【LLMs篇】12:Qwen3 技术报告翻译
Qwen3 模型系列摘要介绍
| 特点/方面 | 描述/详情 |
|---|---|
| 核心目标 | 提升大型语言模型的性能、效率和多语言能力。 |
| 模型系列 | 包含一系列密集型 (Dense) 和混合专家 (MoE) 架构的模型。 |
| 参数规模 | 从 0.6B 到 235B。旗舰模型 Qwen3-235B-A22B (MoE) 总参数 235B,激活参数 22B。 |
| 核心创新点 | |
| 统一框架 | 思考模式 (Thinking Mode) (用于复杂、多步推理) 与 非思考模式 (Non-thinking Mode) (用于快速、上下文驱动的响应) 集成到单一模型中,消除了在不同模型间切换的需求。 |
| 动态模式切换 | 可根据用户查询或聊天模板(如 /think, /no_think 标志)动态切换思考/非思考模式。 |
| 思考预算机制 | 允许用户在推理时自适应地分配计算资源(指定思考token预算),从而根据任务复杂性平衡延迟和性能。 |
| 知识迁移 | 通过利用旗舰模型的知识,显著减少构建较小规模模型所需的计算资源,同时确保其高性能。 |
| 架构改进 (密集型) | 移除了 Qwen2 中的 QKV-bias,引入 QK-Norm 到注意力机制,确保稳定训练。 |
| 架构改进 (MoE) | 遵循 Qwen2.5-MoE 并实现细粒度专家切分;不包含共享专家;采用全局批次负载均衡损失 (global-batch load balancing loss) 鼓励专家专门化。 |
| 预训练策略 | 采用三阶段预训练:1) 通用阶段 (30T+ tokens, 4K序列长度, 119种语言);2) 推理阶段 (5T 高质量tokens, 增强STEM、编码、推理);3) 长上下文阶段 (数百B tokens, 32K序列长度, RoPE基频提升, YARN, DCA技术)。 |
| 后训练策略 (旗舰模型) | 复杂的四阶段后训练:1) 长CoT冷启动;2) 推理RL;3) 思考模式融合 (SFT, 聊天模板设计);4) 通用RL (覆盖指令遵循、格式遵循、偏好对齐、智能体能力、特定场景能力)。 |
| 后训练策略 (轻量级模型) | 采用强到弱蒸馏 (Strong-to-Weak Distillation):1) 离策略蒸馏 (教师模型输出logits);2) 在策略蒸馏 (学生模型生成序列,与教师模型logits对齐)。GPU小时数仅为四阶段训练的1/10。 |
| 数据处理 | 开发了多语言数据标注系统,对超过30万亿token进行多维度标注 (教育价值、领域、主题、安全等),支持实例级数据混合优化。通过Qwen2.5-VL从PDF提取文本,使用Qwen2.5-Math/Coder生成合成数据。 |
| 多语言能力 | 从 Qwen2.5 的 29 种语言扩展到 119 种语言和方言。 |
| 预训练数据量 | 约 36 万亿 (trillion) tokens。 |
| 分词器 (Tokenizer) | 使用 Qwen 的分词器 (Bai et al., 2023),实现字节级字节对编码 (BBPE),词汇表大小为 151,669。 |
| 上下文长度 | 预训练支持最高 32,768 tokens。部分模型(如Qwen3-4B/8B/14B/32B, MoE模型)支持最高 128K tokens 的上下文长度。 |
| 性能表现 | 在代码生成、数学推理、智能体任务等多种基准测试中达到 SOTA,与大型 MoE 模型和专有模型相比具有竞争力。 |
文章目录
- 摘要
- 1 引言
- 2 架构
- 3 预训练
- **3.1 预训练数据**
- **3.2 预训练阶段**
- **3.3 预训练评估**
- 4 后训练
- **4.1 长CoT冷启动**
- **4.2 推理RL**
- **4.3 思考模式融合**
- **4.4 通用RL**
- **4.5 强到弱蒸馏**
- **4.6 后训练评估**
- **4.7 讨论**
- 5 结论
摘要
在本文中,我们介绍了Qwen模型系列的最新版本Qwen3。Qwen3包含一系列大型语言模型(LLM),旨在提升性能、效率和多语言能力。Qwen3系列包括密集型和混合专家(MoE)架构的模型,参数规模从6亿到2350亿。Qwen3的一个关键创新是将思考模式(用于复杂的多步推理)和非思考模式(用于快速的、上下文驱动的响应)集成到一个统一的框架中。这消除了在不同模型之间切换的需求——例如聊天优化模型(如GPT-4o)和专用推理模型(如QwQ-32B)——并能根据用户查询或聊天模板实现动态模式切换。同时,Qwen3引入了思考预算机制,允许用户在推理过程中自适应地分配计算资源,从而根据任务复杂性平衡延迟和性能。此外,通过利用旗舰模型的知识,我们显著减少了构建较小规模模型所需的计算资源,同时确保了它们极具竞争力的性能。实证评估表明,Qwen3在各种基准测试中均取得了SOTA结果,包括代码生成、数学推理、智能体任务等,与更大的MoE模型和专有模型相比具有竞争力。与其前身Qwen2.5相比,Qwen3将多语言支持从29种语言扩展到119种语言和方言,通过改进跨语言理解和生成能力增强了全球可访问性。为促进可复现性和社区驱动的研究与开发,所有Qwen3模型均在Apache 2.0许可下公开。
1 引言
追求人工智能(AGI)或人工超级智能(ASI)一直是人类的长期目标。近期大型基础模型的进展,例如GPT-4o (OpenAI, 2024)、Claude 3.7 (Anthropic, 2025)、Gemini 2.5 (DeepMind, 2025)、DeepSeek-V3 (Liu et al., 2024a)、Llama-4 (Meta-AI, 2025) 和 Qwen2.5 (Yang et al., 2024b),已显示出朝此目标取得的重大进展。这些模型在跨越不同领域和任务的数万亿token的庞大数据集上进行训练,有效地将人类知识和能力提炼到其参数中。此外,通过强化学习优化的推理模型的最新发展,突显了基础模型增强推理时扩展并达到更高智能水平的潜力,例如o3 (OpenAI, 2025)、DeepSeek-R1 (Guo et al., 2025)。虽然大多数SOTA模型仍然是专有的,但开源社区的快速发展已大幅缩小了开源权重模型与闭源模型之间的性能差距。值得注意的是,越来越多的顶级模型 (Meta-AI, 2025; Liu et al., 2024a; Guo et al., 2025; Yang et al., 2024b) 现在正作为开源发布,促进了人工智能领域更广泛的研究和创新。
在本文中,我们介绍了Qwen3,这是我们基础模型系列Qwen的最新一代。Qwen3是一系列开源权重的大型语言模型(LLM),它们在各种任务和领域中都达到了SOTA的性能。我们发布了密集型和混合专家(MoE)模型,参数数量从6亿到2350亿不等,以满足不同下游应用的需求。值得注意的是,旗舰模型Qwen3-235B-A22B是一个MoE模型,总参数量为2350亿,每个token激活220亿参数。这种设计确保了高性能和高效推理。
Qwen3引入了几个关键的改进以增强其功能和可用性。首先,它将两种不同的操作模式——思考模式和非思考模式——集成到一个单一模型中。这允许用户在这些模式之间切换,而无需在不同模型之间交替,例如从Qwen2.5切换到QwQ (Qwen Team, 2024)。这种灵活性确保了开发人员和用户可以有效地调整模型的行为以适应特定任务。此外,Qwen3加入了思考预算功能,为用户提供了对模型在任务执行期间应用的推理努力程度的细粒度控制。这种能力对于优化计算资源和性能至关重要,可以根据实际应用中不同的复杂性来调整模型的思考行为。此外,Qwen3已在覆盖多达119种语言和方言的36万亿token上进行了预训练,有效地增强了其多语言能力。这种扩展的语言支持扩大了其在全球用例和国际应用中部署的潜力。这些进步共同确立了Qwen3作为尖端开源大型语言模型系列的地位,能够有效处理跨越不同领域和语言的复杂任务。
Qwen3的预训练过程使用了一个大规模数据集,包含约36万亿token,经过精心策划以确保语言和领域的多样性。为了有效地扩展训练数据,我们采用了一种多模态方法:对Qwen2.5-VL (Bai et al., 2025) 进行微调,以从大量的PDF文档中提取文本。我们还使用领域特定模型生成合成数据:Qwen2.5-Math (Yang et al., 2024c) 用于数学内容,Qwen2.5-Coder (Hui et al., 2024) 用于代码相关数据。预训练过程遵循三阶段策略。在第一阶段,模型在约30万亿token上进行训练,以建立强大的通用知识基础。在第二阶段,它在知识密集型数据上进一步训练,以增强科学、技术、工程和数学(STEM)以及编码等领域的推理能力。最后,在第三阶段,模型在长上下文数据上进行训练,将其最大上下文长度从4,096增加到32,768 token。
为了更好地将基础模型与人类偏好和下游应用对齐,我们采用了一种多阶段后训练方法,该方法同时赋能思考(推理)和非思考模式。在前两个阶段,我们通过长思维链(CoT)冷启动微调和专注于数学及编码任务的强化学习,致力于发展强大的推理能力。在最后两个阶段,我们将带有和不带有推理路径的数据组合成一个统一的数据集进行进一步微调,使模型能够有效地处理这两种类型的输入,然后我们应用通用领域强化学习来提高模型在广泛下游任务中的性能。对于较小的模型,我们使用强到弱蒸馏,利用来自较大模型的离策略和在策略知识转移来增强其能力。来自高级教师模型的蒸馏在性能和训练效率方面显著优于强化学习。
我们在跨越多个任务和领域的综合基准测试集上评估了我们模型的预训练和后训练版本。实验结果表明,我们的基础预训练模型达到了SOTA的性能。后训练模型,无论是在思考模式还是非思考模式下,都与领先的专有模型和大型混合专家(MoE)模型(如o1、o3-mini和DeepSeek-V3)表现出竞争力。值得注意的是,我们的模型在编码、数学和与智能体相关的任务中表现出色。例如,旗舰模型Qwen3-235B-A22B在AIME’24上达到85.7分,在AIME’25 (AIME, 2025) 上达到81.5分,在LiveCodeBench v5 (Jain et al., 2024) 上达到70.7分,在CodeForces上达到2,056分,在BFCL v3 (Yan et al., 2024) 上达到70.8分。此外,Qwen3系列中的其他模型也显示出与其规模相称的强大性能。此外,我们观察到,增加思考token的思考预算会导致模型在各种任务上的性能持续提高。
在接下来的章节中,我们将描述模型架构的设计,提供其训练过程的详细信息,展示预训练和后训练模型的实验结果,最后通过总结主要发现并概述未来研究的潜在方向来结束本技术报告。
2 架构
Qwen3系列包括6个密集模型,即Qwen3-0.6B、Qwen3-1.7B、Qwen3-4B、Qwen3-8B、Qwen3-14B和Qwen3-32B,以及2个MoE模型,Qwen3-30B-A3B和Qwen3-235B-A22B。旗舰模型Qwen3-235B-A22B总共有2350亿参数,其中220亿为激活参数。下面,我们将详细介绍Qwen3模型的架构。
Qwen3密集模型的架构与Qwen2.5 (Yang et al., 2024b) 相似,包括使用分组查询注意力(GQA, Ainslie et al., 2023)、SwiGLU (Dauphin et al., 2017)、旋转位置嵌入(RoPE, Su et al., 2024)和带有预归一化(pre-normalization)的RMSNorm (Jiang et al., 2023)。此外,我们移除了Qwen2 (Yang et al., 2024a) 中使用的QKV偏置,并引入了QK-Norm (Dehghani et al., 2023) 到注意力机制中,以确保Qwen3的稳定训练。模型架构的关键信息见表1。
Qwen3 MoE模型与Qwen3密集模型共享相同的基础架构。模型架构的关键信息见表2。我们遵循Qwen2.5-MoE (Yang et al., 2024b) 并实现了细粒度专家切分 (Dai et al., 2024)。Qwen3 MoE模型共有128个专家,每个token激活8个专家。与Qwen2.5-MoE不同,Qwen3-MoE设计不包括共享专家。此外,我们采用全局批次负载均衡损失 (Qiu et al., 2025) 来鼓励专家专门化。这些架构和训练创新在下游任务的模型性能上取得了显著的改进。
Qwen3模型使用Qwen的分词器 (Bai et al., 2023),该分词器实现了字节级字节对编码(BBPE, Brown et al., 2020; Wang et al., 2020; Sennrich et al., 2016),词汇表大小为151,669。
表1: Qwen3密集模型的模型架构。
| 模型 | 层数 | 头数 (Q / KV) | 绑定嵌入 | 上下文长度 |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | 是 | 32K |
| Qwen3-1.7B | 28 | 16 / 8 | 是 | 32K |
| Qwen3-4B | 36 | 32 / 8 | 是 | 128K |
| Qwen3-8B | 36 | 32 / 8 | 否 | 128K |
| Qwen3-14B | 40 | 40 / 8 | 否 | 128K |
| Qwen3-32B | 64 | 64 / 8 | 否 | 128K |
表2: Qwen3 MoE模型的模型架构。
| 模型 | 层数 | 头数 (Q / KV) | 专家数 (总计 / 激活) | 上下文长度 |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 128K |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 128K |
3 预训练
在本节中,我们描述了预训练数据的构建、预训练方法的细节,并展示了在标准基准测试中评估基础模型的实验结果。
3.1 预训练数据
与Qwen2.5 (Yang et al., 2024b) 相比,我们显著扩展了训练数据的规模和多样性。具体来说,我们收集了多两倍的预训练token——覆盖了三倍多的语言。所有Qwen3模型都在一个包含119种语言和方言、总计36万亿token的大型多样化数据集上进行训练。该数据集包括各种高质量内容领域,如编码、STEM(科学、技术、工程和数学)、推理任务、书籍、多语言文本和合成数据。
为了进一步扩展预训练数据语料库,我们首先使用Qwen2.5-VL模型 (Bai et al., 2025) 对大量类PDF文档执行文本识别。然后使用Qwen2.5模型 (Yang et al., 2024b) 对识别出的文本进行优化,这有助于提高其质量。通过这个两步过程,我们能够获得额外的高质量文本token集,总量达到数万亿。此外,我们使用Qwen2.5 (Yang et al., 2024b)、Qwen2.5-Math (Yang et al., 2024c) 和Qwen2.5-Coder (Hui et al., 2024) 模型来合成数万亿不同格式的文本token,包括教科书、问答、指令和代码片段,涵盖数十个领域。最后,我们通过整合额外的多语言数据和引入更多语言来进一步扩展预训练语料库。与Qwen2.5中使用的预训练数据相比,支持的语言数量从29种显著增加到119种,增强了模型的语言覆盖范围和跨语言能力。
我们开发了一个多语言数据标注系统,旨在增强训练数据的质量和多样性。该系统已应用于我们的大规模预训练数据集,对超过30万亿token进行了跨多个维度的标注,例如教育价值、领域、主题和安全性。这些详细的标注支持更有效的数据过滤和组合。与以往在数据源或领域层面优化数据混合的研究 (Xie et al., 2023; Fan et al., 2023; Liu et al., 2024b) 不同,我们的方法通过在小型代理模型上使用细粒度数据标签进行广泛的消融实验,在实例层面优化数据混合。
3.2 预训练阶段
Qwen3模型通过三阶段过程进行预训练:
(1) 通用阶段 (S1): 在第一个预训练阶段,所有Qwen3模型都在超过30万亿token上进行训练,序列长度为4,096 token。在此阶段,模型已充分预训练了语言熟练度和通用世界知识,训练数据覆盖119种语言和方言。
(2) 推理阶段 (S2): 为进一步提高推理能力,我们通过增加STEM、编码、推理和合成数据的比例来优化此阶段的预训练语料库。模型在约5万亿更高质量的token上进一步预训练,序列长度为4,096 token。我们还在这个阶段加速了学习率衰减。
(3) 长上下文阶段: 在最后的预训练阶段,我们收集高质量的长上下文语料库以扩展Qwen3模型的上下文长度。所有模型都在数百亿token上进行预训练,序列长度为32,768 token。长上下文语料库包括75%长度在16,384到32,768 token之间的文本,以及25%长度在4,096到16,384 token之间的文本。遵循Qwen2.5 (Yang et al., 2024b),我们使用ABF技术 (Xiong et al., 2023) 将RoPE的基础频率从10,000增加到1,000,000。同时,我们引入了YARN (Peng et al., 2023) 和双块注意力(DCA, An et al., 2024)以在推理过程中实现序列长度能力的四倍提升。
与Qwen2.5 (Yang et al., 2024b) 类似,我们基于上述三个预训练阶段,为最优超参数(例如学习率调度器和批次大小)的预测制定了缩放法则。通过广泛的实验,我们系统地研究了模型架构、训练数据、训练阶段和最优训练超参数之间的关系。最后,我们为每个密集型或MoE模型设置了预测的最优学习率和批次大小策略。
3.3 预训练评估
我们对Qwen3系列的基础语言模型进行了综合评估。基础模型的评估主要关注其在通用知识、推理、数学、科学知识、编码和多语言能力方面的性能。预训练基础模型的评估数据集包括15个基准测试:
- 通用任务: MMLU (Hendrycks et al., 2021a) (5-shot), MMLU-Pro (Wang et al., 2024) (5-shot, CoT), MMLU-redux (Gema et al., 2024) (5-shot), BBH (Suzgun et al., 2023) (3-shot, CoT), SuperGPQA (Du et al., 2025)(5-shot, CoT).
- 数学与STEM任务: GPQA (Rein et al., 2023) (5-shot, CoT), GSM8K (Cobbe et al., 2021) (4-shot, CoT), MATH (Hendrycks et al., 2021b) (4-shot, CoT).
- 编码任务: EvalPlus (Liu et al., 2023a) (0-shot) (HumanEval (Chen et al., 2021), MBPP (Austin et al., 2021), Humaneval+, MBPP+ 的平均值) (Liu et al., 2023a), MultiPL-E (Cassano et al., 2023) (0-shot) (Python, C++, JAVA, PHP, TypeScript, C#, Bash, JavaScript), MBPP-3shot (Austin et al., 2021), CRUX-O of CRUXEval (1-shot) (Gu et al., 2024)。
- 多语言任务: MGSM (Shi et al., 2023) (8-shot, CoT), MMMLU (OpenAI, 2024) (5-shot), INCLUDE (Romanou et al., 2024) (5-shot)。
对于基础模型基线,我们将Qwen3系列基础模型与Qwen2.5基础模型 (Yang et al., 2024b) 以及其他领先的开源基础模型进行比较,包括DeepSeek-V3 Base (Liu et al., 2024a)、Gemma-3 (Team et al., 2025)、Llama-3 (Dubey et al., 2024) 和Llama-4 (Meta-AI, 2025) 系列基础模型,比较参数规模。所有模型都使用相同的评估流程和广泛使用的评估设置进行评估,以确保公平比较。
评估结果总结 基于整体评估结果,我们总结了Qwen3基础模型的一些关键结论。
(1) 与之前开源的SOTA密集型和MoE基础模型(如DeepSeek-V3 Base、Llama-4-Maverick Base和Qwen2.5-72B-Base)相比,Qwen3-235B-A22B-Base在大多数任务中都表现更优,且总参数量或激活参数量显著更少。
(2) 对于Qwen3 MoE基础模型,我们的实验结果表明:(a) 使用相同的预训练数据,Qwen3 MoE基础模型可以达到与Qwen3密集基础模型相似的性能,而激活参数仅为其1/5。(b) 由于Qwen3 MoE架构的改进、训练token规模的扩大以及更先进的训练策略,Qwen3 MoE基础模型可以胜过Qwen2.5 MoE基础模型,且激活参数少于1/2,总参数更少。© 即使激活参数仅为Qwen2.5密集基础模型的1/10,Qwen3 MoE基础模型也能达到相当的性能,这为我们在推理和训练成本方面带来了显著优势。
(3) Qwen3密集基础模型的整体性能与更高参数规模的Qwen2.5基础模型相当。例如,Qwen3-1.7B/4B/8B/14B/32B-Base分别达到了与Qwen2.5-3B/7B/14B/32B/72B-Base相当的性能。特别是在STEM、编码和推理基准测试中,Qwen3密集基础模型的性能甚至超过了更高参数规模的Qwen2.5基础模型。
详细结果如下。
Qwen3-235B-A22B-Base 我们将Qwen3-235B-A22B-Base与我们之前类似规模的MoE模型Qwen2.5-Plus-Base (Yang et al., 2024b) 以及其他领先的开源基础模型进行比较:Llama-4-Maverick (Meta-AI, 2025)、Qwen2.5-72B-Base (Yang et al., 2024b)、DeepSeek-V3 Base (Liu et al., 2024a)。从表3的结果来看,Qwen3-235B-A22B-Base模型在大多数评估基准测试中都获得了最高的性能分数。我们进一步将Qwen3-235B-A22B-Base与其他基线分别进行比较,以进行详细分析。
(1) 与最近开源的Llama-4-Maverick-Base模型(参数数量约是其两倍)相比,Qwen3-235B-A22B-Base在大多数基准测试中仍然表现更好。
(2) 与之前SOTA的开源模型DeepSeek-V3-Base相比,Qwen3-235B-A22B-Base在15个评估基准测试中的14个上胜过DeepSeek-V3-Base,而总参数量仅约为其1/3,激活参数约为其2/3,展示了我们模型的强大功能和成本效益。
(3) 与我们之前类似规模的MoE模型Qwen2.5-Plus相比,Qwen3-235B-A22B-Base在参数和激活参数更少的情况下显著优于它,这显示了Qwen3在预训练数据、训练策略和模型架构方面的显著优势。
(4) 与我们之前的旗舰开源密集模型Qwen2.5-72B-Base相比,Qwen3-235B-A22B-Base在所有基准测试中都超过了后者,并且使用的激活参数少于1/3。同时,由于模型架构的优势,Qwen3-235B-A22B-Base在每万亿token上的推理成本和训练成本远低于Qwen2.5-72B-Base。
Qwen3-32B-Base Qwen3-32B-Base是我们Qwen3系列中最大的密集模型。我们将其与类似规模的基线进行比较,包括Gemma-3-27B (Team et al., 2025) 和Qwen2.5-32B (Yang et al., 2024b)。此外,我们引入了两个强大的基线:最近开源的MoE模型Llama-4-Scout,其参数量是Qwen3-32B-Base的三倍,但激活参数是其一半;
表3: Qwen3-235B-A22B-Base与其他代表性强开源基线的比较。最高分和次高分分别以粗体和下划线显示。
| Qwen2.5-72B Base | Qwen2.5-Plus Base | Llama-4-Maverick Base | DeepSeek-V3 Base | Qwen3-235B-A22B Base | |
|---|---|---|---|---|---|
| 架构 | Dense | MoE | MoE | MoE | MoE |
| # 总参数量 | 72B | 271B | 402B | 671B | 235B |
| # 激活参数量 | 72B | 37B | 17B | 37B | 22B |
| 通用任务 | |||||
| MMLU | 86.06 | 85.02 | 85.16 | 87.19 | 87.81 |
| MMLU-Redux | 83.91 | 82.69 | 84.05 | 86.14 | 87.40 |
| MMLU-Pro | 58.07 | 63.52 | 63.91 | 59.84 | 68.18 |
| SuperGPQA | 36.20 | 37.18 | 40.85 | 41.53 | 44.06 |
| BBH | 86.30 | 85.60 | 83.62 | 86.22 | 88.87 |
| 数学与STEM任务 | |||||
| GPQA | 45.88 | 41.92 | 43.94 | 41.92 | 47.47 |
| GSM8K | 91.50 | 91.89 | 87.72 | 87.57 | 94.39 |
| MATH | 62.12 | 62.78 | 63.32 | 62.62 | 71.84 |
| 编码任务 | |||||
| EvalPlus | 65.93 | 61.43 | 68.38 | 63.75 | 77.60 |
| MultiPL-E | 58.70 | 62.16 | 57.28 | 62.26 | 65.94 |
| MBPP | 76.00 | 74.60 | 75.40 | 74.20 | 81.40 |
| CRUX-O | 66.20 | 68.50 | 77.00 | 76.60 | 79.00 |
| 多语言任务 | |||||
| MGSM | 82.40 | 82.21 | 79.69 | 82.68 | 83.53 |
| MMMLU | 84.40 | 83.49 | 83.09 | 85.88 | 86.70 |
| INCLUDE | 69.05 | 66.97 | 73.47 | 75.17 | 73.46 |
表4: Qwen3-32B-Base与其他强开源基线的比较。最高分和次高分分别以粗体和下划线显示。
| Qwen2.5-32B Base | Qwen2.5-72B Base | Gemma-3-27B Base | Llama-4-Scout Base | Qwen3-32B Base | |
|---|---|---|---|---|---|
| 架构 | Dense | Dense | Dense | MoE | Dense |
| # 总参数量 | 32B | 72B | 27B | 109B | 32B |
| # 激活参数量 | 32B | 72B | 27B | 17B | 32B |
| 通用任务 | |||||
| MMLU | 83.32 | 86.06 | 78.69 | 78.27 | 83.61 |
| MMLU-Redux | 81.97 | 83.91 | 76.53 | 71.09 | 83.41 |
| MMLU-Pro | 55.10 | 58.07 | 52.88 | 56.13 | 65.54 |
| SuperGPQA | 33.55 | 36.20 | 29.87 | 26.51 | 39.78 |
| BBH | 84.48 | 86.30 | 79.95 | 82.40 | 87.38 |
| 数学与STEM任务 | |||||
| GPQA | 47.97 | 45.88 | 26.26 | 40.40 | 49.49 |
| GSM8K | 92.87 | 91.50 | 81.20 | 85.37 | 93.40 |
| MATH | 57.70 | 62.12 | 51.78 | 51.66 | 61.62 |
| 编码任务 | |||||
| EvalPlus | 66.25 | 65.93 | 55.78 | 59.90 | 72.05 |
| MultiPL-E | 58.30 | 58.70 | 45.03 | 47.38 | 67.06 |
| MBPP | 73.60 | 76.00 | 68.40 | 68.60 | 78.20 |
| CRUX-O | 67.80 | 66.20 | 60.00 | 61.90 | 72.50 |
| 多语言任务 | |||||
| MGSM | 78.12 | 82.40 | 73.74 | 79.93 | 83.06 |
| MMMLU | 82.40 | 84.40 | 77.62 | 74.83 | 83.83 |
| INCLUDE | 64.35 | 69.05 | 68.94 | 68.09 | 67.87 |
表5: Qwen3-14B-Base、Qwen3-30B-A3B-Base与其他强开源基线的比较。最高分和次高分分别以粗体和下划线显示。
| Gemma-3-12B Base | Qwen2.5-14B Base | Qwen2.5-32B Base | Qwen2.5-Turbo Base | Qwen3-14B Base | Qwen3-30B-A3B Base | |
|---|---|---|---|---|---|---|
| 架构 | Dense | Dense | Dense | MoE | Dense | MoE |
| # 总参数量 | 12B | 14B | 32B | 42B | 14B | 30B |
| # 激活参数量 | 12B | 14B | 32B | 6B | 14B | 3B |
| 通用任务 | ||||||
| MMLU | 73.87 | 79.66 | 83.32 | 79.50 | 81.05 | 81.38 |
| MMLU-Redux | 70.70 | 76.64 | 81.97 | 77.11 | 79.88 | 81.17 |
| MMLU-Pro | 44.91 | 51.16 | 55.10 | 55.60 | 61.03 | 61.49 |
| SuperGPQA | 24.61 | 30.68 | 33.55 | 31.19 | 34.27 | 35.72 |
| BBH | 74.28 | 78.18 | 84.48 | 76.10 | 81.07 | 81.54 |
| 数学与STEM任务 | ||||||
| GPQA | 31.31 | 32.83 | 47.97 | 41.41 | 39.90 | 43.94 |
| GSM8K | 78.01 | 90.22 | 92.87 | 88.32 | 92.49 | 91.81 |
| MATH | 44.43 | 55.64 | 57.70 | 55.60 | 62.02 | 59.04 |
| 编码任务 | ||||||
| EvalPlus | 52.65 | 60.70 | 66.25 | 61.23 | 72.23 | 71.45 |
| MultiPL-E | 43.03 | 54.79 | 58.30 | 53.24 | 61.69 | 66.53 |
| MBPP | 60.60 | 69.00 | 73.60 | 67.60 | 73.40 | 74.40 |
| CRUX-O | 52.00 | 61.10 | 67.80 | 60.20 | 68.60 | 67.20 |
| 多语言任务 | ||||||
| MGSM | 64.35 | 74.68 | 78.12 | 70.45 | 79.20 | 79.11 |
| MMMLU | 72.50 | 78.34 | 82.40 | 79.76 | 79.69 | 81.46 |
| INCLUDE | 63.34 | 60.26 | 64.35 | 59.25 | 64.55 | 67.00 |
表6: Qwen8B-Base与其他强开源基线的比较。最高分和次高分分别以粗体和下划线显示。
| Llama-3-8B Base | Qwen2.5-7B Base | Qwen2.5-14B Base | Qwen3-8B Base | |
|---|---|---|---|---|
| 架构 | Dense | Dense | Dense | Dense |
| # 总参数量 | 8B | 7B | 14B | 8B |
| # 激活参数量 | 8B | 7B | 14B | 8B |
| 通用任务 | ||||
| MMLU | 66.60 | 74.16 | 79.66 | 76.89 |
| MMLU-Redux | 61.59 | 71.06 | 76.64 | 76.17 |
| MMLU-Pro | 35.36 | 45.00 | 51.16 | 56.73 |
| SuperGPQA | 20.54 | 26.34 | 30.68 | 31.64 |
| BBH | 57.70 | 70.40 | 78.18 | 78.40 |
| 数学与STEM任务 | ||||
| GPQA | 25.80 | 36.36 | 32.83 | 44.44 |
| GSM8K | 55.30 | 85.36 | 90.22 | 89.84 |
| MATH | 20.50 | 49.80 | 55.64 | 60.80 |
| 编码任务 | ||||
| EvalPlus | 44.13 | 62.18 | 60.70 | 67.65 |
| MultiPL-E | 31.45 | 50.73 | 54.79 | 58.75 |
| MBPP | 48.40 | 63.40 | 69.00 | 69.80 |
| CRUX-O | 36.80 | 48.50 | 61.10 | 62.00 |
| 多语言任务 | ||||
| MGSM | 38.92 | 63.60 | 74.68 | 76.02 |
| MMMLU | 59.65 | 71.34 | 78.34 | 75.72 |
| INCLUDE | 44.94 | 53.98 | 60.26 | 59.40 |
表7: Qwen3-4B-Base与其他强开源基线的比较。最高分和次高分分别以粗体和下划线显示。
| Gemma-3-4B Base | Qwen2.5-3B Base | Qwen2.5-7B Base | Qwen3-4B Base | |
|---|---|---|---|---|
| 架构 | Dense | Dense | Dense | Dense |
| # 总参数量 | 4B | 3B | 7B | 4B |
| # 激活参数量 | 4B | 3B | 7B | 4B |
| 通用任务 | ||||
| MMLU | 59.51 | 65.62 | 74.16 | 72.99 |
| MMLU-Redux | 56.91 | 63.68 | 71.06 | 72.79 |
| MMLU-Pro | 29.23 | 34.61 | 45.00 | 50.58 |
| SuperGPQA | 17.68 | 20.31 | 26.34 | 28.43 |
| BBH | 51.70 | 56.30 | 70.40 | 72.59 |
| 数学与STEM任务 | ||||
| GPQA | 24.24 | 26.26 | 36.36 | 36.87 |
| GSM8K | 43.97 | 79.08 | 85.36 | 87.79 |
| MATH | 26.10 | 42.64 | 49.80 | 54.10 |
| 编码任务 | ||||
| EvalPlus | 43.23 | 46.28 | 62.18 | 63.53 |
| MultiPL-E | 28.06 | 39.65 | 50.73 | 53.13 |
| MBPP | 46.40 | 54.60 | 63.40 | 67.00 |
| CRUX-O | 34.00 | 36.50 | 48.50 | 55.00 |
| 多语言任务 | ||||
| MGSM | 33.11 | 47.53 | 63.60 | 67.74 |
| MMMLU | 59.62 | 65.55 | 71.34 | 71.42 |
| INCLUDE | 49.06 | 45.90 | 53.98 | 56.29 |
表8: Qwen3-1.7B-Base、Qwen3-0.6B-Base与其他强开源基线的比较。最高分和次高分分别以粗体和下划线显示。
| Qwen2.5-0.5B Base | Qwen3-0.6B Base | Gemma-3-1B Base | Qwen2.5-1.5B Base | Qwen3-1.7B Base | |
|---|---|---|---|---|---|
| 架构 | Dense | Dense | Dense | Dense | Dense |
| # 总参数量 | 0.5B | 0.6B | 1B | 1.5B | 1.7B |
| # 激活参数量 | 0.5B | 0.6B | 1B | 1.5B | 1.7B |
| 通用任务 | |||||
| MMLU | 47.50 | 52.81 | 26.26 | 60.90 | 62.63 |
| MMLU-Redux | 45.10 | 51.26 | 25.99 | 58.46 | 61.66 |
| MMLU-Pro | 15.69 | 24.74 | 9.72 | 28.53 | 36.76 |
| SuperGPQA | 11.30 | 15.03 | 7.19 | 17.64 | 20.92 |
| BBH | 20.30 | 41.47 | 28.13 | 45.10 | 54.47 |
| 数学与STEM任务 | |||||
| GPQA | 24.75 | 26.77 | 24.75 | 24.24 | 28.28 |
| GSM8K | 41.62 | 59.59 | 2.20 | 68.54 | 75.44 |
| MATH | 19.48 | 32.44 | 3.66 | 35.00 | 43.50 |
| 编码任务 | |||||
| EvalPlus | 31.85 | 36.23 | 8.98 | 44.80 | 52.70 |
| MultiPL-E | 18.70 | 24.58 | 5.15 | 33.10 | 42.71 |
| MBPP | 29.80 | 36.60 | 9.20 | 43.60 | 55.40 |
| CRUX-O | 12.10 | 27.00 | 3.80 | 29.60 | 36.40 |
| 多语言任务 | |||||
| MGSM | 12.07 | 30.99 | 1.74 | 32.82 | 50.71 |
| MMMLU | 31.53 | 50.16 | 26.57 | 60.27 | 63.27 |
| INCLUDE | 24.74 | 34.26 | 25.62 | 39.55 | 45.57 |
以及我们之前的旗舰开源密集模型Qwen2.5-72B-Base,其参数数量是Qwen3-32B-Base的两倍多。结果如表4所示,支持三个关键结论:
(1) 与类似规模的模型相比,Qwen3-32B-Base在大多数基准测试中优于Qwen2.5-32B-Base和Gemma-3-27B Base。值得注意的是,Qwen3-32B-Base在MMLU-Pro上达到65.54分,在SuperGPQA上达到39.78分,显著优于其前身Qwen2.5-32B-Base。此外,Qwen3-32B-Base在编码基准测试中的得分显著高于所有基线模型。
(2) 令人惊讶的是,我们发现Qwen3-32B-Base与Qwen2.5-72B-Base相比取得了有竞争力的结果。尽管Qwen3-32B-Base的参数数量不到Qwen2.5-72B-Base的一半,但它在15个评估基准测试中的10个上优于Qwen2.5-72B-Base。在编码、数学和推理基准测试中,Qwen3-32B-Base具有显著优势。
(3) 与Llama-4-Scout-Base相比,Qwen3-32B-Base在所有15个基准测试中均显著优于它,参数数量仅为Llama-4-Scout-Base的三分之一,但激活参数数量是其两倍。
Qwen3-14B-Base & Qwen3-30B-A3B-Base Qwen3-14B-Base和Qwen3-30B-A3B-Base的评估与类似规模的基线进行比较,包括Gemma-3-12B Base、Qwen2.5-14B Base。同样,我们引入了两个强大的基线:(1) Qwen2.5-Turbo (Yang et al., 2024b),它有42B参数和6B激活参数。请注意,其激活参数是Qwen3-30B-A3B-Base的两倍。(2) Qwen2.5-32B-Base,其激活参数是Qwen3-30B-A3B的11倍,是Qwen3-14B的两倍多。结果如表5所示,我们可以得出以下结论。
(1) 与类似规模的模型相比,Qwen3-14B-Base在所有15个基准测试中均显著优于Qwen2.5-14B-Base和Gemma-3-12B-Base。
(2) 同样,Qwen3-14B-Base与参数数量不到一半的Qwen2.5-32B-Base相比也取得了非常有竞争力的结果。
(3) 仅用1/5的激活非嵌入参数,Qwen3-30B-A3B在所有任务上均显著优于Qwen2.5-14B-Base,并达到了与Qwen3-14B-Base和Qwen2.5-32B-Base相当的性能,这为我们在推理和训练成本方面带来了显著优势。
Qwen3-8B / 4B / 1.7B / 0.6B-Base 对于边缘侧模型,我们采用类似规模的Qwen2.5、Llama-3和Gemma-3基础模型作为基线。结果见表6、表7和表8。所有Qwen3 8B / 4B / 1.7B / 0.6B-Base模型在几乎所有基准测试中都继续保持强劲性能。值得注意的是,Qwen3-8B / 4B / 1.7B-Base模型在一半以上的基准测试中甚至优于更大规模的Qwen2.5-14B / 7B / 3B Base模型,尤其是在STEM相关和编码基准测试中,这反映了Qwen3模型的显著改进。
4 后训练
[图1: Qwen3系列模型的后训练流程。]
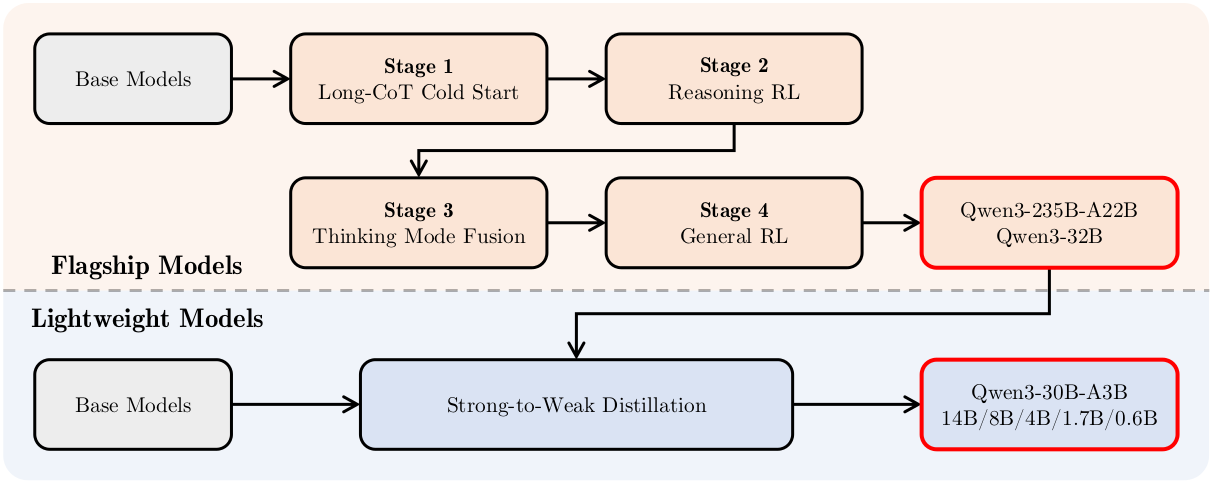
Qwen3的后训练流程在战略上设计了两个核心目标:
(1) 思考控制: 这涉及到整合两种不同的模式,即“非思考”和“思考”模式,为用户提供灵活性,让他们选择模型是否应该进行推理,并通过为思考过程指定token预算来控制思考的深度。
(2) 强到弱蒸馏: 这旨在简化和优化轻量级模型的后训练过程。通过利用大规模模型的知识,我们大幅减少了构建较小规模模型所需的计算成本和开发工作。
如图1所示,Qwen3系列中的旗舰模型遵循一个复杂的四阶段训练过程。前两个阶段专注于发展模型的“思考”能力。接下来的两个阶段旨在将强大的“非思考”功能集成到模型中。
初步实验表明,直接将教师模型的输出logits蒸馏到轻量级学生模型中,可以有效地提高其性能,同时保持对其推理过程的细粒度控制。这种方法消除了为每个小规模模型单独执行详尽的四阶段训练过程的必要性。它带来了更好的即时性能,如更高的Pass@1分数所示,并且还提高了模型的探索能力,如改进的Pass@64结果所示。此外,它以更高的训练效率实现了这些增益,与四阶段训练方法相比,仅需要1/10的GPU小时。
在以下各节中,我们将介绍四阶段训练过程,并详细解释强到弱蒸馏方法。
4.1 长CoT冷启动
我们首先策划一个全面的数据集,涵盖广泛的类别,包括数学、代码、逻辑推理和通用STEM问题。数据集中的每个问题都与经过验证的参考答案或基于代码的测试用例配对。该数据集为长思维链(long-CoT)训练的“冷启动”阶段奠定了基础。
数据集构建涉及一个严格的两阶段过滤过程:查询过滤和响应过滤。在查询过滤阶段,我们使用Qwen2.5-72B-Instruct来识别和移除不易验证的查询。这包括包含多个子问题或要求进行一般文本生成的查询。此外,我们排除了Qwen2.5-72B-Instruct可以在不使用CoT推理的情况下正确回答的查询。这有助于防止模型依赖肤浅的猜测,并确保只包含需要更深层次推理的复杂问题。此外,我们使用Qwen2.5-72B-Instruct标注每个查询的领域,以保持数据集中领域表示的平衡。
在保留一个验证查询集后,我们使用QwQ-32B (Qwen Team, 2025) 为每个剩余查询生成N个候选响应。当QwQ-32B持续无法生成正确解决方案时,人工标注员会手动评估响应的准确性。对于具有正Pass@N的查询,会应用更严格的过滤标准来移除那些 (1) 产生错误最终答案,(2) 包含大量重复,(3) 明显表明猜测而没有充分推理,(4) 思考和总结内容之间存在不一致,(5) 涉及不当的语言混合或风格转换,或 (6) 被怀疑与潜在验证集项目过于相似的响应。随后,从优化后的数据集中精心挑选一个子集,用于推理模式的初始冷启动训练。此阶段的目标是在模型中灌输基础推理模式,而不过分强调即时推理性能。这种方法确保模型的潜力不受限制,从而在后续的强化学习(RL)阶段具有更大的灵活性和改进空间。为有效实现此目标,最好尽量减少此准备阶段的训练样本数量和训练步骤。
4.2 推理RL
推理RL阶段使用的查询-验证器对必须满足以下四个标准:(1) 它们在冷启动阶段未使用。(2) 它们对于冷启动模型是可学习的。(3) 它们尽可能具有挑战性。(4) 它们涵盖广泛的子领域。我们最终收集了总共3,995个查询-验证器对,并采用GRPO (Shao et al., 2024) 来更新模型参数。我们观察到,使用大批量大小和每个查询高数量的rollout,以及通过离策略训练提高样本效率,对训练过程有益。我们还解决了如何通过控制模型的熵使其稳定增加或保持
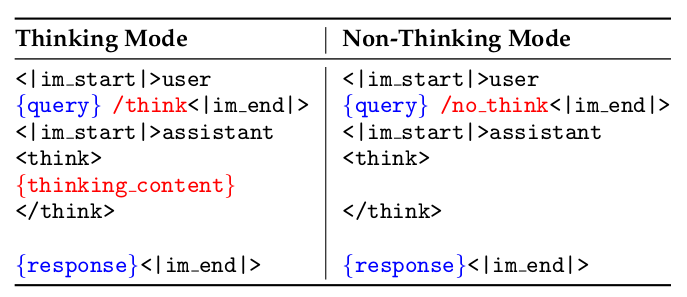
表9: 思考模式融合阶段中思考和非思考模式的SFT数据示例。对于思考模式,/think 标志可以省略,因为它代表默认行为。此功能已在Hugging Face分词器支持的聊天模板¹中实现,其中可以使用附加参数 enable_thinking=False 禁用思考模式。
稳定,这对于维持稳定的训练至关重要。因此,我们在单次RL运行过程中,在训练奖励和验证性能方面都取得了持续的改进,无需对超参数进行任何手动干预。例如,Qwen3-235B-A22B模型在AIME’24上的得分从70.1提高到85.1,总共经过170个RL训练步骤。
4.3 思考模式融合
思考模式融合阶段的目标是将“非思考”能力集成到先前开发的“思考”模型中。这种方法允许开发人员管理和控制推理行为,同时也降低了为思考和非思考任务部署单独模型的成本和复杂性。为实现这一点,我们在推理RL模型上进行持续的监督微调(SFT),并设计一个聊天模板来融合这两种模式。此外,我们发现能够熟练处理两种模式的模型在不同的思考预算下表现始终良好。
SFT数据的构建。 SFT数据集结合了“思考”和“非思考”数据。为确保阶段2模型的性能不受额外SFT的影响,“思考”数据是通过在阶段1查询上使用阶段2模型本身进行拒绝采样生成的。另一方面,“非思考”数据经过精心策划,以涵盖各种任务,包括编码、数学、指令遵循、多语言任务、创意写作、问答和角色扮演。此外,我们采用自动生成的清单来评估“非思考”数据的响应质量。为了增强在低资源语言任务上的性能,我们特别增加了翻译任务的比例。
聊天模板设计。 为了更好地集成这两种模式并使用户能够动态切换模型的思考过程,我们为Qwen3设计了聊天模板,如表9所示。具体来说,对于思考模式和非思考模式的样本,我们分别在用户查询或系统消息中引入/think和/no_think标志。这允许模型遵循用户的输入并相应地选择适当的思考模式。对于非思考模式的样本,我们在助手的响应中保留一个空的思考块。这种设计确保了模型内部格式的一致性,并允许开发人员通过在聊天模板中连接一个空的思考块来阻止模型进行思考行为。默认情况下,模型在思考模式下运行;因此,我们添加了一些用户查询不包含/think标志的思考模式训练样本。对于更复杂的多轮对话,我们随机在用户查询中插入多个/think和/no_think标志,模型响应遵循遇到的最后一个标志。
思考预算。 思考模式融合的另一个优点是,一旦模型学会在非思考和思考模式下响应,它自然会发展出处理中间情况的能力——即基于不完整思考生成响应。这种能力为实现模型思考过程的预算控制奠定了基础。具体来说,当模型的思考长度达到用户定义的阈值时,我们手动停止思考过程并插入停止思考指令:“考虑到用户的时间有限,我现在必须直接基于思考给出解决方案。\n 。\n\n”。插入此指令后,模型将根据其截至该点的累积推理生成最终响应。值得注意的是,这种能力并非显式训练而来,而是应用思考模式融合后自然出现的结果。
4.4 通用RL
通用RL阶段旨在广泛增强模型在各种场景下的能力和稳定性。为促进这一点,我们建立了一个复杂的奖励系统,涵盖超过20个不同的任务,每个任务都有定制的评分标准。这些任务特别针对以下核心能力的增强:
- 指令遵循: 此能力确保模型准确解释并遵循用户指令,包括与内容、格式、长度和结构化输出使用相关的要求,从而提供符合用户期望的响应。
- 格式遵循: 除了明确的指令外,我们期望模型遵守特定的格式约定。例如,它应该通过在思考和非思考模式之间切换来适当地响应
/think和/no_think标志,并在最终输出中一致地使用指定的token(例如,<think>和</think>)来分隔思考和响应部分。 - 偏好对齐: 对于开放式查询,偏好对齐侧重于提高模型的帮助性、参与度和风格,最终提供更自然和令人满意的用户体验。
- 智能体能力: 这涉及到训练模型通过指定的接口正确调用工具。在RL rollout期间,允许模型与真实环境执行反馈进行完整的多轮交互循环,从而提高其在长程决策任务中的性能和稳定性。
- 特定场景能力: 在更专业的场景中,我们设计针对特定上下文的任务。例如,在检索增强生成(RAG)任务中,我们整合奖励信号以引导模型生成准确且与上下文相关的响应,从而最大限度地降低幻觉风险。
为为上述任务提供反馈,我们使用了三种不同类型的奖励:
(1) 基于规则的奖励: 基于规则的奖励已广泛用于推理RL阶段,并且对于诸如指令遵循 (Lambert et al., 2024) 和格式遵守等一般任务也很有用。精心设计的基于规则的奖励可以高精度地评估模型输出的正确性,防止出现奖励hacking等问题。
(2) 带参考答案的基于模型的奖励: 在这种方法中,我们为每个查询提供一个参考答案,并提示Qwen2.5-72B-Instruct根据此参考答案对模型的响应进行评分。这种方法允许更灵活地处理各种任务,而无需严格的格式要求,避免了纯粹基于规则的奖励可能出现的假阴性。
(3) 不带参考答案的基于模型的奖励: 利用人类偏好数据,我们训练一个奖励模型来为模型响应分配标量分数。这种不依赖参考答案的方法可以处理更广泛的查询,同时有效地增强模型的参与度和帮助性。
4.5 强到弱蒸馏
强到弱蒸馏流程专门设计用于优化轻量级模型,包括5个密集模型(Qwen3-0.6B、1.7B、4B、8B和14B)和一个MoE模型(Qwen3-30B-A3B)。这种方法在增强模型性能的同时,有效地赋予了强大的模式切换能力。蒸馏过程分为两个主要阶段:
(1) 离策略蒸馏: 在此初始阶段,我们结合使用/think和/no_think模式生成的教师模型输出来进行响应蒸馏。这有助于轻量级学生模型发展基本的推理技能和在不同思考模式之间切换的能力,为下一个在策略训练阶段奠定坚实的基础。
(2) 在策略蒸馏: 在此阶段,学生模型生成在策略序列以进行微调。具体来说,对提示进行采样,学生模型以/think或/no_think模式产生响应。然后,通过将其logits与教师模型(Qwen3-32B或Qwen3-235B-A22B)的logits对齐来微调学生模型,以最小化KL散度。
4.6 后训练评估
为了全面评估指令调优模型的质量,我们采用了自动基准测试来评估模型在思考和非思考模式下的性能。这些基准测试
表10: 多语言基准测试及其包含的语言。语言以IETF语言标签标识。
| 基准测试 | 语言数量 | 语言 |
|---|---|---|
| Multi-IF | 8 | en, es, fr, hi, it, pt, ru, zh |
| INCLUDE | 44 | ar, az, be, bg, bn, de, el, es, et, eu, fa, fi, fr, he, hi, hr, hu, hy, id, it, ja, ka, kk, ko, lt, mk, ml, ms, ne, nl, pl, pt, ru, sq, sr, ta, te, tl, tr, uk, ur, uz, vi, zh |
| MMMLU | 14 | ar, bn, de, en, es, fr, hi, id, it, ja, ko, pt, sw, zh |
| MT-AIME2024 | 55 | af, ar, bg, bn, ca, cs, cy, da, de, el, en, es, et, fa, fi, fr, gu, he, hi, hr, hu, id, it, ja, kn, ko, lt, lv, mk, ml, mr, ne, nl, no, pa, pl, pt, ro, ru, sk, sl, so, sq, sv, sw, ta, te, th, tl, tr, uk, ur, vi, zh-Hans, zh-Hant |
| PolyMath | 18 | ar, bn, de, en, es, fr, id, it, ja, ko, ms, pt, ru, sw, te, th, vi, zh |
| MLogiQA | 10 | ar, en, es, fr, ja, ko, pt, th, vi, zh |
分为几个维度:
- 通用任务: 我们使用包括MMLU-Redux (Gema et al., 2024)、GPQA-Diamond (Rein et al., 2023)、C-Eval (Huang et al., 2023) 和LiveBench (2024-11-25) (White et al., 2024) 在内的基准测试。对于GPQA-Diamond,我们对每个查询采样10次,并报告平均准确率。
- 对齐任务: 为了评估模型与人类偏好的对齐程度,我们采用了一套专门的基准测试。对于指令遵循性能,我们报告IFEval (Zhou et al., 2023) 的严格提示准确率。为了评估在一般主题上与人类偏好的对齐情况,我们使用Arena-Hard (Li et al., 2024) 和AlignBench v1.1 (Liu et al., 2023b)。对于写作任务,我们依赖Creative Writing V3 (Paech, 2024) 和WritingBench (Wu et al., 2025) 来评估模型的熟练度和创造力。
- 数学与文本推理: 为了评估数学和逻辑推理能力,我们采用高级数学基准测试,包括MATH-500 (Lightman et al., 2023)、AIME’24和AIME’25 (AIME, 2025),以及文本推理任务,包括ZebraLogic (Lin et al., 2025) 和AutoLogi (Zhu et al., 2025)。对于AIME问题,每年的问题包括第一部分和第二部分,共30个问题。对于每个问题,我们采样64次,并取平均准确率作为最终分数。
- 智能体与编码: 为了测试模型在编码和基于智能体的任务中的熟练程度,我们使用BFCL v3 (Yan et al., 2024)、LiveCodeBench (v5, 2024.10-2025.02) (Jain et al., 2024) 和来自CodeElo (Quan et al., 2025) 的Codeforces Ratings。对于BFCL,所有Qwen3模型都使用FC格式进行评估,并使用yarn将模型部署到64k的上下文长度以进行多轮评估。一些基线源自BFCL排行榜,取FC和Prompt格式之间的较高分数。对于未在排行榜上报告的模型,则评估Prompt格式。对于LiveCodeBench,在非思考模式下,我们使用官方推荐的提示,而在思考模式下,我们调整提示模板以允许模型更自由地思考,移除了“你除了程序之外不会返回任何东西”的限制。为了评估模型与编程竞赛专家之间的性能差距,我们使用CodeForces来计算Elo等级分。在我们的基准测试中,每个问题通过生成最多八个独立的推理尝试来解决。
- 多语言任务: 对于多语言能力,我们评估四种任务:指令遵循、知识、数学和逻辑推理。指令遵循使用Multi-IF (He et al., 2024) 进行评估,该测试侧重于8种关键语言。知识评估包括两种类型:通过INCLUDE (Romanou et al., 2024) 评估区域知识,涵盖44种语言;通过MMMLU (OpenAI, 2024) 评估通用知识,涵盖14种语言,不包括未优化的约鲁巴语;对于这两个基准测试,我们仅采样原始数据的10%以提高评估效率。数学任务采用MT-AIME2024 (Son et al., 2025),涵盖55种语言,以及PolyMath (Wang et al., 2025),包括18种语言。逻辑推理使用MLogiQA进行评估,涵盖10种语言,源自Zhang et al. (2024)。
对于思考模式下的所有Qwen3模型,我们使用0.6的采样温度,0.95的top-p值和20的top-k值。此外,对于Creative Writing v3和WritingBench,我们应用1.5的存在惩罚(presence penalty)以鼓励生成更多样化的内容。对于非思考模式下的Qwen3模型,我们将采样超参数配置为温度=0.7,top-p=0.8,top-k=20,存在惩罚=1.5。对于思考和非思考模式,我们将最大输出长度设置为32,768个token,但在AIME’24和AIME’25中,我们将此长度扩展到38,912个token,以提供足够的思考空间。
表11: Qwen3-235B-A22B (思考模式) 与其他推理基线的比较。最高分和次高分分别以粗体和下划线显示。
| OpenAI-o1 | DeepSeek-R1 | Grok-3-Beta (Think) | Gemini2.5-Pro | Qwen3-235B-A22B | |
|---|---|---|---|---|---|
| 架构 | MoE | MoE | |||
| # 激活参数量 | 37B | 22B | |||
| # 总参数量 | 671B | 235B | |||
| 通用任务 | |||||
| MMLU-Redux | 92.8 | 92.9 | 93.7 | 92.7 | |
| GPQA-Diamond | 78.0 | 71.5 | 80.2 | 84.0 | 71.1 |
| C-Eval | 85.5 | 91.8 | 82.9 | 89.6 | |
| LiveBench 2024-11-25 | 75.7 | 71.6 | 82.4 | 77.1 | |
| 对齐任务 | |||||
| IFEval strict prompt | 92.6 | 83.3 | 89.5 | 83.4 | |
| Arena-Hard | 92.1 | 92.3 | 96.4 | 95.6 | |
| AlignBench v1.1 | 8.86 | 8.76 | 9.03 | 8.94 | |
| Creative Writing v3 | 81.7 | 85.5 | 86.0 | 84.6 | |
| WritingBench | 7.69 | 7.71 | 8.09 | 8.03 | |
| 数学与文本推理 | |||||
| MATH-500 | 96.4 | 97.3 | 98.8 | 98.0 | |
| AIME’24 | 74.3 | 79.8 | 83.9 | 92.0 | 85.7 |
| AIME’25 | 79.2 | 70.0 | 77.3 | 86.7 | 81.5 |
| ZebraLogic | 81.0 | 78.7 | 87.4 | 80.3 | |
| AutoLogi | 79.8 | 86.1 | 85.4 | 89.0 | |
| 智能体与编码 | |||||
| BFCL v3 | 67.8 | 56.9 | 62.9 | 70.8 | |
| LiveCodeBench v5 | 63.9 | 64.3 | 70.6 | 70.4 | 70.7 |
| CodeForces (Rating / Percentile) | 1891/96.7% | 2029/98.1% | 2001 / 97.9% | 2056/98.2% | |
| 多语言任务 | |||||
| Multi-IF | 48.8 | 67.7 | 77.8 | 71.9 | |
| INCLUDE | 84.6 | 82.7 | 85.1 | 78.7 | |
| MMMLU 14 languages | 88.4 | 86.4 | 86.9 | 84.3 | |
| MT-AIME2024 | 67.4 | 73.5 | 76.9 | 80.8 | |
| PolyMath | 38.9 | 47.1 | 52.2 | 54.7 | |
| MLogiQA | 75.5 | 73.8 | 75.6 | 77.1 |
表12: Qwen3-235B-A22B (非思考模式) 与其他非推理基线的比较。最高分和次高分分别以粗体和下划线显示。
| GPT-4o -2024-11-20 | DeepSeek-V3 | Qwen2.5-72B -Instruct | LLaMA-4 -Maverick | Qwen3-235B-A22B | |
|---|---|---|---|---|---|
| 架构 | MoE | Dense | MoE | MoE | |
| # 激活参数量 | 37B | 72B | 17B | 22B | |
| # 总参数量 | 671B | 72B | 402B | 235B | |
| 通用任务 | |||||
| MMLU-Redux | 87.0 | 89.1 | 86.8 | 91.8 | 89.2 |
| GPQA-Diamond | 46.0 | 59.1 | 49.0 | 69.8 | 62.9 |
| C-Eval | 75.5 | 86.5 | 84.7 | 83.5 | 86.1 |
| LiveBench 2024-11-25 | 52.2 | 60.5 | 51.4 | 59.5 | 62.5 |
| 对齐任务 | |||||
| IFEval strict prompt | 86.5 | 86.1 | 84.1 | 86.7 | 83.2 |
| Arena-Hard | 85.3 | 85.5 | 81.2 | 82.7 | 96.1 |
| AlignBench v1.1 | 8.42 | 8.64 | 7.89 | 7.97 | 8.91 |
| Creative Writing v3 | 81.1 | 74.0 | 61.8 | 61.3 | 80.4 |
| WritingBench | 7.11 | 6.49 | 7.06 | 5.46 | 7.70 |
| 数学与文本推理 | |||||
| MATH-500 | 77.2 | 90.2 | 83.6 | 90.6 | 91.2 |
| AIME’24 | 11.1 | 39.2 | 18.9 | 38.5 | 40.1 |
| AIME’25 | 7.6 | 28.8 | 15.0 | 15.9 | 24.7 |
| ZebraLogic | 27.4 | 42.1 | 26.6 | 40.0 | 37.7 |
| AutoLogi | 65.9 | 76.1 | 66.1 | 75.2 | 83.3 |
| 智能体与编码 | |||||
| BFCL v3 | 72.5 | 57.6 | 63.4 | 52.9 | 68.0 |
| LiveCodeBench v5 | 32.7 | 33.1 | 30.7 | 37.2 | 35.3 |
| CodeForces (Rating / Percentile) | 864 / 35.4% | 1134 / 54.1% | 859 / 35.0% | 712 / 24.3% | 1387 / 75.7% |
| 多语言任务 | |||||
| Multi-IF | 65.6 | 55.6 | 65.3 | 75.5 | 70.2 |
| INCLUDE | 78.8 | 76.7 | 69.6 | 80.9 | 75.6 |
| MMMLU 14 languages | 80.3 | 81.1 | 76.9 | 82.5 | 79.8 |
| MT-AIME2024 | 9.2 | 20.9 | 12.7 | 27.0 | 32.4 |
| PolyMath | 13.7 | 20.4 | 16.9 | 26.1 | 27.0 |
| MLogiQA | 57.4 | 58.9 | 59.3 | 59.9 | 67.6 |
评估结果总结 根据评估结果,我们总结了最终Qwen3模型的几个关键结论如下:
(1) 我们的旗舰模型Qwen3-235B-A22B在思考和非思考模式下均展示了开源模型中最先进的整体性能,超越了诸如DeepSeek-R1和DeepSeek-V3等强大基线。Qwen3-235B-A22B也与闭源领先模型(如OpenAI-o1、Gemini2.5-Pro和GPT-4o)高度竞争,展示了其深厚的推理能力和全面的通用能力。
(2) 我们的旗舰密集模型Qwen3-32B在大多数基准测试中优于我们之前最强的推理模型QwQ-32B,并且与闭源OpenAI-o3-mini性能相当,表明其具有令人信服的推理能力。Qwen3-32B在非思考模式下也表现出色,并超越了我们之前的旗舰非推理密集模型Qwen2.5-72B-Instruct。
(3) 我们的轻量级模型,包括Qwen3-30B-A3B、Qwen3-14B和其他较小的密集模型,与参数量相近或更大的开源模型相比,始终具有更优越的性能,证明了我们强到弱蒸馏方法的成功。
详细结果如下。
Qwen3-235B-A22B 对于我们的旗舰模型Qwen3-235B-A22B,我们将其与领先的推理和非推理模型进行比较。对于思考模式,我们采用OpenAI-o1 (OpenAI, 2024)、DeepSeek-R1 (Guo et al., 2025)、Grok-3-Beta (Think) (xAI, 2025) 和Gemini2.5-Pro (DeepMind, 2025) 作为推理基线。对于非思考模式,我们采用GPT-4o-2024-11-20 (OpenAI, 2024)、DeepSeek-V3 (Liu et al., 2024a)、Qwen2.5-72B-Instruct (Yang et al., 2024b) 和LLaMA-4-Maverick (Meta-AI, 2025) 作为非推理基线。我们在表11和12中展示了评估结果。
(1) 从表11可以看出,仅用60%的激活参数和35%的总参数,Qwen3-235B-A22B (思考模式) 在17/23的基准测试中优于DeepSeek-R1,尤其是在需要推理的任务(例如,数学、智能体和编码)上,展示了Qwen3-235B-A22B在开源模型中最先进的推理能力。此外,Qwen3-235B-A22B (思考模式) 也与闭源OpenAI-o1、Grok-3-Beta (Think) 和Gemini2.5-Pro高度竞争,大幅缩小了开源和闭源模型在推理能力上的差距。
(2) 从表12可以看出,Qwen3-235B-A22B (非思考模式) 超过了其他领先的开源模型,包括DeepSeek-V3、LLaMA-4-Maverick以及我们之前的旗舰模型Qwen2.5-72B-Instruct,并且在18/23的基准测试中也超过了闭源GPT-4o-2024-11-20,表明即使在没有刻意思考过程增强的情况下,它也具有固有的强大能力。
Qwen3-32B 对于我们的旗舰密集模型Qwen3-32B,我们在思考模式下采用DeepSeek-R1-Distill-Llama-70B、OpenAI-o3-mini (medium)以及我们之前最强的推理模型QwQ-32B (Qwen Team, 2025) 作为基线。我们还在非思考模式下采用GPT-4o-mini-2024-07-18、LLaMA-4-Scout以及我们之前的旗舰模型Qwen2.5-72B-Instruct作为基线。我们在表13和14中展示了评估结果。
(1) 从表13可以看出,Qwen3-32B (思考模式) 在17/23的基准测试中优于QwQ-32B,使其成为32B参数量级新的SOTA推理模型。此外,Qwen3-32B (思考模式) 也与闭源OpenAI-o3-mini (medium) 竞争,具有更好的对齐和多语言性能。
(2) 从表14可以看出,Qwen3-32B (非思考模式) 在几乎所有基准测试中都表现出优于所有基线的性能。特别是,Qwen3-32B (非思考模式) 在通用任务上与Qwen2.5-72B-Instruct表现相当,在对齐、多语言和推理相关任务上具有显著优势,再次证明了Qwen3相对于我们之前Qwen2.5系列模型的基本改进。
Qwen3-30B-A3B & Qwen3-14B 对于Qwen3-30B-A3B和Qwen3-14B,我们在思考模式下将它们与DeepSeek-R1-Distill-Qwen-32B和QwQ-32B进行比较,在非思考模式下与Phi-4 (Abdin et al., 2024)、Gemma-3-27B-IT (Team et al., 2025) 和Qwen2.5-32B-Instruct进行比较。我们在表15和16中展示了评估结果。
(1) 从表15可以看出,Qwen3-30B-A3B和Qwen3-14B (思考模式) 都与QwQ-32B高度竞争,尤其是在推理相关的基准测试上。值得注意的是,Qwen3-30B-A3B以更小的模型尺寸和更少的
表13: Qwen3-32B (思考模式) 与其他推理基线的比较。最高分和次高分分别以粗体和下划线显示。
| DeepSeek-R1 -Distill-Llama-70B | QwQ-32B | OpenAI-o3-mini (medium) | Qwen3-32B | |
|---|---|---|---|---|
| 架构 | Dense | Dense | Dense | |
| # 激活参数量 | 70B | 32B | 32B | |
| # 总参数量 | 70B | 32B | 32B | |
| 通用任务 | ||||
| MMLU-Redux | 89.3 | 90.0 | 90.0 | 90.9 |
| GPQA-Diamond | 65.2 | 65.6 | 76.8 | 68.4 |
| C-Eval | 71.8 | 88.4 | 75.1 | 87.3 |
| LiveBench 2024-11-25 | 54.5 | 72.0 | 70.0 | 74.9 |
| 对齐任务 | ||||
| IFEval strict prompt | 79.3 | 83.9 | 91.5 | 85.0 |
| Arena-Hard | 60.6 | 89.5 | 89.0 | 93.8 |
| AlignBench v1.1 | 6.74 | 8.70 | 8.38 | 8.72 |
| Creative Writing v3 | 62.1 | 82.4 | 74.8 | 81.0 |
| WritingBench | 6.08 | 7.86 | 7.52 | 7.90 |
| 数学与文本推理 | ||||
| MATH-500 | 94.5 | 98.0 | 98.0 | 97.2 |
| AIME’24 | 70.0 | 79.5 | 79.6 | 81.4 |
| AIME’25 | 56.3 | 69.5 | 74.8 | 72.9 |
| ZebraLogic | 71.3 | 76.8 | 88.9 | 88.8 |
| AutoLogi | 83.5 | 88.1 | 86.3 | 87.3 |
| 智能体与编码 | ||||
| BFCL v3 | 49.3 | 66.4 | 64.6 | 70.3 |
| LiveCodeBench v5 | 54.5 | 62.7 | 66.3 | 65.7 |
| CodeForces (Rating / Percentile) | 1633 / 91.4% | 1982 / 97.7% | 2036 / 98.1% | 1977 / 97.7% |
| 多语言任务 | ||||
| Multi-IF | 57.6 | 68.3 | 48.4 | 73.0 |
| INCLUDE | 62.1 | 69.7 | 73.1 | 73.7 |
| MMMLU 14 languages | 69.6 | 80.9 | 79.3 | 80.6 |
| MT-AIME2024 | 29.3 | 68.0 | 73.9 | 75.0 |
| PolyMath | 29.4 | 45.9 | 38.6 | 47.4 |
| MLogiQA | 60.3 | 75.5 | 71.1 | 76.3 |
表14: Qwen3-32B (非思考模式) 与其他非推理基线的比较。最高分和次高分分别以粗体和下划线显示。
| GPT-4o-mini -2024-07-18 | LLaMA-4 -Scout | Qwen2.5-72B -Instruct | Qwen3-32B | |
|---|---|---|---|---|
| 架构 | MoE | Dense | Dense | |
| # 激活参数量 | 17B | 72B | 32B | |
| # 总参数量 | 109B | 72B | 32B | |
| 通用任务 | ||||
| MMLU-Redux | 81.5 | 86.3 | 86.8 | 85.7 |
| GPQA-Diamond | 40.2 | 57.2 | 49.0 | 54.6 |
| C-Eval | 66.3 | 78.2 | 84.7 | 83.3 |
| LiveBench 2024-11-25 | 41.3 | 47.6 | 51.4 | 59.8 |
| 对齐任务 | ||||
| IFEval strict prompt | 80.4 | 84.7 | 84.1 | 83.2 |
| Arena-Hard | 74.9 | 70.5 | 81.2 | 92.8 |
| AlignBench v1.1 | 7.81 | 7.49 | 7.89 | 8.58 |
| Creative Writing v3 | 70.3 | 55.0 | 61.8 | 78.3 |
| WritingBench | 5.98 | 5.49 | 7.06 | 7.54 |
| 数学与文本推理 | ||||
| MATH-500 | 78.2 | 82.6 | 83.6 | 88.6 |
| AIME’24 | 8.1 | 28.6 | 18.9 | 31.0 |
| AIME’25 | 8.8 | 10.0 | 15.0 | 20.2 |
| ZebraLogic | 20.1 | 24.2 | 26.6 | 29.2 |
| AutoLogi | 52.6 | 56.8 | 66.1 | 78.5 |
| 智能体与编码 | ||||
| BFCL v3 | 64.0 | 45.4 | 63.4 | 63.0 |
| LiveCodeBench v5 | 27.9 | 29.8 | 30.7 | 31.3 |
| CodeForces (Rating / Percentile) | 1113 / 52.6% | 981 / 43.7% | 859 / 35.0% | 1353 / 71.0% |
| 多语言任务 | ||||
| Multi-IF | 62.4 | 64.2 | 65.3 | 70.7 |
| INCLUDE | 66.0 | 74.1 | 69.6 | 70.9 |
| MMMLU 14 languages | 72.1 | 77.5 | 76.9 | 76.5 |
| MT-AIME2024 | 6.0 | 19.1 | 12.7 | 24.1 |
| PolyMath | 12.0 | 20.9 | 16.9 | 22.5 |
| MLogiQA | 42.6 | 53.9 | 59.3 | 62.9 |
表15: Qwen3-30B-A3B / Qwen3-14B (思考模式) 与其他推理基线的比较。最高分和次高分分别以粗体和下划线显示。
| DeepSeek-R1 -Distill-Qwen-32B | QwQ-32B | Qwen3-14B | Qwen3-30B-A3B | |
|---|---|---|---|---|
| 架构 | Dense | Dense | Dense | MoE |
| # 激活参数量 | 32B | 32B | 14B | 3B |
| # 总参数量 | 32B | 32B | 14B | 30B |
| 通用任务 | ||||
| MMLU-Redux | 88.2 | 90.0 | 88.6 | 89.5 |
| GPQA-Diamond | 62.1 | 65.6 | 64.0 | 65.8 |
| C-Eval | 82.2 | 88.4 | 86.2 | 86.6 |
| LiveBench 2024-11-25 | 45.6 | 72.0 | 71.3 | 74.3 |
| 对齐任务 | ||||
| IFEval strict prompt | 72.5 | 83.9 | 85.4 | 86.5 |
| Arena-Hard | 60.8 | 89.5 | 91.7 | 91.0 |
| AlignBench v1.1 | 7.25 | 8.70 | 8.56 | 8.70 |
| Creative Writing v3 | 55.0 | 82.4 | 80.3 | 79.1 |
| WritingBench | 6.13 | 7.86 | 7.80 | 7.70 |
| 数学与文本推理 | ||||
| MATH-500 | 94.3 | 98.0 | 96.8 | 98.0 |
| AIME’24 | 72.6 | 79.5 | 79.3 | 80.4 |
| AIME’25 | 49.6 | 69.5 | 70.4 | 70.9 |
| ZebraLogic | 69.6 | 76.8 | 88.5 | 89.5 |
| AutoLogi | 74.6 | 88.1 | 89.2 | 88.7 |
| 智能体与编码 | ||||
| BFCL v3 | 53.5 | 66.4 | 70.4 | 69.1 |
| LiveCodeBench v5 | 54.5 | 62.7 | 63.5 | 62.6 |
| CodeForces (Rating / Percentile) | 1691 / 93.4% | 1982 / 97.7% | 1766 / 95.3% | 1974 / 97.7% |
| 多语言任务 | ||||
| Multi-IF | 31.3 | 68.3 | 74.8 | 72.2 |
| INCLUDE | 68.0 | 69.7 | 71.7 | 71.9 |
| MMMLU 14 languages | 78.6 | 80.9 | 77.9 | 78.4 |
| MT-AIME2024 | 44.6 | 68.0 | 73.3 | 73.9 |
| PolyMath | 35.1 | 45.9 | 45.8 | 46.1 |
| MLogiQA | 63.3 | 75.5 | 71.1 | 70.1 |
表16: Qwen3-30B-A3B / Qwen3-14B (非思考模式) 与其他非推理基线的比较。最高分和次高分分别以粗体和下划线显示。
| Phi-4 | Gemma-3 -27B-IT | Qwen2.5-32B -Instruct | Qwen3-14B | Qwen3-30B-A3B | |
|---|---|---|---|---|---|
| 架构 | Dense | Dense | Dense | Dense | MoE |
| # 激活参数量 | 14B | 27B | 32B | 14B | 3B |
| # 总参数量 | 14B | 27B | 32B | 14B | 30B |
| 通用任务 | |||||
| MMLU-Redux | 85.3 | 82.6 | 83.9 | 82.0 | 84.1 |
| GPQA-Diamond | 56.1 | 42.4 | 49.5 | 54.8 | 54.8 |
| C-Eval | 66.9 | 66.6 | 80.6 | 81.0 | 82.9 |
| LiveBench 2024-11-25 | 41.6 | 49.2 | 50.0 | 59.6 | 59.4 |
| 对齐任务 | |||||
| IFEval strict prompt | 62.1 | 80.6 | 79.5 | 84.8 | 83.7 |
| Arena-Hard | 75.4 | 86.8 | 74.5 | 86.3 | 88.0 |
| AlignBench v1.1 | 7.61 | 7.80 | 7.71 | 8.52 | 8.55 |
| Creative Writing v3 | 51.2 | 82.0 | 54.6 | 73.1 | 68.1 |
| WritingBench | 5.73 | 7.22 | 5.90 | 7.24 | 7.22 |
| 数学与文本推理 | |||||
| MATH-500 | 80.8 | 90.0 | 84.6 | 90.0 | 89.8 |
| AIME’24 | 22.9 | 32.6 | 18.8 | 31.7 | 32.8 |
| AIME’25 | 17.3 | 24.0 | 12.8 | 23.3 | 21.6 |
| ZebraLogic | 32.3 | 24.6 | 26.1 | 33.0 | 33.2 |
| AutoLogi | 66.2 | 64.2 | 65.5 | 82.0 | 81.5 |
| 智能体与编码 | |||||
| BFCL v3 | 47.0 | 59.1 | 62.8 | 61.5 | 58.6 |
| LiveCodeBench v5 | 25.2 | 26.9 | 26.4 | 29.0 | 29.8 |
| CodeForces (Rating / Percentile) | 1280 / 65.3% | 1063 / 49.3% | 903 / 38.2% | 1200 / 58.6% | 1267 / 64.1% |
| 多语言任务 | |||||
| Multi-IF | 49.5 | 69.8 | 63.2 | 72.9 | 70.8 |
| INCLUDE | 65.3 | 71.4 | 67.5 | 67.8 | 67.8 |
| MMMLU 14 languages | 74.7 | 76.1 | 74.2 | 72.6 | 73.8 |
| MT-AIME2024 | 13.1 | 23.0 | 15.3 | 23.2 | 24.6 |
| PolyMath | 17.4 | 20.3 | 18.3 | 22.0 | 23.3 |
| MLogiQA | 53.1 | 58.5 | 58.0 | 58.9 | 53.3 |
表17: Qwen3-8B / Qwen3-4B (思考模式) 与其他推理基线的比较。最高分和次高分分别以粗体和下划线显示。
| DeepSeek-R1 -Distill-Qwen-14B | DeepSeek-R1 -Distill-Qwen-32B | Qwen3-4B | Qwen3-8B | |
|---|---|---|---|---|
| 架构 | Dense | Dense | Dense | Dense |
| # 激活参数量 | 14B | 32B | 4B | 8B |
| # 总参数量 | 14B | 32B | 4B | 8B |
| 通用任务 | ||||
| MMLU-Redux | 84.1 | 88.2 | 83.7 | 87.5 |
| GPQA-Diamond | 59.1 | 62.1 | 55.9 | 62.0 |
| C-Eval | 78.1 | 82.2 | 77.5 | 83.4 |
| LiveBench 2024-11-25 | 52.3 | 45.6 | 63.6 | 67.1 |
| 对齐任务 | ||||
| IFEval strict prompt | 72.6 | 72.5 | 81.9 | 85.0 |
| Arena-Hard | 48.0 | 60.8 | 76.6 | 85.8 |
| AlignBench v1.1 | 7.43 | 7.25 | 8.30 | 8.46 |
| Creative Writing v3 | 54.2 | 55.0 | 61.1 | 75.0 |
| WritingBench | 6.03 | 6.13 | 7.35 | 7.59 |
| 数学与文本推理 | ||||
| MATH-500 | 93.9 | 94.3 | 97.0 | 97.4 |
| AIME’24 | 69.7 | 72.6 | 73.8 | 76.0 |
| AIME’25 | 44.5 | 49.6 | 65.6 | 67.3 |
| ZebraLogic | 59.1 | 69.6 | 81.0 | 84.8 |
| AutoLogi | 78.6 | 74.6 | 87.9 | 89.1 |
| 智能体与编码 | ||||
| BFCL v3 | 49.5 | 53.5 | 65.9 | 68.1 |
| LiveCodeBench v5 | 45.5 | 54.5 | 54.2 | 57.5 |
| CodeForces (Rating / Percentile) | 1574 / 89.1% | 1691 / 93.4% | 1671 / 92.8% | 1785 / 95.6% |
| 多语言任务 | ||||
| Multi-IF | 29.8 | 31.3 | 66.3 | 71.2 |
| INCLUDE | 59.7 | 68.0 | 61.8 | 67.8 |
| MMMLU 14 languages | 73.8 | 78.6 | 69.8 | 74.4 |
| MT-AIME2024 | 33.7 | 44.6 | 60.7 | 65.4 |
| PolyMath | 28.6 | 35.1 | 40.0 | 42.7 |
| MLogiQA | 53.6 | 63.3 | 65.9 | 69.0 |
表18: Qwen3-8B / Qwen3-4B (非思考模式) 与其他非推理基线的比较。最高分和次高分分别以粗体和下划线显示。
| LLAMA-3.1-8B -Instruct | Gemma-3 -12B-IT | Qwen2.5-7B -Instruct | Qwen2.5-14B -Instruct | Qwen3-4B | Qwen3-8B | |
|---|---|---|---|---|---|---|
| 架构 | Dense | Dense | Dense | Dense | Dense | Dense |
| # 激活参数量 | 8B | 12B | 7B | 14B | 4B | 8B |
| # 总参数量 | 8B | 12B | 7B | 14B | 4B | 8B |
| 通用任务 | ||||||
| MMLU-Redux | 61.7 | 77.8 | 75.4 | 80.0 | 77.3 | 79.5 |
| GPQA-Diamond | 32.8 | 40.9 | 36.4 | 45.5 | 41.7 | 39.3 |
| C-Eval | 52.0 | 61.1 | 76.2 | 78.0 | 72.2 | 77.9 |
| LiveBench 2024-11-25 | 26.0 | 43.7 | 34.9 | 42.2 | 48.4 | 53.5 |
| 对齐任务 | ||||||
| IFEval strict prompt | 75.0 | 80.2 | 71.2 | 81.0 | 81.2 | 83.0 |
| Arena-Hard | 30.1 | 82.6 | 52.0 | 68.3 | 66.2 | 79.6 |
| AlignBench v1.1 | 6.01 | 7.77 | 7.27 | 7.67 | 8.10 | 8.38 |
| Creative Writing v3 | 52.8 | 79.9 | 49.8 | 55.8 | 53.6 | 64.5 |
| WritingBench | 4.57 | 7.05 | 5.82 | 5.93 | 6.85 | 7.15 |
| 数学与文本推理 | ||||||
| MATH-500 | 54.8 | 85.6 | 77.6 | 83.4 | 84.8 | 87.4 |
| AIME’24 | 6.3 | 22.4 | 9.1 | 15.2 | 25.0 | 29.1 |
| AIME’25 | 2.7 | 18.8 | 12.1 | 13.6 | 19.1 | 20.9 |
| ZebraLogic | 12.8 | 17.8 | 12.0 | 19.7 | 35.2 | 26.7 |
| AutoLogi | 30.9 | 58.9 | 42.9 | 57.4 | 76.3 | 76.5 |
| 智能体与编码 | ||||||
| BFCL v3 | 49.6 | 50.6 | 55.8 | 58.7 | 57.6 | 60.2 |
| LiveCodeBench v5 | 10.8 | 25.7 | 14.4 | 21.9 | 21.3 | 22.8 |
| CodeForces (Rating / Percentile) | 473 / 14.9% | 462 / 14.7% | 191 / 0.0% | 904 / 38.3% | 842 / 33.7% | 1110 / 52.4% |
| 多语言任务 | ||||||
| Multi-IF | 52.1 | 65.6 | 47.7 | 55.5 | 61.3 | 69.2 |
| INCLUDE | 34.0 | 65.3 | 53.6 | 63.5 | 53.8 | 62.5 |
| MMMLU 14 languages | 44.4 | 70.0 | 61.4 | 70.3 | 61.7 | 66.9 |
| MT-AIME2024 | 0.4 | 16.7 | 5.5 | 8.5 | 13.9 | 16.6 |
| PolyMath | 5.8 | 17.6 | 11.9 | 15.0 | 16.6 | 18.8 |
| MLogiQA | 41.9 | 54.5 | 49.5 | 51.3 | 49.9 | 51.4 |
表19: Qwen3-1.7B / Qwen3-0.6B (思考模式) 与其他推理基线的比较。最高分和次高分分别以粗体和下划线显示。
| DeepSeek-R1 -Distill-Qwen-1.5B | DeepSeek-R1 -Distill-Llama-8B | Qwen3-0.6B | Qwen3-1.7B | |
|---|---|---|---|---|
| 架构 | Dense | Dense | Dense | Dense |
| # 激活参数量 | 1.5B | 8B | 0.6B | 1.7B |
| # 总参数量 | 1.5B | 8B | 0.6B | 1.7B |
| 通用任务 | ||||
| MMLU-Redux | 45.4 | 66.4 | 55.6 | 73.9 |
| GPQA-Diamond | 33.8 | 49.0 | 27.9 | 40.1 |
| C-Eval | 27.1 | 50.4 | 50.4 | 68.1 |
| LiveBench 2024-11-25 | 24.9 | 40.6 | 30.3 | 51.1 |
| 对齐任务 | ||||
| IFEval strict prompt | 39.9 | 59.0 | 59.2 | 72.5 |
| Arena-Hard | 4.5 | 17.6 | 8.5 | 43.1 |
| AlignBench v1.1 | 5.00 | 6.24 | 6.10 | 7.60 |
| Creative Writing v3 | 16.4 | 51.1 | 30.6 | 48.0 |
| WritingBench | 4.03 | 5.42 | 5.61 | 7.02 |
| 数学与文本推理 | ||||
| MATH-500 | 83.9 | 89.1 | 77.6 | 93.4 |
| AIME’24 | 28.9 | 50.4 | 10.7 | 48.3 |
| AIME’25 | 22.8 | 27.8 | 15.1 | 36.8 |
| ZebraLogic | 4.9 | 37.1 | 30.3 | 63.2 |
| AutoLogi | 19.1 | 63.4 | 61.6 | 83.2 |
| 智能体与编码 | ||||
| BFCL v3 | 14.0 | 21.5 | 46.4 | 56.6 |
| LiveCodeBench v5 | 13.2 | 42.5 | 12.3 | 33.2 |
| 多语言任务 | ||||
| Multi-IF | 13.3 | 27.0 | 36.1 | 51.2 |
| INCLUDE | 21.9 | 34.5 | 35.9 | 51.8 |
| MMMLU 14 languages | 27.3 | 40.1 | 43.1 | 59.1 |
| MT-AIME2024 | 12.4 | 13.2 | 7.8 | 36.1 |
| PolyMath | 14.5 | 10.8 | 11.4 | 25.2 |
| MLogiQA | 29.0 | 32.8 | 40.9 | 56.0 |
表20: Qwen3-1.7B / Qwen3-0.6B (非思考模式) 与其他非推理基线的比较。最高分和次高分分别以粗体和下划线显示。
| Gemma-3 -1B-IT | Phi-4-mini | Qwen2.5-1.5B -Instruct | Qwen2.5-3B -Instruct | Qwen3-0.6B | Qwen3-1.7B | |
|---|---|---|---|---|---|---|
| 架构 | Dense | Dense | Dense | Dense | Dense | Dense |
| # 激活参数量 | 1.0B | 3.8B | 1.5B | 3.1B | 0.6B | 1.7B |
| # 总参数量 | 1.0B | 3.8B | 1.5B | 3.1B | 0.6B | 1.7B |
| 通用任务 | ||||||
| MMLU-Redux | 33.3 | 67.9 | 50.7 | 64.4 | 44.6 | 64.4 |
| GPQA-Diamond | 19.2 | 25.2 | 29.8 | 30.3 | 22.9 | 28.6 |
| C-Eval | 28.5 | 40.0 | 53.3 | 68.2 | 42.6 | 61.0 |
| LiveBench 2024-11-25 | 14.4 | 25.3 | 18.0 | 23.8 | 21.8 | 35.6 |
| 对齐任务 | ||||||
| IFEval strict prompt | 54.5 | 68.6 | 42.5 | 58.2 | 54.5 | 68.2 |
| Arena-Hard | 17.8 | 32.8 | 9.0 | 23.7 | 6.5 | 36.9 |
| AlignBench v1.1 | 5.3 | 6.00 | 5.60 | 6.49 | 5.60 | 7.20 |
| Creative Writing v3 | 52.8 | 10.3 | 31.5 | 42.8 | 28.4 | 43.6 |
| WritingBench | 5.18 | 4.05 | 4.67 | 5.55 | 5.13 | 6.54 |
| 数学与文本推理 | ||||||
| MATH-500 | 46.4 | 67.6 | 55.0 | 67.2 | 55.2 | 73.0 |
| AIME’24 | 0.9 | 8.1 | 0.9 | 6.7 | 3.4 | 13.4 |
| AIME’25 | 0.8 | 5.3 | 0.4 | 4.2 | 2.6 | 9.8 |
| ZebraLogic | 1.9 | 2.7 | 3.4 | 4.8 | 4.2 | 12.8 |
| AutoLogi | 16.4 | 28.8 | 22.5 | 29.9 | 37.4 | 59.8 |
| 智能体与编码 | ||||||
| BFCL v3 | 16.3 | 31.3 | 47.8 | 50.4 | 44.1 | 52.2 |
| LiveCodeBench v5 | 1.8 | 10.4 | 5.3 | 9.2 | 3.6 | 11.6 |
| 多语言任务 | ||||||
| Multi-IF | 32.8 | 40.5 | 20.2 | 32.3 | 33.3 | 44.7 |
| INCLUDE | 32.7 | 43.8 | 33.1 | 43.8 | 34.4 | 42.6 |
| MMMLU 14 languages | 32.5 | 51.4 | 40.4 | 51.8 | 37.1 | 48.3 |
| MT-AIME2024 | 0.2 | 0.9 | 0.7 | 1.6 | 1.5 | 4.9 |
| PolyMath | 3.5 | 6.7 | 5.0 | 7.3 | 4.6 | 10.3 |
| MLogiQA | 31.8 | 39.5 | 40.9 | 39.5 | 37.3 | 41.1 |
激活参数的1/10,展示了我们强到弱蒸馏方法在赋予轻量级模型深厚推理能力方面的有效性。
(2) 从表16可以看出,Qwen3-30B-A3B和Qwen3-14B (非思考模式) 在大多数基准测试中都超过了非推理基线。它们以显著更少的激活参数和总参数超越了我们之前的Qwen2.5-32B-Instruct模型,从而实现了更高效和更具成本效益的性能。
Qwen3-8B / 4B / 1.7B / 0.6B 对于Qwen3-8B和Qwen3-4B,我们在思考模式下将它们与DeepSeek-R1-Distill-Qwen-14B和DeepSeek-R1-Distill-Qwen-32B进行比较,在非思考模式下分别与LLaMA-3.1-8B-Instruct (Dubey et al., 2024)、Gemma-3-12B-IT (Team et al., 2025)、Qwen2.5-7B-Instruct和Qwen2.5-14B-Instruct进行比较。对于Qwen3-1.7B和Qwen3-0.6B,我们在思考模式下将它们与DeepSeek-R1-Distill-Qwen-1.5B和DeepSeek-R1-Distill-Llama-8B进行比较,在非思考模式下分别与Gemma-3-1B-IT、Phi-4-mini、Qwen2.5-1.5B-Instruct和Qwen2.5-3B-Instruct进行比较。我们在表17和18中展示了Qwen3-8B和Qwen3-4B的评估结果,在表19和20中展示了Qwen3-1.7B和Qwen3-0.6B的评估结果。总体而言,这些边缘侧模型表现出令人印象深刻的性能,并且即使与参数更多的基线(包括我们之前的Qwen2.5模型)相比,在思考或非思考模式下都表现更优。这些结果再次证明了我们强到弱蒸馏方法的有效性,使我们能够以显著降低的成本和精力构建轻量级的Qwen3模型。
4.7 讨论
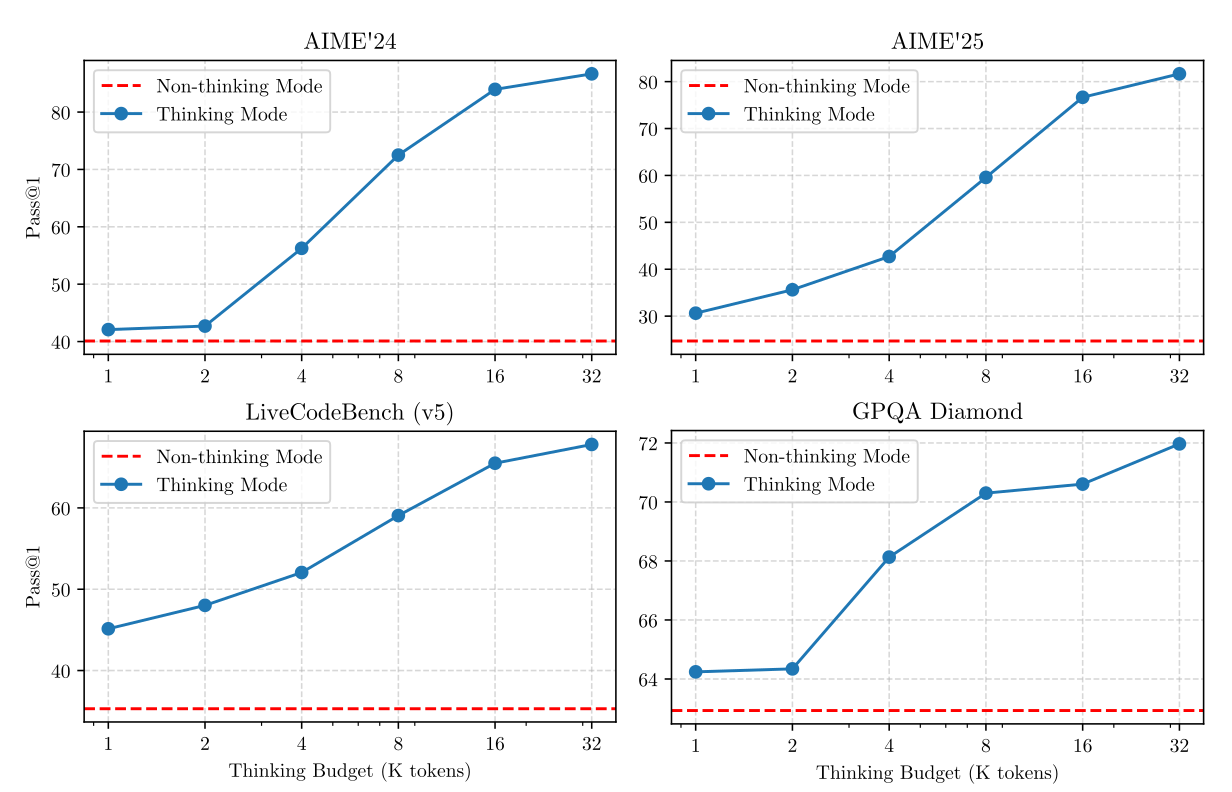
思考预算的有效性 为了验证Qwen3可以通过利用增加的思考预算来提高其智能水平,我们在数学、编码和STEM领域的四个基准测试中调整了分配的思考预算。由此产生的缩放曲线如图2所示,Qwen3展示了与分配的思考预算相关的可扩展且平滑的性能改进。此外,我们观察到,如果我们将输出长度进一步扩展到32K以上,模型的性能预计将在未来进一步提高。我们将此探索留作未来的工作。
[图2: Qwen3-235B-A22B在不同思考预算下的性能。]
在策略蒸馏的有效性和效率 我们通过比较在经历蒸馏与直接强化学习后的性能和计算成本(以GPU小时衡量)来评估在策略蒸馏的有效性和效率,两者都从相同的离策略蒸馏的8B检查点开始。为简单起见,我们在此比较中仅关注与数学和代码相关的查询。
结果总结在表21中,表明蒸馏比强化学习取得了显著更好的性能,而所需GPU小时仅约为其1/10。此外,来自教师logits的蒸馏使学生模型能够扩展其探索空间并增强其推理潜力,如与初始检查点相比,蒸馏后AIME’24和AIME’25基准测试上pass@64分数的提高所证明。相比之下,强化学习并未导致pass@64分数的任何提高。这些观察结果突出了利用更强的教师模型指导学生模型学习的优势。
表21: Qwen3-8B上强化学习与在策略蒸馏的比较。括号中的数字表示pass@64分数。
| 方法 | AIME’24 | AIME’25 | MATH500 | LiveCodeBench v5 | MMLU -Redux | GPQA -Diamond | GPU 小时 |
|---|---|---|---|---|---|---|---|
| 离策略蒸馏 | 55.0 (90.0) | 42.8 (83.3) | 92.4 | 42.0 | 86.4 | 55.6 | |
| + 强化学习 | 67.6 (90.0) | 55.5 (83.3) | 94.8 | 52.9 | 86.9 | 61.3 | 17,920 |
| + 在策略蒸馏 | 74.4 (93.3) | 65.5 (86.7) | 97.0 | 60.3 | 88.3 | 63.3 | 1,800 |
思考模式融合和通用RL的效果 为了评估后训练期间思考模式融合和通用强化学习(RL)的有效性,我们对Qwen-32B模型的不同阶段进行了评估。除了前面提到的数据集外,我们还引入了几个内部基准来监测其他能力。这些基准包括:
- CounterFactQA: 包含反事实问题,模型需要识别问题并非事实并避免产生幻觉答案。
- LengthCtrl: 包括具有长度要求的创意写作任务;最终分数基于生成内容长度与目标长度之间的差异。
- ThinkFollow: 涉及随机插入
/think和/no_think标志的多轮对话,以测试模型是否能根据用户查询正确切换思考模式。 - ToolUse: 评估模型在单轮、多轮和多步工具调用过程中的稳定性。分数包括意图识别的准确性、格式准确性和参数准确性。
表22: Qwen3-32B在推理RL(阶段2)、思考模式融合(阶段3)和通用RL(阶段4)后的性能。带*的基准是内部基准。
| 类别 | 基准测试 | 阶段2 推理RL (思考) | 阶段3 思考模式融合 (思考) | 阶段3 思考模式融合 (非思考) | 阶段4 通用RL (思考) | 阶段4 通用RL (非思考) |
|---|---|---|---|---|---|---|
| 通用任务 | LiveBench 2024-11-25 | 68.6 | 70.9+2.3 | 57.1 | 74.9+4.0 | 59.8+2.8 |
| Arena-Hard | 86.8 | 89.4+2.6 | 88.5 | 93.8+4.4 | 92.8+4.3 | |
| CounterFactQA* | 50.4 | 61.3+10.9 | 64.3 | 68.1+6.8 | 66.4+2.1 | |
| 指令与格式遵循 | IFEval strict prompt | 73.0 | 78.4+5.4 | 78.4 | 85.0+6.6 | 83.2+4.8 |
| Multi-IF | 61.4 | 64.6+3.2 | 65.2 | 73.0+8.4 | 70.7+5.5 | |
| LengthCtrl* | 62.6 | 70.6+8.0 | 84.9 | 73.5+2.9 | 87.3+2.4 | |
| ThinkFollow* | 88.7 | 98.9+10.2 | ||||
| 智能体 | BFCL v3 | 69.0 | 68.4-0.6 | 61.5 | 70.3+1.9 | 63.0+1.5 |
| ToolUse* | 63.3 | 70.4+7.1 | 73.2 | 85.5+15.1 | 86.5+13.3 | |
| 知识与STEM | MMLU-Redux | 91.4 | 91.0-0.4 | 86.7 | 90.9-0.1 | 85.7-1.0 |
| GPQA-Diamond | 68.8 | 69.0+0.2 | 50.4 | 68.4-0.6 | 54.6+4.3 | |
| 数学与编码 | AIME’24 | 83.8 | 81.9-1.9 | 28.5 | 81.4-0.5 | 31.0+2.5 |
| LiveCodeBench v5 | 68.4 | 67.2-1.2 | 31.1 | 65.7-1.5 | 31.3+0.2 |
结果如表22所示,我们可以得出以下结论:
(1) 阶段3将非思考模式集成到模型中,该模型在经过前两个训练阶段后已具备思考能力。ThinkFollow基准测试88.7的得分表明模型已初步具备模式切换能力,尽管偶尔仍会出错。阶段3还增强了模型在思考模式下的通用和指令遵循能力,其中CounterFactQA提高了10.9分,LengthCtrl提高了8.0分。
(2) 阶段4进一步增强了模型在思考和非思考模式下的通用、指令遵循和智能体能力。值得注意的是,ThinkFollow得分提高到98.9,确保了准确的模式切换。
(3) 对于知识、STEM、数学和编码任务,思考模式融合和通用RL并未带来显著改进。相反,对于像AIME’24和LiveCodeBench这样的挑战性任务,思考模式下的性能在这两个训练阶段后实际上有所下降。我们推测这种退化是由于模型在更广泛的通用任务上进行了训练,这可能会损害其在处理复杂问题方面的专业能力。在Qwen3的开发过程中,我们选择接受这种性能权衡,以增强模型的整体通用性。
5 结论
在本技术报告中,我们介绍了Qwen系列的最新版本Qwen3。Qwen3同时具备思考模式和非思考模式,允许用户动态管理用于复杂思考任务的token数量。该模型在一个包含36万亿token的广泛数据集上进行了预训练,使其能够理解和生成119种语言和方言的文本。通过一系列全面的评估,Qwen3在预训练和后训练模型的一系列标准基准测试中均表现出强大的性能,包括与代码生成、数学、推理和智能体相关的任务。
在不久的将来,我们的研究将集中在几个关键领域。我们将继续通过使用质量更高、内容更多样化的数据来扩大预训练规模。同时,我们将致力于改进模型架构和训练方法,以实现有效压缩、扩展到极长上下文等目标。此外,我们计划增加强化学习的计算资源,特别强调从环境反馈中学习的基于智能体的RL系统。这将使我们能够构建能够处理需要推理时扩展的复杂任务的智能体。