阿里发布扩散模型Wan VACE,全面支持生图、生视频、图像编辑,适配低显存~
项目背景详述
推出与目的

Wan2.1-VACE 于 2025 年 5 月 14 日发布,作为一个综合模型,旨在统一视频生成和编辑任务。其目标是解决视频处理中的关键挑战,即在时间和空间维度上保持一致性。该模型支持多种任务,包括参考到视频生成(R2V)、视频到视频编辑(V2V)和遮罩视频到视频编辑(MV2V),通过整合这些功能,简化用户工作流程,提供如 Move-Anything、Swap-Anything、Reference-Anything、Expand-Anything 和 Animate-Anything 等能力。
创新特点
-
多语言文本生成:Wan2.1-VACE 是首个能生成中英文文本的视频模型,这显著提升了其在实际应用中的实用性。
-
高效视频处理:模型利用 Wan-VAE(视频变分自编码器),能够高效编码和解码任意长度的 1080P 视频,同时保留时间信息,使其成为视频和图像生成的基础。
-
硬件兼容性:提供 1.3B 和 14B 两个版本,其中 1.3B 版本仅需约 8.19 GB VRAM,适合消费级 GPU,扩大了使用范围。
-
开源与社区支持:模型及其推理代码、权重和技术报告可在 GitHub、Hugging Face 和 ModelScope 上获取,促进了透明度和社区参与。
意义
Wan2.1-VACE 建立在其前身(如 Wan2.1-T2V-1.3B 和 ACE Plus)的基础上,通过整合多种任务到一个统一框架,简化了复杂视频编辑和生成任务。它代表了开源视频 AI 领域的重大进步,特别是在视频生成和编辑的多样化应用上。
模型结构详述
版本与分辨率
Wan2.1-VACE 提供两个版本:
-
1.3B 版本,适合 480P 分辨率(约 81x480x832)。
-
14B 版本,适合 720P 分辨率(约 81x720x1280)。
这些版本允许用户根据硬件能力和任务需求选择合适的模型。
核心架构
-
扩散变换器(DiT)与流量匹配框架:模型的核心基于扩散变换器,使用流量匹配框架,确保高效且高质量的视频生成。
-
T5 编码器:集成 T5 编码器,支持多语言文本处理,增强了模型处理中英文输入的能力。
-
交叉注意力机制:在变换器块中使用交叉注意力,高效整合文本、图像和视频输入。
独特组件
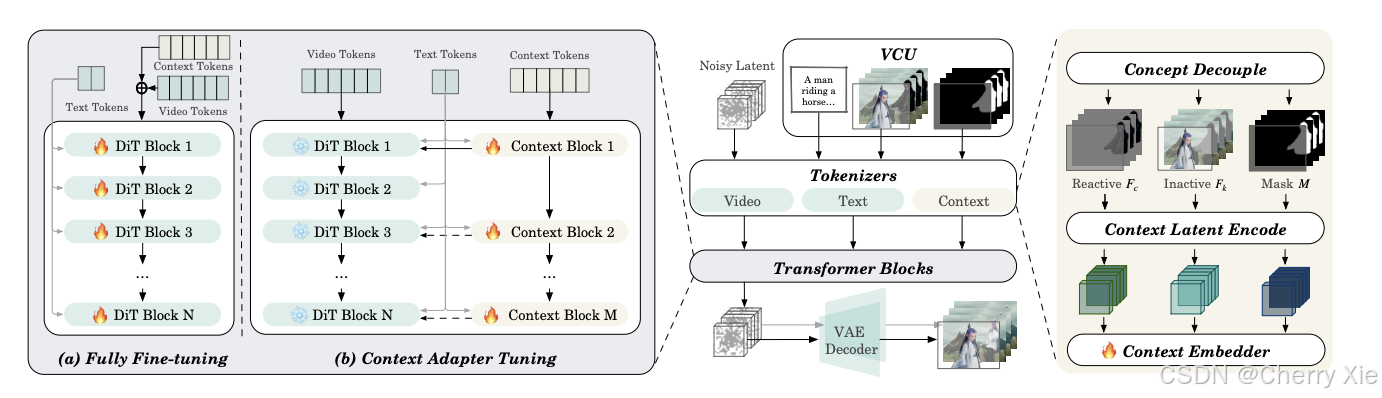
-
视频条件单元(VCU):这是 Wan2.1-VACE 的关键结构,统一整合各种视频任务输入(如编辑、参考、遮罩),使模型能够无缝处理多样化任务。
-
上下文适配器:通过形式化的时间和空间维度表示,注入任务概念,支持灵活处理任意视频合成任务。这增强了模型的适应性,适用于多种场景。
-
调制参数:使用多层感知机(MLP)计算六个调制参数,包含 Linear 和 SiLU 层。这些参数在变换器块间共享,但具有不同的偏差,允许精细控制生成过程。
任务支持
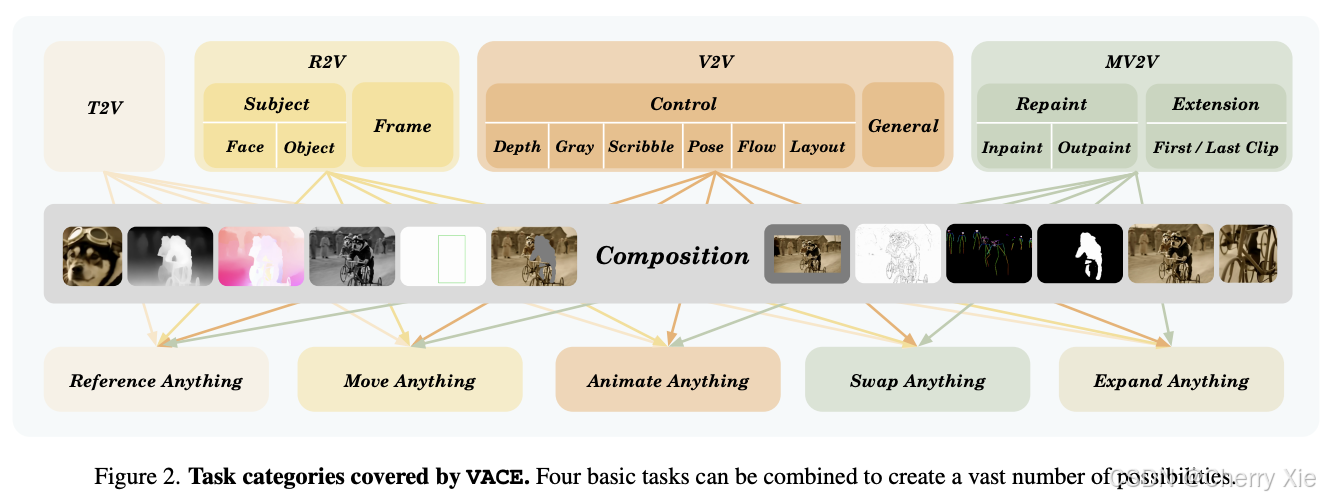
Wan2.1-VACE 支持广泛的任务,包括:
-
文本到视频(T2V):根据文本描述生成视频。
-
图像到视频(I2V):基于图像输入生成视频。
-
视频编辑(V2V):根据用户输入编辑现有视频。
-
文本到图像(T2I):根据文本提示生成图像。
-
视频到音频(V2A):基于视频生成音频。
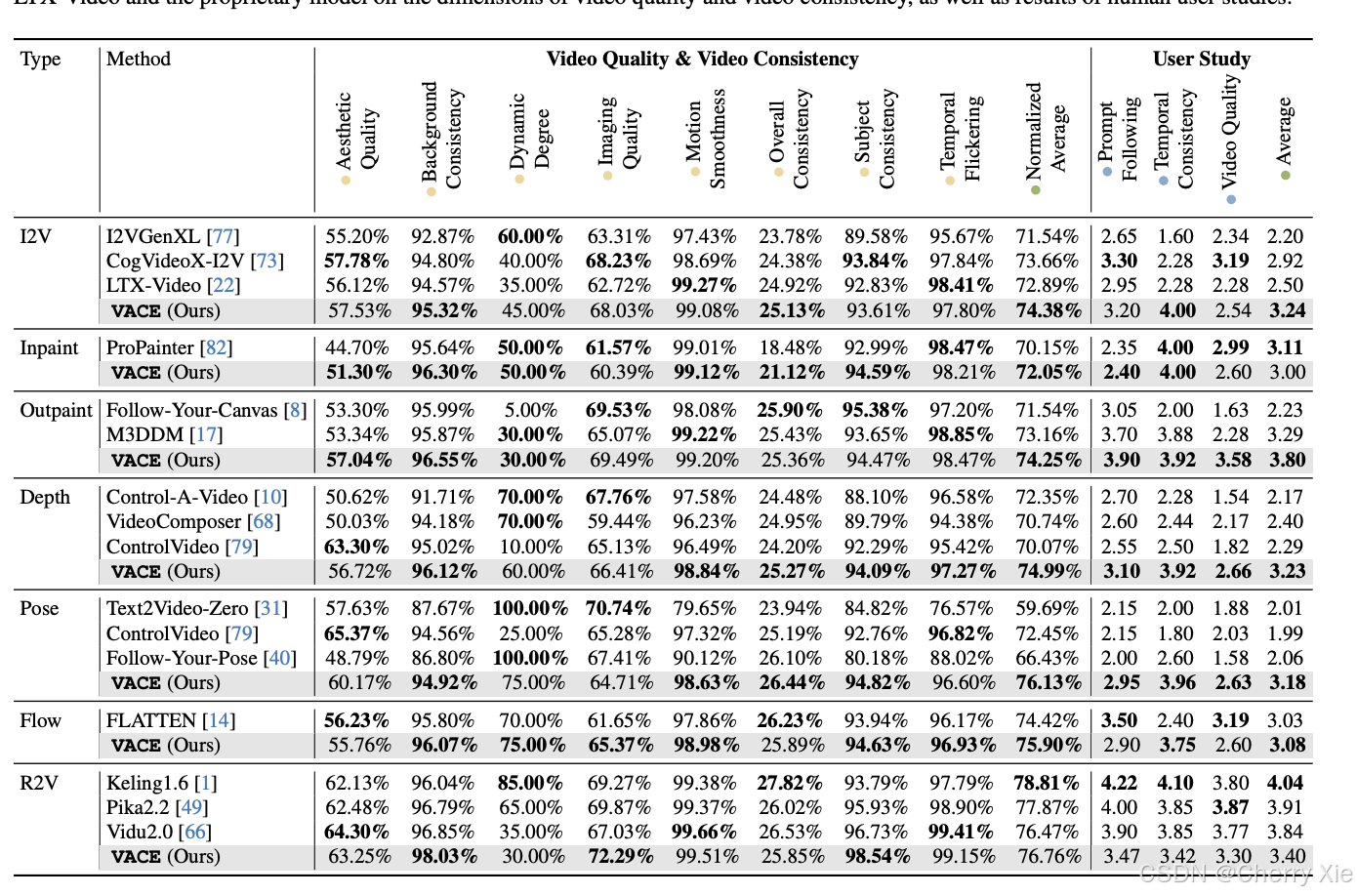

性能与效率
-
1.3B 版本优化为消费级 GPU,仅需约 8.19 GB VRAM,适合大多数用户。
-
14B 版本虽然资源需求更高,但支持更高分辨率和更复杂任务,适合专业场景。
看看效果
相关文献
github地址:https://github.com/ali-vilab/VACE
技术报告:https://arxiv.org/pdf/2503.07598
模型下载:https://github.com/Wan-Video/Wan2.1#model-download
官方地址:https://ali-vilab.github.io/VACE-Page/