AI Engine Kernel and Graph Programming--知识分享6
输入输出缓冲器
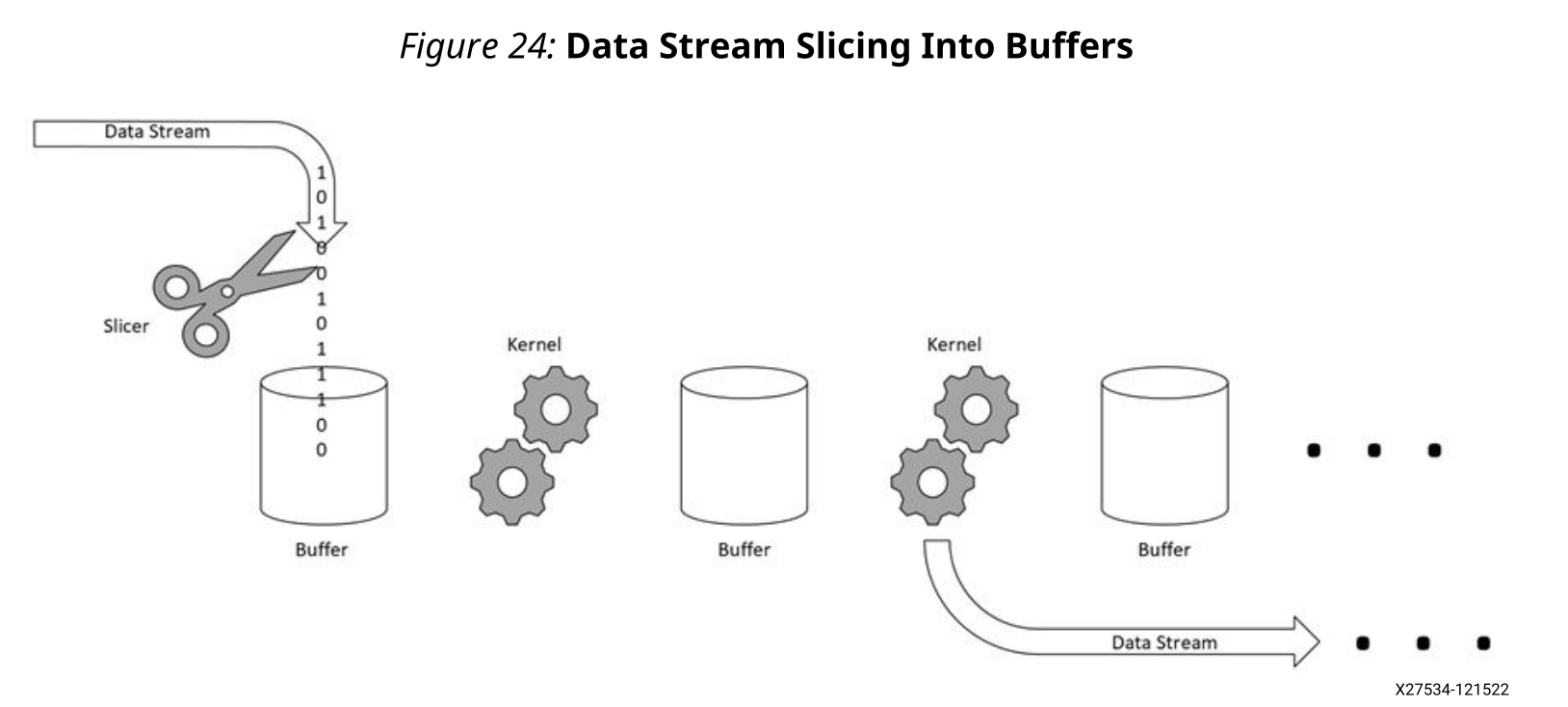
输入和输出缓冲区表示连续存储在图块的物理存储器上的数据块,并且可以由图中的内核使用。这些数据的来源可以是产生它们的其他内核,也可以是通过AI Engine数组接口来自PL。缓冲器端口可以被分配在内核执行的区块的物理存储器中,或者在可访问的相邻区块的物理存储器中。当内核在其输入端有一个缓冲区端口时,它会等待缓冲区完全可用,然后才开始执行。内核可以随机或以线性方式访问缓冲区端口的内容。相反,内核可以将一个数据块(帧)写入本地存储器,以便在完成执行后由其他内核使用。当缓冲区的源是流时,该流被切片成连续的块,这些块被一个接一个地存储到缓冲区中,如下所示。
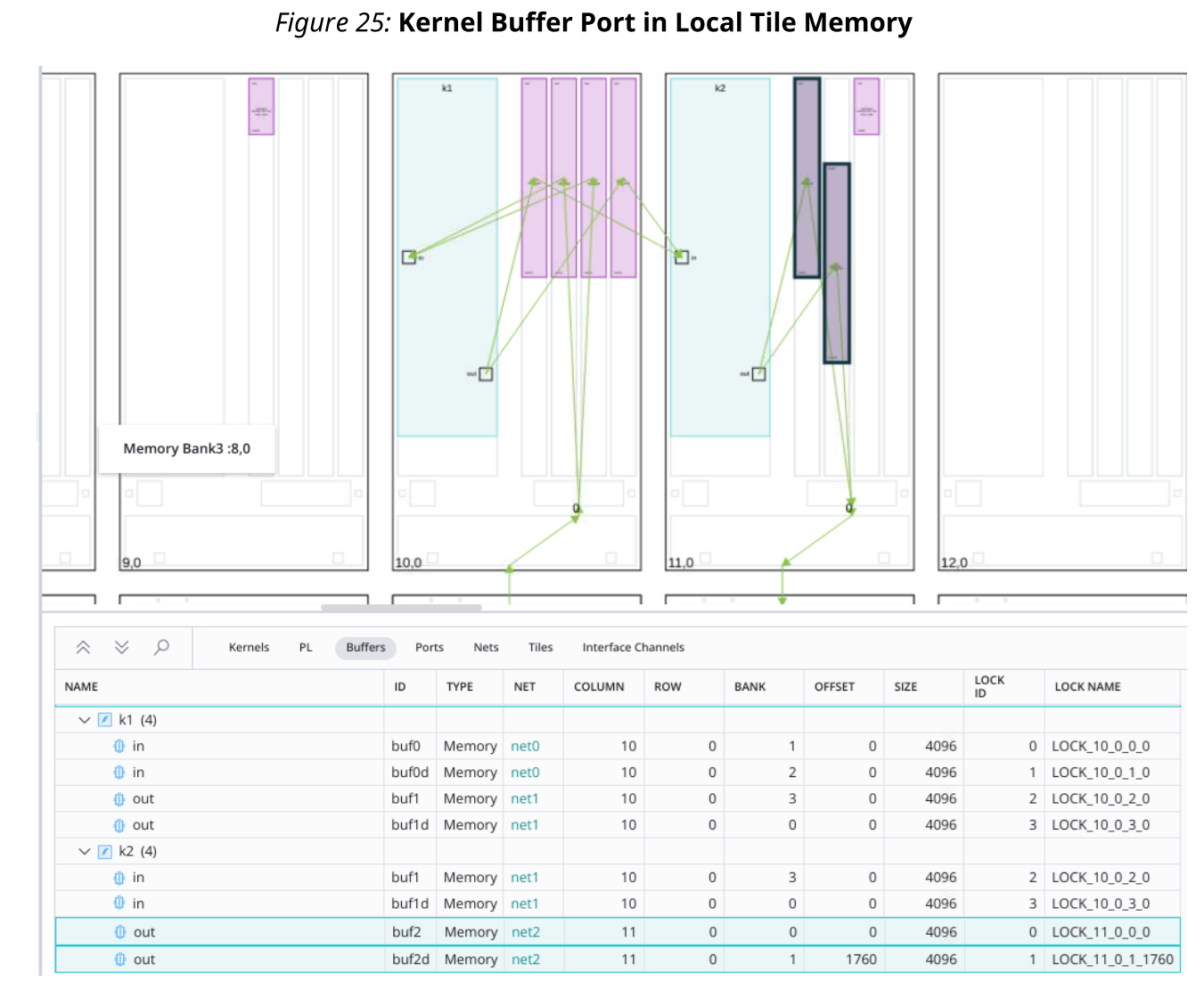
 下图显示了驻留在本地tile内存中的内核缓冲区端口的示例。内核k1在tile(10,0)中,并且输入缓冲器端口被分配在同一tile(10,0)的本地存储器中。
下图显示了驻留在本地tile内存中的内核缓冲区端口的示例。内核k1在tile(10,0)中,并且输入缓冲器端口被分配在同一tile(10,0)的本地存储器中。
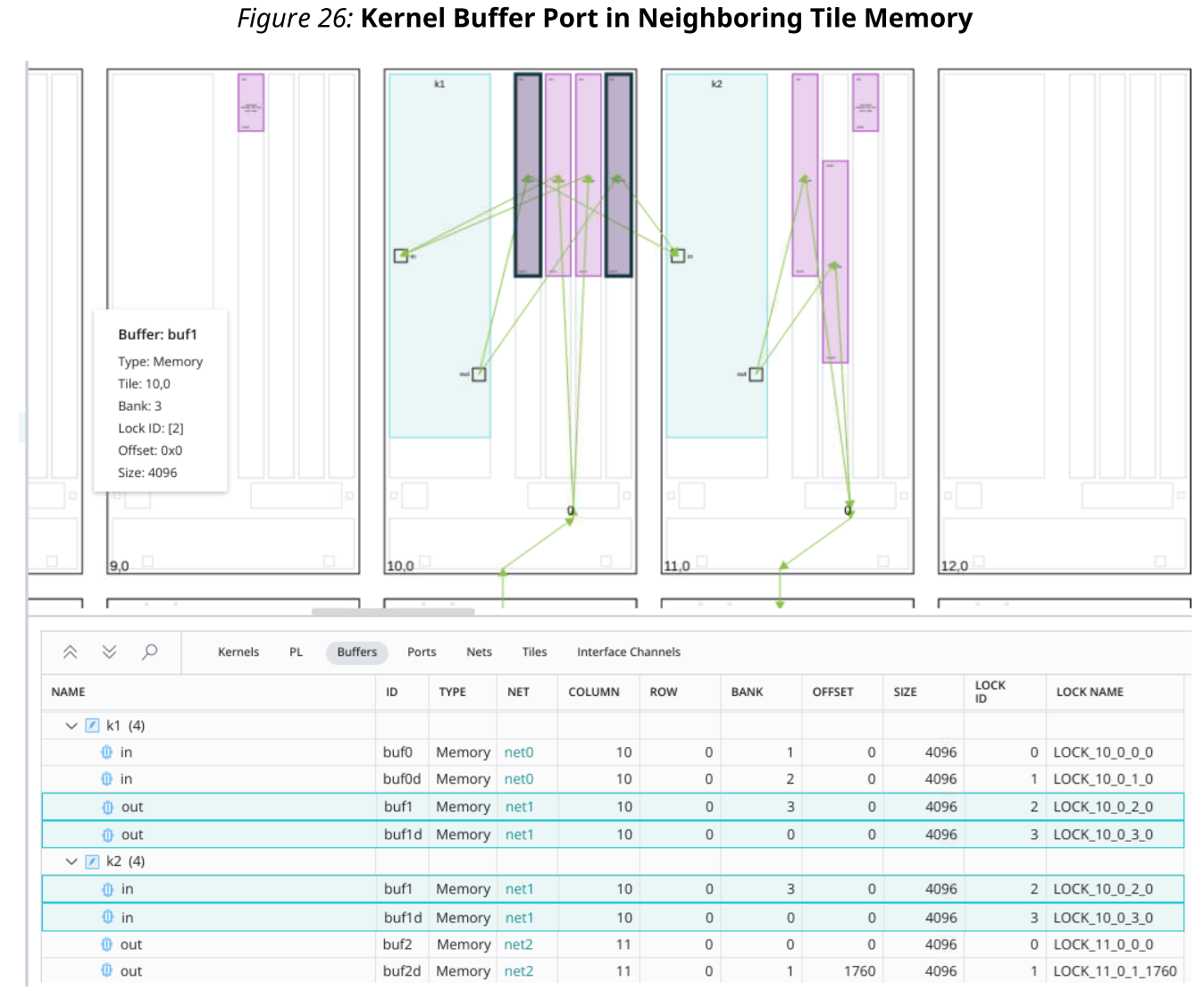
下图显示了在相邻切片内存中分配的内核缓冲区端口的示例。kernel k2在tile(11,0)中,并且输入缓冲器端口在相邻tile(10,0)处。注意:工具可以根据用户指定的设计约束自动放置缓冲区。单个缓冲区端口(包括Ping和Pong缓冲区)必须放置在单个tile中。对于AI Engine设备,单个缓冲区端口不大于32 KB。
基于缓冲区端口的访问
缓冲区端口为内核提供了一种对数据块进行操作的方法。缓冲器端口在单个方向上操作(例如,输入或输出)。内核具有的传入数据块的视图称为输入缓冲区。输入缓冲区由类型定义。在内核对其进行操作之前,需要声明缓冲区中包含的数据类型。
内核拥有的输出数据块的视图称为输出缓冲区。它们是由一个类型定义的。下面的示例显示了一个名为simple的内核的声明。简单内核有一个名为in的输入缓冲区,其中包含复数整数,其中真实的和虚部都是16位宽的有符号整数。简单内核还有一个名为out的输出缓冲区,其中包含32位宽的有符号整数。
void simple(input_buffer<cint16> & in,output_buffer<int32> &out);下面的示例显示了使用adf::extents模板参数声明输入和输出缓冲区端口大小。
void simple(input_buffer<cint16, adf::extents<INPUT_SAMPLE_SIZE>> & in,output_buffer<int32, adf::extents<OUTPUT_SAMPLE_SIZE>> & out);这些缓冲区数据结构由AI引擎编译器从数据流图连接中推断出来,并在实现图控件的包装器代码中声明。内核函数只对作为参数传递给它们的指向缓冲区数据结构的指针进行操作。不需要在数据流图或内核程序中声明这些缓冲区数据结构。
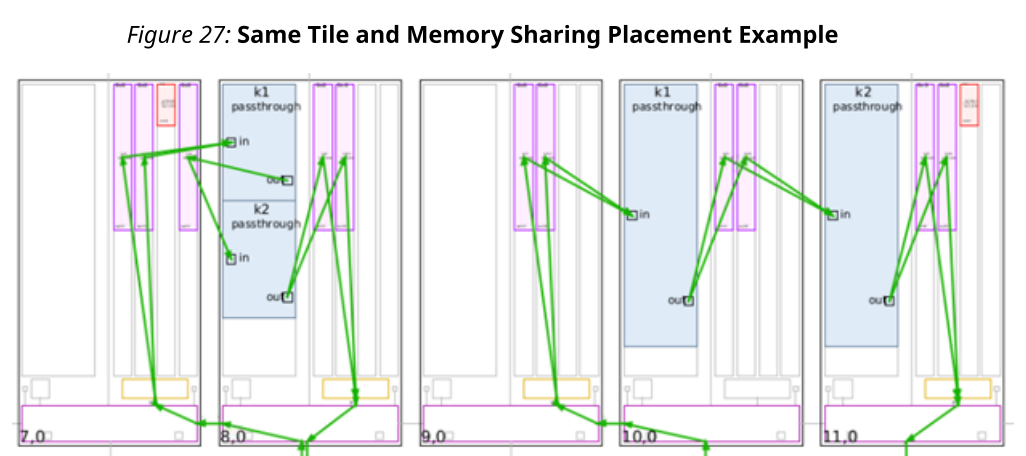
当两个内核(k1,k2)通过缓冲器(k1的输出缓冲器连接到k2的输入缓冲器)进行通信时,编译器尝试将它们放置到可以共享至少一个AI引擎内存模块的瓦片中。
·如果两个内核位于同一个瓦片上,编译器使用单个内存区域进行通信,因为它们不是同时执行的(参见下图中瓦片(8,0)中的k1和k2以及(7,0)中的单个共享内存块)。由于AI引擎中多个内核的执行是顺序的,因此在使用相同的内存区域时可以避免访问冲突。
·如果两个内核被放置在共享AI引擎内存模块的不同tile中,编译器将推断出乒乓缓冲区,允许两个内核同时写入和读取,但不写入相同的内存区域(参见下图中tile(10,0)中的k1,tile(11,0)中的k2以及(10,0)中实现为乒乓缓冲区的共享缓冲区)。
·如果您的系统性能可以处理它,那么您可以通过对内核端口应用single_buffer()约束,将乒乓缓冲区切换为单缓冲区<port>。
·如果两个内核被放置在遥远的瓦片中,编译器将自动推断出在k1的输出处有一个乒乓缓冲区,在输入k2处有另一个乒乓缓冲区。这两个乒乓球与DMA连接,DMA将使用数据流自动将k1的输出缓冲器的内容复制到k2的输入缓冲器上。
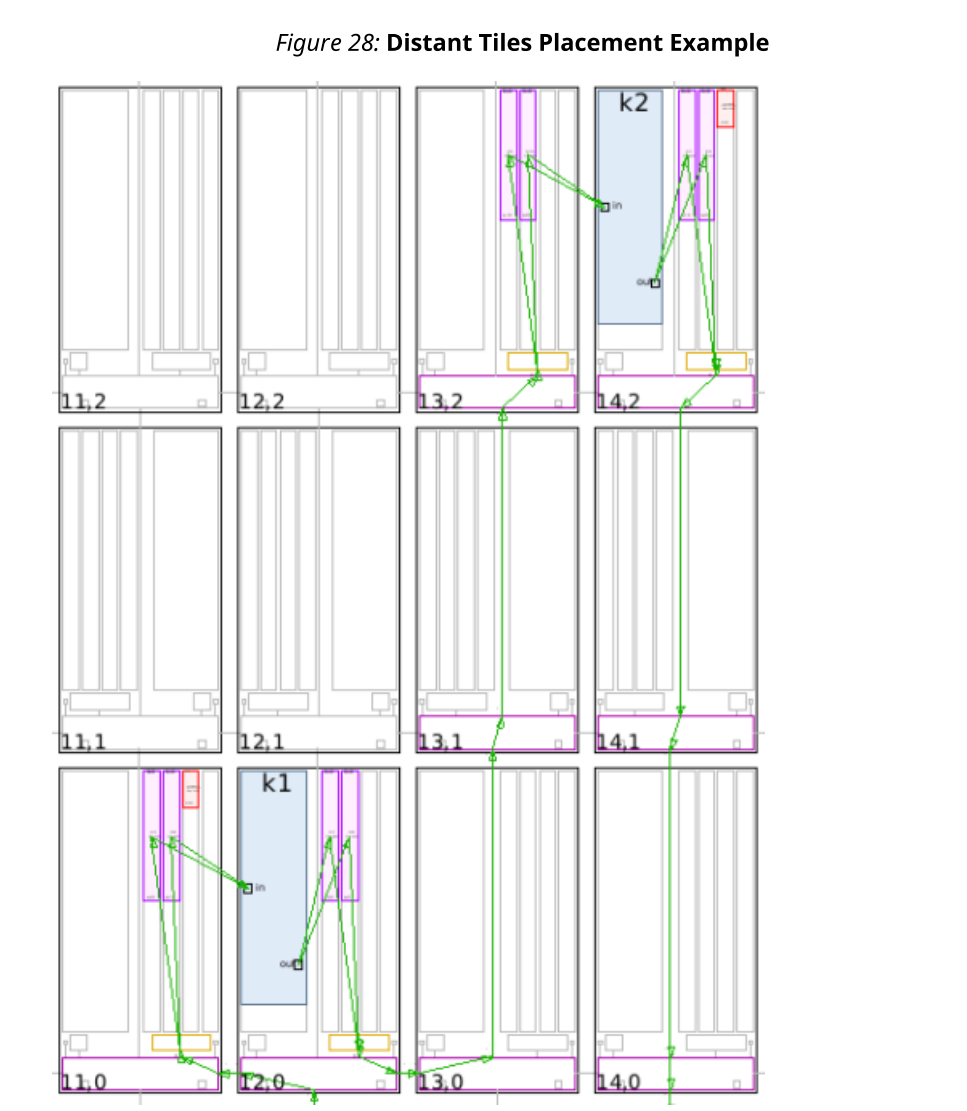
·当多个缓冲区/流汇聚到内核上时,各个路径可能具有非常不同的延迟,这可能潜在地导致死锁。为了避免这种问题,可以在两个内核之间插入FIFO。编译器将生成与远程瓦片情况相同类型的架构,除了在流连接的中间插入FIFO。
缓冲区端口属性和API
可以配置的缓冲区端口属性包括缓冲区端口的大小、余量、锁定协议(同步或异步)、寻址模式(线性或循环)以及单缓冲区与乒乓缓冲区。在这些属性中,margin、锁定协议和寻址模式在内核函数签名中指定。在图中指定了单一缓冲器的乒乓缓冲区。
缓冲区端口的大小可以在内核签名或图形构造函数中指定。如果内核函数签名没有指定大小,或者指定为adf::inherited_extent,则必须使用dimensions()API在图形中指定大小。dimensions()API用于图的构造器中,并根据样本数量配置缓冲器端口大小。adf::inherited_extent,表示将从上下文推断的缓冲区大小,例如,它是从图中的规范推断的。
缓冲器端口余量表示从一个块的末尾到下一个块的开头复制的样本数。如果指定了边距参数,则分配的总内存为样本大小和边距大小之和乘以模板数据类型(以字节数表示)((样本大小+边距大小)* sizeof(数据类型))。在循环输出缓冲区的情况下,可以将余量指定为adf::inherited_margin。在这种情况下,余量大小将由连接到此输出端口的接收器指定。
指定边距大小的示例函数原型如下:
simple(input_buffer<int32, adf::extents<adf::inherited_extent>,adf::margin<MARGIN_SIZE>> & in0,output_buffer<int32> & out0);注:
·缓冲区端口类型定义了它们的尺寸和数据样本数量的余量。要确定存储在物理内存中的实际数据大小,您需要将样本总数乘以支持的数据类型(以字节为单位)。
·缓冲区大小和边距大小必须是16字节的倍数。
·与I/O缓冲区相关的构造在adf命名空间中定义。因此,这些构造需要用adf::限定,除非您使用名称空间adf。
数据存取机制
同步缓冲区端口访问
内核从其输入缓冲区读取数据并向其输出缓冲区写入数据。默认情况下,等待数据输入缓冲区所需的同步在进入内核之前执行。提供空输出缓冲区所需的同步也在进入内核之前执行。在内核开始执行之后,内核中的同步缓冲区端口不需要同步来读取或写入各个数据样本。
缓冲区端口大小可以通过dimensions()API或内核函数原型声明。
·option1:在图形中使用dimensions()API进行配置。
connect netN(in.out[0], k.in[0]);
dimensions(k.in[0])={INPUT_SAMPLE_SIZE};·option2:使用内核函数原型进行配置,其中函数原型在内核头文件中声明,并在图形代码中引用。
connect netN(in.out[0], k.in[0]);内核代码指定数据类型和缓冲区大小。
void simple(input_buffer<int32, adf::extents<INPUT_SAMPLE_SIZE>> & in,output_buffer<int32, adf::extents<OUTPUT_SAMPLE_SIZE>> & out);在以下示例中,位于瓦片1中的内核使用乒乓缓冲区进行写入,而位于瓦片2(与瓦片1相邻)中的内核使用相同的乒乓缓冲区进行阅读。两个内核和两个主函数的执行时间不同,导致运行时的处理器停顿。总体机制是内核1写入ping缓冲区,而内核2从pong缓冲区读取。在下图中,迭代内核1写入pong缓冲区,内核2从ping缓冲区读取。
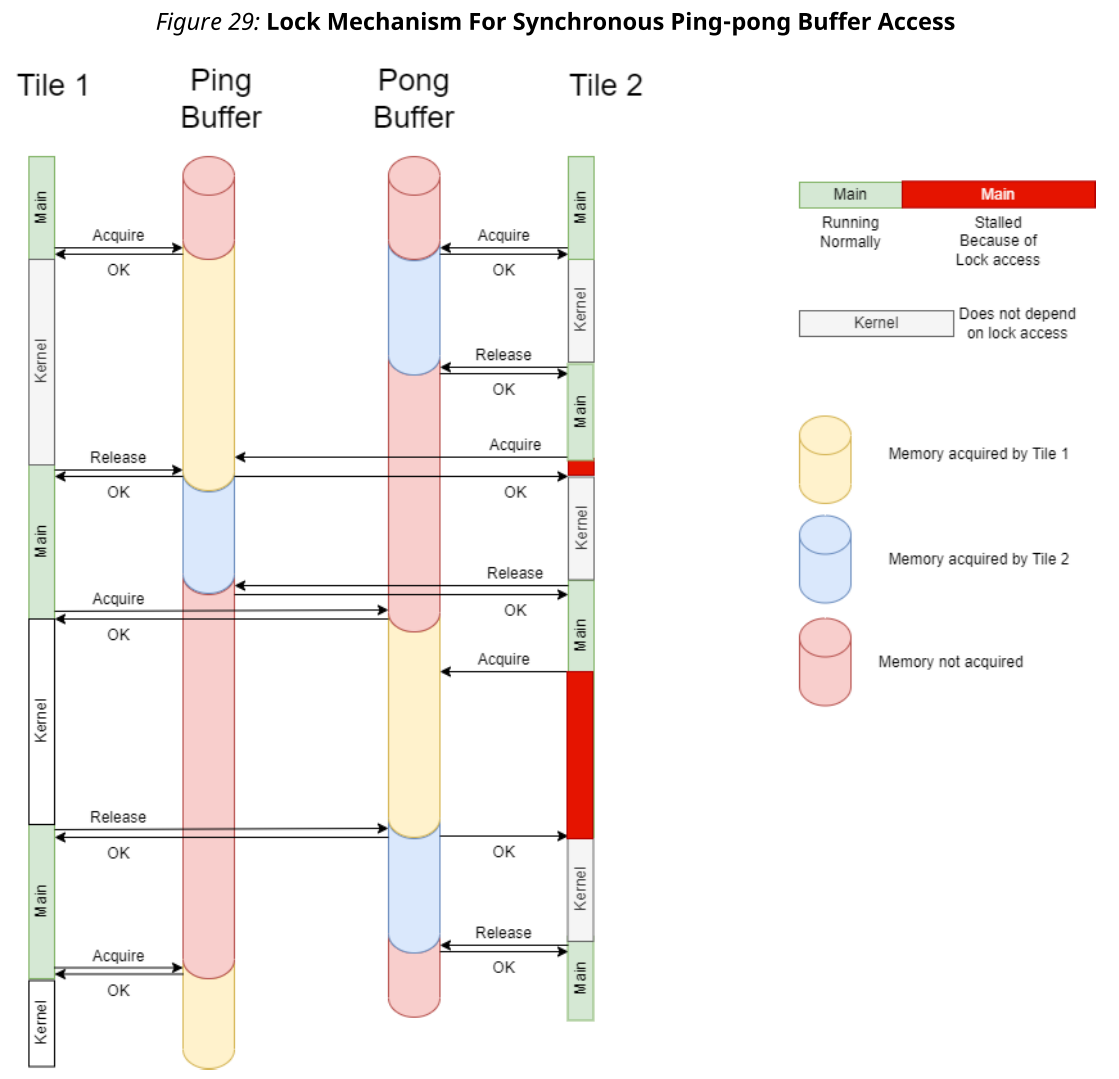
内核的缓冲区锁定机制在tiles main函数中处理。只有当所有的输入和输出缓冲区都被分别锁定用于阅读和写时,内核才启动。如果缓冲区准备好被获取,则锁定获取的最小延迟为七个时钟周期。如果它已经被另一个内核锁定,它将暂停,直到它变得可用(在图中以红色表示)。
从图中可以看到,锁定获取交替发生在ping缓冲区和pong缓冲区中。ping或pong缓冲区的选择是自动的,此时不需要用户决定。
当使用同步缓冲区端口时,内核的输出缓冲区上的锁在内核执行完成后被释放。然后,该缓冲区可以由其消费者内核获取,也可以由DMA传输到其目的地(目的地例如PLIO)。重要的是要注意,同步输出缓冲区将在内核的每次迭代期间获取和释放,而不管内核写入缓冲区的样本数量。
带余量配置的同步缓冲器端口
·option1:在图形中使用dimensions()API进行配置。
k = kernel::create(simple);
connect netN(in.out[0], k.in[0]);
dimensions(k.in[0]) = {INPUT_SAMPLE_SIZE};
dimensions(k.out[0]) = {OUTPUT_SAMPLE_SIZE};内核k的函数原型指定了边距大小。
注意:不能在图形中指定边距。必须在内核签名中的缓冲区模板参数内设置边距。
simple(input_buffer<int32, adf::extents<adf::inherited_extent>,adf::margin<MARGIN_SIZE>> & in0,output_buffer<int32> & out0);·option2:使用内核函数原型进行配置。
k = kernel::create(simple);
connect netN(in.out[0], k.in[0]);Kernel k的函数原型指定输入缓冲区大小加上边距大小和输出缓冲区大小。
simple(input_buffer<int32, adf::extents<INPUT_SAMPLE_SIZE>,
adf::margin<MARGIN_SIZE>> & in0,output_buffer<int32, adf::extents<OUTPUT_SAMPLE_SIZE>> & out0);缓冲器端口被设计为顺序访问。内核程序读取缓冲区端口,并从样本的第一个位置开始。因此,一个有用的模型是当前位置的模型,它可以在读或写时前进或回退。在启动内核时,当前位置始终处于正确的位置。例如,滤波器的输入缓冲器端口的当前位置在第一个样本上以恢复延迟线。在滤波器需要输入数据样本的重叠的情况下,它可以是较旧的样本,在这种情况下,需要使用如上所述的重叠或余量来声明连接。类似地,输出缓冲器的当前位置位于要发送到下一个块的第一个样本上,而不管该块是否需要复制较早的样本。内核可以自由地操作该当前位置,并且当内核完成时,该位置不必位于块的末尾。将缓冲器端口实现为线性缓冲器。还支持循环缓冲区端口类型。有关详细信息,请参阅缓冲区端口的线性和循环寻址。
缓冲端口组播
AI引擎编译器不将缓冲区端口限制为一对一连接。在某些情况下,相同的输出缓冲区可以被其他内核用来执行各种任务。您可以根据需要将生产者连接到尽可能多的消费者。AI引擎编译器将自动推断MM2S DMA以读取输出缓冲区,并且有尽可能多的S2MM DMA写入其各自的输入缓冲区。
private:
adf::kernel mk;
adf::kernel tk0,tk1,tk2,tk3;
...
connect net0 ( mk.out[0] , tk0.in[0] );
connect net1 ( mk.out[0] , tk1.in[0] );
connect net2 ( mk.out[0] , tk2.in[0] );
connect net3 ( mk.out[0] , tk3.in[0] );
...
dimensions(tk0.in[0]) = {128};
dimensions(tk1.in[0]) = {128};
dimensions(tk2.in[0]) = {128};
dimensions(tk3.in[0]) = {128};内核函数原型
tk0(input_buffer<int32, adf::extents<adf::inherited_extent>> & in0,output_buffer<int32, adf::extents<OUTPUT_SAMPLE_SIZE>> & out0);
tk1(input_buffer<int32, adf::extents<adf::inherited_extent>,adf::margin<32>> & in0,output_buffer<int32, adf::extents<OUTPUT_SAMPLE_SIZE>> & out0);
tk2(input_buffer<int32, adf::extents<adf::inherited_extent>,adf::margin<64>> & in0,output_buffer<int32, adf::extents<OUTPUT_SAMPLE_SIZE>> & out0);
tk3(input_buffer<int32, adf::extents<adf::inherited_extent>> & in0,output_buffer<int32, adf::extents<OUTPUT_SAMPLE_SIZE>> & out0);内核tk0、tk1、tk2和tk3的输入缓冲器同时被服务。这是因为内核缓存器的输出缓冲区只被读取一次。轻微的延迟变化只是由于AI引擎阵列中从制造者到各种接受者所采取的不同AXI4流路径。
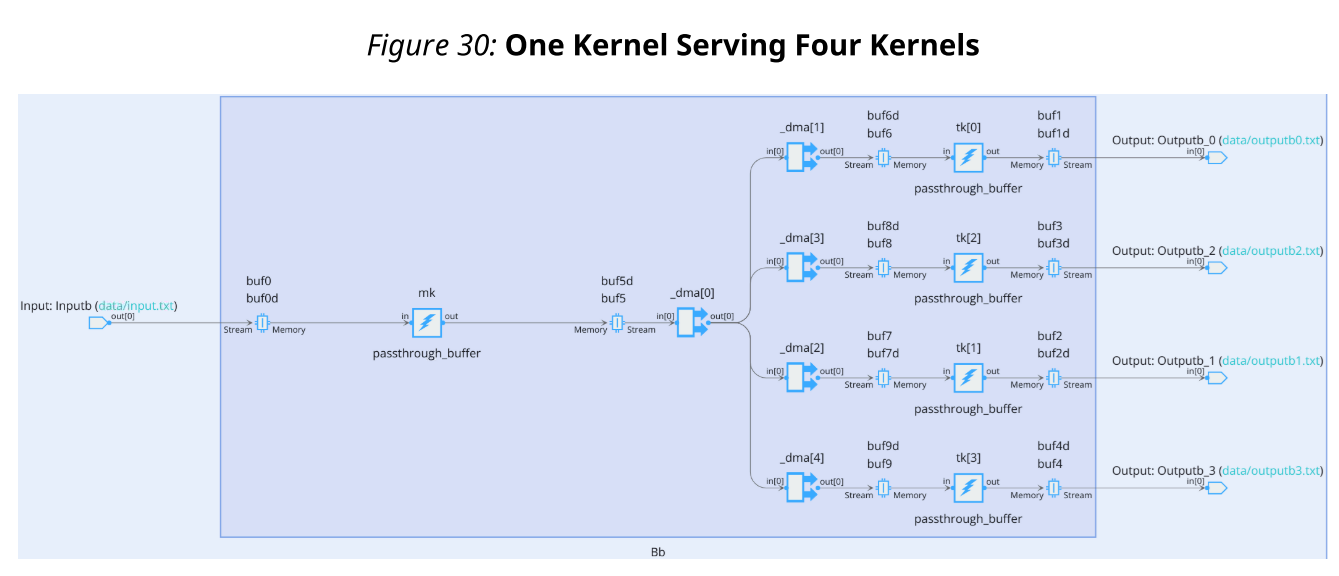
在代码中,同一个内核输出连接到四个不同的内核输入。AI引擎编译器在内核之间添加DMA,以便buf 5(d)缓冲区的内容可以使用AXI 4-Stream互连网络复制到其他缓冲区。
用于多速率处理的缓冲器端口连接
在某些设计中,内核的输出缓冲器端口的大小可以不同于下一个内核的输入缓冲器端口的大小。在这种情况下,连接声明将包含输出端口的大小和输入缓冲区端口的大小。举例来说:
connect net0 (kernel0.out[0], kernel1.in[0]);
dimensions(kernel0.out[0]) = {128};
dimensions(kernel1.in[0]) = {192};在上面的示例中,内核0写入128个样本,内核1期望将192个样本写入内存。在这种情况下,AI引擎编译器执行多速率分析。在这种情况下,编译器将指定kernel1应该运行两次,而kernel0将运行三次。您可以手动指定图形中这些内核的重复计数,如下所示:
repetition_count(kernel0) = 3;
repetition_count(kernel1) = 2;正如您可以将输出缓冲区端口多播到图中的多个输入缓冲区端口(自动DMA插入机制)一样,您也可以在此特定用例中执行多速率处理:
connect net0 ( kernel0.out[0] , kernel1.in[0] );
connect net1 ( kernel0.out[0] , kernel2.in[0] );
dimensions(kernel0.out[0]) = {128};
dimensions(kernel1.in[0]) = {64};
dimensions(kernel2.in[0]) = {192};在本例中,AI Engine编译器自动检测到kernel 0应运行三次,kernel 1应运行六次,kernel 2应运行两次,以获得一个图形迭代,graph.run(1)。也可以在图形中手动指定这些重复计数。
以下是一个图形示例,其中有理上变频器(7/5)后跟单速率内核。两者的输入帧长度都是350,但是上变频器的输出帧长度是490。
connect ( datain , upconv.in[0] );
connect ( upconv.out[0] , singlerate.in[0] );
connect ( singlerate.out[0] , dataout );
// If the connection is buffer based dimensions can be specified
// in the graph
dimensions(upconv.in[0]) = {350};
dimensions(upconv.out[0]) = {490};
dimensions(singlerate.in[0]) = {350};
dimensions(singlerate.out[0]) = {350};
// If the connections are stream based, repetitions count must be specified
repetition_count(upconv) = 5;
// LCM(350,490)/490 = 5
repetition_count(singlerate) = 7; // LCM(350,490)/350 = 7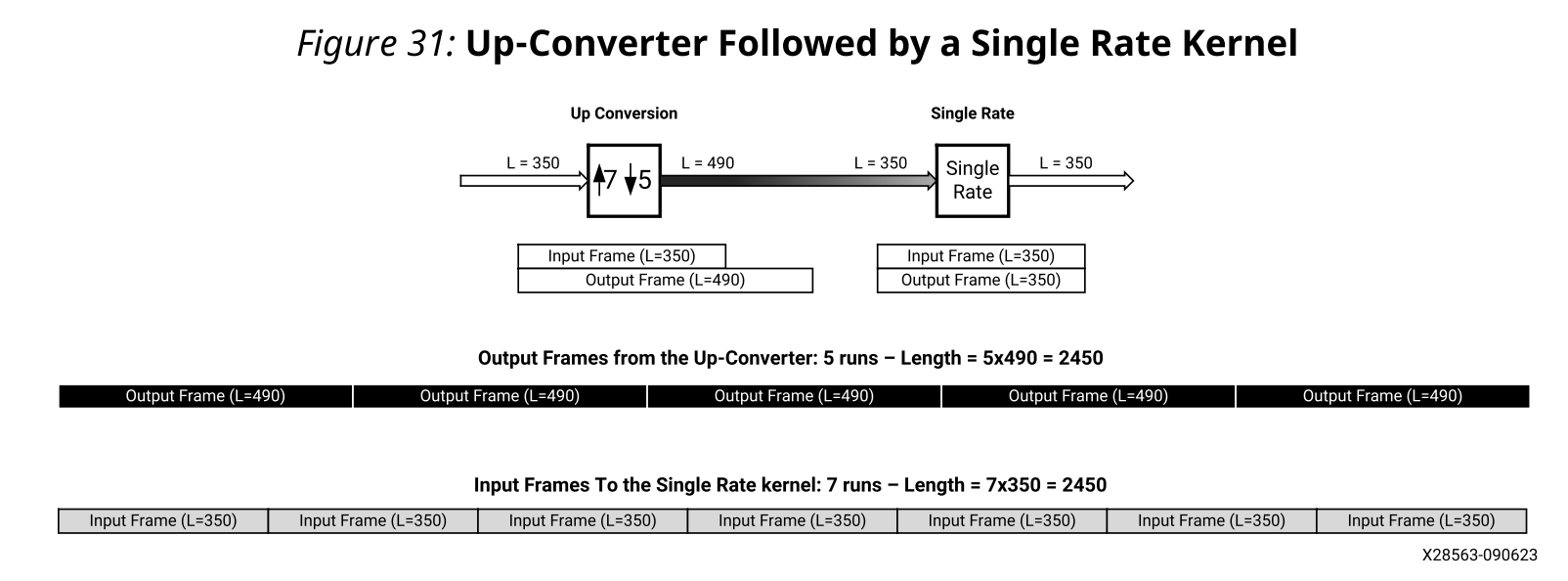
在上图中,上转换内核必须运行五次,单速率内核必须运行七次,才能在两个内核之间产生和消耗相同数量的样本。
在该示例中,上变频器的输出帧长度大于单速率内核的输入帧的长度。这意味着上变频器将在单次迭代中重写ping和pong缓冲器(或其他更复杂的方案)。
精彩文章,请关注订阅号:威视锐科技