从无标注的病理切片中自动提取临床相关的组织形态表型簇,探索其与患者预后、分子表型以及治疗反应的关联
小罗碎碎念
在医学AI研究领域,针对结肠癌病理诊断中人工标注成本高与传统监督学习模型局限性的问题,本文提出基于自监督学习(SSL)的组织形态分析框架。
本文利用Barlow Twins模型对435例TCGA结肠癌全玻片图像(WSIs)的无标注图像块进行特征提取,通过Leiden社区检测算法聚类出47个组织形态表型簇(HPCs),并在1213例AVANT临床试验队列中验证了HPCs的形态一致性与跨数据集泛化能力,为无标注病理图像的特征挖掘提供了新范式。

研究构建了从特征提取到临床关联的完整技术链条:Barlow Twins提取的128维特征经降维和病理学家评估,将HPCs划分为包含肿瘤基质、免疫细胞、黏液区等在内的8个超级簇,揭示了肿瘤上皮分化程度、基质排列特征与免疫浸润模式的异质性。
结合Cox比例风险模型,HPCs组成在AVANT标准治疗组(FOLFOX-4)中预测总生存期(OS)的c-index达0.65,优于基于年龄、TNM分期等临床特征的基线模型,且独立于肿瘤基质比(TSR)等病理参数,证明了形态表型的预后价值。
进一步整合免疫景观分析与基因集富集分析(GSEA),研究发现HPCs可关联分子通路与治疗反应机制:免疫细胞富集簇与高白细胞分数正相关,坏死簇(HPC5)因VEGFA高表达可能对贝伐珠单抗敏感,而KRAS信号激活的黏液肿瘤簇对标准化疗耐药。
该研究不仅为医学AI提供了可解释的病理特征体系,还通过HPCs将组织形态、分子表型与治疗结局关联,为构建“形态-分子-预后”多模态预测模型奠定了基础,有望推动AI在病理辅助诊断与个体化治疗中的临床转化。
交流群
欢迎大家加入【医学AI】交流群,本群设立的初衷是提供交流平台,方便大家后续课题合作。
目前小罗全平台关注量67,000+,交流群总成员1500+,大部分来自国内外顶尖院校/医院,期待您的加入!!
由于近期入群推销人员较多,已开启入群验证,扫码添加我的联系方式,备注姓名-单位-科室/专业,即可邀您入群。
知识星球
对推文中的内容感兴趣,想深入探讨?在处理项目时遇到了问题,无人商量?加入小罗的知识星球,寻找科研道路上的伙伴吧!
一、文献概述
1-1:研究背景与目的
传统结肠癌诊断依赖病理学家对苏木精-伊红(H&E)染色切片的显微评估,结合TNM分期等临床病理特征制定治疗策略,但面临老龄化人口带来的诊断负担及分子标记物检测的复杂性。
数字病理技术通过扫描全玻片图像(WSIs)结合深度学习(DL)提升了诊断效率,但传统监督学习需大量人工标注。
本研究旨在利用自监督学习(SSL)从无标注的H&E WSIs中自动提取临床相关的组织形态表型簇(HPCs),并探索其与患者预后、分子表型及治疗反应的关联。
1-2:研究方法
-
数据与模型训练
- 使用TCGA结肠癌(TCGA-COAD)队列的435例WSIs,将其分割为224×224像素的图像块(tiles),采用Barlow Twins SSL模型提取128维特征向量。
- 通过Leiden社区检测算法对特征向量进行无偏聚类,识别出47个HPCs,并在独立的**AVANT临床试验队列(1213例WSIs)**中验证其可重复性和预后预测能力。
-
HPCs的组织病理学特征
- 由病理学家对每个HPC的代表性图像块进行评估,标注肿瘤上皮、基质、免疫细胞等组织类型及分化程度、基质结构等特征,归纳为8个“超级簇”(如健康/异型增生组织、坏死、黏液区、免疫细胞、肿瘤基质等)。
-
预后分析与治疗反应
- 在TCGA-COAD中训练Cox比例风险模型,基于HPCs组成预测总生存期(OS),并在AVANT队列的标准治疗组(FOLFOX-4)和实验治疗组(贝伐珠单抗联合化疗)中验证。
- 结合免疫景观分析(如白细胞分数、基质高表达)和基因集富集分析(GSEA),探索HPCs与分子通路及治疗机制的关联。
1-3:关键结果
-
HPCs的结构与验证
- 47个HPCs在TCGA和AVANT队列中表现出高度形态一致性,专家评估显示簇内形态相似性高,且跨数据集迁移性良好(如TCGA与AVANT的HPCs图像块形态匹配)。
- 通过UMAP和PAGA图可视化,HPCs按组织成分分为8个超级簇,如肿瘤基质超级簇包含不同分化程度的基质结构,免疫细胞超级簇与较好预后相关。
-
HPCs与预后的关联
- 标准治疗组(FOLFOX-4):HPCs模型的OS预测c-index为0.65,优于临床基线模型(c-index=0.58)。健康结肠组织(HPC39)、免疫细胞富集簇(如HPC31)与较好预后相关;黏液肿瘤(HPC12、38)、低分化肿瘤上皮(HPC45)及紊乱基质(HPC40)与较差预后相关。
- 实验治疗组(贝伐珠单抗):HPCs模型独立预测OS(HR=1.82),坏死簇(HPC5)因VEGFA高表达可能对贝伐珠单抗敏感;KRAS信号通路激活的黏液肿瘤簇(HPC14)对化疗反应差。
-
分子与免疫特征
- 免疫景观分析显示,免疫细胞簇(HPC31)与高白细胞分数正相关,基质紊乱簇(HPC0、21)与基质高表达相关。
- GSEA显示,标准治疗组中上皮-间质转化通路在预后不良簇富集;实验治疗组中,贝伐珠单抗靶点VEGFA相关通路在坏死簇(HPC5)富集,提示其治疗敏感性。
1-4:讨论与临床意义
- 肿瘤微环境的重要性:基质结构(如排列整齐vs.紊乱)、免疫浸润程度及肿瘤分化等级是关键预后因素,HPCs可量化这些特征,补充现有TNM分期。
- 治疗机制探索:贝伐珠单抗对坏死组织丰富(VEGFA高表达)的患者可能更有效,而KRAS突变相关的黏液肿瘤对标准化疗耐药,提示HPCs可指导个体化治疗选择。
- AI在病理中的应用:HPCs作为可解释的AI工具,可生成病理报告辅助多学科会诊,结合基因表达数据优化治疗决策,有望纳入国际病理指南(如ICCR、TNM评估)。
1-5:结论
本研究通过自监督学习构建了结肠癌H&E图像的组织形态表型图谱,验证了HPCs在预后预测和治疗反应中的临床价值,为精准肿瘤学提供了新的病理标志物和分析框架。
未来需在更大队列中验证,并探索其在其他癌症类型中的应用。
二、结肠癌组织形态学研究中自监督学习特征提取及分析流程
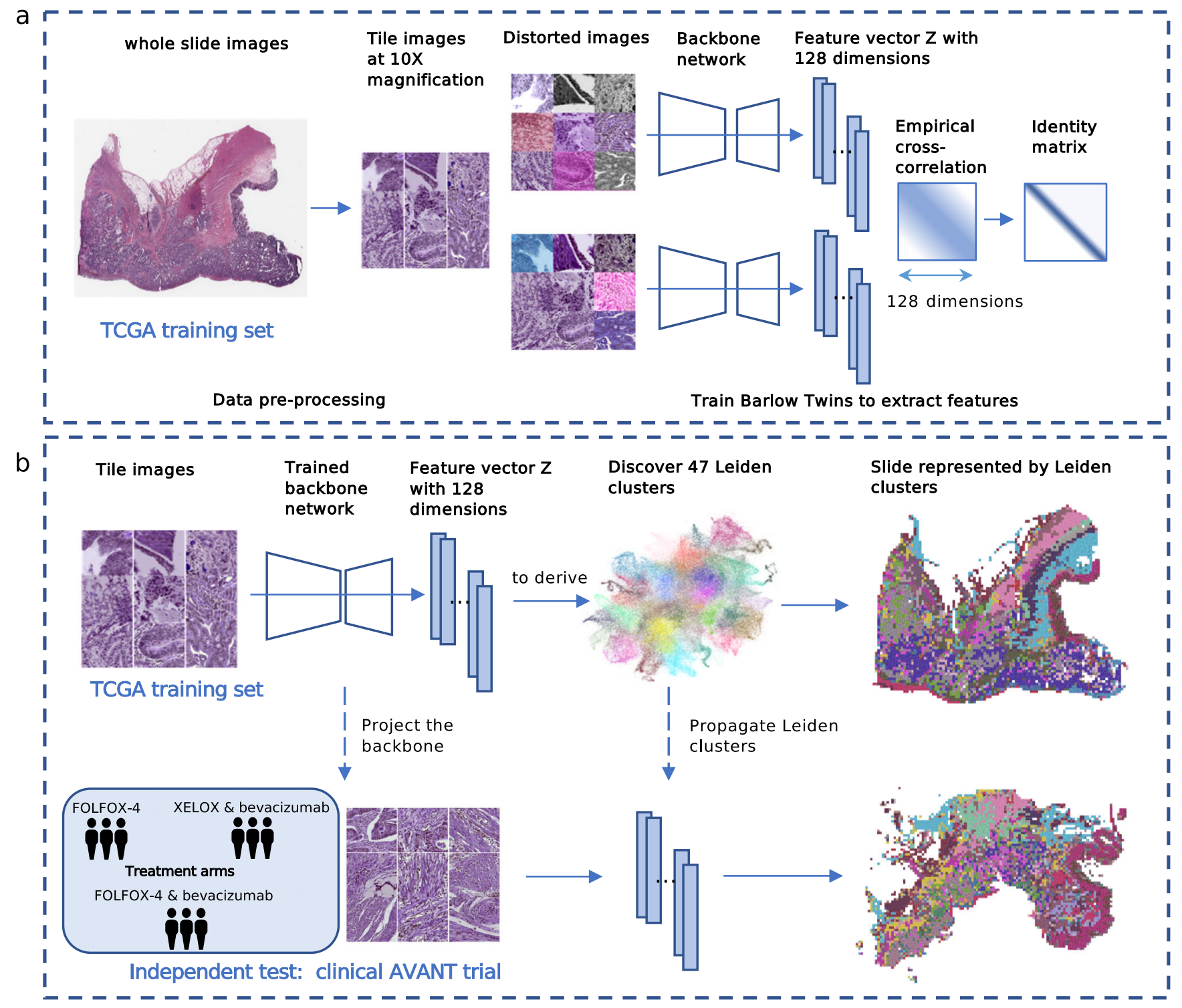
2-1:数据预处理与特征提取
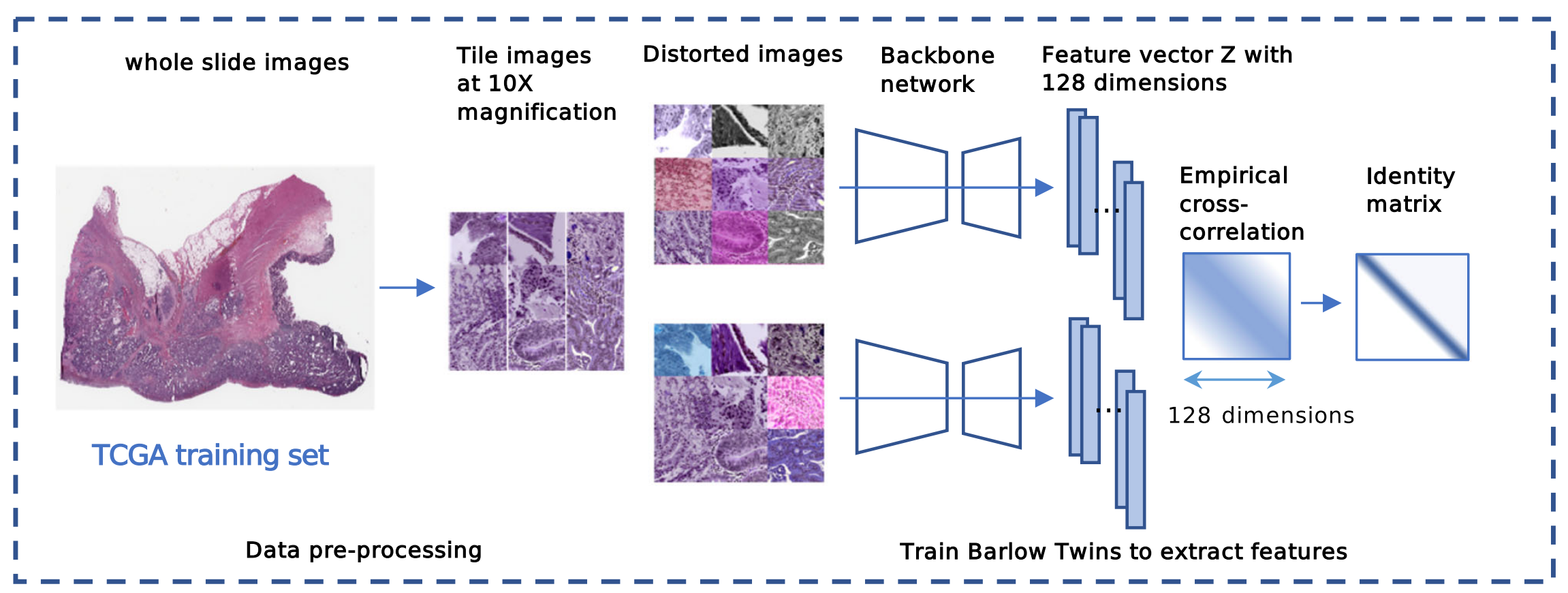
- 数据预处理:以癌症基因组图谱(TCGA)训练集的全玻片图像(whole slide images)为起始数据,将其按10倍放大倍数分割成小块图像(Tile images at 10X magnification) 。之后对小块图像进行扭曲变换(Distorted images),生成不同视角的图像数据,丰富数据多样性。
- 特征提取:使用Barlow Twins模型,通过骨干网络(Backbone network)处理扭曲后的图像。骨干网络输出128维的特征向量Z(Feature vector Z with 128 dimensions) 。训练过程中,计算经验互相关(Empirical cross - correlation),目标是使特征向量的相关矩阵接近单位矩阵(Identity matrix),通过这种方式让模型学习到有区分度的图像特征 。 此流程借助自监督学习自动挖掘组织图像特征,避免了大量人工标注,为后续分析组织形态学表型等奠定基础。
2-2:特征聚类与验证
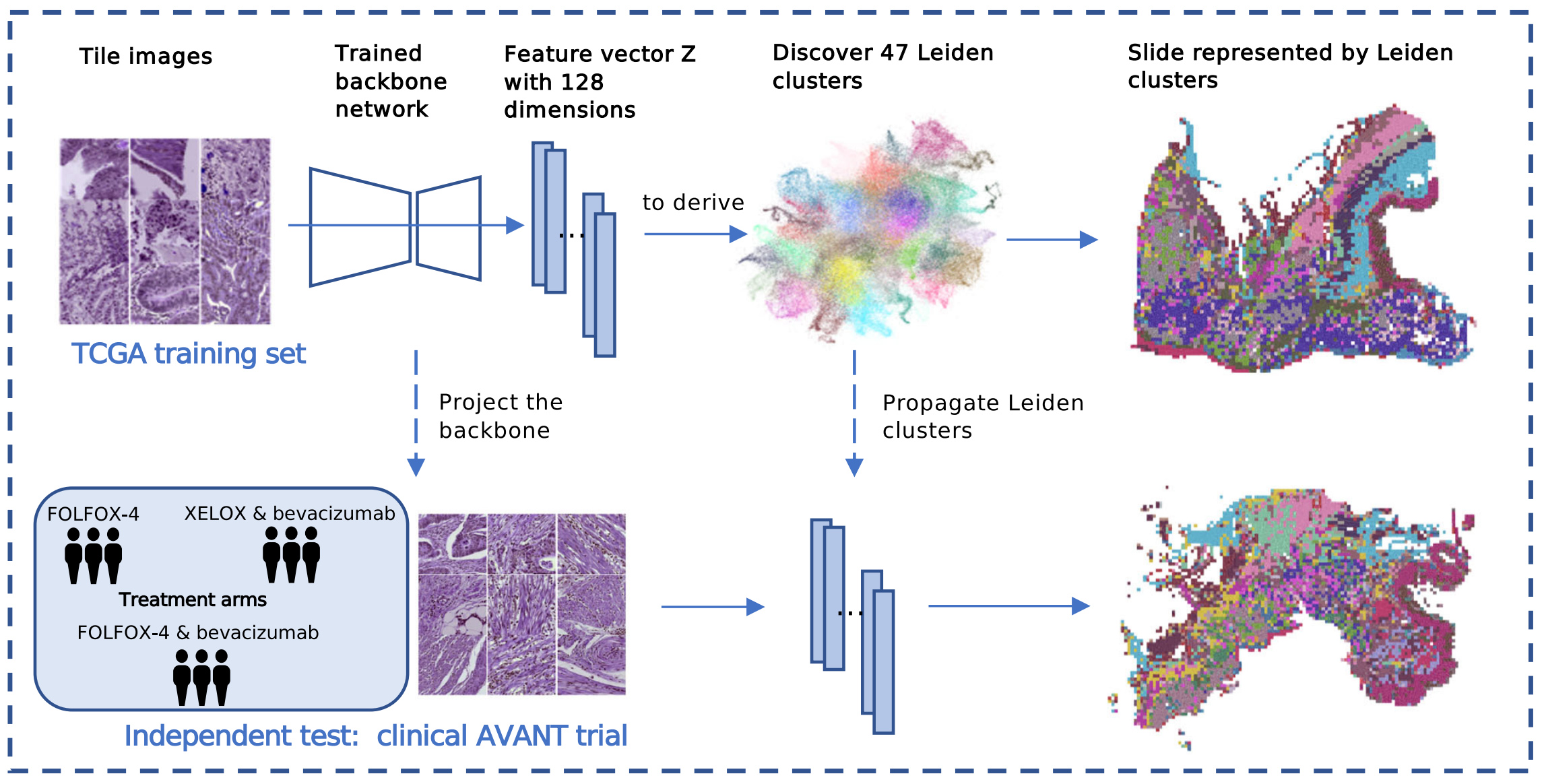
模型训练与聚类
- 以TCGA训练集的小块图像(Tile images)为输入,经训练好的骨干网络(Trained backbone network)处理,得到128维的特征向量Z(Feature vector Z with 128 dimensions)。
- 基于这些特征向量,通过算法推导发现47个Leiden簇(Discover 47 Leiden clusters) ,并将这些簇的信息传播回全玻片图像,得到用Leiden簇表示的全玻片图像(Slide represented by Leiden clusters) ,实现对组织形态学特征的聚类与可视化呈现。
独立测试验证
- 在AVANT临床试验独立测试集中,包含不同治疗组(如FOLFOX - 4、XELOX & bevacizumab、FOLFOX - 4 & bevacizumab )。
- 将测试集的小块图像通过已训练的骨干网络(Project the backbone),得到特征向量,再应用之前发现的Leiden簇信息,同样得到用Leiden簇表示的全玻片图像,以此验证模型在不同治疗组样本上的有效性和泛化能力 ,判断模型能否准确识别不同治疗组样本中的组织形态学特征。
- 该流程用于评估基于TCGA训练集训练的模型在外部临床样本中的表现,为模型的临床应用潜力提供依据。
2-3:组织形态表型簇(HPCs)展示
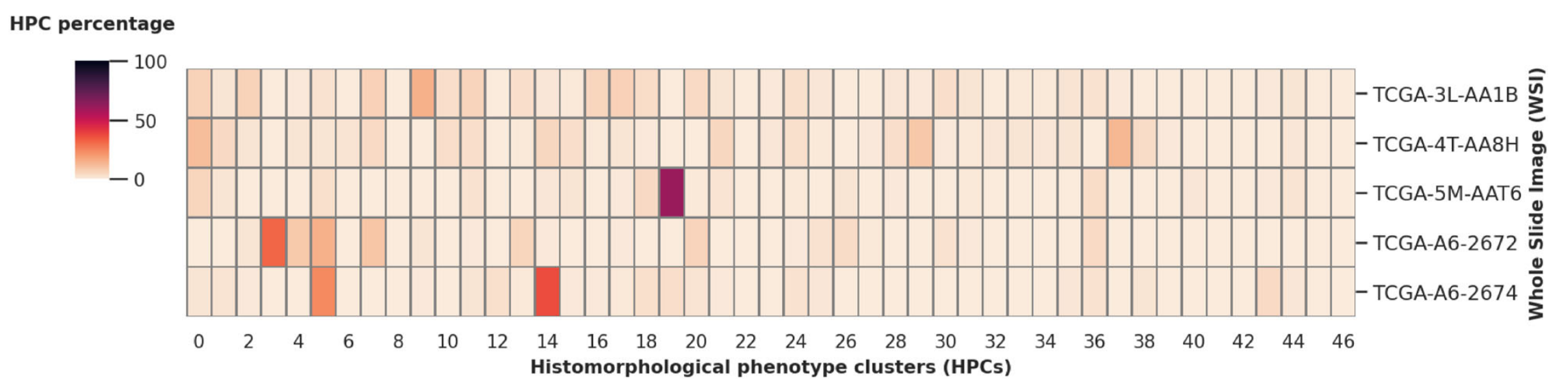
- 横轴:代表不同的组织形态表型簇(Histomorphological phenotype clusters, HPCs),从0到46编号,共47个HPCs 。
- 纵轴:是不同的全玻片图像样本,如TCGA - 3L - AA1B、TCGA - 4T - AA8H等 。
- 颜色:依据左侧颜色条,颜色从浅到深(从白色到深红色再到黑色),代表HPCs在相应全玻片图像中的占比从0%到100% 。比如在TCGA - 5M - AAT6样本中,有一个HPCs呈现较深颜色,说明该HPCs在这个样本中占比较高;而多数方格颜色较浅,意味着对应HPCs在相应样本中占比较低。
颜色深浅代表HPCs在相应全玻片图像中的占比,颜色越深表示占比越高,可直观比较不同样本中各类HPCs的比例差异。
三、利用人工智能辅助结肠癌诊疗的临床应用流程
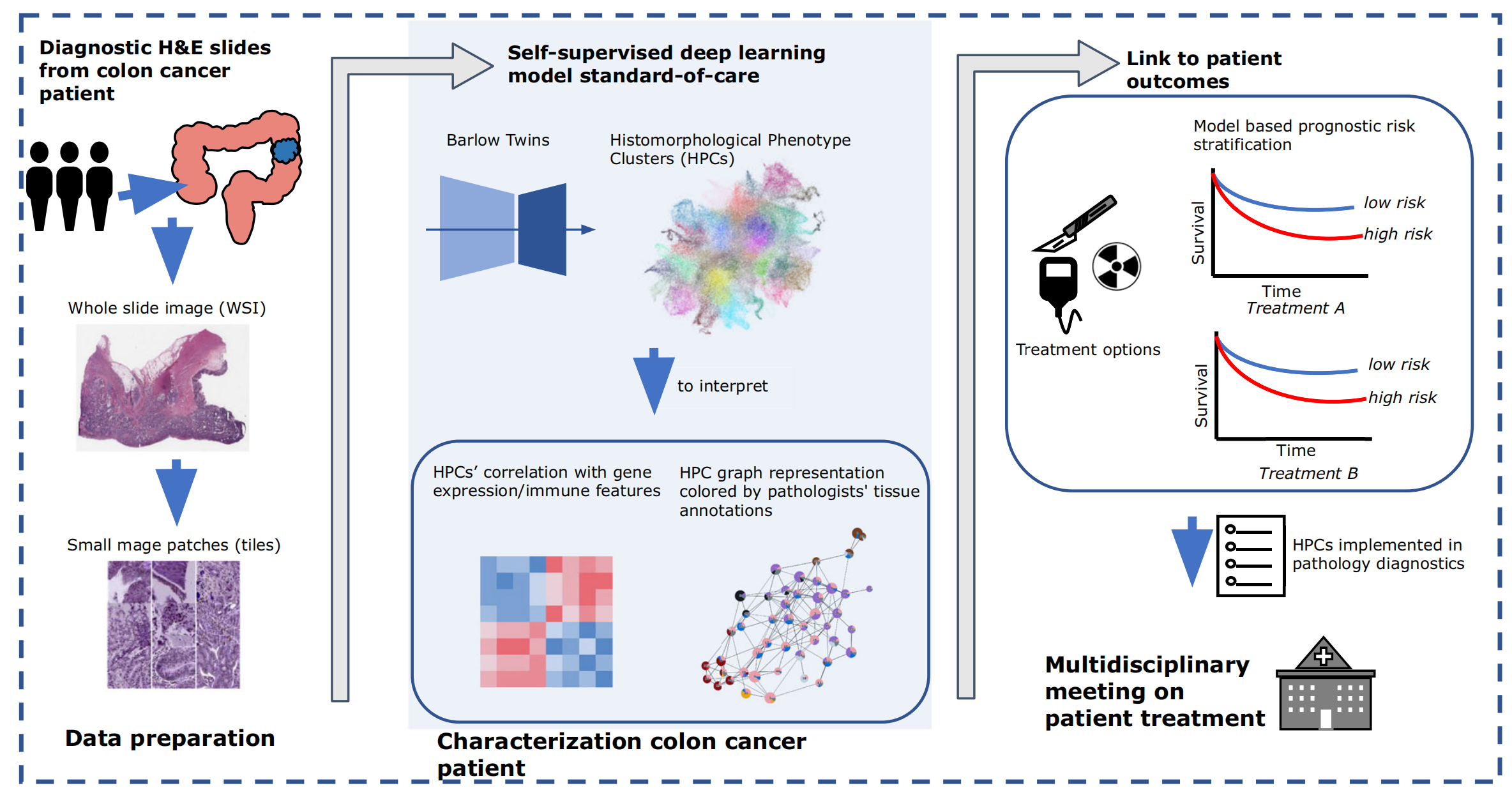
数据准备阶段
从结肠癌患者获取诊断用的苏木精 - 伊红(H&E)染色全玻片图像(WSI),并将其分割成小图像块(tiles),为后续分析提供基础数据 。
结肠癌特征分析阶段
- 运用自监督深度学习模型Barlow Twins处理小图像块,生成组织形态表型簇(HPCs) 。
- 探究HPCs与基因表达、免疫特征的关联,通过病理学家对组织的标注将HPCs图形化呈现,使其更便于理解和与组学数据关联 。
多学科诊疗决策阶段
- 依据HPCs构建预后风险模型,对患者进行风险分层,区分出低风险和高风险组,绘制不同治疗方案(Treatment A、Treatment B )下的生存曲线,直观展示不同风险组患者的生存情况 。
- 将HPCs融入病理诊断,在多学科诊疗会议上辅助肿瘤学家、病理学家等专业人员制定个性化治疗方案,助力精准医疗 。
该流程展示了从图像数据获取、特征分析挖掘到临床治疗决策支持的完整过程,体现了人工智能在结肠癌诊疗中辅助风险评估和个性化治疗的重要价值。
四、组织形态表型学习(HPL)系统框架
HPL能够在不需要专家注释或标签的情况下,自动发现病理切片中有区分性的图像特征。
该系统通过对图像图块进行聚类,识别形态学相似的组织区域,创建一个可与组织学、分子和临床表型相关联的组织形态表型库。
4-1:系统架构
HPL采用模块化设计,具有不同的组件,可对全玻片图像(WSI)的数据进行各个阶段的分析处理。
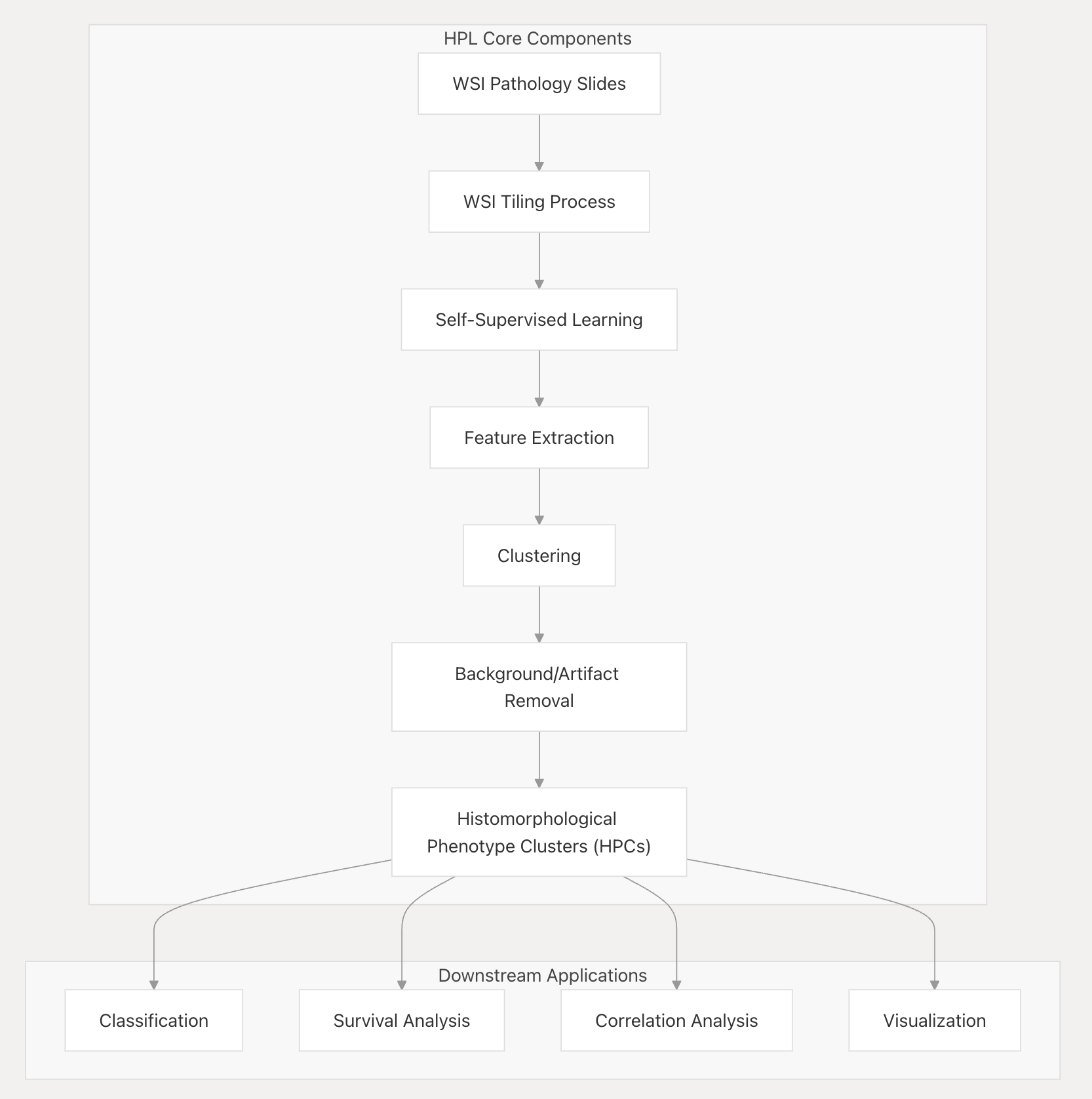
- WSI Pathology Slides(全玻片病理切片):这是系统处理的原始数据来源 ,是组织病理学分析的基础。
- WSI Tiling Process(WSI分块处理):将大型的全玻片图像分割成固定大小(文中为224×224像素 )的图块,并存储为HDF5文件,为后续分析做准备。
- Self - Supervised Learning(自监督学习):采用Barlow Twins等自监督学习方法,从未标记的组织学图块中学习有意义的表示,提取能反映重要形态学特征的信息。
- Feature Extraction(特征提取):利用训练好的自监督模型,从所有图像图块中提取特征向量,这些向量捕获每个组织区域的基本形态学属性,如得到维度为128的潜在表示。
- Clustering(聚类):使用Leiden聚类算法,对提取的特征向量进行分组,将具有相似形态学特征的图块聚为一类,形成组织形态表型簇(HPCs)。
- Background/Artifact Removal(背景/伪影去除):识别并剔除分析中包含的背景和伪影图块,确保HPCs代表真实的生物结构。
- Histomorphological Phenotype Clusters (HPCs)(组织形态表型簇 ):经过前面步骤得到的聚类结果,是后续分析的关键数据集合。
- Downstream Applications(下游应用) :
- Classification(分类):例如利用逻辑回归对肺癌亚型进行分类,以HPCs作为特征。
- Survival Analysis(生存分析):借助Cox比例风险模型,将HPCs作为预后标志物来预测患者预后情况。
- Correlation Analysis(相关性分析):通过统计相关性分析,将HPCs与分子和临床表型建立关联。
- Visualization(可视化):运用UMAP等技术,通过交互式可视化工具实现聚类可视化以及WSI叠加展示等。
4-2:数据流
- Raw WSIs(原始全玻片图像):作为起始数据,是未经处理的全玻片组织病理学图像。
- Tiled Images (H5)(分块图像,存储为H5格式) :通过WSI Tiling Process(WSI分块处理),将原始全玻片图像分割成固定大小图块,并以HDF5(H5)文件格式存储 ,便于后续分析处理。
- Self - Supervised Model(自监督模型) :采用自监督学习方法(如Barlow Twins ),对分块图像进行学习,目的是从未标记数据中提取有意义的特征表示。
- Feature Vectors (H5)(特征向量,存储为H5格式) :自监督模型训练完成后,从分块图像中提取出特征向量,这些向量捕获图像的形态学特征,并以H5文件格式存储。
- Combined Feature Set (H5)(组合特征集,存储为H5格式) :将提取的特征向量整合形成组合特征集,依然存储为H5文件格式,为后续聚类分析提供数据基础。
- Leiden Clustering(莱顿聚类) :运用莱顿聚类算法对组合特征集进行聚类操作,将具有相似形态学特征的图块归为一类,形成组织形态表型簇(HPCs )。
- Filtered HPCs(过滤后的组织形态表型簇) :通过背景和伪影去除步骤,对聚类得到的HPCs进行筛选,剔除包含背景和伪影的图块,使HPCs更能代表真实生物结构。
- Downstream Analysis(下游分析) :基于过滤后的HPCs开展各类下游分析,如肺癌亚型分类、生存分析、相关性分析以及可视化展示等,挖掘组织病理学图像中蕴含的临床相关信息。
4-3:关键组件
全玻片图像分块处理
分块处理将大型全玻片图像分割成较小的224×224像素图块,并将其存储在HDF5(H5)文件中。这一初始数据处理步骤为所有后续分析奠定了基础。
| 组件 | 用途 | 输出 |
|---|---|---|
| WSI分块 | 将全玻片图像分割为固定大小的图块 | 包含图像和元数据的H5文件 |
自监督学习
HPL采用自监督学习方法Barlow Twins,从未标记的组织学图块中学习有意义的表示。
该模型经过训练,可在无监督的情况下提取捕获重要形态学特征的特征。
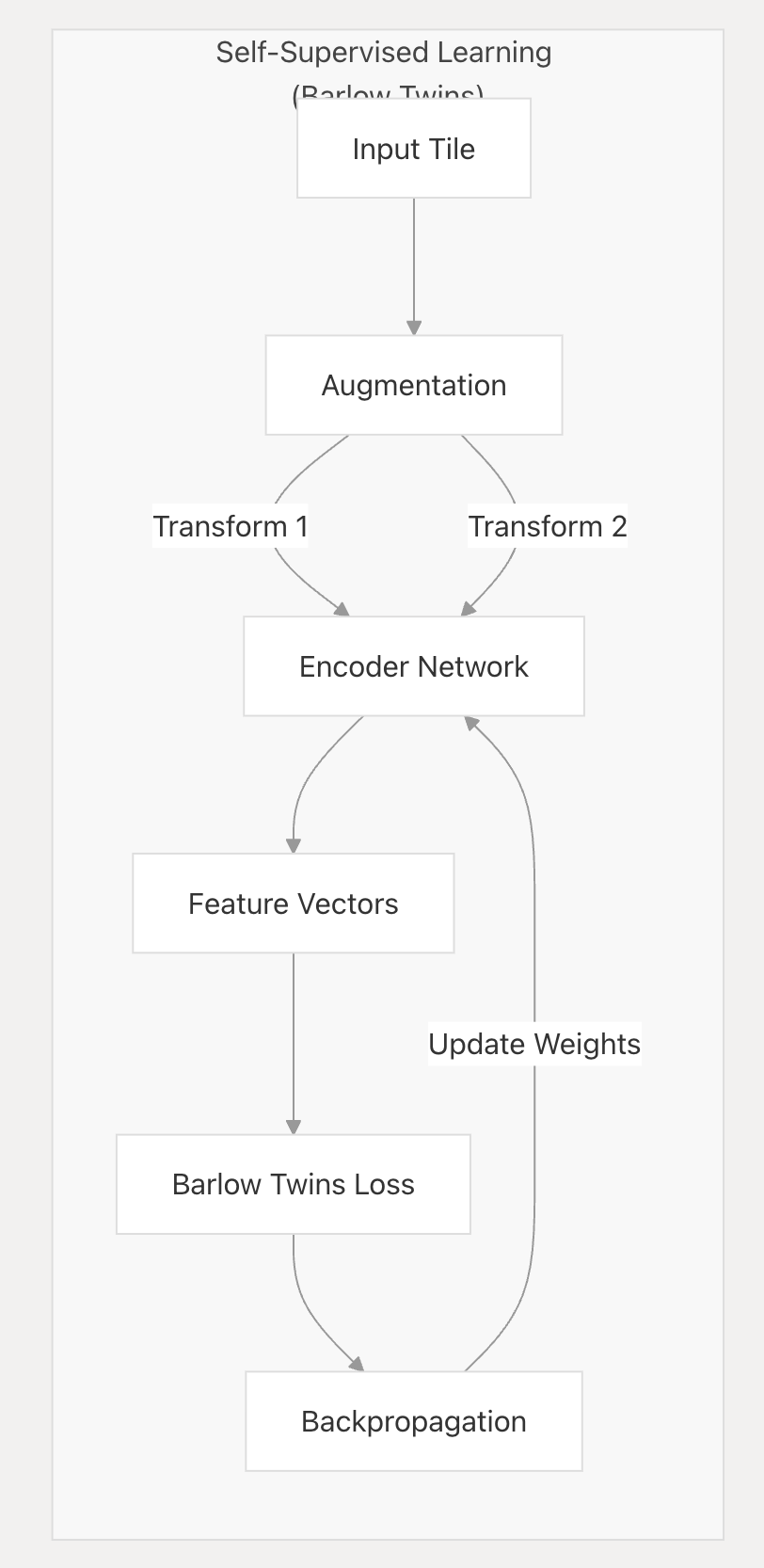
特征提取
训练后,自监督模型用于从所有图像图块中提取特征向量。这些特征向量捕获每个组织区域的基本形态学特征。
| 特征类型 | 维度 | 来源 |
|---|---|---|
| 潜在表示 | 128 | 模型编码器输出 |
莱顿聚类
特征向量使用莱顿聚类(一种用于网络社区检测的算法)进行分组。此过程识别具有相似形态学特征的图块,并将其分组为组织形态表型簇(HPC)。
背景去除
识别背景和伪影图块并将其从分析中移除,以确保HPC代表真实的生物结构。

下游应用
识别出的HPC支持各种下游分析:
| 应用 | 描述 | 实现方式 |
|---|---|---|
| 分类 | 使用逻辑回归进行肺癌亚型分类 | 以HPC为特征 |
| 生存分析 | 使用Cox比例风险模型预测患者预后 | 以HPC为预后标志物 |
| 相关性分析 | 将HPC与分子和临床表型相关联 | 统计相关性分析 |
| 可视化 | UMAP、聚类可视化和WSI叠加 | 交互式可视化工具 |
4-4:系统集成
HPL系统通过基于文件的工作流程集成各种计算组件。每个步骤产生的输出将作为后续步骤的输入。
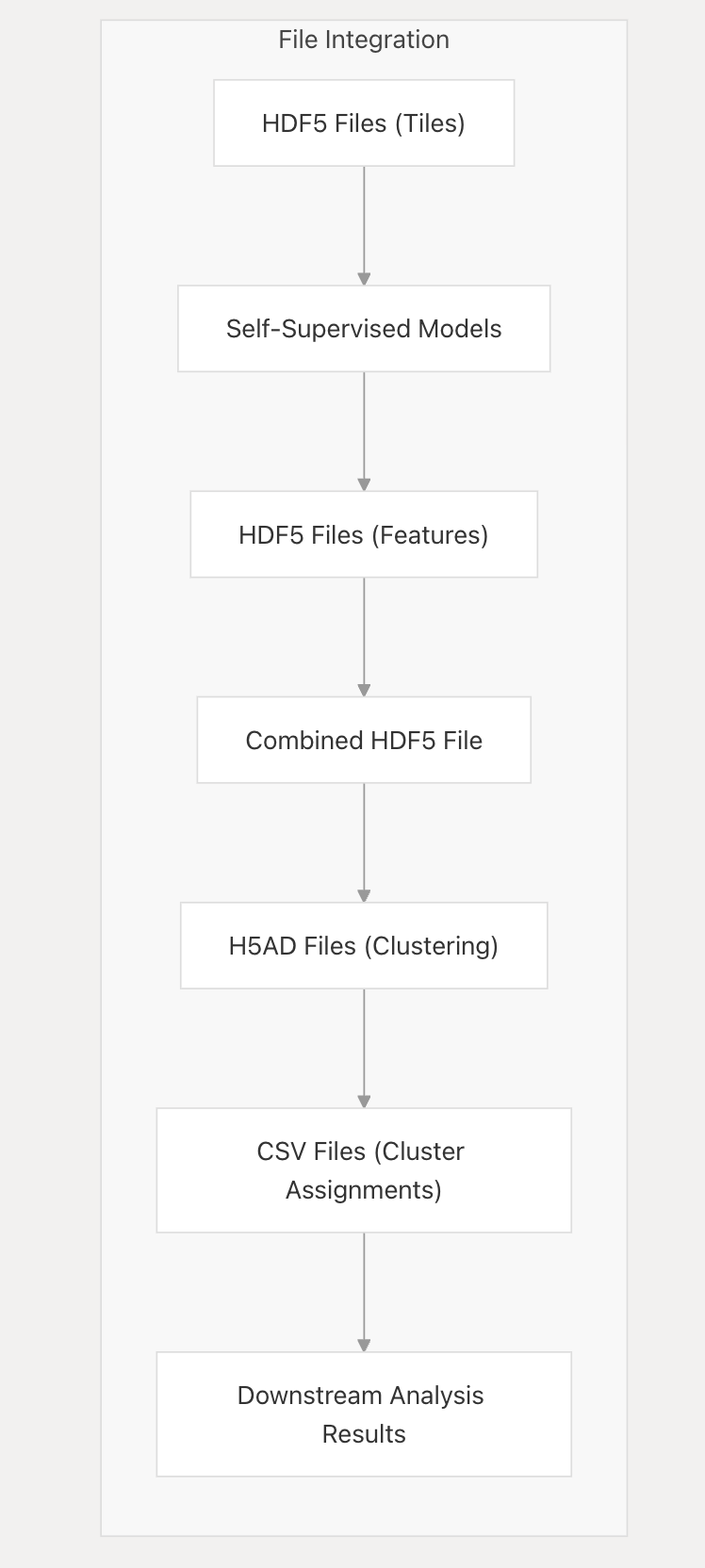
4-5:目录结构
HPL使用标准化的目录结构来组织数据、模型和结果:
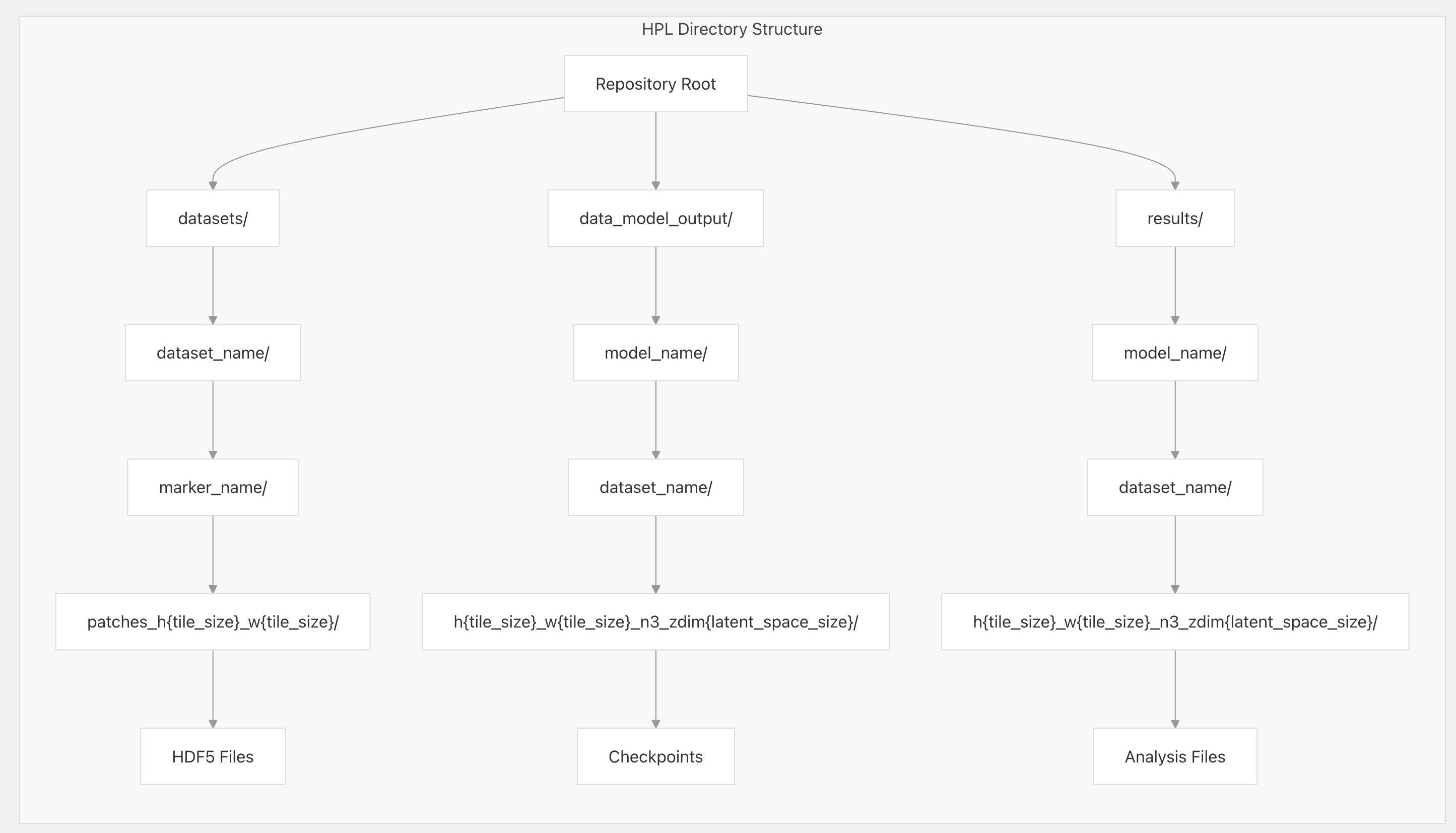
Repository Root(仓库根目录)
作为整个项目的根目录,是所有文件和子目录的起始位置 。
datasets/(数据集目录)
- dataset_name/(数据集名称子目录) :可根据不同的数据集命名创建子目录,用于区分存储不同来源或不同类型的数据集。
- marker_name/(标记名称子目录) :在特定数据集下,依据不同标记(如不同生物标志物 )进一步细分目录。
- patches_h{tile_size}_w{tile_size}/(图块尺寸相关子目录) :按照图块的高度和宽度尺寸创建子目录,用于存放与特定尺寸图块相关的数据 。
- HDF5 Files(HDF5文件) :最终在该层级目录下存储HDF5格式文件,通常是存储分块后的图像数据等。
data_model_output/(数据模型输出目录)
- model_name/(模型名称子目录) :以不同模型命名创建子目录,用于隔离不同模型的输出结果。
- dataset_name/(数据集名称子目录) :针对特定模型,再依据使用的数据集进行细分。
- h{tile_size}_w{tile_size}_n3_zdim{latent_space_size}/(参数相关子目录) :依据图块尺寸、潜在空间维度等模型参数创建子目录 。
- Checkpoints(检查点文件) :用于保存模型训练过程中的检查点文件,方便模型的恢复和继续训练。
results/(结果目录)
- model_name/(模型名称子目录) :按模型名称分类,存放不同模型产生的结果文件。
- dataset_name/(数据集名称子目录) :在特定模型下,依据数据集进一步分类。
- h{tile_size}_w{tile_size}_n3_zdim{latent_space_size}/(参数相关子目录) :根据图块尺寸、潜在空间维度等参数细分目录。
- Analysis Files(分析文件) :存储经过下游分析(如聚类分析、分类分析等 )后产生的结果文件。
4-6:HDF5文件结构
HDF5文件是HPL工作流程的核心,并遵循标准化结构:
| 数据集名称 | 内容 | 维度 |
|---|---|---|
{set}_img | 图块图像 | [n_samples, height, width, channels] |
{set}_tiles | 图块坐标 | [n_samples, 2] |
{set}_slides | 玻片标识符 | [n_samples, 1] |
{set}_samples | 患者标识符 | [n_samples, 1] |
{set}_z_latent | 特征向量 | [n_samples, latent_dim] |
{set}_h_latent | 隐藏表示 | [n_samples, hidden_dim] |
4-7:核心技术
HPL依赖于多种关键技术和库:
| 技术 | 用途 | 版本 |
|---|---|---|
| TensorFlow | 深度学习框架 | 1.15 |
| Scanpy | 单细胞分析工具(用于聚类) | 1.7-1.8 |
| UMAP | 降维 | 0.5.0 |
| h5py | HDF5文件处理 | 3.4.0 |
| Lifelines | 生存分析 | 0.26.3 |
| scikit-learn | 机器学习实用工具 | 0.24.0 |
4-8:代码架构
HPL代码库被组织成多个模块,处理工作流程的不同方面:

Main Scripts(主脚本)
是代码的核心执行入口,包含多个主要的Python脚本:
- run_representationspathology.py:用于运行与组织病理学图像特征表示相关的核心流程,涉及从原始图像数据提取特征等操作。
- run_representationspathology_projection.py:负责将提取的组织病理学图像特征进行投影变换等处理,与降维或特征空间转换有关。
- run_representationsleiden.py:和Leiden聚类算法相关,用于执行聚类操作,将图像特征向量进行聚类分组。
- report_representationsleiden_lr.py:基于Leiden聚类结果,使用逻辑回归(LR)进行分析并生成报告的脚本,比如用于肺癌亚型分类报告。
- report_representationsleiden_cox.py:基于Leiden聚类结果,使用Cox比例风险模型进行生存分析并生成报告的脚本。
Utility Modules(实用模块)
提供各类辅助功能,包含以下子模块:
- data_manipulation/ :专注于数据处理操作,如数据读取、清洗、预处理等,为其他脚本提供数据相关支持。
- models/ :存放与模型相关的代码,包括自监督学习模型(如Barlow Twins )等的定义、训练和配置等代码。
- utilities/ :包含各种通用工具函数,如文件读写工具、日志记录工具、参数配置工具等,辅助主脚本和其他模块运行。
结束语
本期推文的内容就到这里啦,如果需要获取医学AI领域的最新发展动态,请关注小罗的推送!如需进一步深入研究,获取相关资料,欢迎加入我的知识星球!