YOLOv8源码修改(5)- YOLO知识蒸馏(下)设置蒸馏超参数:以yolov8-pose为例
目录
前言
1. 不同蒸馏算法资源占用
2. 不动态调整蒸馏损失
2.1 训练定量化结果
2.1 训练结果可视化结果
3. 动态调整蒸馏损失权重及实验分析
3.1 余弦衰减和指数衰减
3.2 CWD蒸馏损失
3.3 MGD蒸馏损失
3.4 AT蒸馏损失
3.5 SKD和PKD蒸馏损失
4. 调权重心得总结
5. 待验证
前言
YOLOv8源码修改(5)- YOLO知识蒸馏(上)添加蒸馏代码,以yolov8-pose为例进行知识蒸馏
接上文,我们已经加好了yolo蒸馏训练的必要代码,但并不意味着知识蒸馏就有用。我总结了以下一些可能有影响的因素:
(1)蒸馏算法的选择。最常用的CWD、MGD等知识蒸馏算法,论文中MGD的性能就要好过CWD。
(2)蒸馏算法的超参设置。以MGD为例,alpha_mgd的权重设置,lambda_mgd的权重设置等等,不同的参数设置会取得不同效果,MGD的论文里也写了,他的最佳经验值,是够能在我们自己的数据集上取得最好呢?
(3)蒸馏损失权重的设置。这点我认为是最重要的。因为所有蒸馏算法都绕不开,尤其对于yolo来说,yolo基于检测最基本的loss有box_loss、cls_loss和dfl_loss,如果是obb、seg、pose等任务,还会引入其他的loss。如果蒸馏损失过大,势必会导致其中一些较小的loss“失效”。
(4)数据集本身的质量。以COCO2017人体关键点为例,里面有些人需要预测出,有些人不需要预测出(我认为是标注错误、或者漏标)。但模型可能有别的“思考”,比如,只预测出属于“前景”的人,而“背景”的人不预测。大模型(m号以上)可以区分这种细粒度的区别,但小模型不行,因此就表现为中间层显著的特征差异,这时候知识蒸馏就明显了。而我数据清洗后,几乎没有漏标和错标,只要是人就预测出,这种特征可能相对简单,小模型(s号,n号可能还是不行)已经足够表示,所以再用知识蒸馏,这时效果就不明显了。
(5)教师模型和学生模型的差异。这里的差异不仅表现为中间层维度的差异,还可能是架构的差异,比如用yolov11m去蒸馏yolov8s,从一个维度映射到另一个维度,这种特征映射真的能形成等效表达吗?以及还有性能上的差异,教师模型比学生模型优秀多少,才能让学生模型有一个稳定提升。
(6)蒸馏代码实现的细节。我主要还是参考了paddleDetection中的yolo蒸馏实现,其中对特征用了均值归一化,如果换成一个可学习的BN层是否会更好,还有中间相同维度特征的映射,是否还要再加入一个相同维度的1D卷积?
经过大量调试训练后,我得出的心得:
对于实际落地的yolo训练而言(写论文不在其中),一个好的蒸馏算法应该只有一个参数,就是“损失权重”,最多再加一个影响不大的可调节参数。
根据动态调整训练过程中的损失权重,我发现:不同蒸馏算法的影响可能没有那么大,只要损失权重调整的好,都可以取得一个不错的训练结果。
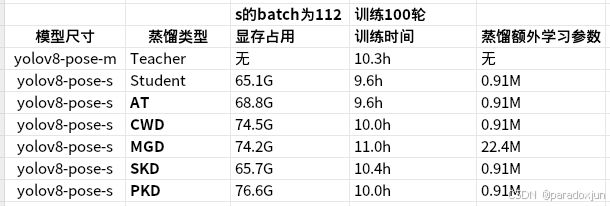
1. 不同蒸馏算法资源占用
下面是我训练时候记录的资源占用情况,可以看到MGD训练时间比其他的多了1小时,这些算法大都要生成中间特征,以进行一系列操作,因此显存占用大。
所以,经过我的调整测试,我一般选择AT来做蒸馏,实现简单,资源占用少,关键还有效。除非准确度有要求,才考虑其他的蒸馏算法。
2. 不动态调整蒸馏损失
2.1 训练定量化结果
首先,还是问问神奇的GPT,蒸馏损失大小怎么调整,他是这样告诉我的:
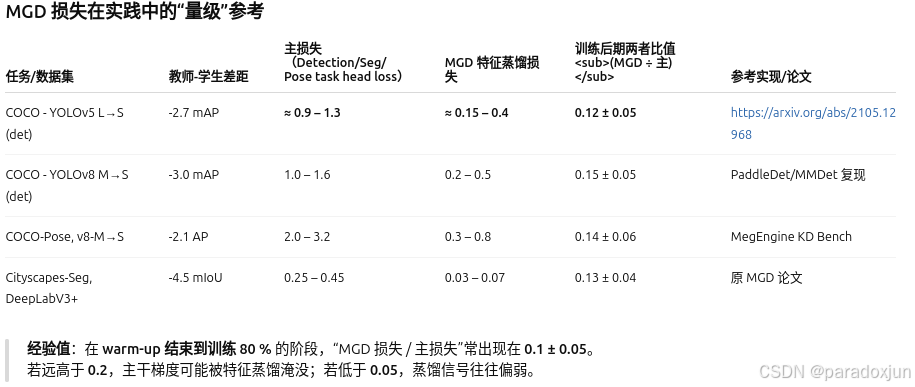
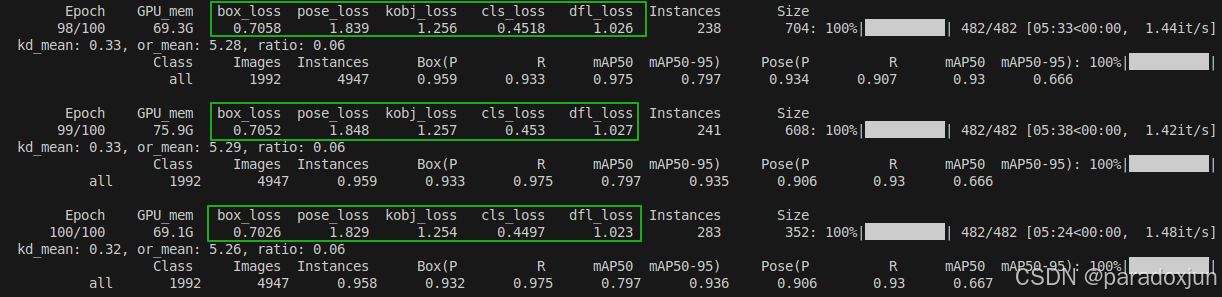
可调节的占比范围大概在0.1-0.8之间,然后如下图绿色框中所示,观察一下yolov8s-pose的几类损失,发现box_loss和dfl_loss很小加起来才等于其他3个损失。所以,我就想蒸馏损失应该控制在20%~30%之间(绝对数值在1.0~2.0之间),这样占比刚好取个平均值。
基于上面这样设置参数,本文直接进行了实验,得到了以下结果:

如上图,仅CWD取得比较明显的效果,MGD仅次于CWD。于是,我们就有疑问:这和论文中的结果不对啊。MGD是后发的论文,里面明明还写了自己效果比CWD好的。
此外,我们还容易发难:这个AT是什么鬼,不仅没正面作用,还产生负面效果了,难道是这个蒸馏算法实现不对,或者就是个rubbish算法,打着“attention”的旗号水论文,根本没有普适性?
而经过我对训练过程分析,发现恰恰相反,AT是所有算法中收敛最快的,尤其在前50轮的训练,基本要比正常训练高1~2%的点。那就又有疑问了:假设我们从50轮起训练,不加任何蒸馏损失,我AT训练得到的模型,应该有一个更好的起点(各项指标都高),那么最终获取的模型,至少不应该比其他蒸馏算法训练得到的差吧?
因此,我也做了一些可视化分析。
2.1 训练结果可视化结果
每10轮,记录一下验证的结果(B表示检测框,P表示关键点):
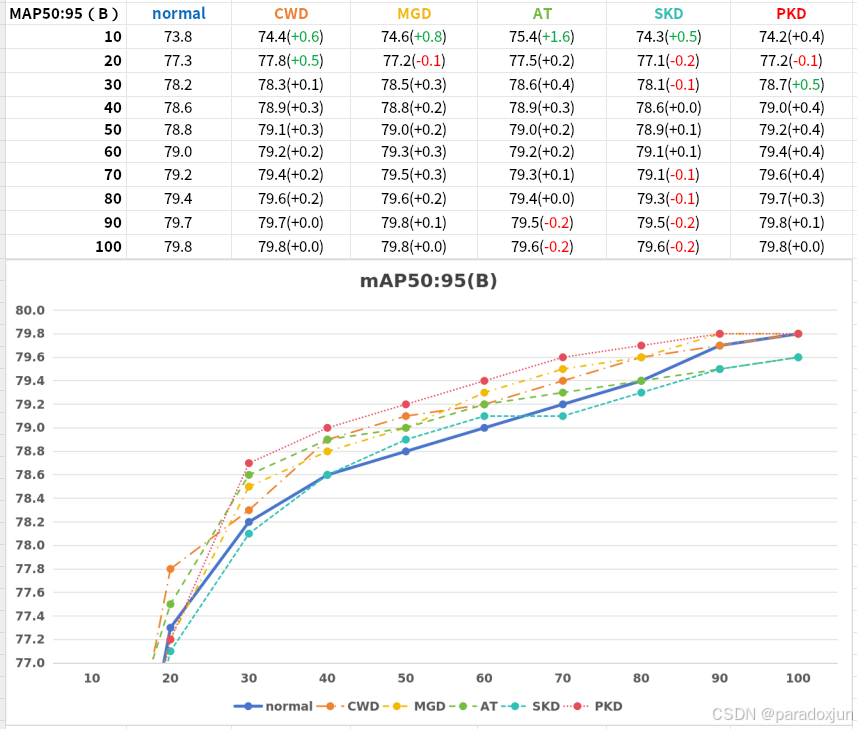
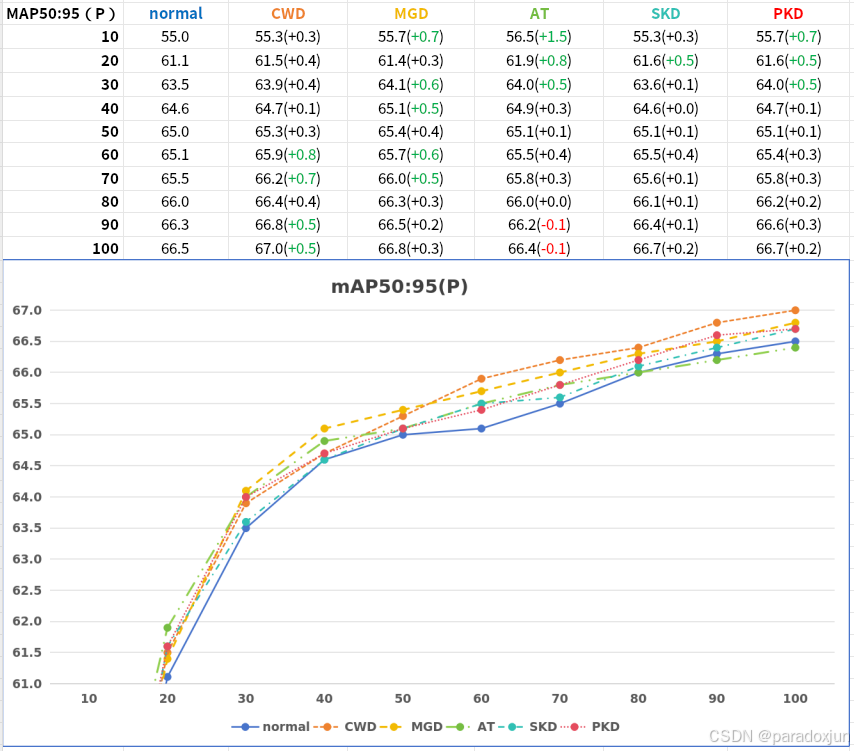
根据上面的图表,我很很如看到AT在开始是瑶瑶领先的,收敛速度很快。但是在50轮之后就不行了。那只有一个原因,训练后期,AT的蒸馏损失对模型优化是负面影响。
因此,我用余弦衰减来对AT蒸馏损失进行加权,最终得到以下变化:

根据上图,很容易发现,进行衰减加权后,整个训练过程中,取得的性能都要优于直接使用的性能。最终,pose的mAP50:95取得66.8(超正常训练的66.5),也说明知识蒸馏产生了一些效果。
3. 动态调整蒸馏损失权重及实验分析
使用余弦衰减、指数衰减后损失权重的可视化分析。这里没有使用“温度”这个参数来调整损失大小,是因为相比分类,检测、关键点等损失调整要困难很多,直接用权重加权会简单很多。
3.1 余弦衰减和指数衰减
也可以引入warmup,因为前期损失过大,不过用了以后,似乎没啥用。
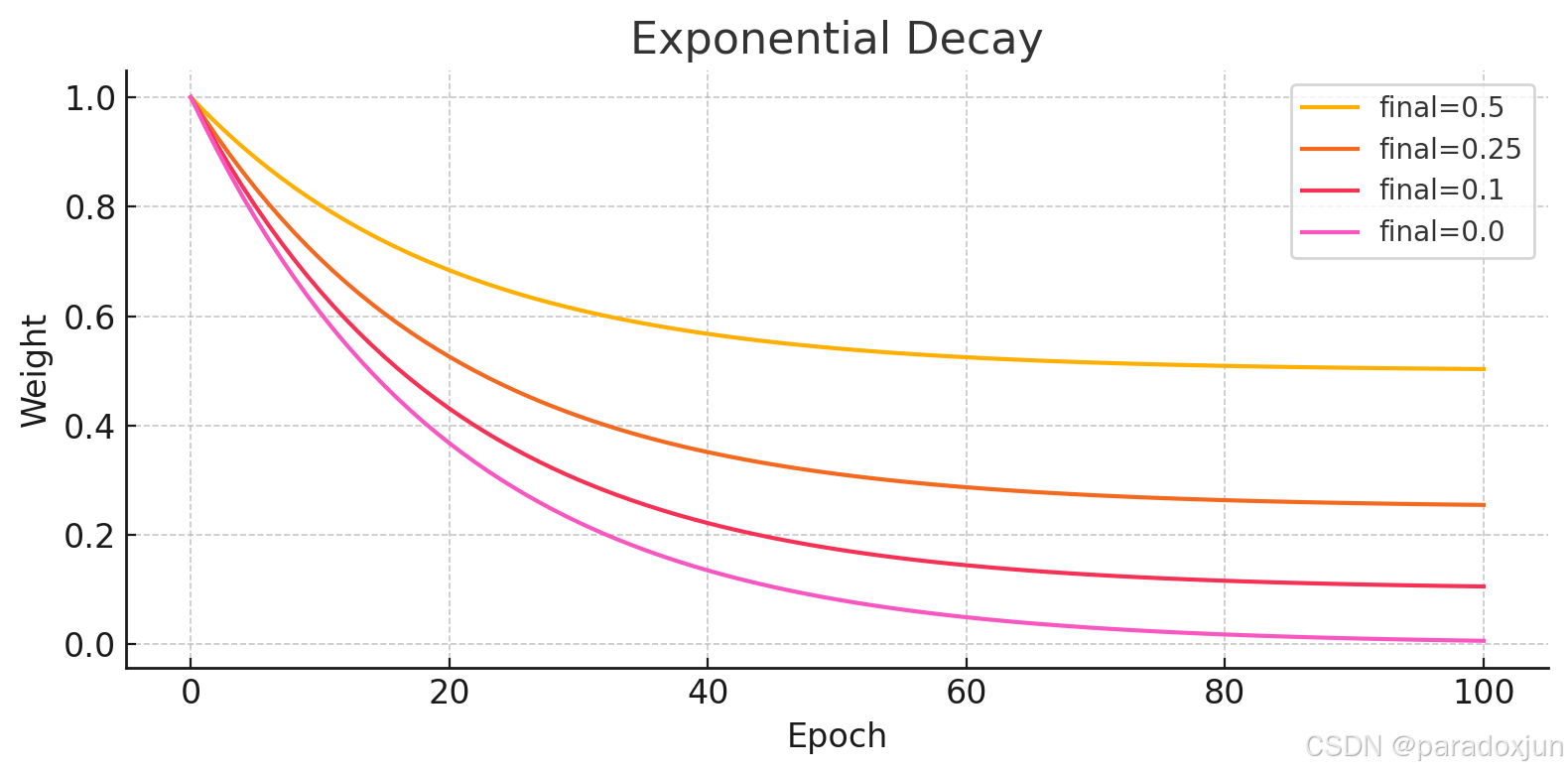
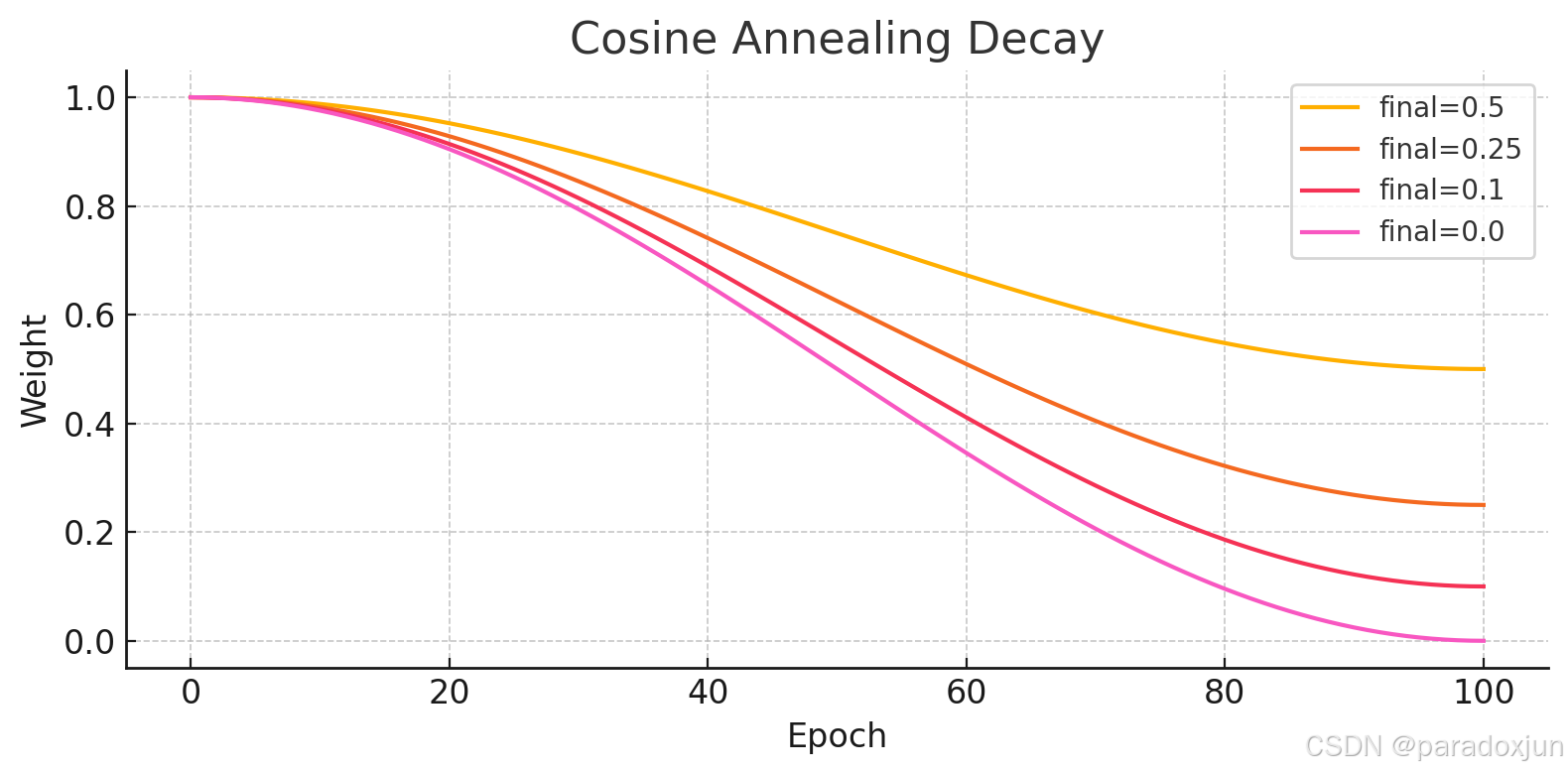
这两种衰减方式的选择,主要是看损失需不需要快速衰减,比如AT后期没用,可能需要衰减快一点,就用指数衰减,其他可以用余弦衰减。具体还是要根据自己的训练过程中,蒸馏损失下降的特性以及产生的影响去调整。
指数衰减:
余弦衰减:
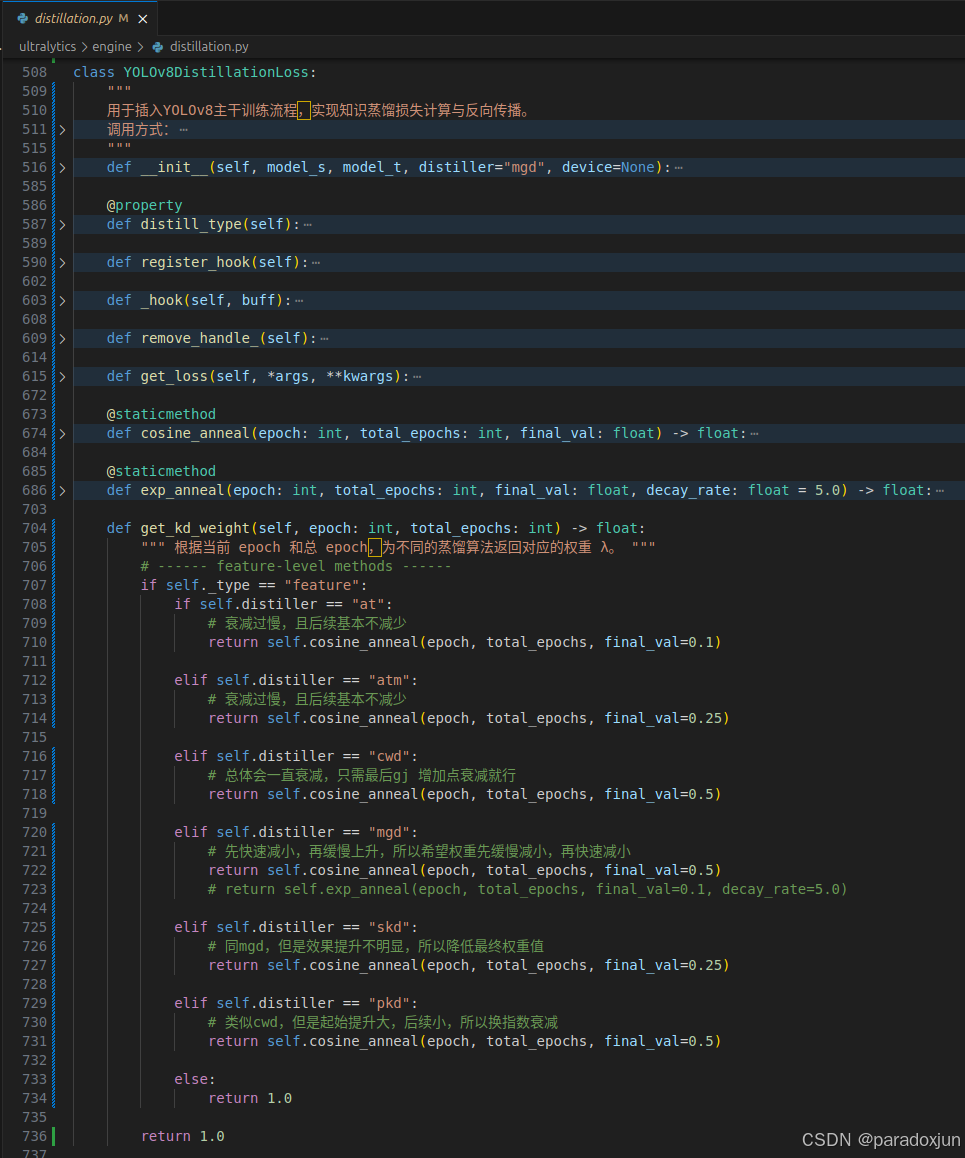
 衰减的预设参数的代码写在了distillation.py中YOLOv8DistillationLoss类的get_kd_weight方法中:
衰减的预设参数的代码写在了distillation.py中YOLOv8DistillationLoss类的get_kd_weight方法中:
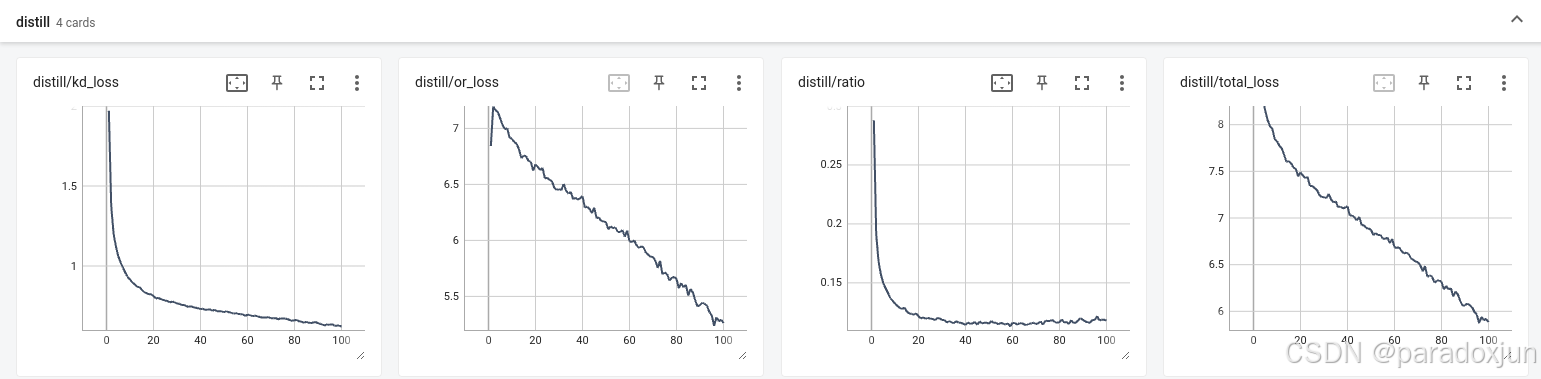
3.2 CWD蒸馏损失
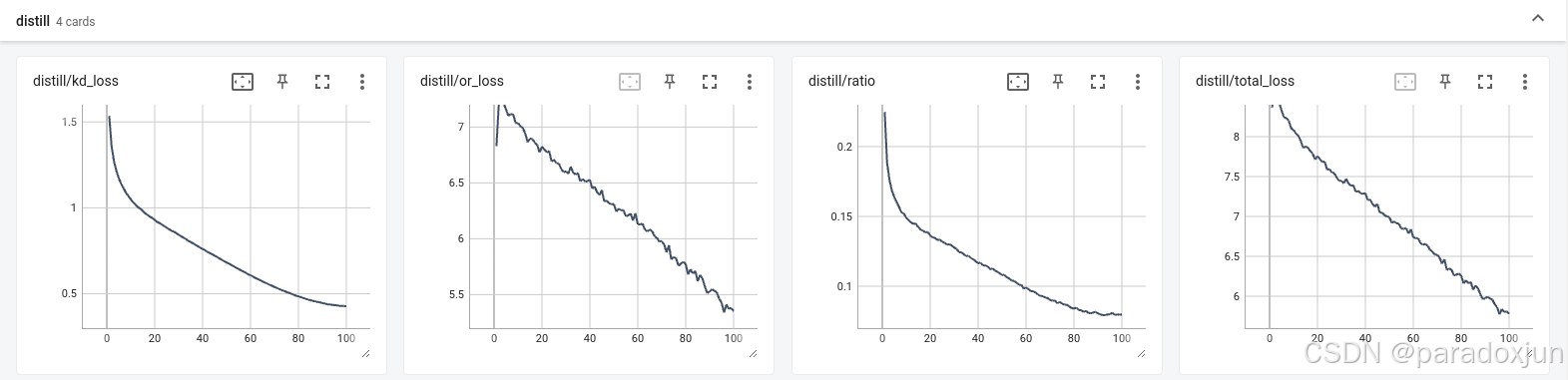
如下图,最初用BN来归一化的版本的,下井很快,20轮后比例就稳定在0.11,总统而言,该算法损失下降速度和yolov8-pose的一致,可能不需要加权重,只需要调整比例。
加权后下降,如下图,精度反而掉了0.3%,参数还需要调整一下。
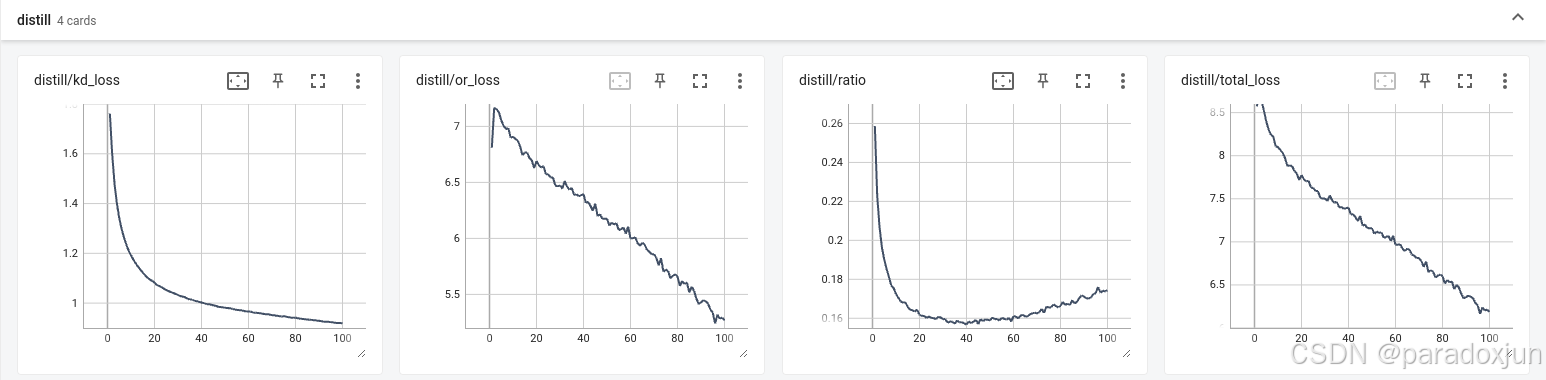
3.3 MGD蒸馏损失
MGD的蒸馏损失在后期占比还提升了,说明下降过慢,对应后期性能增加也变慢了。
我设置最终权重衰减到0.1,不过训练结果好像也没有提升,也没有下降。经过多次实验,我发现只要权重不是设置太高或者太低,该方法都能产生效果,是鲁棒性比较好的一个方法。
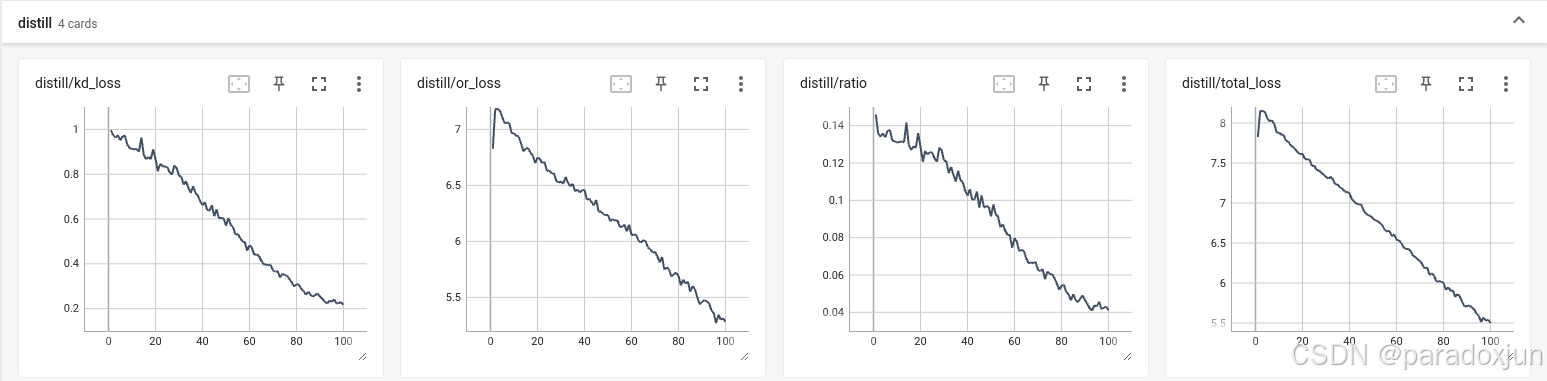
3.4 AT蒸馏损失
AT的下降趋势看起和CWD类似,但是比例却不同,损失占比一致在20%左右,可能太高了,但是前期收敛快也是真的快,是唯一一个能在20轮的时候就让原始损失到6.5的,比其他算法快了10轮。
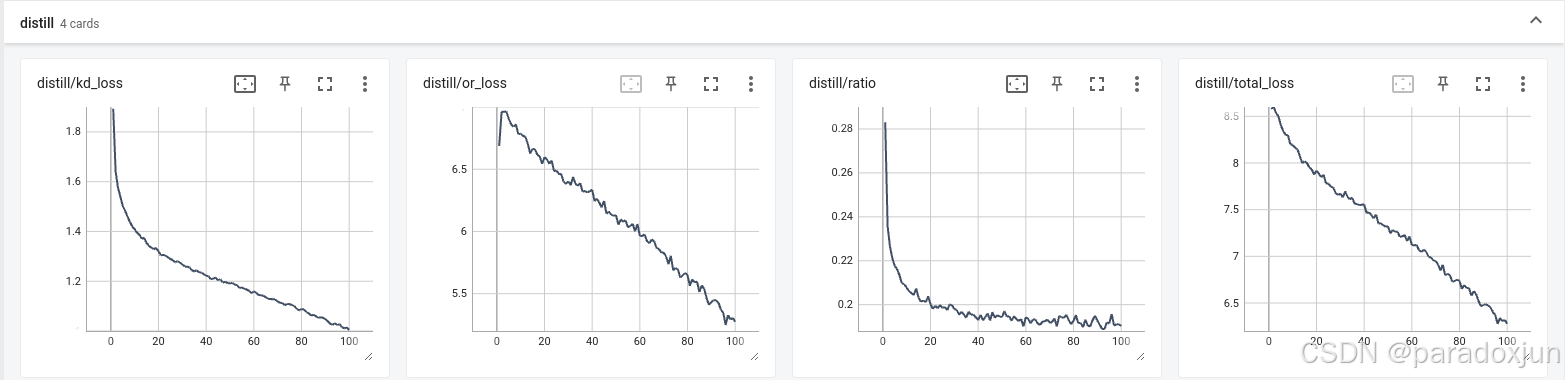
加权后,衰减到0,衰减好像过快了,导致后期就是没进行知识蒸馏的训练。所以这部分参数还得再调试。
3.5 SKD和PKD蒸馏损失
这两种算法不会实际用,仅做实验参考。
SKD:2.1中训练效果变差,有原因,就是这个损失在后期占比越来越高,影响原始损失的下降了。
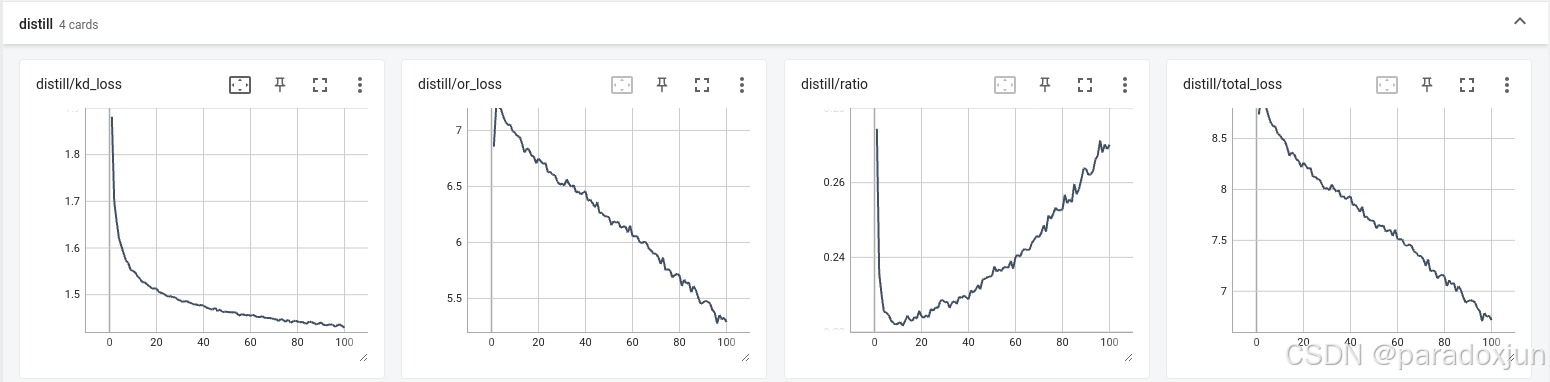
PKD:中规中矩,没啥特点,类似CWD,要用估计也优先用CWD。
4. 调权重心得总结
我会优先选择AT,因为实现简单,资源消耗少,训练时间也不会变长。实际训练的想法就是但求无错,最好有功。
求鲁棒性选择MGD,算法对参数设置(用论文中的就行)没那么敏感,多多少少会有些效果。
求结果选择CWD,只要参数调的好,效果比MGD还好。
初始权重调整:将蒸馏损失与原始损失的初始比例调整到15%~25%,最终比例调整到5%~15%,可能是一个比较好的设置。
如果教师模型性能远超学生模型(比如yolov8m-pose蒸馏yolov8n-pose),那么参数设置可以没那么严格,因为我在做m蒸n时,参数直接用的m蒸s的,根本没调,结果也能提升2.5%~2.8%。
5. 待验证
优于时间有限,目前验证的结论如上。大家可以多尝试,分享下调参经验。
还可以采用多种/多阶段的知识蒸馏方式,比如AT+MGD,开始设置9:1权重,最后设置1:9权重,因为AT开始效果好,MGD后期效果好一些,可以多尝试。