⭐️⭐️⭐️白嫖的阿里云认证⭐️⭐️⭐️ 第三弹【课时2:RAG应用的构建和优化】for「大模型Clouder认证:RAG应用构建及优化」
一、学习目标:明确核心能力培养方向
概要
通过系统化学习,掌握在阿里云百炼平台构建可调用RAG应用的全流程,并深入理解RAG技术的局限性及针对性优化策略,形成从理论到实战的完整知识体系。
具体目标列表
- 流程掌握:
- 精准操作百炼平台完成「数据导入→知识索引创建→应用开发→多方式API调用」的闭环,熟悉各环节状态监控(如数据导入进度、文档解析状态)。
- 区分智能体应用调用与Assistant API调用的适用场景,能根据业务需求选择合适的接口方案。
- 问题认知:
- 能结合具体案例(如用户模糊提问、知识库漏检、答案幻觉)分析RAG三大核心局限性的产生机制,识别技术链中的薄弱环节。
- 优化能力:
- 针对不同业务场景(如法律文档检索、电商导购问答)定制Chunk切分策略(领域知识切分/上下文感知切分),掌握Embedding模型选型的核心指标(中文场景优先BGE-large-zh-v1.5)。
- 实现Multi-Query多路召回、Self-RAG自我反思等优化策略的提示词设计,理解其对生成答案相关性的提升逻辑。
- 评测思维:
- 建立包含「检索准确率(Precision)、召回率(Recall)」「生成真实性(Factuality)、实用性(Actionability)」的多维评测体系,能使用Ragas工具进行初步性能诊断。
二、知识点汇总:从构建到优化的全链路解析
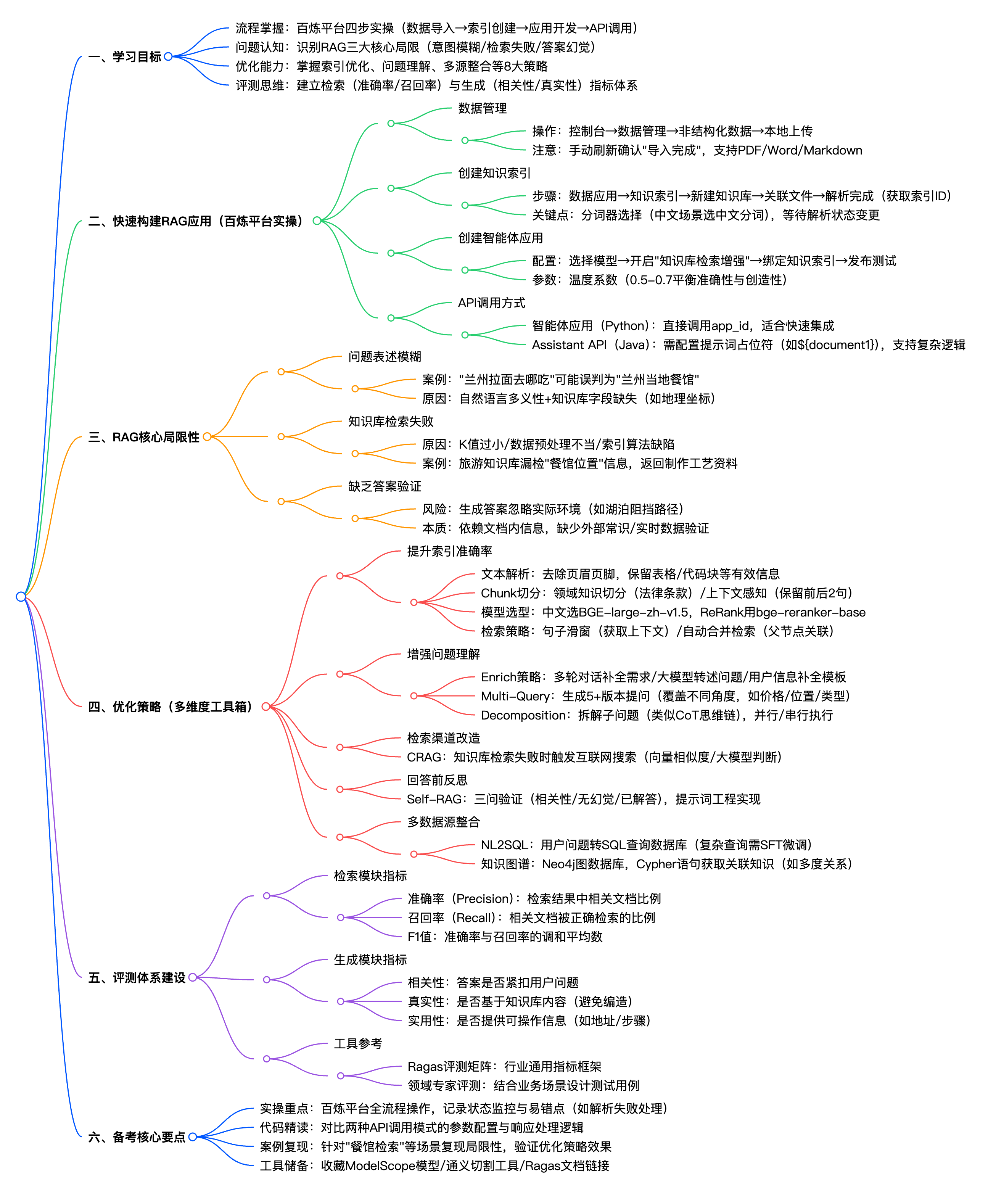
1. 快速构建RAG应用:百炼平台实操四步法(含API调用深度解析)
1.1 数据管理:非结构化数据导入的「三要素」
- 操作路径:百炼控制台→数据管理→非结构化数据→默认类目→导入数据(支持本地上传/OSS文件)
- 关键细节:
- 数据状态监控:需手动刷新页面直至状态显示「导入完成」,大文件(>100MB)解析时间可能长达10分钟以上。
- 格式支持:优先上传PDF/Word/Markdown,纯文本文件需注意编码格式(建议UTF-8),避免解析乱码。
1.2 创建知识索引:从文件到可检索向量的转化过程
- 新建知识库:数据应用→知识索引→创建知识库→填写名称(如"电商产品手册")→默认配置(分词器选「中文分词」)
- 文件关联:勾选已导入的文档(支持多选),注意文件大小限制(单文件建议<50MB)
- 解析等待:系统自动完成「文本提取→分句→生成Embedding向量」,解析完成后在「知识库索引主页」获取知识索引ID(格式为"kg-xxx",后续Assistant API调用必需)
1.3 创建应用:智能体应用的参数配置指南
- 核心开关:开启「知识库检索增强」后,需绑定步骤1.2创建的知识索引,实现大模型与知识库的联动
- 模型参数:温度系数(Temperature)建议初始设为0.7(平衡创造性与准确性),高频问答场景可降至0.5
- 发布测试:发布后在右侧对话框输入「百炼的业务空间是什么?」验证检索效果,观察是否返回知识库内容
1.4 API调用:两种模式的核心区别与代码解析
▶ 模式一:智能体应用调用(Python示例,适合快速集成)
import os
from dashscope import Application
from http import HTTPStatusdef call_agent_app():# 核心参数:app_id为步骤1.3生成的应用ID,需替换占位符response = Application.call(app_id=