私有知识库 Coco AI 实战(七):摄入本地 PDF 文件
是否有些本地文件要检索?没问题。我们先对 PDF 类的文件进行处理,其他的文件往后稍。
Coco Server Token
创建一个 token 备用。

PDF_Reader
直接写个 python 程序解析 PDF 内容,上传到 Coco Server 就行了。还记得以前都是直接写入 Coco 后台的 Easysearch 的,这次我们走 Coco Server 的 API 写入数据。
程序逻辑
- 检查是否存在 id 为 local_pdf 的 connector 和 datasource,不存在就创建。
- 遍历一个目录中的所有 pdf 文件
- 把 pdf 文件的内容发送给 Coco Server 的 API
使用程序
- 修改 220 行替换成自己的 Coco server token
- 修改 221 行换成自己 Coco Server 的地址
- 修改 229 行换成自己 PDF 文件的目录
- 运行程序
from PyPDF2 import PdfReader
import os
import requests
from pathlib import Pathclass PDFPage:def __init__(self, title: str, content: str, page_number: int):self.title = titleself.content = contentself.type = "pdf"self.page = page_numberdef read_pdf(file_path: str) -> list[PDFPage]:"""读取PDF文件并为每一页创建一个PDFPage对象Args:file_path (str): PDF文件的路径Returns:list[PDFPage]: 包含所有页面对象的列表"""# 检查文件是否存在if not os.path.exists(file_path):raise FileNotFoundError(f"找不到文件: {file_path}")# 检查文件是否为PDFif not file_path.lower().endswith('.pdf'):raise ValueError("文件必须是PDF格式")# 获取文件名(不包含路径)file_name = os.path.basename(file_path)# 创建PDF阅读器对象pdf_reader = PdfReader(file_path)pages = []# 遍历每一页for page_num in range(len(pdf_reader.pages)):# 获取当前页面page = pdf_reader.pages[page_num]# 提取文本内容content = page.extract_text()# 创建页面对象pdf_page = PDFPage(title=file_name,content=content,page_number=page_num + 1 # 页码从1开始)pages.append(pdf_page)return pagesdef send_to_coco_server(page: PDFPage,datasource_id: str,api_token: str,file_path: str,server_url: str = "http://localhost:9000") -> dict:"""将PDF页面内容发送到Coco ServerArgs:page (PDFPage): PDF页面对象datasource_id (str): Coco Server的数据源IDapi_token (str): API Tokenfile_path (str): PDF文件的完整路径server_url (str): Coco Server的URLReturns:dict: 服务器响应"""headers = {'X-API-TOKEN': api_token, 'Content-Type': 'application/json'}# 将Windows路径转换为标准路径格式(使用正斜杠)file_url = file_path.replace('\\', '/')data = {'title': f"{page.title} - 第{page.page}页",'summary': f"PDF文档 {page.title} 的第{page.page}页内容",'content': page.content,'category': 'local_pdf','url': file_url}url = f"{server_url}/datasource/{datasource_id}/_doc"response = requests.post(url, headers=headers, json=data)return response.json()def process_directory(directory_path: str, api_token: str, datasource_id: str,server_url: str) -> None:"""处理指定目录下的所有PDF文件Args:directory_path (str): 目录路径api_token (str): API Tokendatasource_id (str): 数据源IDserver_url (str): 服务器URL"""# 确保目录存在if not os.path.exists(directory_path):raise FileNotFoundError(f"目录不存在: {directory_path}")# 获取所有PDF文件pdf_files = list(Path(directory_path).rglob("*.pdf"))total_files = len(pdf_files)print(f"找到 {total_files} 个PDF文件")# 处理每个PDF文件for file_index, pdf_file in enumerate(pdf_files, 1):print(f"\n处理文件 {file_index}/{total_files}: {pdf_file}")try:# 获取文件的绝对路径absolute_path = str(pdf_file.absolute())# 读取PDF文件pdf_pages = read_pdf(absolute_path)# 处理每一页for page in pdf_pages:print(f" 正在处理: {page.title} - 第{page.page}页")try:result = send_to_coco_server(page, datasource_id,api_token, absolute_path,server_url)print(f" 上传成功! 文档ID: {result.get('_id')}")except Exception as e:print(f" 上传失败: {str(e)}")except Exception as e:print(f"处理文件 {pdf_file} 时出错: {str(e)}")continuedef create_connector_and_datasource(server_url: str, api_token: str) -> str:"""创建connector和datasourceArgs:server_url (str): 服务器URLapi_token (str): API TokenReturns:str: 创建的datasource ID"""headers = {'X-API-TOKEN': api_token, 'Content-Type': 'application/json'}# 检查connector是否存在connector_id = 'local_pdf'connector_url = f"{server_url}/connector/{connector_id}"try:response = requests.get(connector_url, headers=headers)if response.status_code == 404:# 创建connectorconnector = {'name': 'Local PDF Connector','category': 'local_files','icon': 'font_filetype-PDF'}print("创建 local_pdf connector...")response = requests.put(f"{server_url}/connector/local_pdf?replace=true",headers=headers,json=connector)# print(response.json())# print(response.status_code)if response.status_code == 200 and response.json().get('result') == 'updated':print("Connector创建成功")else:raise Exception(f"创建Connector失败: {response.text}")# 检查datasource是否存在datasource_url = f"{server_url}/datasource/local_pdf"response = requests.get(datasource_url, headers=headers)if response.status_code == 404:# 创建datasourcedatasource = {'name': 'Local PDF Datasource','id': 'local_pdf','type': 'connector','connector': {'id': 'local_pdf',},'sync_enabled': False,'enabled': True}print("创建 local_pdf datasource...")response = requests.put(f"{server_url}/datasource/local_pdf?replace=true",headers=headers,json=datasource)if response.status_code == 200 and response.json().get('result') == 'updated':print("Datasource创建成功")else:raise Exception(f"创建Datasource失败: {response.text}")return 'local_pdf'except Exception as e:print(f"创建过程中发生错误: {str(e)}")raisedef main():"""主函数,处理指定目录下的所有PDF文件并发送到Coco Server"""try:# Coco Server配置api_token = "d02rutog1maf0invql60130c0y8g4se4i5brurqa2k72r6ozysvxvzgda90cnbwg26bw4g7tv09zjfuw0c33"server_url = "http://192.168.10.3:9000"# 创建或获取datasourceprint("检查并创建必要的connector和datasource...")datasource_id = create_connector_and_datasource(server_url, api_token)print(f"使用datasource ID: {datasource_id}")# 指定要处理的目录directory_path = "D:/LangChain/infini-rag/easysearch" # 替换为你的目录路径# 处理目录process_directory(directory_path, api_token, datasource_id, server_url)print("\n所有文件处理完成!")except Exception as e:print(f"发生错误: {str(e)}")if __name__ == "__main__":main()测试搜索
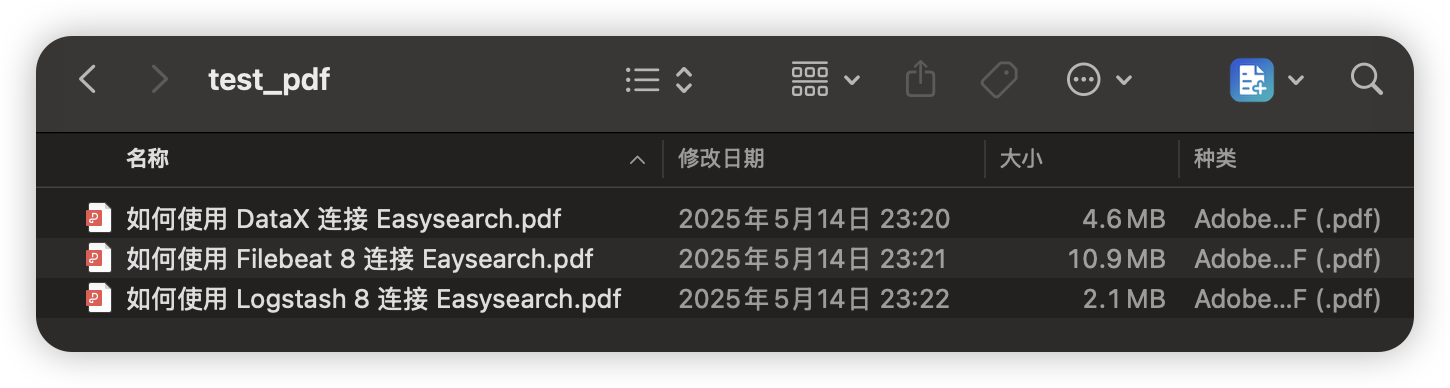
我的测试目录里有三个 PDF 文件。
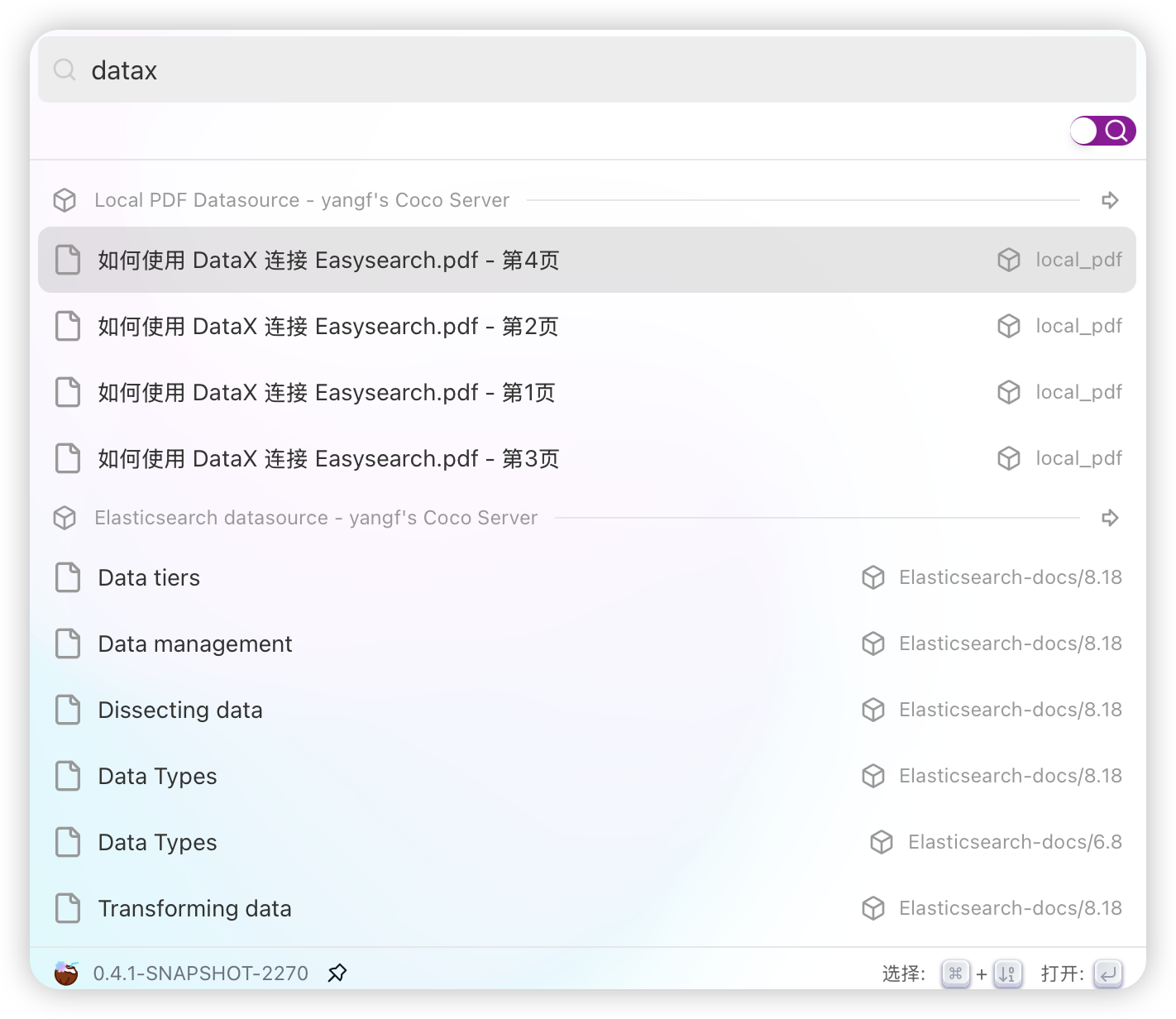
通过程序采集内容后,就能对这些内容进行搜索了。
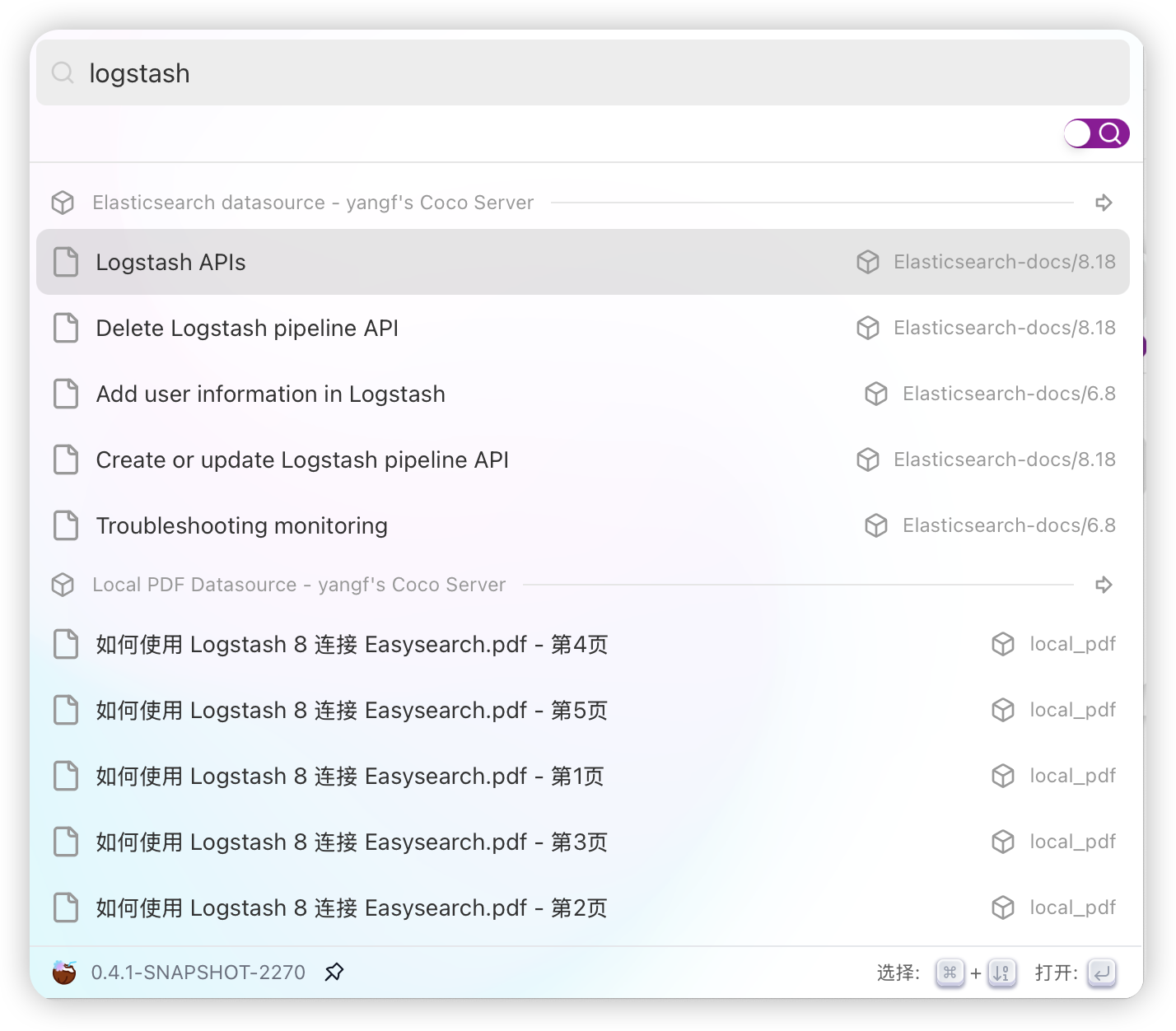
选择对应的条目回车就能直接打开 PDF 文件。
测试小助手
有了之前创建小助手的经验,我们很快也能打造一个本地 PDF 资源的小助手。
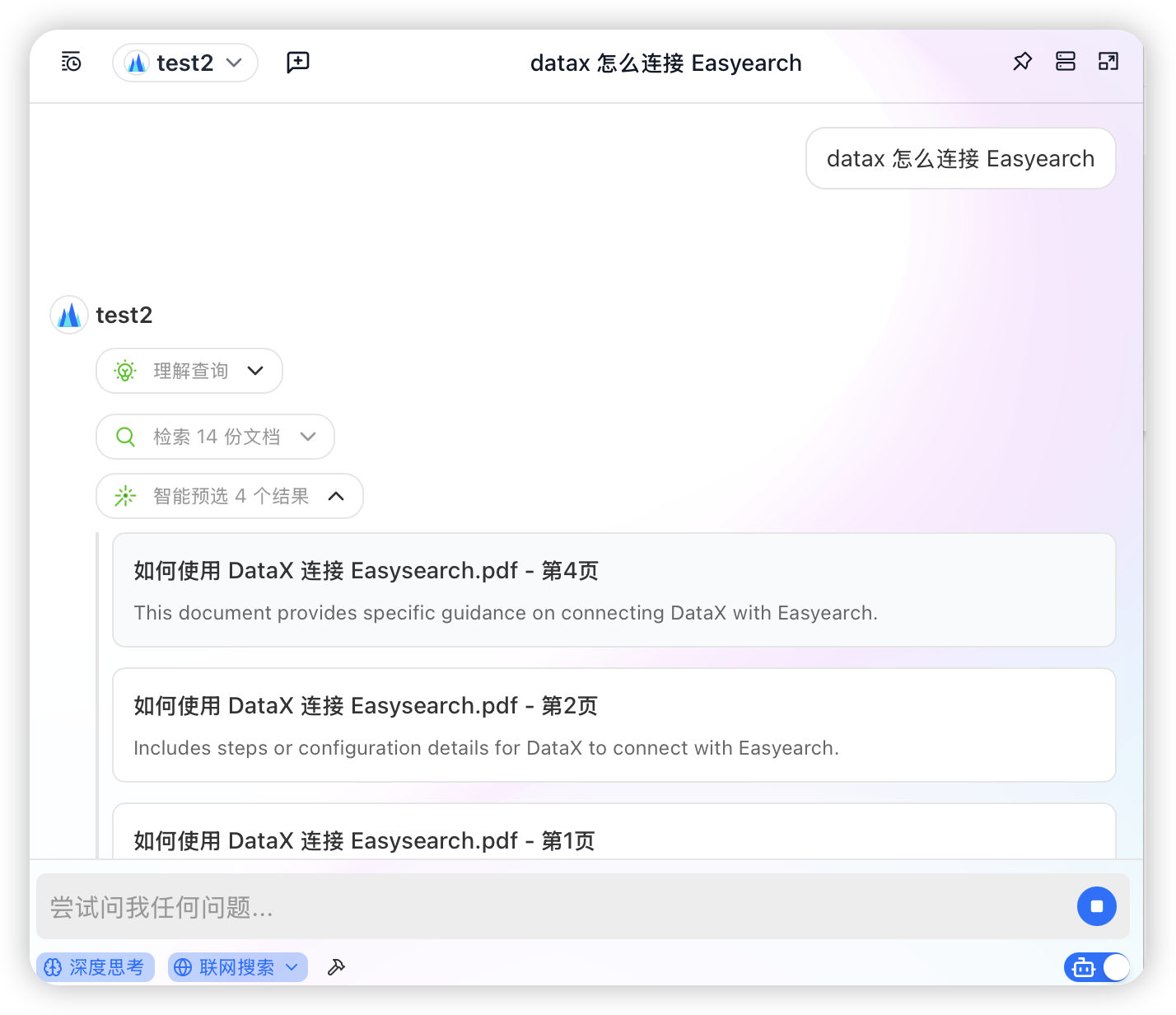
回答内容基本来自本地 PDF 文件内容,用这个来管理本地 PDF 知识,真是太方便了。