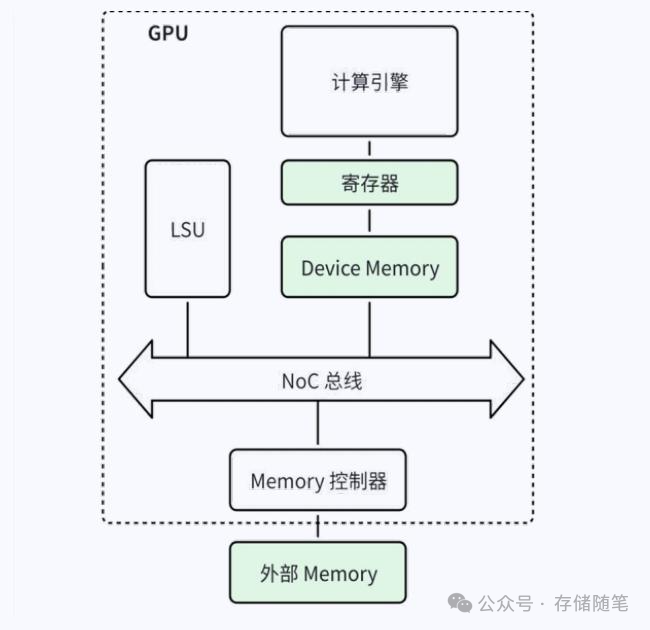
基于上述架构模型的 GPU,计算引擎主要负责数据的处理,LSU 负责数据的传输,如下图所示,两个模块可以并行工作形成流水线,数据传输主要依靠 Load 和 Store 语义完成。
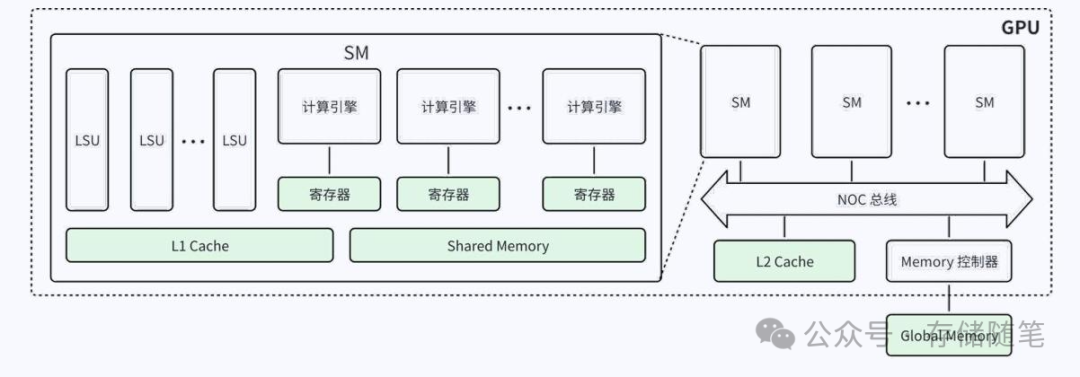
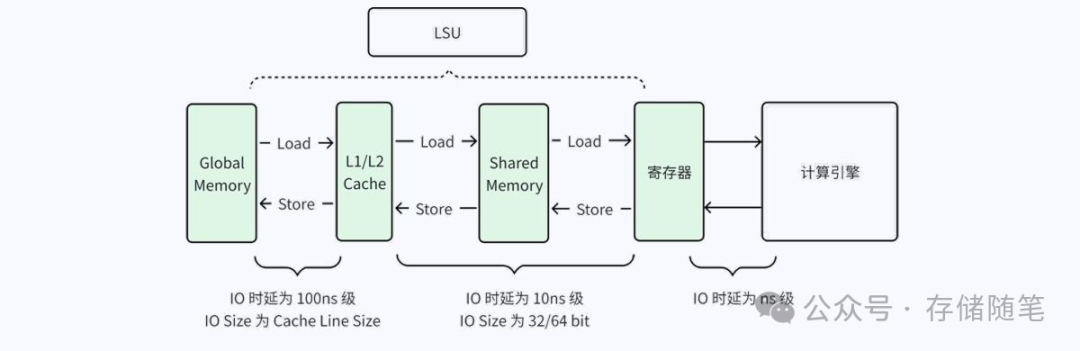
实际的 GPU 架构要比上述的 GPU 架构模型更加复杂,GPGPU(General Purpose GPU)架构通常如下图所示,Device Memory 包括 L1/L2 Cache 和 Shared Memory,Shared Memory 和 L1 Cache 位于 Streaming Multiprocessor(SM)内部,不能在 SM 之间进行共享。L2 Cache 位于 SM 外部,可以被所有 SM 共享。GPU 外部 Memory 为 Global Memory,可以 被所有的 SM 访问,也可以被 CPU 或者其他 GPU 访问。
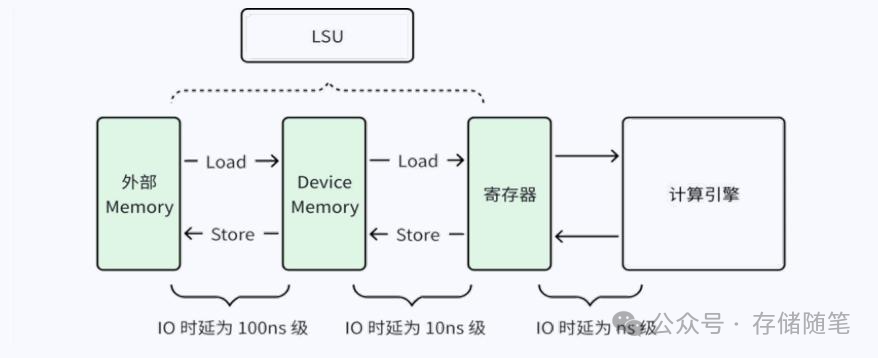
在上述 GPU 的架构中,GPU 主要通过 LSU 完成数据的传输,如下图所示。计 算引擎通过寄存器进行数据的访问,IO 时延为 ns 级。LSU 通过 Load/Store 操作实现 Shared Memory 与寄存器之间,以及 Shared Memory 与/L1/L2 Cache 之间的数据传输,IO 时延为 10ns 级,IO Size 通常为寄存器级(32/64 bit)。当出现 Cache Miss 时,LSU 需要进行 Global Memory 和Shared Memory 之间的数据传输,IO 时延为 100ns 级,IO Size 为 Cache Line Size(64/128/256 Byte)。
在 AI 应用场景中,计算引擎需要处理大量的数据信息,LSU 可以实现数据的 高效传输,但是 LSU 每次传输的数据块比较小,在传输大块数据时,需要 LSU 下发多个 Load/Store 指令来完成数据的搬运。Load/Store 指令的内存地址或 者寄存器地址信息,需要计算引擎提前生成并发给 LSU,Load/Store 指令的 地址信息处理会消耗计算引擎的算力资源。因此通过 LSU 来完成大块数据的传 输,会伴随计算引擎的部分算力资源的消耗。
为了优化 GPU 数据传输方案,降低计算引擎用于数据传输的算力资源,新型 号的 GPU 在片内增加了类似于 DMA 引擎的传输模块,如 NVIDIA 从Hopper 系列的 GPU 开始,在 SM 内增加了 Tensor Memory Accelerator (TMA),专门用于 Global Memory 到 Shared Memory 之间的数据传输, 如下图所示。