RAG 和 Fine-Tuning
为什么需要RAG和Fine-Tuning
RAG(Retrieval-Augmented Generation)和Fine-Tuning是两种用于提高自然语言处理模型性能(准确性)的方法,单纯的LLM存在下面两个问题,
- 一旦LLM训练好模型后其知识库就静态和固化了,时间久了就缺乏新的知识输入
- 一个模型可能无法学到企业和组织内部的私有数据或专有领域的数据,知识面有限
RAG和Fine-Tuning在一定程度上能解决上面的问题,让LLM的回答能尽可能的准确。
什么是RAG
RAG(Retrieval Augmented Generation,RAG)是一种模型架构,通过将外部知识整合到生成过程中,来提高大语言模型(LLM)生成回答的准确性。该架构巧妙地整合了从庞大知识库中检索到的相关信息,并以此为基础,指导大型语言模型生成更为精准的答案,从而显著提升了回答的准确性与深度。
RAG本质上是通过工程化手段,解决LLM知识更新困难的问题。其核心手段是利用外挂于LLM的知识数据库(通常使用向量数据库)存储未在训练数据集中出现的新数据、领域数据等。通常而言,RAG将知识问答分成三个阶段:索引、知识检索和基于检索内容的问答。
企业中使用RAG的主要目的是增强大模型,为大模型提供能力提升,目前主要是以下几方面:
a) 减少大模型在回答问题时的幻觉问题
b) 让大模型的回答可以附带相关的来源和参考
c) 消除使用元数据注释文档的需要
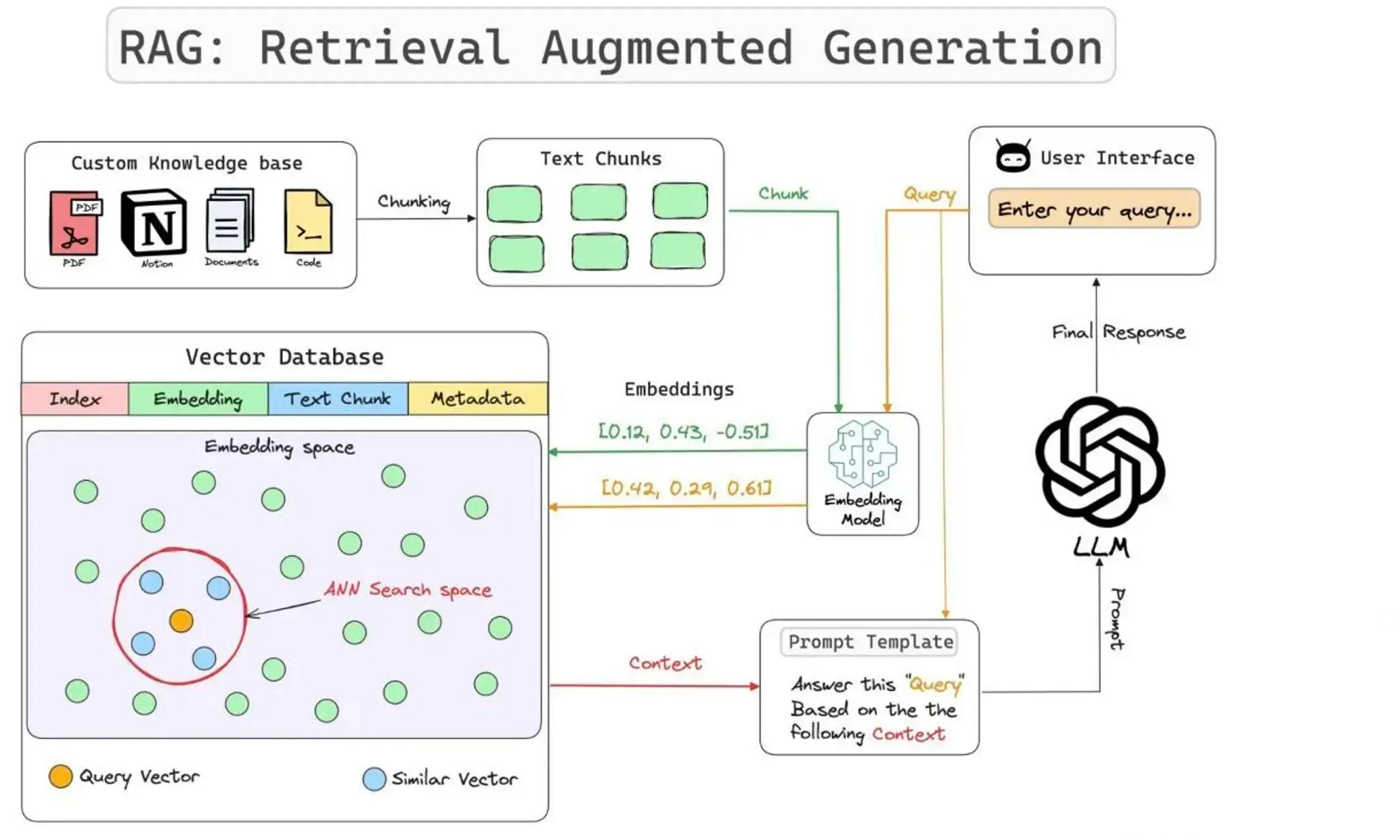
RAG的关键组成部分
第一、自定义知识库(Custom Knowledge)
定制知识库是指一系列紧密关联且始终保持更新的知识集合,它构成了 RAG 的核心基础。这个知识库可以表现为一个结构化的数据库形态(比如:MySQL),也可以表现为一套非结构化的文档体系(比如:文件、图图片、音频、视频等),甚至可能是两者兼具的综合形式。
第二、分块处理(Chunking)
分块技术是指将大规模的输入文本有策略地拆解为若干个较小、更易管理的片段(Chunk)的过程。这一过程旨在确保所有文本内容均能适应嵌入模型所限定的输入尺寸,同时也有助于显著提升检索效率。一般可以按照文本段落,小节等分块,能保证每个段落在语义上是完整的。
第三、嵌入模型(Embedding Model)
一种将多模态数据(文本、图片、音频等)表示为数值向量的技术,不同类型的数据一般对应不同的embedding算法。
第四、向量数据库( Vector Databases)
用于存储embedding后的向量的数据库,用于快速检索和相似性搜索,具有SQL CRUD 操作、元数据过滤和水平扩展等功能。
第五、用户聊天界面(User Chat Interface)
一个用户友好的界面,允许用户与 RAG 系统互动,提供输入查询并接收输出。查询转换为嵌入向量,用于从向量数据库检索相关上下文知识。
第六、查询引擎(Query Engine)
查询引擎是负责从外部数据源或知识库中检索相关信息的组件。它在生成过程中为语言模型提供上下文和知识支持。查询引擎通常连接到一个或多个数据源,这些数据源可以是向量数据库、全文搜索引擎、知识图谱或其他类型的数据库。查询引擎从外部数据源获取到充分数据以后,将这些数据和原始的问题生成为Prompt模板,然后交给LLM。
第七、提示词模板(Prompt Template)
为 RAG 系统生成合适提示词的过程,可以是用户查询和自定义知识库的组合。提示词可以包含指令(让LLM做什么事情),上下文(做某件事情的上下文背景),输入数据(LLM需要处理的输入数据),输出指示(期望输出的内容的格式)。准确的,没有歧义的提示词,能够让LLM充分理解问题的本身,避免回答错误。
什么是Fine-Tuning
Fine-Tuning(微调)的目的是通过在特定任务或领域的数据上进一步训练预训练模型,以提高其在该任务或领域上的表现。Fine-Tuning通常涉及在预训练模型的基础上,使用特定任务的数据进行额外的训练,以使模型更好地适应该任务的特定需求。需要再次训练数据,有一定的训练资源开销。
RAG vs. Fine-Tuning
1. 目的和方法
- RAG:
- 目的:结合检索和生成能力,以提高模型在处理复杂查询时的准确性和信息丰富度。
- 方法:通过检索相关信息并将其与生成模型结合,生成更准确和信息丰富的回答。
- Fine-Tuning:
- 目的:通过在特定任务或领域的数据上进一步训练预训练模型,以提高其在该任务或领域上的表现。
- 方法:使用特定任务的数据对预训练模型进行额外训练,使其更好地适应该任务的特定需求。
2. 信息来源
- RAG:
- 依赖外部知识库或文档库,能够动态地利用最新的信息。
- 适合处理需要实时数据或外部知识的任务。
- Fine-Tuning:
- 依赖于训练数据集,模型的知识来源于训练数据。
- 适合处理特定领域或任务的固定知识。
3. 适用场景
- RAG:
- 适用于需要结合外部知识库的问答系统、对话系统等。
- 在长尾问题或需要背景信息的场景中表现优异。
- Fine-Tuning:
- 适用于分类、翻译、情感分析等需要高精度的任务。
- 在特定领域或任务中表现优异。
4. 灵活性和适应性
- RAG:
- 更加灵活,能够适应动态变化的信息需求。
- 适合处理开放域问题。
- Fine-Tuning:
- 适应性较强,但主要针对特定任务或领域。
- 需要针对每个新任务进行单独的微调。
5. 实现复杂度
- RAG:
- 需要维护和更新外部知识库,复杂度较高。
- 需要设计检索机制和生成机制的结合。
- Fine-Tuning:
- 实现相对简单,只需在特定数据集上进行训练。
- 需要足够的标注数据来进行有效的微调。
RAG和Fine-Tuning各有优势,选择使用哪种方法取决于具体的应用需求。RAG适合需要动态信息和外部知识的场景,而Fine-Tuning适合需要高精度和特定领域适应性的场景。在某些情况下,可以结合使用两者,以获得更好的性能。