李沐《动手学深度学习》| 4.4 模型的选择、过拟合和欠拟合.md
文章目录
- 误差
- 训练误差和泛化误差
- 验证数据集和测试数据集
- K-折交叉验证
- 过拟合Overfitting和欠拟合Underfitting
- 模型容量/模型复杂性
- 模型容量的影响
- 估计模型容量
- 通过代码理解模型选择、观察欠拟合和过拟合现象
- 1.生成数据集
- 2.对模型进行训练和测试
- 3.完整代码
- 4.调整阶级,观察结果
- 三阶多项式函数拟合(正常情况)
- 线性函数拟合(欠拟合)
- 高阶多项式函数拟合(过拟合)
误差
训练误差和泛化误差
训练误差:模型在训练数据集上的误差
泛化误差(重点关注):模型在新数据上的误差
验证数据集和测试数据集
训练数据集:训练模型参数
验证数据集:**调整超参数的数据,**使用这个数据集来评估超参数的好坏
- 例如拿出50%的训练数据作为验证数据集
- 非大数据集通常使用K-折交叉验证
测试数据集:只用一次的数据集,用于测试模型的泛化能力
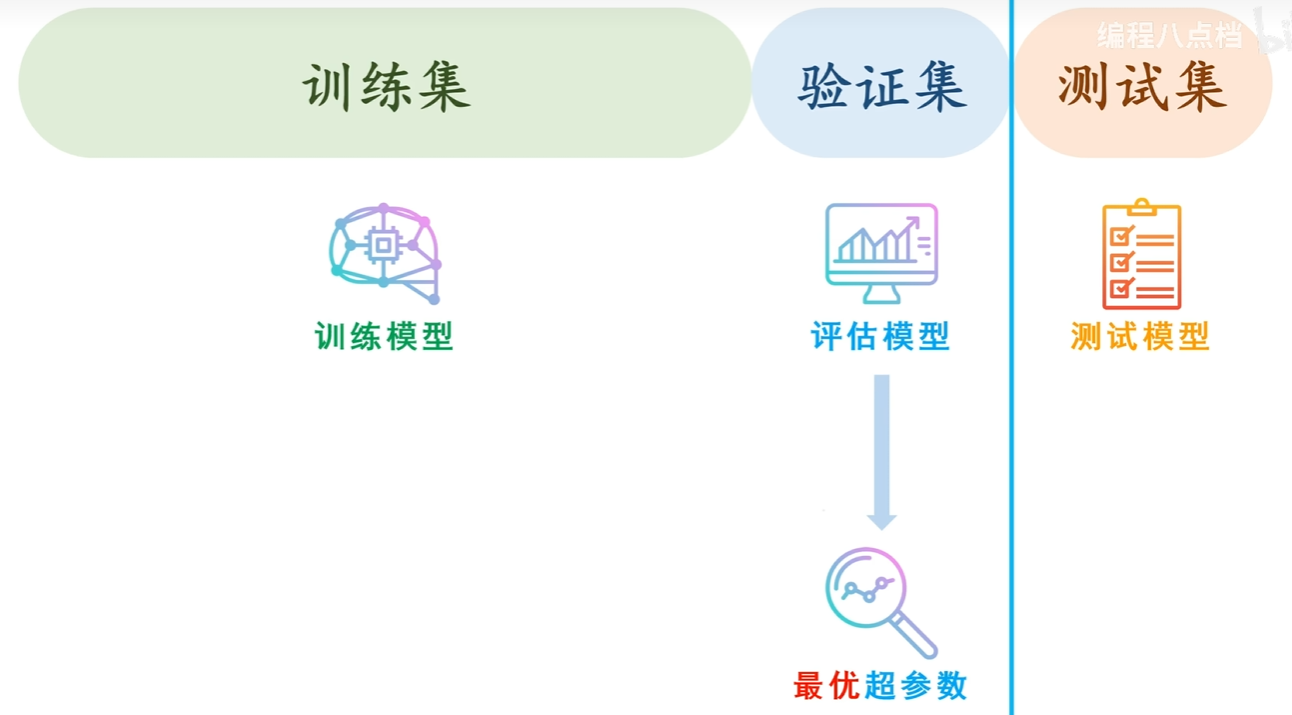
超参数最优化的一种方法
- 通过训练集数据学习得到模型的参数,在此阶段是固定了一组超参数,通过优化算法训练模型。
- 设置超参数的组合或者范围(例如学习率=0.1、0.01、0.001)
- 从设定的超参数中随机采样,使用采样到的超参数值重新用训练集训练新的参数,通过验证数据评估识别精度。
深度学习需要很长的时间,所以在超参数的搜索中,需要尽早放弃不符合逻辑的超参数。其次,在超参数最优化中,可以减少学习的epoch,缩短一次评估所需的时间。
- 重复步骤3根据识别精度的结果(100次等),缩小超参数的范围
重复上述操作,不断缩小超参数的范围,缩小到一定程度时,从该范围中选出一个超参数的值。
说明
- 验证集不参与参数训练,仅用于横向比较不同超参数的效果。
每次采样出新的超参数,**重新使用训练集训练新的参数,**然后再使用验证集评估超参数的效果。
- 每次调整超参数后,模型参数会重新训练,因此不同超参数对应不同的模型
超参数直接影响模型参数的优化过程,因此每组超参数对应不同的参数训练结果,本质上是不同的模型实例。
之后的章节,为了偷懒。用于测试模型的数据集,其实很多是验证数据集,所以泛化能力是虚高的。但是我们需要知道,应该使用测试数据集来测试模型,测试数据集是未知的。
李宏毅老师对这部分的解释
把Training的资料分成两半,一部分叫作Training Set,一部分是Validation Set。先在Training Set上训练模型,然后在Validation Set上衡量模型的均分误差mse,最后用测试数据集测试模型。
章节:What to do if my network fails to train - General Guide
K-折交叉验证
存在问题:没有足够多的数据使用,想要尽可能多的数据集作为训练数据集
极端案例
某个人脸检测任务中,只有亚洲人脸、欧洲人脸、非洲人脸三个样本,这三个样本的特征差异都非常大。如果只拿其中一个样本做验证集,也就是验证集的数据数量太少,不能完全表示训练集的特征分布,那验证集苹果出来的模型效果也是不可靠的。
解决办法:使用K-折交叉验证的方法来确定最优的超参数组合
算法
K-fold Cross Validation把训练集切成K等份,拿其中一份当作Validation Set,另外K-1份当Training Set,重复N次。
假设我们切成3份,第一次让第3份为validation,跑一次模型。然后第二次让第2份为validation,跑一次模型。最后第三次,让第1份为validation,跑一次模型。最后取三种情况下的平均值,选平均结果最好的模型。
常用K=5或K=10,在选择K时,需要权衡要用多少数据作为训练和能承受多少倍的代价(会跑K遍数据集)。
将训练集分割成K块
For i=1,....,K 使用第i块作为验证数据集,其余作为训练数据集
报告k个验证集误差的平均
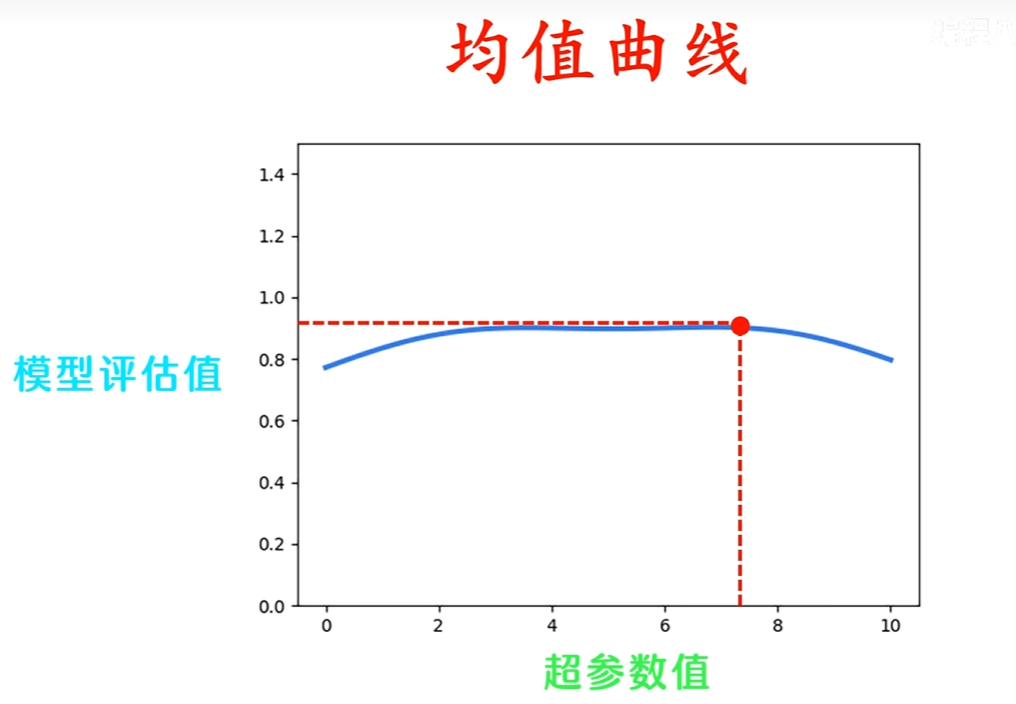
所有的数据都参与了训练,也参与了验证,得到了K条超参数-评估曲线( x x x轴是超参数数值, y y y轴是评估效果),将K条曲线取均值,就可以得到一条均值曲线。
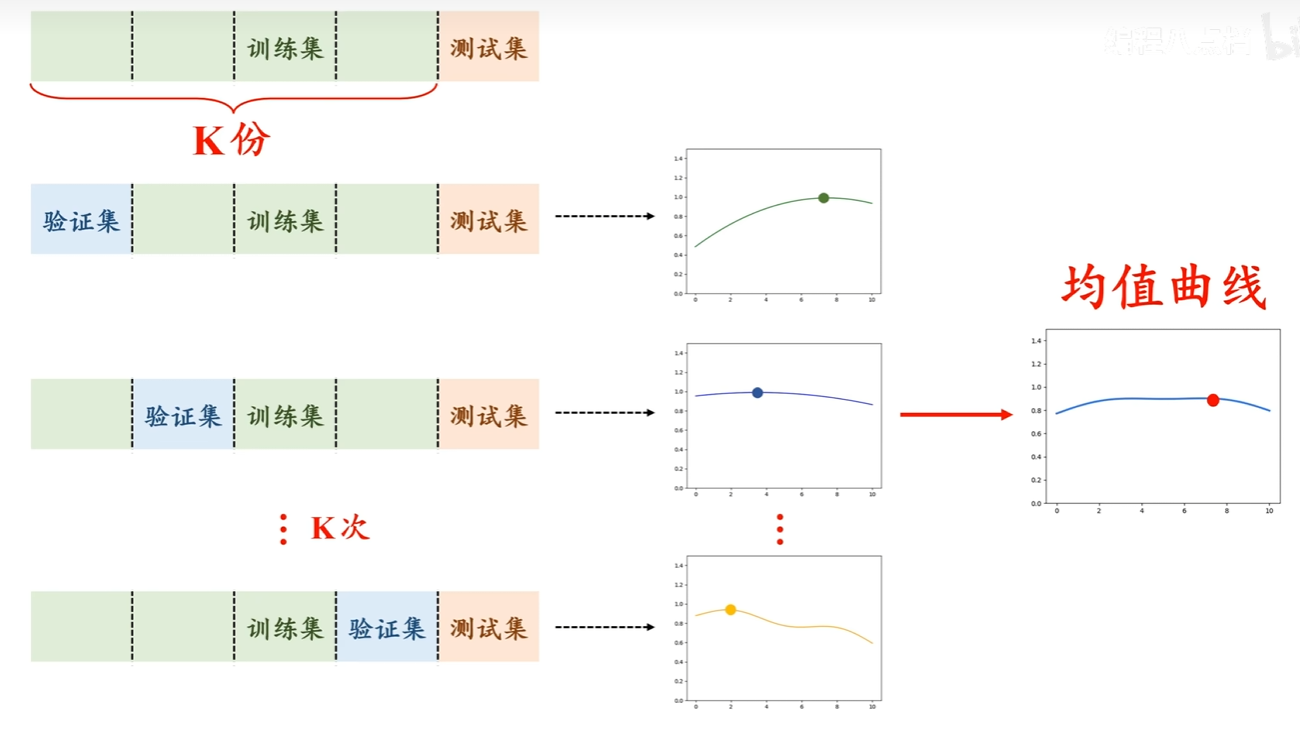
均值曲线中模型评估值最高的点对应的超参数值,就是我们要找的最优超参数。当出现多个超参数时,我们选取的就是一个超参数组合。
过拟合Overfitting和欠拟合Underfitting
过拟合Overfitting:模型在训练数据上表现极佳,但在新数据(测试数据)上表现较差。
- 原因:模型过于复杂,过度学习了训练数据中的噪声、细节或随机波动,导致失去了泛化能力。
- 表现:训练误差很低,验证/测试误差显著提高
- 解决方法:1.简化模型 2.增加训练数据量
欠拟合underfitting:模型在训练数据和新数据上表现都不佳,无法捕捉数据的基本模式。
- 原因:模型过于简单或者特征选择不当,导致无法学习数据中的关键规律
- 表现:训练误差和验证/测试误差都很高。

模型容量/模型复杂性
模型容量/模型复杂性:拟合各种函数的能力/模型参数的数量大小
- 低容量的模型难以拟合训练数据
- 高容量的模型可以记住所有的训练数据,训练数据中的噪声、细节或随机波动也会被学习

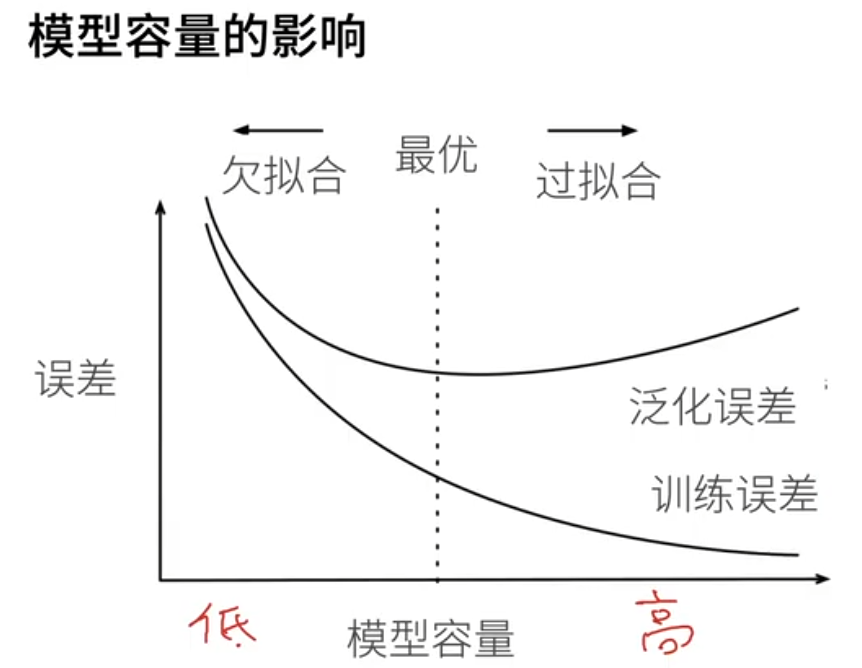
模型容量的影响
最优容量:在过拟合和欠拟合之间找到平衡点,使模型既捕捉数据规律,又不被噪声干扰。
目标是在最优模型容量的地方(模型容量先足够大,在足够大的情况下)
- 泛化误差尽可能的小 - 会承受一定程度的过拟合
- 泛化误差和训练误差的差距尽可能的小
x x x轴是不同的模型容量,也就是每个点代表不同的模型
估计模型容量
- 难以在不同的种类算法之间比较
- 给定一个模型种类,比如神经网络
- 参数的个数
- 参数的选型范围
通过代码理解模型选择、观察欠拟合和过拟合现象
理解代码的含义就可以了,因为d2l版本问题,感觉书上的代码经常运行不起来
我们通过多项式拟合来探索这些概念。
import math
import numpy as np
import torch
from torch import nn
from d2l import torch as d2l
1.生成数据集
使用以下三阶多项式来生成训练和测试数据的标签
y = 5 + 1.2 x − 3.4 x 2 2 ! + 5.6 x 3 3 ! + ϵ w h e r e ϵ N ( 0 , 0.1 2 ) y=5+1.2x-3.4\frac{x^2}{2!} + 5.6\frac{x^3}{3!}+\epsilon \;\;\;where\;\epsilon~N(0,0.1^2) y=5+1.2x−3.42!x2+5.63!x3+ϵwhereϵ N(0,0.12),其中 ϵ \epsilon ϵ噪服从均值为0且标准差为0.1的正态分布。
在优化的过程中,我们通常希望避免非常大的梯度值或损失值。 这就是我们将特征从 x i x_i xi调整为 x i i ! \frac{x^i}{i!} i!xi的原因, 这样可以避免很大的 i i i带来的特别大的指数值。 我们将为训练集和测试集各生成100个样本。
代码说明
- 产生20维的向量矩阵W,仅前4个非零权重,引入噪声。
目标是生成一个三阶多项式的真实模型,但用更高阶的多项式取拟合。
虽然生成时权重为0,但在训练中模型可能错误地学习到高阶项与噪声的关联,导致过拟合现象出现。
- 生成数据集,数据集是一维的,每个样本是标准正态分布的随机值。
- 使用
np.power将每个样本的原始特征扩展维多项式形式。例如,若原始特征为x,则生成
[x^0, x^1, x^2, ..., x^19],共20个特征(对应max_degree=20)。
poly_features 是 (200, 20) 的矩阵,200个样本,每个样本20个特征。
- 在数学中,Gamma函数满足 Γ ( n ) = ( n − 1 ) ! Γ(n)=(n−1)! Γ(n)=(n−1)!,所以
math.gamma(i + 1)等价于 i ! i! i!。 - 生成一个与
labels形状相同的随机噪声数组,噪声服从均值为0、标准差为0.1的正态分布,也就是上面公式里的 ϵ \epsilon ϵ。将生成的噪声叠加到原始标签上,使最终标签包含随机扰动。
这里scale控制噪声的强度,0.1是一个经验值,噪声适中,既模拟真实扰动,又保留核心规律。
max_degree = 20 # 多项式的最大阶数
n_train, n_test = 100, 100 # 训练和测试数据集大小
true_w = np.zeros(max_degree) # 分配大量的空间
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6])# 生成200个样本(训练+测试),每个样本是标准正态分布的随机值
features = np.random.normal(size=(n_train + n_test, 1))
# 打乱顺序
np.random.shuffle(features)
# 生成多项式特征:x^0, x^1, x^2, ..., x^19
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))# 归一化处理
for i in range(max_degree): # i从0开始poly_features[:, i] /= math.gamma(i + 1) # gamma(n)=(n-1)!# 生成模型 labels的维度:(n_train+n_test,)
labels = np.dot(poly_features, true_w)
labels += np.random.normal(scale=0.1, size=labels.shape)
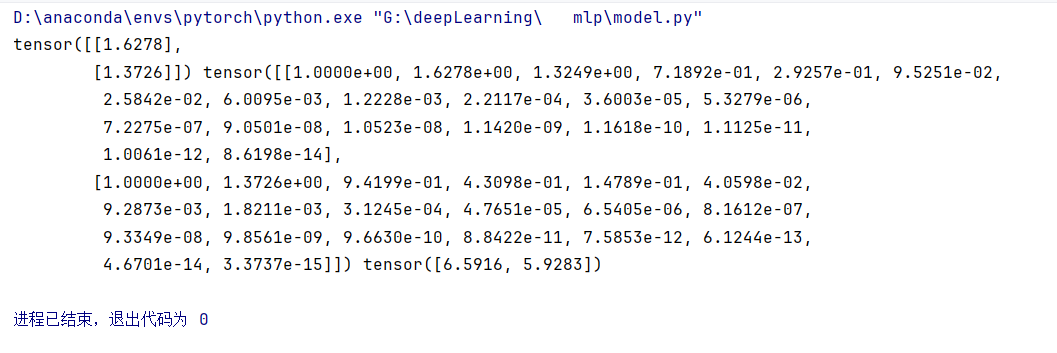
我们查看一下生成的前两个样本
将四个NumPy数组(true_w, features, poly_features, labels)转换为PyTorch张量(PyTorch里的函数只能处理张量),只是类型变了形状没有变化,并保持变量名不变。
features随机生成的200个样本,每个样本一个特征值,形状是[200,1]poly_features根据features生成的多项式特征,形状是[2,20]labels样本的标签,形状是[200]
true_w, features, poly_features, labels = [torch.tensor(x, dtype=torch.float32) for x in [true_w, features, poly_features, labels]]print(features[:2], poly_features[:2, :], labels[:2])
2.对模型进行训练和测试
实现一个函数来评估模型在给定数据集上的损失
**metric.add(l.sum(), l.numel())****: **若 l 的形状为 (32,)(批次大小32),则 l.sum() 为32个样本的损失总和,l.numel() 为32。
def evaluate_loss(net, data_iter, loss): #@save"""评估给定数据集上模型的损失"""metric = d2l.Accumulator(2) # 损失的总和,样本数量for X, y in data_iter:out = net(X)y = y.reshape(out.shape)l = loss(out, y)metric.add(l.sum(), l.numel())return metric[0] / metric[1]
定义训练函数
- 这里使用了
nn里的MESLoss,但是设置reduction='none',这样求出来的是张量,如果不指定reduction则默认是标量。 nn.Sequential(nn.Linear(input_shape, 1, bias=False))使用简单的线性网络,在该网络中不设置偏移,因为在多项式中已经实现了( b x 0 bx^0 bx0里的 b b b)。- 使用
d2l.load_array将数据封装为PyTorch的DataLoader,参数is_train=False表示测试数据不进行洗牌,保持顺序。 train_labels/test_labels的形状为(batch_size,),该网络的输出为(batch_size,1),需要将一维的原始标签转换为二维形状。net[0].weight是该线性层的权重张量获取该线性层的权重张量,PyTorch 张量可能包含梯度信息(grad),用于反向传播。.data的作用是 获取张量的纯数据部分,.numpy()的作用是将 PyTorch 张量转换为 NumPy 数组。
def train(train_features, test_features, train_labels, test_labels,num_epochs=400):loss = nn.MSELoss(reduction='none')input_shape = train_features.shape[-1] # 拉平成一维net = nn.Sequential(nn.Linear(input_shape, 1, bias=False))# 批量大小 最大10batch_size = min(10, train_labels.shape[0])# train_labels/test_labels的形状为(1,),转化为二维形式train_iter = d2l.load_array((train_features, train_labels.reshape(-1,1)),batch_size)test_iter = d2l.load_array((test_features, test_labels.reshape(-1,1)),batch_size, is_train=False)trainer = torch.optim.SGD(net.parameters(), lr=0.01)animator = d2l.Animator(xlabel='epoch', ylabel='loss', yscale='log',xlim=[1, num_epochs], ylim=[1e-3, 1e2],legend=['train', 'test'])for epoch in range(num_epochs):d2l.train_epoch_ch3(net, train_iter, loss, trainer)if epoch == 0 or (epoch + 1) % 20 == 0:animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss),evaluate_loss(net, test_iter, loss)))# 模型学习到的权重参数,用于验证是否接近真实权重print('weight:', net[0].weight.data.numpy())
注意新版本d2l的没有train_epoch_ch3函数,我们可以把之前的粘贴过来
// 定义
def accuracy(y_hat, y):if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum())
def train_epoch_ch3(net, train_iter, loss, updater): # @saveif isinstance(net, torch.nn.Module):net.train()metric = d2l.Accumulator(3)for X, y in train_iter:y_hat = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.mean().backward()updater.step()else:l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())return metric[0] / metric[2], metric[1] / metric[2] //调用
train_epoch_ch3(net, train_iter, loss, trainer)
3.完整代码
import math
import numpy as np
import torch
from torch import nn
from d2l import torch as d2lmax_degree = 20 # 多项式的最大阶数
n_train, n_test = 100, 100 # 训练和测试数据集大小
true_w = np.zeros(max_degree) # 分配大量的空间
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6])# 生成200个样本(训练+测试),每个样本是标准正态分布的随机值
features = np.random.normal(size=(n_train + n_test, 1))# 打乱顺序
np.random.shuffle(features)
# 生成多项式特征:x^0, x^1, x^2, ..., x^19
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
for i in range(max_degree):poly_features[:, i] /= math.gamma(i + 1) # gamma(n)=(n-1)!
# labels的维度:(n_train+n_test,)
labels = np.dot(poly_features, true_w)
labels += np.random.normal(scale=0.1, size=labels.shape)true_w, features, poly_features, labels = [torch.tensor(x, dtype=torch.float32) for x in [true_w, features, poly_features, labels]]def evaluate_loss(net, data_iter, loss): #@save"""评估给定数据集上模型的损失"""metric = d2l.Accumulator(2) # 损失的总和,样本数量for X, y in data_iter:out = net(X)y = y.reshape(out.shape)l = loss(out, y)metric.add(l.sum(), l.numel())return metric[0] / metric[1]
def accuracy(y_hat, y):if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum())
def train_epoch_ch3(net, train_iter, loss, updater): # @saveif isinstance(net, torch.nn.Module):net.train()metric = d2l.Accumulator(3)for X, y in train_iter:y_hat = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.mean().backward()updater.step()else:l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())return metric[0] / metric[2], metric[1] / metric[2]
def train(train_features, test_features, train_labels, test_labels,num_epochs=400):loss = nn.MSELoss(reduction='none')input_shape = train_features.shape[-1] # 拉平成一维net = nn.Sequential(nn.Linear(input_shape, 1, bias=False))# 批量大小 最大10batch_size = min(10, train_labels.shape[0])# train_labels/test_labels的形状为(1,),转化为二维形式train_iter = d2l.load_array((train_features, train_labels.reshape(-1, 1)),batch_size)test_iter = d2l.load_array((test_features, test_labels.reshape(-1, 1)),batch_size, is_train=False)trainer = torch.optim.SGD(net.parameters(), lr=0.01)animator = d2l.Animator(xlabel='epoch', ylabel='loss', yscale='log',xlim=[1, num_epochs], ylim=[1e-3, 1e2],legend=['train', 'test'])for epoch in range(num_epochs):train_epoch_ch3(net, train_iter, loss, trainer)if epoch == 0 or (epoch + 1) % 20 == 0:animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss),evaluate_loss(net, test_iter, loss)))# 模型学习到的权重参数,用于验证是否接近真实权重print('weight:', net[0].weight.data.numpy())4.调整阶级,观察结果
三阶多项式函数拟合(正常情况)
我们将首先使用三阶多项式函数,它与数据生成函数的阶数相同。
poly_features形状为(200, 20)的矩阵,包含200个样本的20阶多项式特征。这里取前n_train(100)个样本作为训练集,每个样本仅保留前4个特征(对应 x 0 , x 1 , x 2 2 ! , x 3 3 ! x^0,x^1,\frac{x^2}{2!} ,\frac{x^3}{3!} x0,x1,2!x2,3!x3),输入函数train的形状为(100,4)。
train(poly_features[:n_train, :4], poly_features[n_train:, :4],labels[:n_train], labels[n_train:])学习到的权重是 w e i g h t : [ [ 4.99574 1.260503 − 3.3923686 5.5092816 ] ] weight: [[ 4.99574\;\;1.260503\;\;-3.3923686\;\;5.5092816]] weight:[[4.995741.260503−3.39236865.5092816]],真实的权重是 [ 5. 1.2 ; − 3.4 ; 5.6 ] [ 5.\;\;1.2\;;-3.4\;;5.6] [5.1.2;−3.4;5.6]
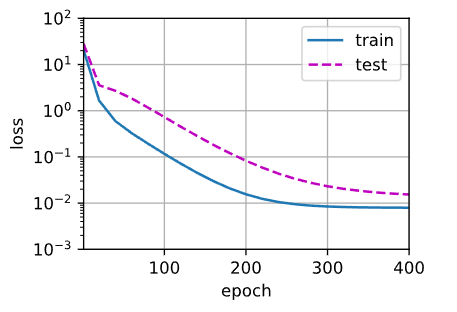
线性函数拟合(欠拟合)
欠拟合:模型过于简单在训练数据和新数据上表现都不佳,无法捕捉数据的基本模式。
欠拟合的出现的原因是模型过于简单,所以我们这里选择两个维度特征(不完整的数据特征)。
# 从多项式特征中选择前2个维度,即1和x
train(poly_features[:n_train, :2], poly_features[n_train:, :2],labels[:n_train], labels[n_train:])
学习到的权重是 w e i g h t : [ [ 3.2321868 4.6844296 ] ] weight: [[ 3.2321868\;\;4.6844296]] weight:[[3.23218684.6844296]],真实的权重是 [ 5. 1.2 − 3.4 5.6 ] [ 5.\;\;1.2\;\;-3.4\;\;5.6] [5.1.2−3.45.6]
模型在训练数据集和测试数据集上表现都不好, 在最后一个迭代周期完成后,训练损失仍然很高。 当用来拟合非线性模式(如这里的三阶多项式函数)时,线性模型容易欠拟合。
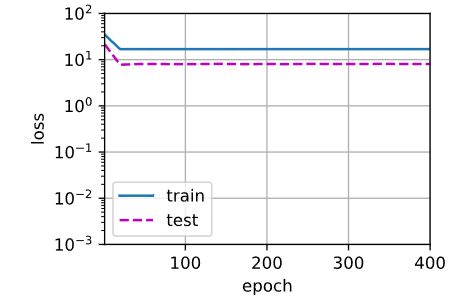
高阶多项式函数拟合(过拟合)
真实的数据规律是一个低阶多项式(例如前4阶),高阶项的系数本应为0(因为真实规律不需要它们)。当数据量不足时,模型(如高阶多项式)无法通过有限的样本判断哪些高阶项应该被忽略。模型会尝试用所有高阶项(如20阶)拟合数据,导致这些高阶项的系数无法收敛到0,也就是说这个过于复杂的模型会轻易受到训练数据中噪声的影响。
# 从多项式特征中选取所有维度
train(poly_features[:n_train, :], poly_features[n_train:, :],labels[:n_train], labels[n_train:], num_epochs=1500)
第二次学习到的权重是 [ [ 4.999185 1.2562195 − 3.3267603 5.166168 − 0.25657412 1.4090952 0.26903385 0.17492299 − 0.06891886 0.07352303 0.1228769 0.11360212 − 0.15172039 0.06682999 0.04851915 − 0.19917817 0.09261453 0.21324849 − 0.07531199 0.03049731 ] ] [[ 4.999185\;\;1.2562195\;\;-3.3267603\;\;5.166168\;\;-0.25657412\;\;1.4090952\;\;0.26903385\;\;0.17492299\;\;-0.06891886\;\;0.07352303\;\;0.1228769\;\;0.11360212\;\;-0.15172039\;\;0.06682999\;\;0.04851915\;\;-0.19917817\;\;0.09261453\;\;0.21324849\;\;-0.07531199\;\;0.03049731]] [[4.9991851.2562195−3.32676035.166168−0.256574121.40909520.269033850.17492299−0.068918860.073523030.12287690.11360212−0.151720390.066829990.04851915−0.199178170.092614530.21324849−0.075311990.03049731]]
真实的权重是 [ 5. 1.2 − 3.4 5.6 ] [ 5.\;\;1.2\;\;-3.4\;\;5.6] [5.1.2−3.45.6]
从第二次结果看,虽然训练损失可以有效地降低,但测试损失仍然很高。 结果表明,复杂模型对数据造成了过拟合。
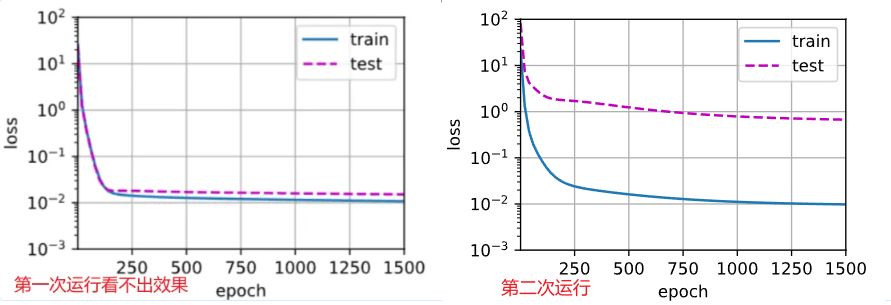
不知道为什么第一次跑看不出效果