LLMs之Qwen:《Qwen3 Technical Report》翻译与解读
LLMs之Qwen:《Qwen3 Technical Report》翻译与解读
导读:Qwen3是Qwen系列最新的大型语言模型,它通过集成思考和非思考模式、引入思考调度机制、扩展多语言支持以及采用强到弱的知识等创新技术,在性能、效率和多语言能力方面都取得了显着提升。实验结果表明,Qwen3在各种基准测试中都表现出色,尤其是在代码生成、数学推理和Agent等任务领域,证明了其作为一种强大而灵活的开源LLM的潜力。
>> 背景痛点
●一直追求实现通用人工智能(AGI)或人工超智能(ASI)。几乎所有大型基础模型(如GPT-4o、Claude 3.7、Gemini 2.5、DeepSeek-V3、Llama-4、Qwen2.5)在实现这一目标上取得了显着进展。
●这些模型通过在海量数据集上训练,将有效的人类知识和能力提炼到模型参数中。然而,大多数最先进的模型仍然是开源的,开源社区的发展正在急剧缩小开源模型和闭源模型之间的性能差距。
● 现有的模型通常需要在聊天优化模型和专门的推理模型之间切换,效率较低。
>> 具体的解决方案:提出了Qwen3,Qwen模型系列的最新版本,旨在提高性能、效率和多语言能力。
● Qwen3包含一系列大型模型(LLM),参数规模从0.6到2350亿不等,包括密集模型和混合专家(MoE架构)。
● 核心创新的是思考模式(用于复杂的多步骤推理)和非思考模式(用于快速的、后续驱动的响应)集成到一个统一的框架中。
● 引入了“思考预算”,允许用户在推理过程中自适应地分配计算资源,从而根据复杂度平衡延迟机制和性能。
● 通过利用模型模型的知识,显着减少构建小规模模型所需的计算资源,同时确保其具有高度可比性的性能。
● 显着扩展了多语言支持,从29种语言和方言增加到119种,通过改进的跨旗舰语言全球理解和生成能力增强了可访问性。
>> 核心思路步骤
●预训练阶段:
●●数据准备:使用Qwen2.5-VL提取PDF文档中的文本,并使用Qwen2.5、Qwen2.5-Math、Qwen2.5-Coder等模型生成合成数据。
●多阶段训练:
●●第一阶段(通用阶段):在超过30万亿的代币上进行训练,学习语言和通用世界知识。
●●第二阶段(推理思维阶段):增加STEM、训练编码、推理和合成数据的比例,提高推理能力。
●●第三阶段(长上下文阶段):收集高质量的长上下文语料库,将上下文长度从4,096个32,768个tokens。
●后期阶段:
● Long-CoT Cold Start:构建包含数学、代码、逻辑推理和通用STEM问题的综合数据集,用于长-CoT的“冷启动”阶段。
●推理RL:采用GRPO等强化学习方法,优化模型参数,提高推理能力。
●思维模式融合:将“非思考”能力集成到“思考”模型中,设计聊天模板,使用户可以动态切换模型的思考过程。
●通用强化学习:建立覆盖20多个不同任务的奖励系统,全面提升模型在指令遵循、格式遵循、偏好在线营销和代理能力等方面的能力。
●由强到弱的蒸馏:通过离线策略和策略的知识转移,从大型模型中提炼到轻量级模型的知识转移,提高小规模模型的性能和推理能力。
>> 优势
●统一的思维模式:在不同模型之间切换,可以在不同模型之间切换,可以在思维模式和非思维模式之间快速动态地切换。
●可控的计算资源:通过“思考调度机制”,用户可以根据任务复杂度自适应地分配计算资源。
●强大的多语言能力:支持119种语言和方言,增强了全球可访问性。
●小规模模型构建:通过知识,可以以最少的计算资源构建具有性能的小规模模型。
●卓越的性能:在代码生成、数学推理和Agent任务等多种基准测试中取得了最先进的结果,与更大的MoE模型和母体模型相比具有竞争力。
>> 总结和观点
● Qwen3-235B-A22B在大多数任务中承担其他开源模型,参数较少。
● Qwen3 MoE模型可以用1/5的激活参数实现与Qwen3密集模型相似的性能。
● Qwen3密集模型在STEM、编码和推理基准测试中的性能甚至超过了参数规模更大的Qwen2.5模型。 ● 增加思考布局可以持续提高模型在各种
任务中的性能。
在线策略增长比强化学习能力以更少的GPU时间实现更好的性能。
● 思考模式融合和通用强化学习可以提高模型的通用能力和稳定性。
目录
《Qwen3 Technical Report》翻译与解读
Abstract
1、Introduction
Conclusion
《Qwen3 Technical Report》翻译与解读
| 地址 | 论文地址:[2505.09388] Qwen3 Technical Report |
| 时间 | 2025年5月14日 |
| 作者 | Qwen Team |
Abstract
| In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0. | 在本研究中,我们推出了 Qwen3,这是 Qwen 模型系列的最新版本。Qwen3 包含一系列大型语言模型(LLM),旨在提升性能、效率和多语言能力。Qwen3 系列涵盖了密集型和专家混合(MoE)架构的模型,参数规模从 0.6 亿到 2350 亿不等。Qwen3 的一项关键创新在于将思考模式(用于复杂、多步骤推理)和非思考模式(用于快速、基于上下文的响应)整合到一个统一框架中。这消除了在诸如聊天优化模型(例如 GPT-4o)和专用推理模型(例如 QwQ-32B)之间切换的需要,并能够根据用户查询或聊天模板动态切换模式。同时,Qwen3 引入了思考预算机制,允许用户在推理过程中自适应地分配计算资源,从而根据任务复杂度平衡延迟和性能。此外,通过利用旗舰模型的知识,我们显著减少了构建较小规模模型所需的计算资源,同时确保其具有高度竞争力的性能。实证评估表明,Qwen3 在包括代码生成、数学推理、代理任务等在内的各种基准测试中均取得了最先进的成果,与更大的 MoE 模型和专有模型相比也毫不逊色。与前一代 Qwen2.5 相比,Qwen3 扩大了多语言支持,从 29 种语言和方言增加到 119 种,通过改进跨语言理解和生成能力,增强了全球可访问性。为了促进可重复性以及社区驱动的研究和开发,所有 Qwen3 模型均在 Apache 2.0 许可下公开可用。 |
1、Introduction
| The pursuit of artificial general intelligence (AGI) or artificial super intelligence (ASI) has long been a goal for humanity. Recent advancements in large foundation models, e.g., GPT-4o (OpenAI, 2024), Claude 3.7 (Anthropic, 2025), Gemini 2.5 (DeepMind, 2025), DeepSeek-V3 (Liu et al., 2024a), Llama-4 (Meta-AI, 2025), and Qwen2.5 (Yang et al., 2024b), have demonstrated significant progress toward this objective. These models are trained on vast datasets spanning trillions of tokens across diverse domains and tasks, effectively distilling human knowledge and capabilities into their parameters. Furthermore, recent developments in reasoning models, optimized through reinforcement learning, highlight the potential for foundation models to enhance inference-time scaling and achieve higher levels of intelligence, e.g., o3 (OpenAI, 2025), DeepSeek-R1 (Guo et al., 2025). While most state-of-the-art models remain proprietary, the rapid growth of open-source communities has substantially reduced the performance gap between open-weight and closed-source models. Notably, an increasing number of top-tier models (Meta-AI, 2025; Liu et al., 2024a; Guo et al., 2025; Yang et al., 2024b) are now being released as open-source, fostering broader research and innovation in artificial intelligence. In this work, we introduce Qwen3, the latest series in our foundation model family, Qwen. Qwen3 is a collection of open-weight large language models (LLMs) that achieve state-of-the-art performance across a wide variety of tasks and domains. We release both dense and Mixture-of-Experts (MoE) models, with the number of parameters ranging from 0.6 billion to 235 billion, to meet the needs of different downstream applications. Notably, the flagship model, Qwen3-235B-A22B, is an MoE model with a total of 235 billion parameters and 22 billion activated ones per token. This design ensures both high performance and efficient inference. | 1. 引言 长期以来,追求通用人工智能(AGI)或超级人工智能(ASI)一直是人类的目标。近期,大型基础模型(如 OpenAI 于 2024 年发布的 GPT-4、Anthropic 于 2025 年发布的 Claude 3.7、DeepMind 于 2025 年发布的 Gemini 2.5、Liu 等人于 2024 年发布的 DeepSeek-V3、Meta-AI 于 2025 年发布的 Llama-4 以及 Yang 等人于 2024 年发布的 Qwen2.5)取得了显著进展,朝着这一目标迈进。这些模型在涵盖数万亿标记的广泛领域和任务的海量数据集上进行训练,有效地将人类的知识和能力融入其参数之中。此外,通过强化学习优化的推理模型的最新发展,突显了基础模型在推理时间扩展方面提升性能以及实现更高智能水平的潜力,例如 OpenAI 于 2025 年发布的 o3 和 Guo 等人于 2025 年发布的 DeepSeek-R1。尽管大多数最先进的模型仍为专有,但开源社区的迅速发展已大幅缩小了开源模型与闭源模型之间的性能差距。值得注意的是,越来越多的顶级模型(如 Meta-AI 于 2025 年发布的、Liu 等人于 2024 年发布的、Guo 等人于 2025 年发布的)杨等人(2024 年 b)正在将相关成果以开源形式发布,这促进了人工智能领域更广泛的研究与创新。 在本研究中,我们推出了 Qwen 系列的最新成员——Qwen3。Qwen3 是一系列开放权重的大语言模型(LLM),在众多任务和领域中均达到了最先进的性能水平。我们发布了密集型和专家混合型(MoE)模型,参数数量从 6 亿到 2350 亿不等,以满足不同下游应用的需求。值得一提的是,旗舰模型 Qwen3-235B-A22B 是一个 MoE 模型,总参数量达 2350 亿,每标记激活参数量为 220 亿。这种设计既保证了高性能,又实现了高效推理。 |
| Qwen3 introduces several key advancements to enhance its functionality and usability. First, it integrates two distinct operating modes, thinking mode and non-thinking mode, into a single model. This allows users to switch between these modes without alternating between different models, e.g., switching from Qwen2.5 to QwQ (Qwen Team, 2024). This flexibility ensures that developers and users can adapt the model’s behavior to suit specific tasks efficiently. Additionally, Qwen3 incorporates thinking budgets, pro-viding users with fine-grained control over the level of reasoning effort applied by the model during task execution. This capability is crucial to the optimization of computational resources and performance, tai-loring the model’s thinking behavior to meet varying complexity in real-world applications. Furthermore, Qwen3 has been pre-trained on 36 trillion tokens covering up to 119 languages and dialects, effectively enhancing its multilingual capabilities. This broadened language support amplifies its potential for deployment in global use cases and international applications. These advancements together establish Qwen3 as a cutting-edge open-source large language model family, capable of effectively addressing complex tasks across various domains and languages. The pre-training process for Qwen3 utilizes a large-scale dataset consisting of approximately 36 trillion tokens, curated to ensure linguistic and domain diversity. To efficiently expand the training data, we employ a multi-modal approach: Qwen2.5-VL (Bai et al., 2025) is finetuned to extract text from extensive PDF documents. We also generate synthetic data using domain-specific models: Qwen2.5-Math (Yang et al., 2024c) for mathematical content and Qwen2.5-Coder (Hui et al., 2024) for code-related data. The pre-training process follows a three-stage strategy. In the first stage, the model is trained on about 30 trillion tokens to build a strong foundation of general knowledge. In the second stage, it is further trained on knowledge-intensive data to enhance reasoning abilities in areas like science, technology, engineering, and mathematics (STEM) and coding. Finally, in the third stage, the model is trained on long-context data to increase its maximum context length from 4,096 to 32,768 tokens. | Qwen3 引入了多项关键改进,以增强其功能性和易用性。首先,它将两种不同的运行模式——思考模式和非思考模式整合到了一个模型中。这使得用户能够在不切换不同模型的情况下(例如从 Qwen2.5 切换到 QwQ,Qwen 团队,2024 年)在这些模式之间进行切换。这种灵活性确保了开发人员和用户能够高效地调整模型的行为以适应特定任务。此外,Qwen3 还引入了思考预算,让用户能够精细控制模型在任务执行过程中所投入的推理努力程度。这一能力对于优化计算资源和性能至关重要,能够根据实际应用中的复杂程度调整模型的思考行为。此外,Qwen3 还在涵盖多达 119 种语言和方言的约 36 万亿个标记的数据集上进行了预训练,极大地增强了其多语言能力。这种广泛的语言支持扩大了其在全球用例和国际应用中的部署潜力。这些进步共同使 Qwen3 成为一个前沿的开源大型语言模型系列,能够有效应对各种领域和语言中的复杂任务。 Qwen3 的预训练过程使用了一个大规模的数据集,包含约 36 万亿个标记,经过精心整理以确保语言和领域的多样性。为了高效地扩充训练数据,我们采用了一种多模态方法:对 Qwen2.5-VL(Bai 等人,2025 年)进行微调,以从大量的 PDF 文档中提取文本。我们还使用特定领域的模型生成合成数据:Qwen2.5-Math(Yang 等人,2024 年 c)用于数学内容,Qwen2.5-Coder(Hui 等人,2024 年)用于代码相关数据。预训练过程遵循三阶段策略。在第一阶段,模型在约 30 万亿个标记上进行训练,以构建扎实的通用知识基础。在第二阶段,模型进一步在知识密集型数据上进行训练,以增强在科学、技术、工程和数学(STEM)以及编码等领域的推理能力。最后,在第三阶段,模型在长上下文数据上进行训练,将其最大上下文长度从 4096 个标记增加到 32768 个标记。 |
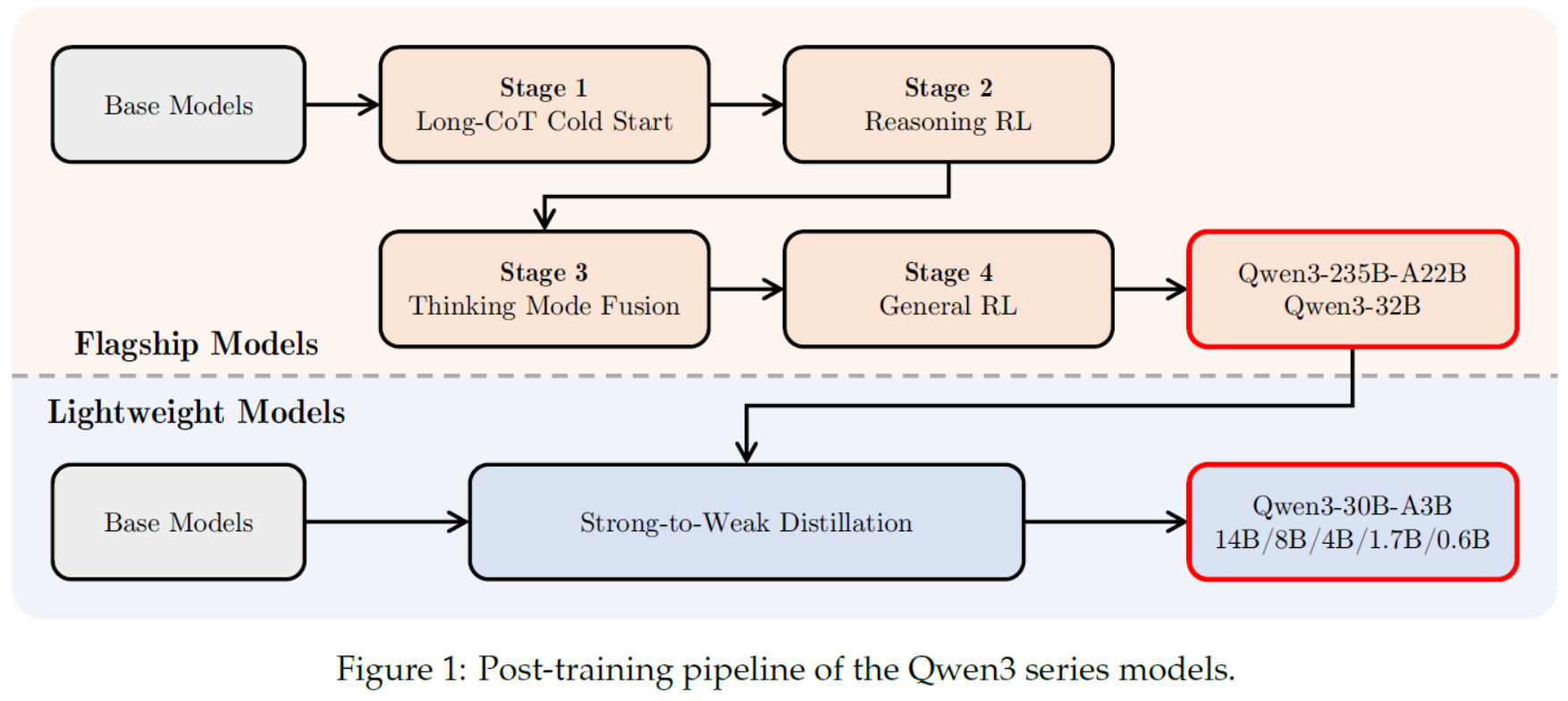
| To better align foundation models with human preferences and downstream applications, we employ a multi-stage post-training approach that empowers both thinking (reasoning) and non-thinking modes. In the first two stages, we focus on developing strong reasoning abilities through long chain-of-thought (CoT) cold-start finetuning and reinforcement learning focusing on mathematics and coding tasks. In the final two stages, we combine data with and without reasoning paths into a unified dataset for further fine-tuning, enabling the model to handle both types of input effectively, and we then apply general-domain reinforcement learning to improve performance across a wide range of downstream tasks. For smaller models, we use strong-to-weak distillation, leveraging both off-policy and on-policy knowledge transfer from larger models to enhance their capabilities. Distillation from advanced teacher models significantly outperforms reinforcement learning in performance and training efficiency. We evaluate both pre-trained and post-trained versions of our models across a comprehensive set of benchmarks spanning multiple tasks and domains. Experimental results show that our base pre-trained models achieve state-of-the-art performance. The post-trained models, whether in thinking or non-thinking mode, perform competitively against leading proprietary models and large mixture-of-experts (MoE) models such as o1, o3-mini, and DeepSeek-V3. Notably, our models excel in coding, mathematics, and agent-related tasks. For example, the flagship model Qwen3-235B-A22B achieves 85.7 on AIME’24 and 81.5 on AIME’25 (AIME, 2025), 70.7 on LiveCodeBench v5 (Jain et al., 2024), 2,056 on CodeForces, and 70.8 on BFCL v3 (Yan et al., 2024). In addition, other models in the Qwen3 series also show strong performance relative to their size. Furthermore, we observe that increasing the thinking budget for thinking tokens leads to a consistent improvement in the model’s performance across various tasks. In the following sections, we describe the design of the model architecture, provide details on its training procedures, present the experimental results of pre-trained and post-trained models, and finally, conclude this technical report by summarizing the key findings and outlining potential directions for future research. | 为了使基础模型更好地与人类偏好和下游应用相契合,我们采用了一种多阶段的后期训练方法,这种方法既支持推理模式也支持非推理模式。在前两个阶段,我们通过长链思维(CoT)冷启动微调和专注于数学和编程任务的强化学习来培养强大的推理能力。在最后两个阶段,我们将有推理路径和无推理路径的数据合并到一个统一的数据集中进行进一步微调,使模型能够有效地处理这两种类型的输入,然后应用通用领域的强化学习来提高其在广泛下游任务中的表现。对于较小的模型,我们采用强到弱的知识蒸馏,利用来自较大模型的离策略和在策略知识转移来增强其能力。来自先进教师模型的知识蒸馏在性能和训练效率方面显著优于强化学习。 我们对模型的预训练版本和后期训练版本进行了全面评估,涵盖了多个任务和领域的基准测试。实验结果表明,我们的基础预训练模型达到了最先进的性能。无论是思考模式还是非思考模式下的后训练模型,在与领先的专有模型和大型专家混合模型(如 o1、o3-mini 和 DeepSeek-V3)的竞争中都表现出色。值得注意的是,我们的模型在编程、数学和代理相关任务中表现出色。例如,旗舰模型 Qwen3-235B-A22B 在 AIME'24 中得分 85.7,在 AIME'25(AIME,2025)中得分 81.5,在 LiveCodeBench v5(Jain 等人,2024)中得分 70.7,在 CodeForces 中得分 2056,在 BFCL v3(Yan 等人,2024)中得分 70.8。此外,Qwen3 系列中的其他模型相对于其规模也表现出色。另外,我们观察到增加思考标记的思考预算会持续提升模型在各种任务中的性能。 在接下来的部分中,我们将描述模型架构的设计,提供其训练过程的详细信息,展示预训练和后训练模型的实验结果,并在最后总结本技术报告的关键发现,概述未来研究的潜在方向。 |
Table 1: Model architecture of Qwen3 dense models.
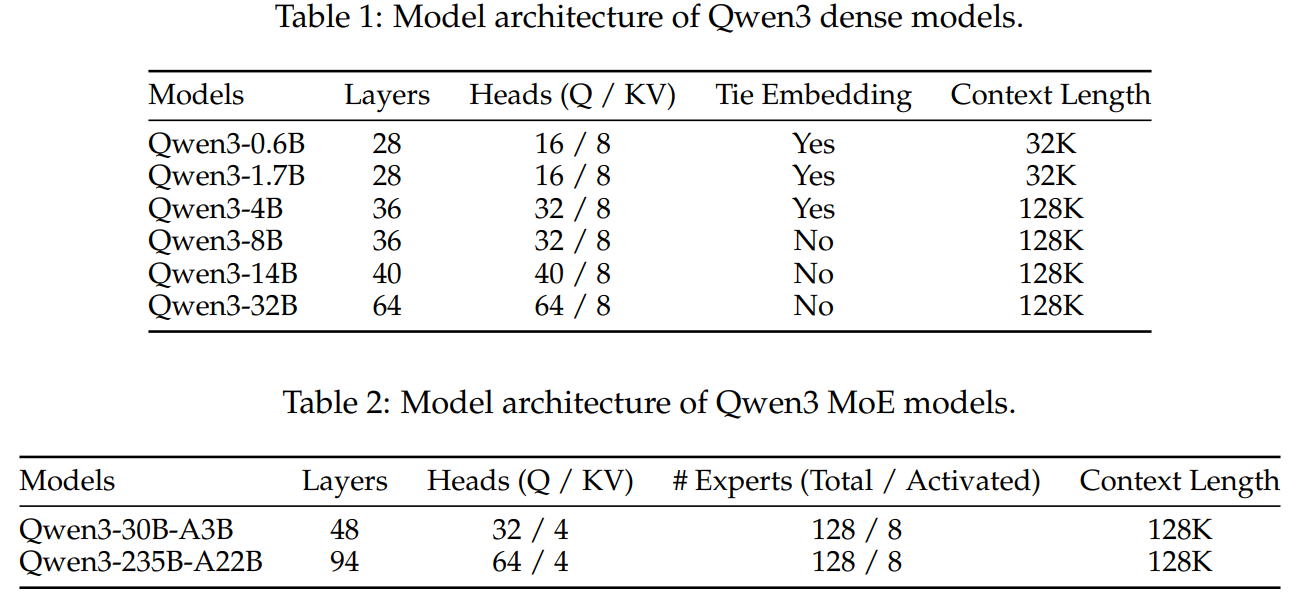
Figure 1: Post-training pipeline of the Qwen3 series models.
Conclusion
| In this technical report, we introduce Qwen3, the latest version of the Qwen series. Qwen3 features both thinking mode and non-thinking mode, allowing users to dynamically manage the number of tokens used for complex thinking tasks. The model was pre-trained on an extensive dataset containing 36 trillion tokens, enabling it to understand and generate text in 119 languages and dialects. Through a series of comprehensive evaluations, Qwen3 has shown strong performance across a range of standard benchmarks for both pre-trained and post-trained models, including tasks related to code generation, mathematics, reasoning, and agents. In the near future, our research will focus on several key areas. We will continue to scale up pretraining by using data that is both higher in quality and more diverse in content. At the same time, we will work on improving model architecture and training methods for the purposes of effective compression, scaling to extremely long contexts, etc. In addition, we plan to increase computational resources for reinforcement learning, with a particular emphasis on agent-based RL systems that learn from environmental feedback. This will allow us to build agents capable of tackling complex tasks that require inference time scaling. | 在这份技术报告中,我们介绍了 Qwen 系列的最新版本 Qwen3。Qwen3 具备思考模式和非思考模式,用户能够动态管理用于复杂思考任务的标记数量。该模型在包含 36 万亿标记的大型数据集上进行了预训练,能够理解和生成 119 种语言和方言的文本。通过一系列全面的评估,Qwen3 在预训练和后训练模型的标准基准测试中均表现出色,包括代码生成、数学、推理和代理相关的任务。 在不久的将来,我们的研究将集中在几个关键领域。我们将继续通过使用质量更高、内容更丰富的数据来扩大预训练规模。同时,我们将致力于改进模型架构和训练方法,以实现有效的压缩、扩展到极长的上下文等目标。此外,我们计划增加用于强化学习的计算资源,特别侧重于从环境反馈中学习的基于代理的强化学习系统。这将使我们能够构建出能够应对需要推理时间扩展的复杂任务的智能体。 |