使用LLaMA-Factory微调ollama中的大模型(二)------使用数据集微调大模型
前提:LLaMA-Factory已安装完毕并运行成功,详见上一篇博客使用LLaMA-Factory微调ollama中的大模型(一)------家用电脑安装LLaMA-Factory工具-CSDN博客
1.寻找可以用的数据集
(1)根据官方文档,我们可以看到LLaMA-Factory支持alpaca 格式和 sharegpt 格式的数据集
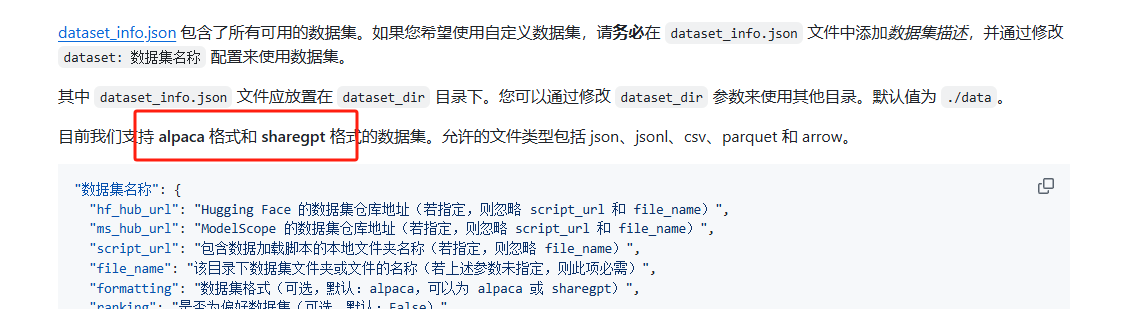
所谓alpaca 格式,就是有instruction指令,input输入,output输出等,其中instruction指令和output输出是必须的,举个例子:一个json对象中,
instruction:帮我找一下错别字
input:清明时节雨分分
output:清明时节雨纷纷
这样就是一个让大模型找错别字的数据
或者
instruction:告诉我一句李白写的诗句
output:飞流直下三千尺,疑是银河落九天

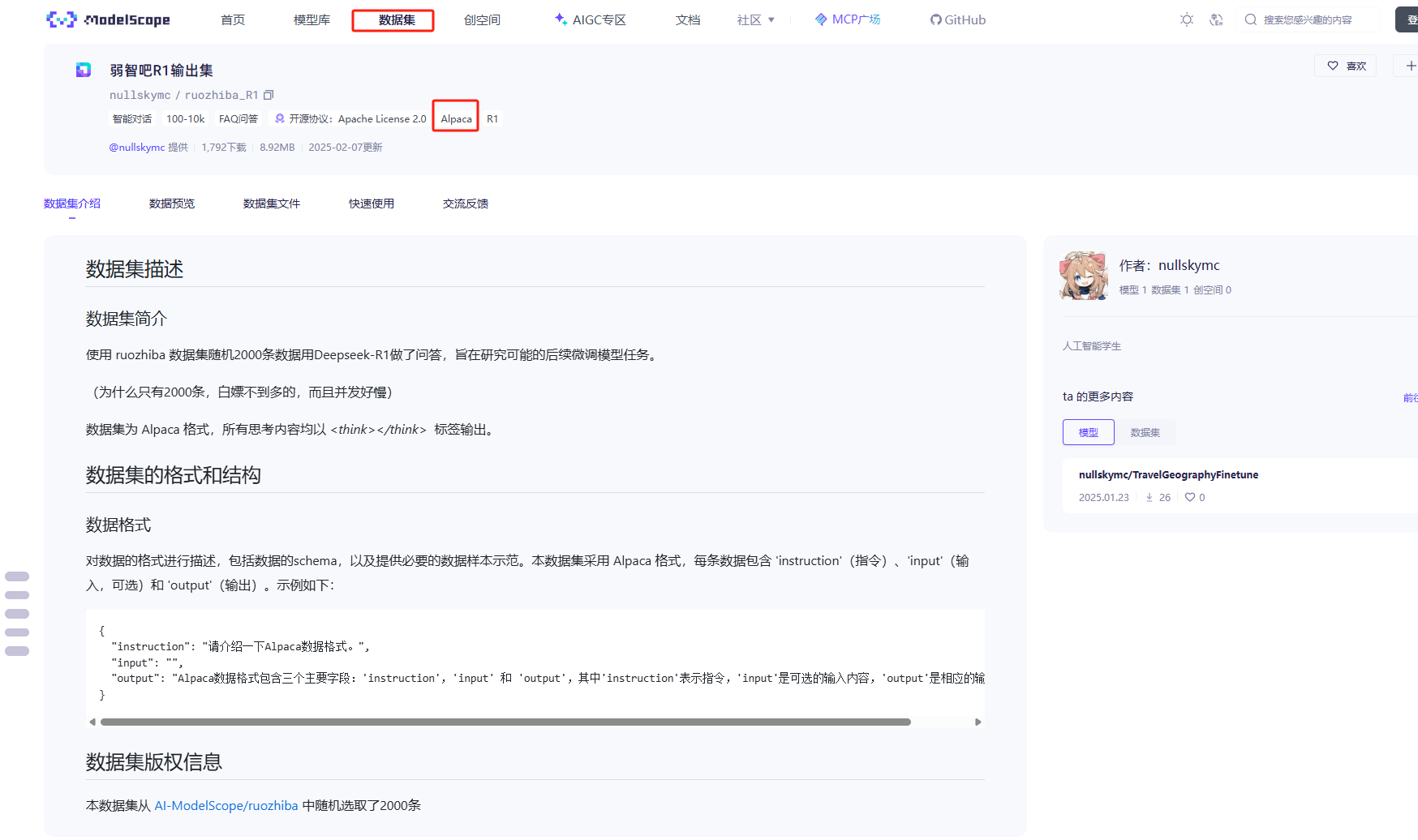
(2)访问魔搭社区魔搭社区,先找一个数据集来用,当然针对自己业务需求,也可以自己创造数据集
这里找到一个弱智吧R1输出集,是Alpaca格式的
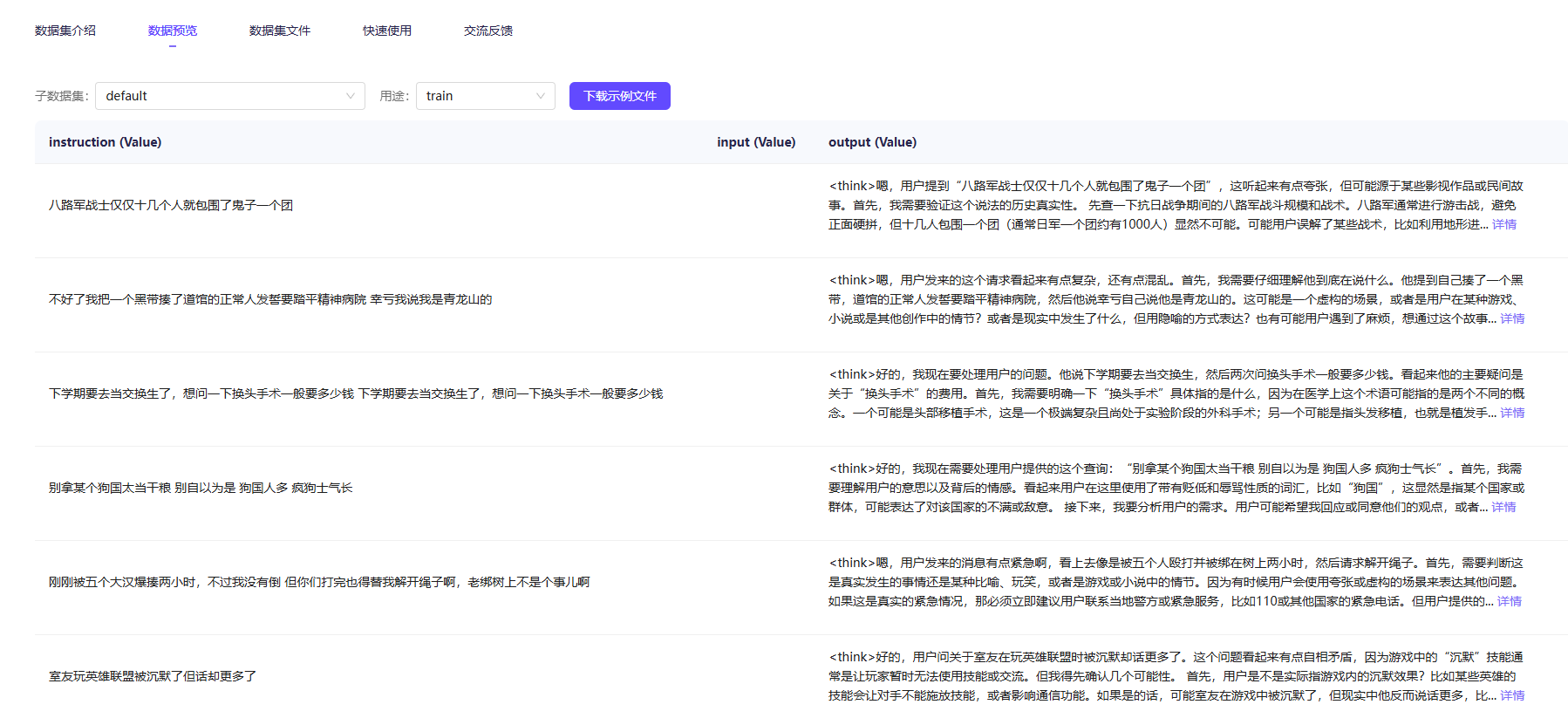
预览数据,确实也符合要求
直接下载就行,虽然是jsonl格式,但是也符合要求
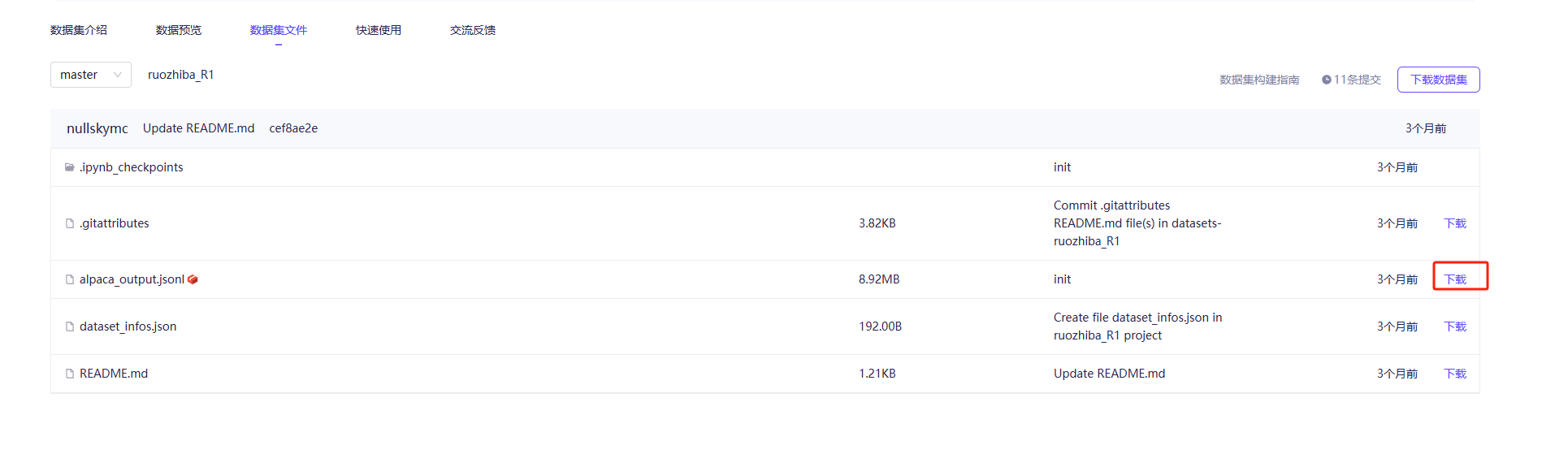
下载完成后,放入LLaMA-Factory目录下的data中
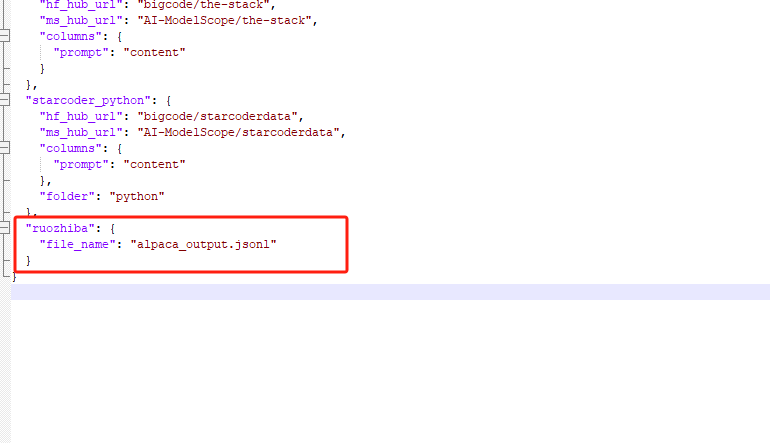
修改dataset_info.json文件,在最下面加入这个数据集的配置
2.训练大模型
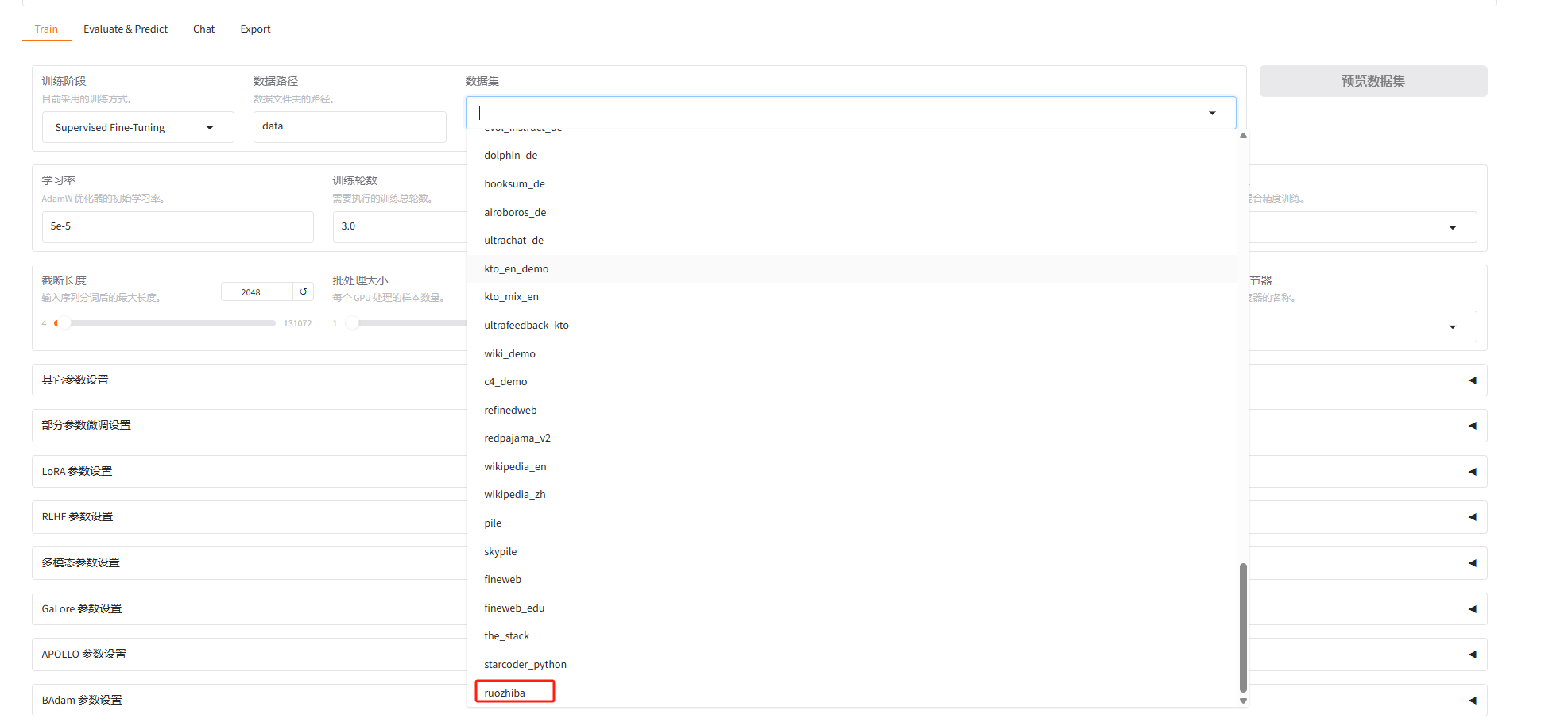
回到LLaMA-Factory的界面,Train里面的数据集,找到我们配置的ruozhiba
我为了搞快点,训练论述定了3轮,实际上数据集越大,轮数可以少点,3-5轮就可以了,数据集小了,最好训练多几轮,提高模型的质量,如果数据集太小了,调100轮也没啥用
点击开始,看到下面输出了日志,训练就开始了,电脑变得很卡
看看任务管理器,显卡确实开始满负荷运行了,看一直打开着的cmd界面,有进度条可以看
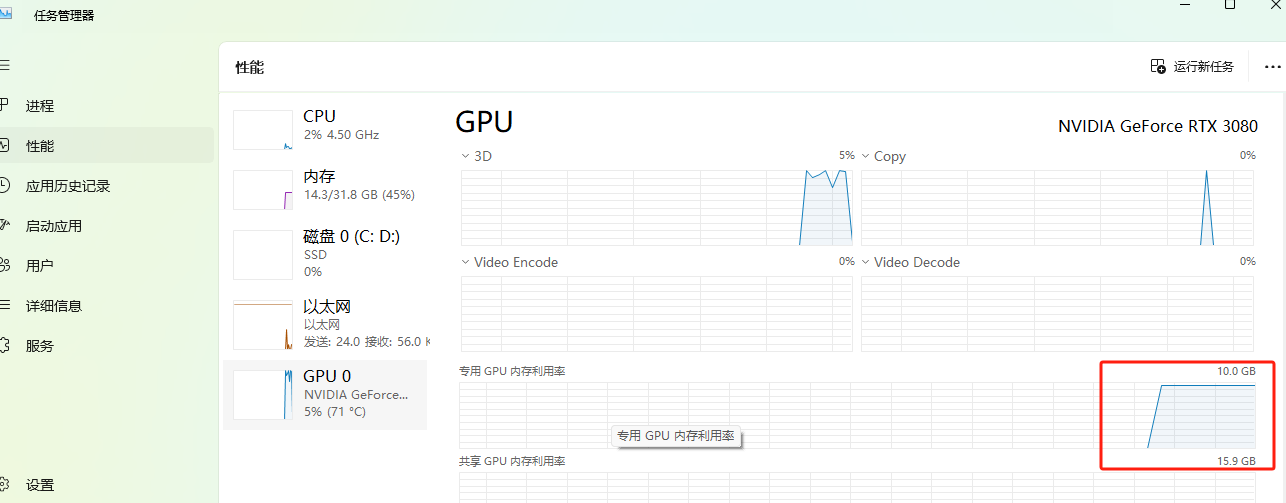

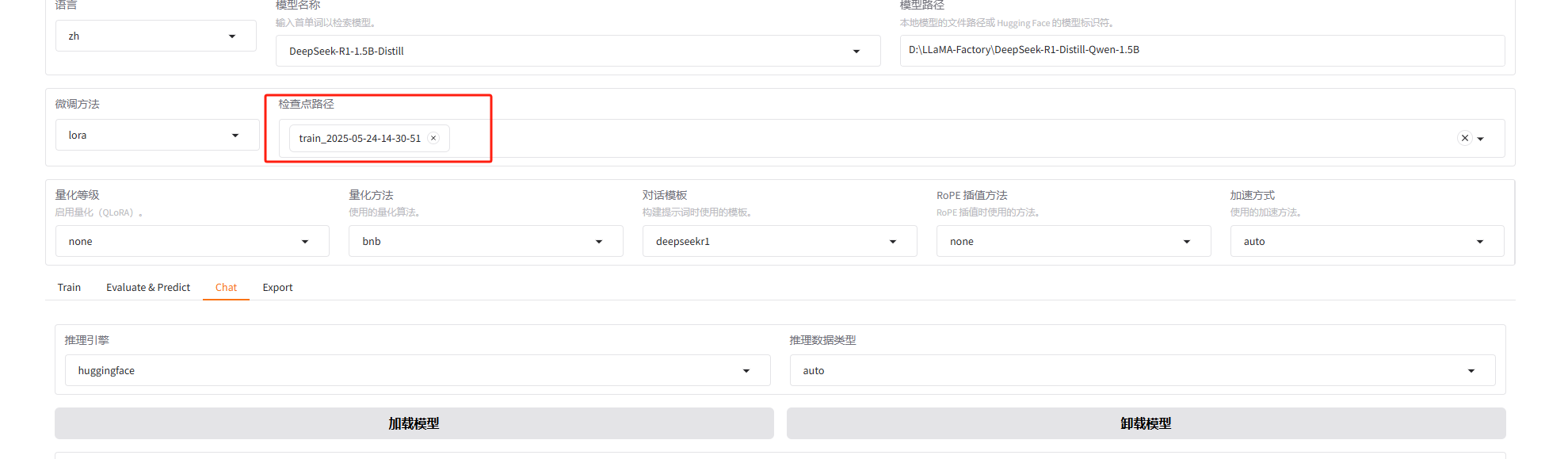
我大概等了一个半小时,完成后在这里选择训练的这个,然后点击加载模型,就可以测试了
在刚刚的数据集中找一个例子试试
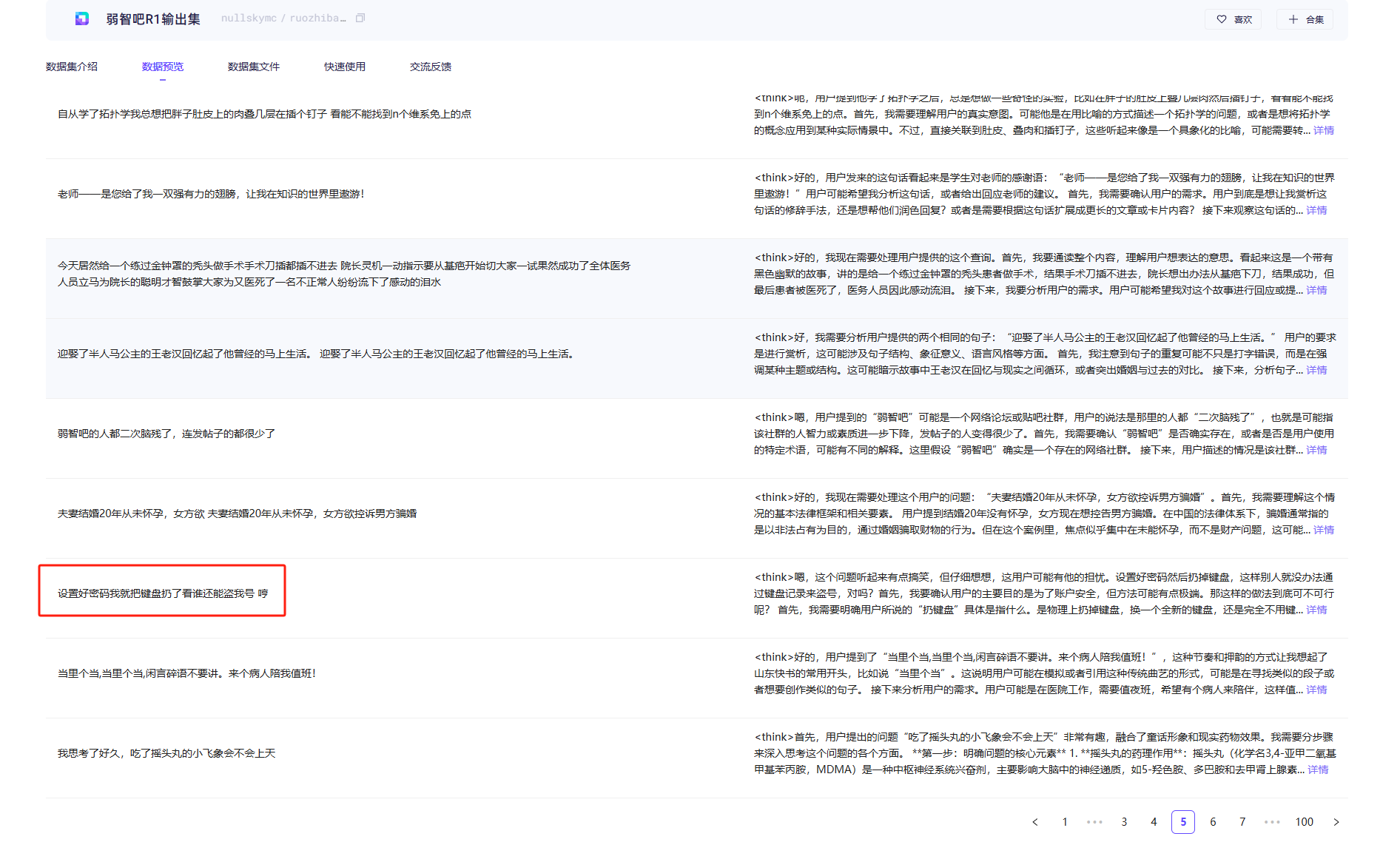
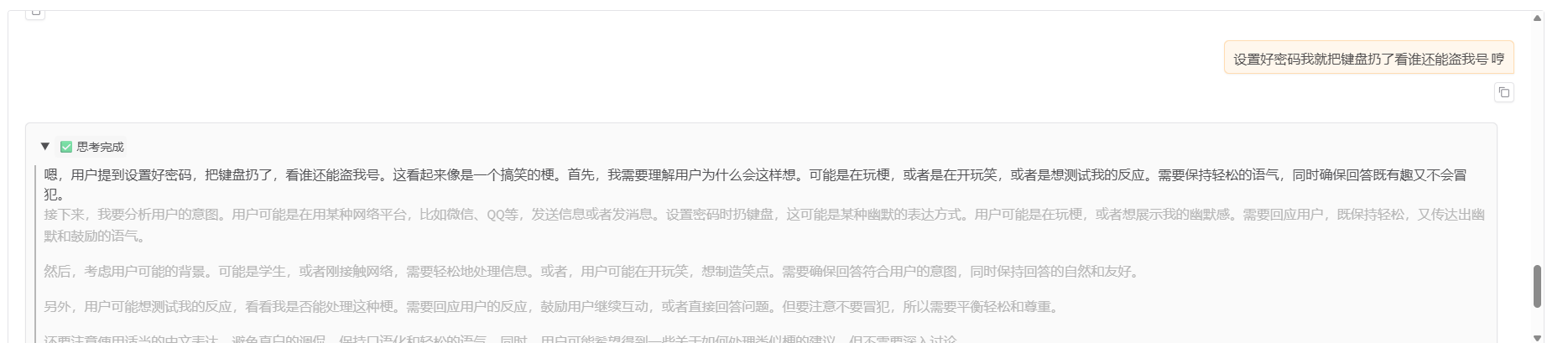
可以看到输出的内容确实和数据集中的一个路数了,正儿八经回答弱智问题
3.导出大模型
点击Export,输入导出的目录,点击开始导出就可以了
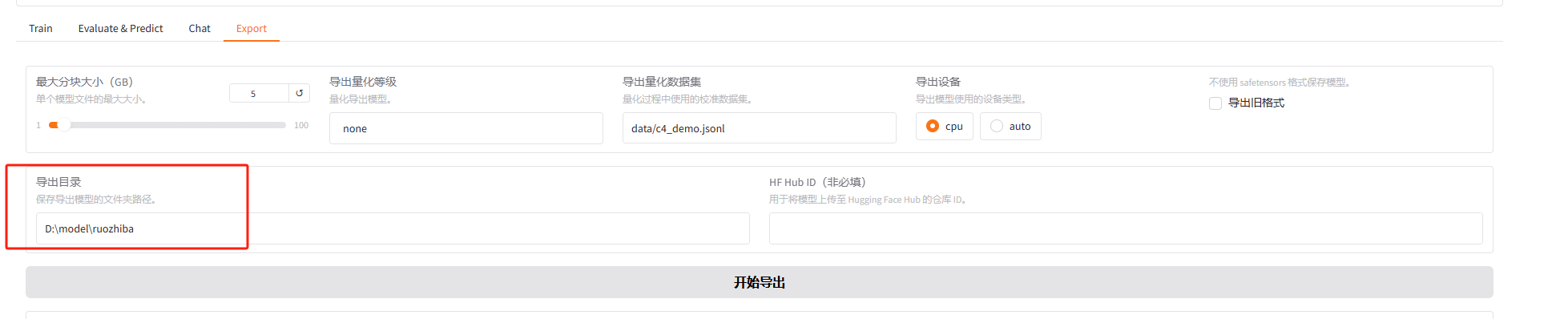
可以看到已经有了
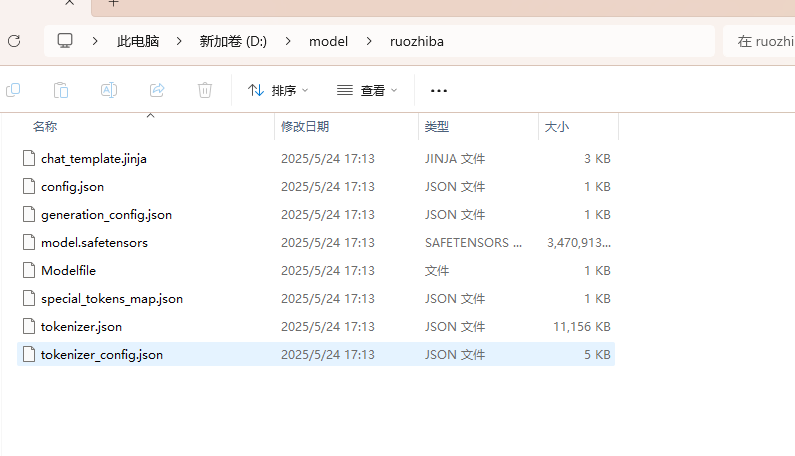
ollama导入模型
进入模型的这个文件夹,输入命令ollama create ruozhiba_deepseek_1.5b -f Modelfile,名字自己随意
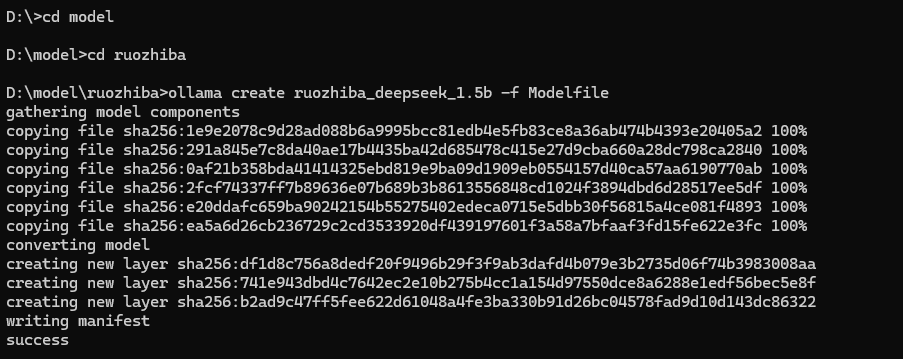
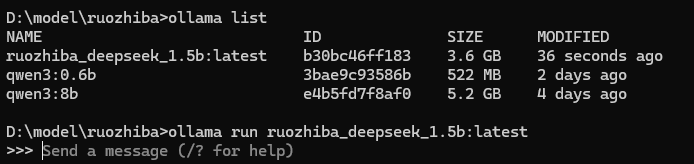
可以查看已经完成了,可以使用了
这只是最简单的使用LLaMa-Factory微调大模型的操作,更多的参数意义以及优化的操作还有待好好研究。