OpenCv高阶(十六)——Fisherface人脸识别
文章目录
- 前言
- 一、Fisherface人脸识别原理
- 1. 核心思想:LDA与Fisher准则
- 2. 实现步骤
- (1) 数据预处理
- (2) 计算类内散布矩阵 SW对每个类别(每个人)计算均值向量 μi:
- (3) 计算类间散布矩阵 SB
- (4) 求解投影矩阵 W
- (5) 降维与分类
- 3. Fisherface vs. Eigenface
- 4. 优缺点
- 二、Fisherface人脸识别代码
- 1、导入依赖库
- 2、定义在OpenCV图像上添加中文文本的函数
- 3、定义图像预处理函数
- 4、主程序
- ---------- 数据准备阶段 ----------
- ---------- 模型训练阶段 ----------
- ------------ 预测阶段 ---------------
- ---------- 结果可视化 ----------
- 总结
前言
人脸识别作为计算机视觉领域的核心课题之一,在安全监控、身份认证、人机交互等领域具有广泛的应用前景。早期的经典方法如Eigenface(基于主成分分析,PCA)通过无监督降维提取人脸的主要特征,但其忽略了类别标签信息,对光照、表情等类内变化敏感,导致分类性能受限。为解决这一问题,Belhumeur等人于1997年提出了Fisherface方法,将线性判别分析(Linear Discriminant Analysis, LDA)引入人脸识别领域。该方法通过有监督学习,最大化不同人脸间的差异,同时压缩同一人脸在不同条件下的类内差异,从而显著提升了识别鲁棒性。
一、Fisherface人脸识别原理
Fisherface是一种基于线性判别分析(Linear Discriminant Analysis, LDA)的人脸识别方法,由Belhumeur等人在1997年提出。其核心思想是通过最大化类间差异(不同人脸之间的差异)并最小化类内差异(同一人脸在不同条件下的差异),找到最优的投影方向,从而实现高效的人脸分类。以下是其原理的详细解释:
1. 核心思想:LDA与Fisher准则
LDA目标:在降维过程中,找到一个投影矩阵,使得投影后的数据满足:
类间散布(Between-class scatter)最大化:不同类别(不同人)的数据尽可能分开。
类内散布(Within-class scatter)最小化:同一类别(同一人)的数据尽可能聚集。
Fisher准则:通过最大化类间散布与类内散布的比值,找到最优投影方向:

2. 实现步骤
(1) 数据预处理
将人脸图像转换为灰度图,并归一化为相同尺寸(如100×100像素)。
将每张图像展平为一个列向量(维度为D×1,如10000维)。
(2) 计算类内散布矩阵 SW对每个类别(每个人)计算均值向量 μi:

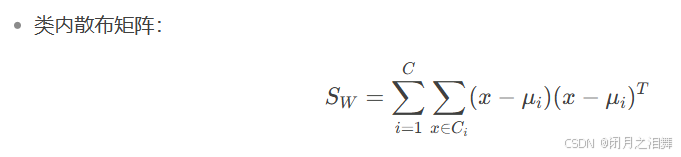
(3) 计算类间散布矩阵 SB
计算全局均值向量 μ:

(4) 求解投影矩阵 W
通过广义特征值分解求解:
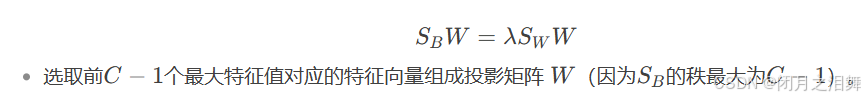
(5) 降维与分类
将原始数据投影到低维空间:
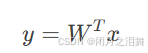
在低维空间中使用分类器(如KNN、SVM)进行分类。
3. Fisherface vs. Eigenface
Eigenface(PCA):基于主成分分析(PCA),最大化全局方差,无监督方法。对光照、姿态变化敏感。
Fisherface(LDA):结合类别信息,最大化类间差异、最小化类内差异,有监督方法。对光照、表情等变化更具鲁棒性。
4. 优缺点
优点:
利用类别信息,分类性能优于PCA。
对类内变化(如光照、表情)有更好的鲁棒性。
缺点:
需要类别标签,属于有监督方法。
当样本数远小于特征维度时(如小样本问题),SW 可能奇异(不可逆),需先通过PCA降维(称为Fisherfaces的常见实现方式)。
二、Fisherface人脸识别代码
1、导入依赖库
import cv2 # OpenCV库,用于图像处理和计算机视觉任务
import numpy as np # 数值计算库
from PIL import Image, ImageFont, ImageDraw # 图像处理库(用于添加中文文本)
2、定义在OpenCV图像上添加中文文本的函数
def cv2AddChineseText(img, text, position, textColor=(0,255,0), textSize=30):"""功能:在OpenCV图像上添加中文文本参数:img: 输入图像(OpenCV格式的numpy数组)text: 要添加的中文文本position: 文本位置坐标 (x,y)textColor: 文本颜色 (B,G,R)textSize: 字体大小返回:添加文本后的图像(OpenCV格式)"""# 将OpenCV的BGR图像转换为PIL的RGB格式if(isinstance(img, np.ndarray)):img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))# 创建PIL绘图对象draw = ImageDraw.Draw(img)# 加载中文字体(注意字体文件路径需要存在)fontStyle = ImageFont.truetype('../data/simhei.ttf', textSize, encoding='utf-8')# 在指定位置绘制文本draw.text(position, text, textColor, font=fontStyle)# 将PIL图像转回OpenCV格式(BGR)return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
3、定义图像预处理函数
def image_re(img):"""功能:读取图像并进行预处理处理步骤:1. 以灰度模式读取图像2. 调整尺寸为120x180像素3. 将图像添加到全局列表images中"""a = cv2.imread(img, 0) # 参数0表示灰度模式读取a = cv2.resize(a, (120, 180)) # 统一图像尺寸images.append(a) # 添加到训练集列表
4、主程序
---------- 数据准备阶段 ----------
if __name__ == "__main__":images = [] # 存储训练图像的列# 加载训练图像(注意路径需要存在)image_re('../data/face-detect/lyf1.png') # 刘亦菲样本1image_re('../data/face-detect/lyf2.png') # 刘亦菲样本2image_re('../data/face-detect/pyc1.png') # 彭逸畅样本1image_re('../data/face-detect/pyc2.png') # 彭逸畅样本2# 创建对应标签(0=刘亦菲,1=彭逸畅)labels = [0, 0, 1, 1] # 每个样本对应的类别标签# 加载待识别的测试图像pre_image = cv2.imread('../data/face-detect/pyc.png', 0) # 灰度读取pre_image = cv2.resize(pre_image, (120, 180)) # 调整尺寸
---------- 模型训练阶段 ----------
# 创建FisherFace识别器(需要安装opencv-contrib-python)recognizer = cv2.face.FisherFaceRecognizer_create(threshold=5000)# 训练模型recognizer.train(images, np.array(labels)) # 输入图像列表和标签数组
------------ 预测阶段 ---------------
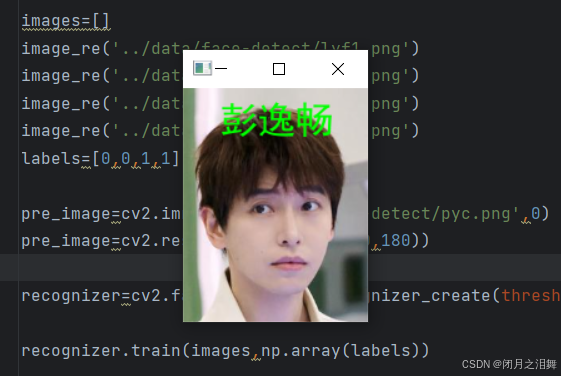
# 进行预测,返回预测标签和置信度label, confidence = recognizer.predict(pre_image)# 创建标签到姓名的映射字典dic = {0: '刘亦菲', 1: '彭逸畅', -1: '无法识别'} # -1为默认未知类别---------- 结果可视化 ----------
# 读取原始彩色图像并添加识别结果文本result_img = cv2AddChineseText(cv2.imread('../data/face-detect/pyc.png').copy(), # 原始彩色图像dic[label], # 识别结果文本(30, 10), # 文本位置textColor=(0, 255, 0) # 绿色文本)# 显示结果图像cv2.imshow('Face Recognition Result', result_img)cv2.waitKey(0) # 等待按键后关闭窗口
最终效果:
与之前的人脸识别项目相同,此处依然可以调用摄像头,具体实现方法和LBPH实现方法相同。
总结
Fisherface作为基于线性判别分析(LDA)的经典人脸识别方法,通过有监督的投影方向优化,在特征空间中实现了类间差异的最大化与类内差异的最小化。相较于无监督的Eigenface方法,Fisherface充分挖掘了类别标签信息,显著提升了人脸在复杂光照、表情等变化下的识别精度。然而,该方法在小样本场景下面临类内散布矩阵奇异性的问题,常需结合PCA进行预处理以缓解维度灾难。
尽管深度学习方法已在人脸识别中取得突破性进展,Fisherface的理论框架仍具有重要价值。其在低维特征提取与可解释性方面的优势,使其在嵌入式设备、轻量级系统中保有应用潜力。未来,结合传统方法与深度学习的特点,或可进一步推动人脸识别技术在鲁棒性、效率与泛化能力上的均衡发展。