通过强化学习让大模型自适应开启思考模式
论文标题
AdaptThink: Reasoning Models Can Learn When to Think
论文地址
https://arxiv.org/pdf/2505.13417
代码地址
https://github.com/THU-KEG/AdaptThink
作者背景
清华大学
动机
思考模式提高了大模型处理复杂问题的能力,但最近有不少工作报告了许多简单任务上,繁琐的思考不仅开销更大,反而还可能降低回答准确性。于是有人利用空或简单的思考标签,将思考模型改造成了非思考模型,提高了简单任务上的准确率
<think> Okay, I think I have finished thinking. </think>
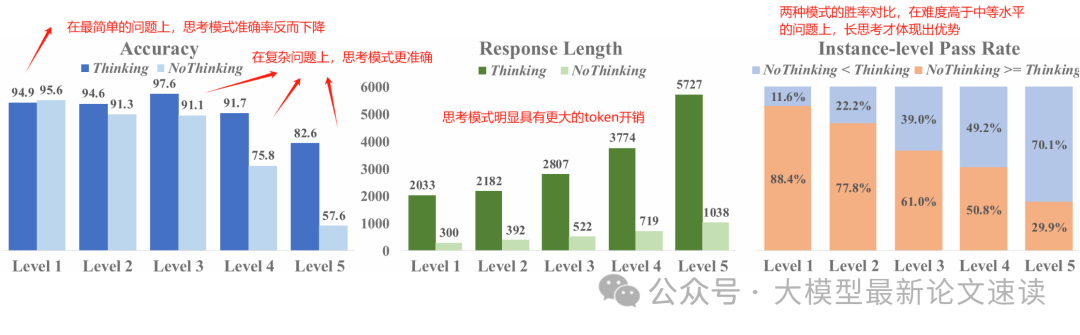
于是我们很自然地想到,可以动态控制大模型的思考长度,从而更高效地应对不同难度的问题。之前也介绍过一些相关的工作,但都是通过超参数或规则来改变思维链,而本文旨在让大模型学会自行判断启用何种思考模式,以达到最优的性能与效率
Uncert-CoT: 计算不确定性判断是否启用CoT
如何精准控制大模型的推理深度
本文方法
本文提出AdaptThink,核心思想是让推理模型能够根据问题的难度自适应地选择“Thinking”(思考)或“NoThinking”(不思考)的回答模式
一、优化目标
考虑到在推理效率上,无思考模式相较于有思考模式有着显著的优势,一个理想的选择策略应该在整体性能不下降的情况下,倾向于选择无思考模式。具体地,使用无KL项的PPO风格优化目标:
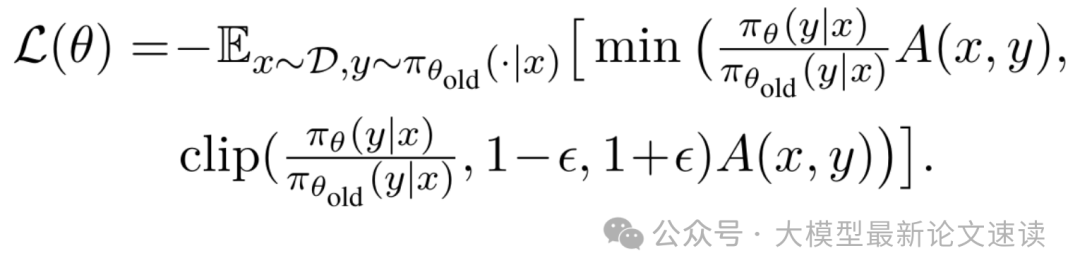
其中,clip是裁剪函数,用于提高训练流程的稳定性;A(x, y)是优势函数:
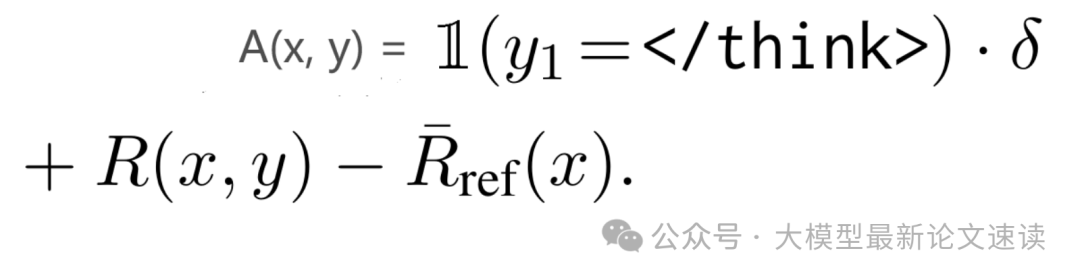
- 1(y1=)是一个指示函数,当y为非思考模式开头时为1,思考模式下则为0
- δ是超参数,用于控制非思考模式的优势程度
- R(x,y) 是奖励函数,表示回答准确性
- R_bar_ref(x)是参考模型平均奖励,用于对策略模型奖励分数的归一化
二、重要性采样
由于我们是在推理模型上进行对齐训练,初始阶段模型响应都是思考模式的结果,所以使用了重要性采样技术。定义一个新分布:
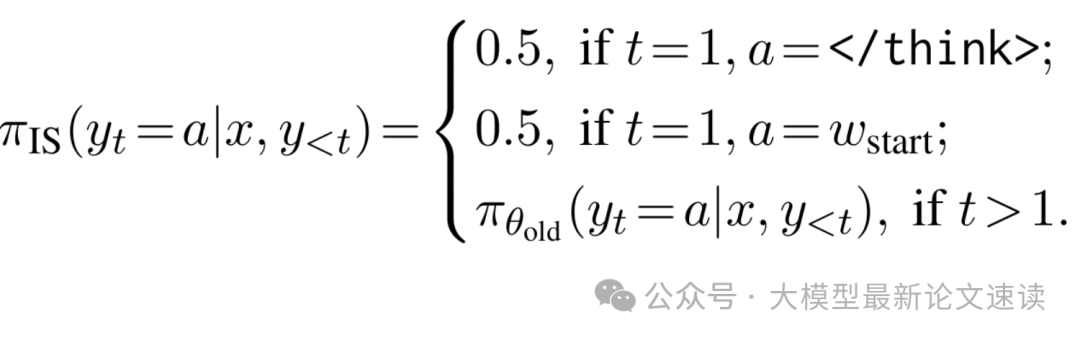
在t=1的冷启动阶段,我们强制让模型推理的第一个token为或W_start,前者是类似于之前介绍的NoThinking方法(通过空的思考标签让模型跳过思考),后者是一个常用于开启长思考的单词(例如 Alright)
当冷启动结束 t>1 时,则回归原始模型的采样
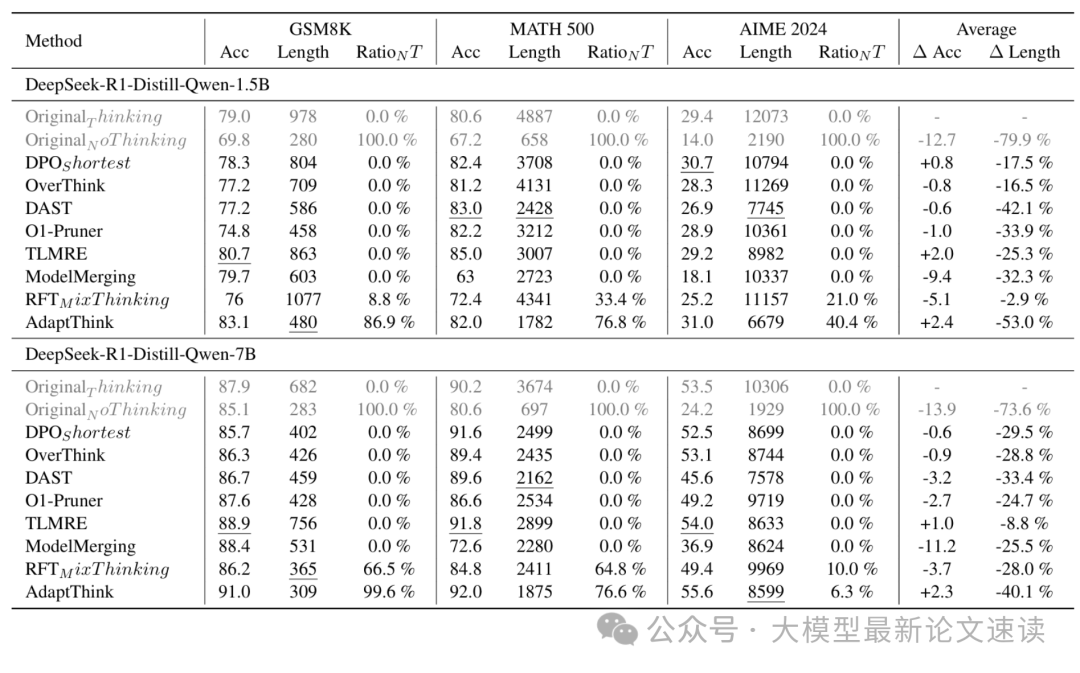
实验结果
作者在1.5B和7B的R1-distill-Qwen模型上进行了实验,结果表明在3种数学题基准上,AdaptThink 显著减少了推理成本,同时进一步提高了模型的准确性