MySQL基础关键_014_MySQL 练习题
目 录
一、有以下表,请用一条 SQL 语句查询出每门课程都大于 80 分的学生
二、综合题1(数据自行模拟)
1.查询身份证号为“440401430103082”的申请日期
2.查询同一个身份证号有两条及以上记录的身份证号码及记录个数
3.将身份证号码为“440401430103082”的记录在两个表中的申请状态均改为“07”
4.删除“g_cardapplydetail”表中所有姓“宋”的记录
三、 综合题2
1.统计不及格(0~59)、良好(60~80)、优秀(80~100)的课程数
2. 计算每科都及格者的平均成绩
四、 综合题3(数据自行模拟)
1.请用一条SQL语句查询不同部门中担任“钳工”的职工平均工资
2.请用一条SQL语句查询不同部门中担任“钳工”的职工平均工资高于2000的部门
五、综合题4(数据自行模拟)
1.查询所有居住地与工作的公司在同一城市的员工的姓名
2. 查询比“木易十三炼钢厂”所有员工收入都高的员工姓名
3.查询平均年薪在20000元以上的公司及其平均年薪
六、综合题5
1.查询每个客户的所有订单并按照地址排序,要求输出格式为:address client_name phone order_id
2.查询每个客户订购的图书总价,要求输出格式为:client_name total_price
3.如果要求每个订单可以包含多种图书,应该如何修改order表的主键?
4.为了保证每个订单只被一个客户拥有,应该在clientorder表上增加怎样的约束?
七、综合题6(数据自行模拟)
1.查询1号课比2号课成绩高的学生的学号
2.查询平均成绩大于60分的学号和平均成绩
3.查询所有学生的学号、姓名、选课数、总成绩
4.查询姓“李”的老师的个数
5.查询没选过“叶平”老师课的学号、姓名
八、 综合题7(数据自行模拟)
1.查询没有选修课程编号为C1的学生姓名
2.查询每门课程的名称和平均成绩,并按照成绩排序
3.选了2门课以上的学生姓名
九、补充1:行列互换
十、通过 SQL 语句得出表中结果
十一、补充2:窗口函数
十二、有一张表有如下数据,写出一条 SQL 将数字连续性和断点展现出来
一、有以下表,请用一条 SQL 语句查询出每门课程都大于 80 分的学生
| name | course | grade |
|---|---|---|
| 张筱筱 | 语文 | 81 |
| 张筱筱 | 数学 | 75 |
| 李政强 | 英语 | 90 |
# 初始化
drop table if exists t_student;
create table t_student(name varchar(255),course varchar(255),grade double(3,1)
);
insert into t_student values('张筱筱', '语文', 81);
insert into t_student values('张筱筱', '数学', 75);
insert into t_student values('李政强', '英语', 90);-- 1.查询成绩小于等于 80 的学生姓名
select distinct name from t_student where grade <= 80;-- sum.查询剩余学生
select distinct name from t_student where name not in(select distinct name from t_student where grade <= 80);
二、综合题1(数据自行模拟)
| 字段 | 说明 | 类型 | 长度 |
|---|---|---|---|
| g_applyno | 申请单号(关键字) | varchar | 8 |
| g_applydate | 申请日期 | bigint | 8 |
| g_state | 申请状态 | varchar | 2 |
| 字段 | 说明 | 类型 | 长度 |
|---|---|---|---|
| g_applyno | 申请单号(关键字) | varchar | 8 |
| g_stateg_name | 申请人姓名 | varchar | 8 |
| g_idcard | 申请人身份证号 | varchar | 30 |
| g_state | 申请状态 | varchar | 2 |
# 初始化(随机模拟)
drop table if exists g_cardapply;create table g_cardapply(g_applyno varchar(8) primary key,g_applydate bigint(8),g_state varchar(2)
);insert into g_cardapply values(1,20080808, '01');
insert into g_cardapply values(2,20221011, '01');
insert into g_cardapply values(3,20230323, '01');
insert into g_cardapply values(4,20071212, '02');
insert into g_cardapply values(5,20091211, '02');drop table if exists g_cardapplydetail;create table g_cardapplydetail(g_applyno varchar(8),g_name varchar(8),g_idcard varchar(30),g_state varchar(2)
);insert into g_cardapplydetail values('1','黄梓婷','440401430103082','01');
insert into g_cardapplydetail values('2','黄梓婷','440401430103082','01');
insert into g_cardapplydetail values('3','黄梓婷','440401430103082','01');
insert into g_cardapplydetail values('4','宋刚','440401430111111','02');
insert into g_cardapplydetail values('5','邱钰红','440401430122222','02');1.查询身份证号为“440401430103082”的申请日期
-- 1.查询对应的申请日期
select a.g_applydate from g_cardapply a join g_cardapplydetail b on a.g_applyno = b.g_applyno where b.g_idcard = '440401430103082';-- 2.转成日期格式(可选)
select str_to_date(cast(a.g_applydate as char), '%Y%m%d') from g_cardapply a join g_cardapplydetail b on a.g_applyno = b.g_applyno where b.g_idcard = '440401430103082';
2.查询同一个身份证号有两条及以上记录的身份证号码及记录个数
select g_idcard, count(*) from g_cardapplydetail group by g_idcard having count(*) >= 2;
3.将身份证号码为“440401430103082”的记录在两个表中的申请状态均改为“07”
update g_cardapply a join g_cardapplydetail b on a.g_applyno = b.g_applyno and b.g_idcard = '440401430103082' set a.g_state = '07', b.g_state = '07';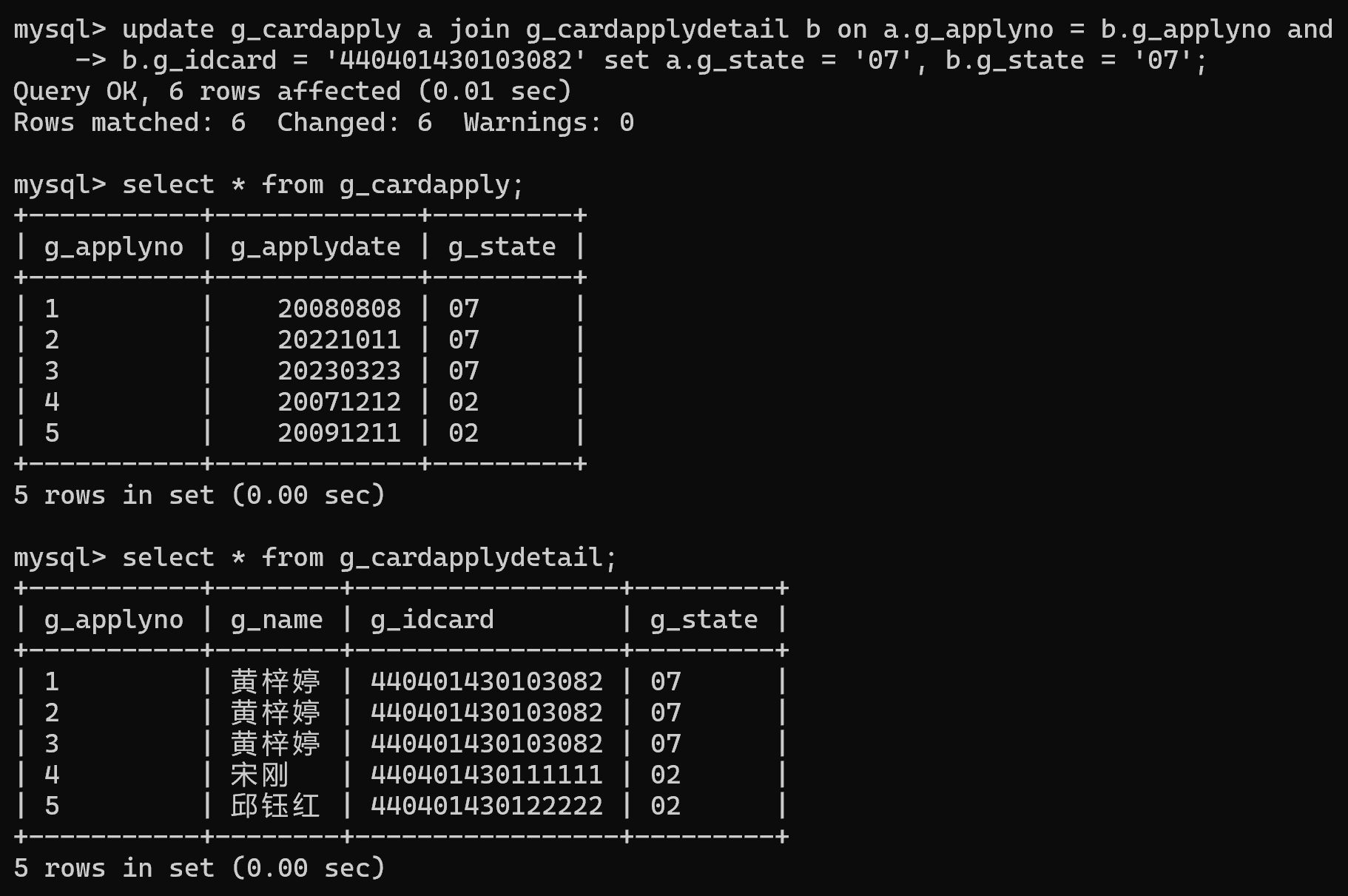
4.删除“g_cardapplydetail”表中所有姓“宋”的记录
delete a, b from g_cardapplydetail a join g_cardapply b on a.g_applyno = b.g_applyno where a.g_name like '宋%';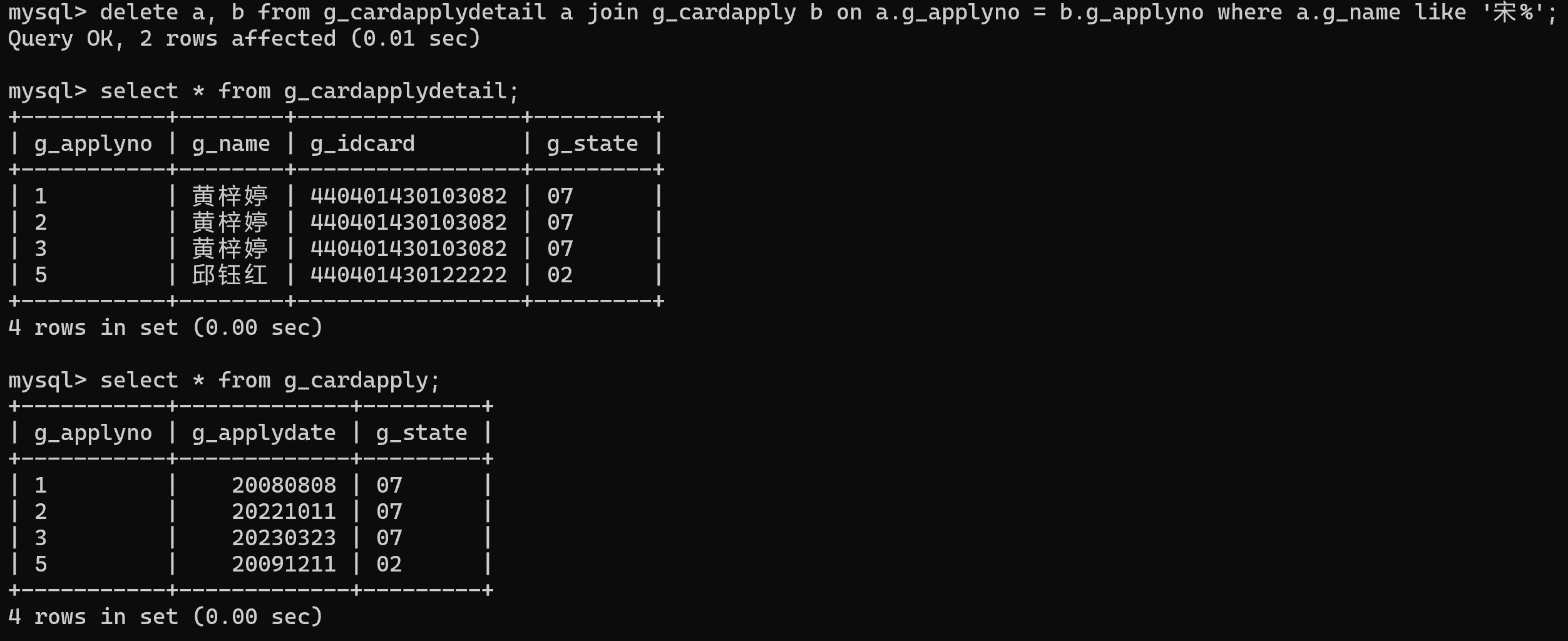
三、 综合题2
| name | subject | score | stuid |
|---|---|---|---|
| 秦世华 | 数学 | 89 | 1 |
| 秦世华 | 语文 | 80 | 1 |
| 秦世华 | 英语 | 70 | 1 |
| 张载 | 数学 | 90 | 2 |
| 张载 | 语文 | 70 | 2 |
| 张载 | 英语 | 80 | 2 |
# 初始化
drop table if exists stuscore;
create table stuscore(name varchar(255),subject varchar(255),score int,stuid int
);
insert into stuscore values('秦世华','数学',89,1);
insert into stuscore values('秦世华','语文',80,1);
insert into stuscore values('秦世华','英语',70,1);
insert into stuscore values('张载','数学',90,2);
insert into stuscore values('张载','语文',70,2);
insert into stuscore values('张载','英语',80,2);1.统计不及格(0~59)、良好(60~80)、优秀(80~100)的课程数
-- 方法一
# 1.分组
select case when score >= 0 and score < 60 then '不及格' when score >= 60 and score < 81 then '良好' when score >= 81 and score <= 100 then '优秀' else '错误' end as assess from stuscore;# 2.计数
select case when score >= 0 and score < 60 then '不及格' when score >= 60 and score < 81 then '良好' when score >= 81 and score <= 100 then '优秀' else '错误' end as assess, count(*)
from stuscore
group by assess;-- 方法二
# 1.不及格
select count(*) from stuscore where score between 0 and 59;# 2.良好
select count(*) from stuscore where score between 60 and 80;# 3.优秀
select count(*) from stuscore where score between 81 and 100;# 4.sum
select '不及格' as assess, count(*)
from stuscore
where score between 0 and 59
union all
select '良好', count(*)
from stuscore
where score between 60 and 80
union all
select '优秀', count(*)
from stuscore
where score between 81 and 100;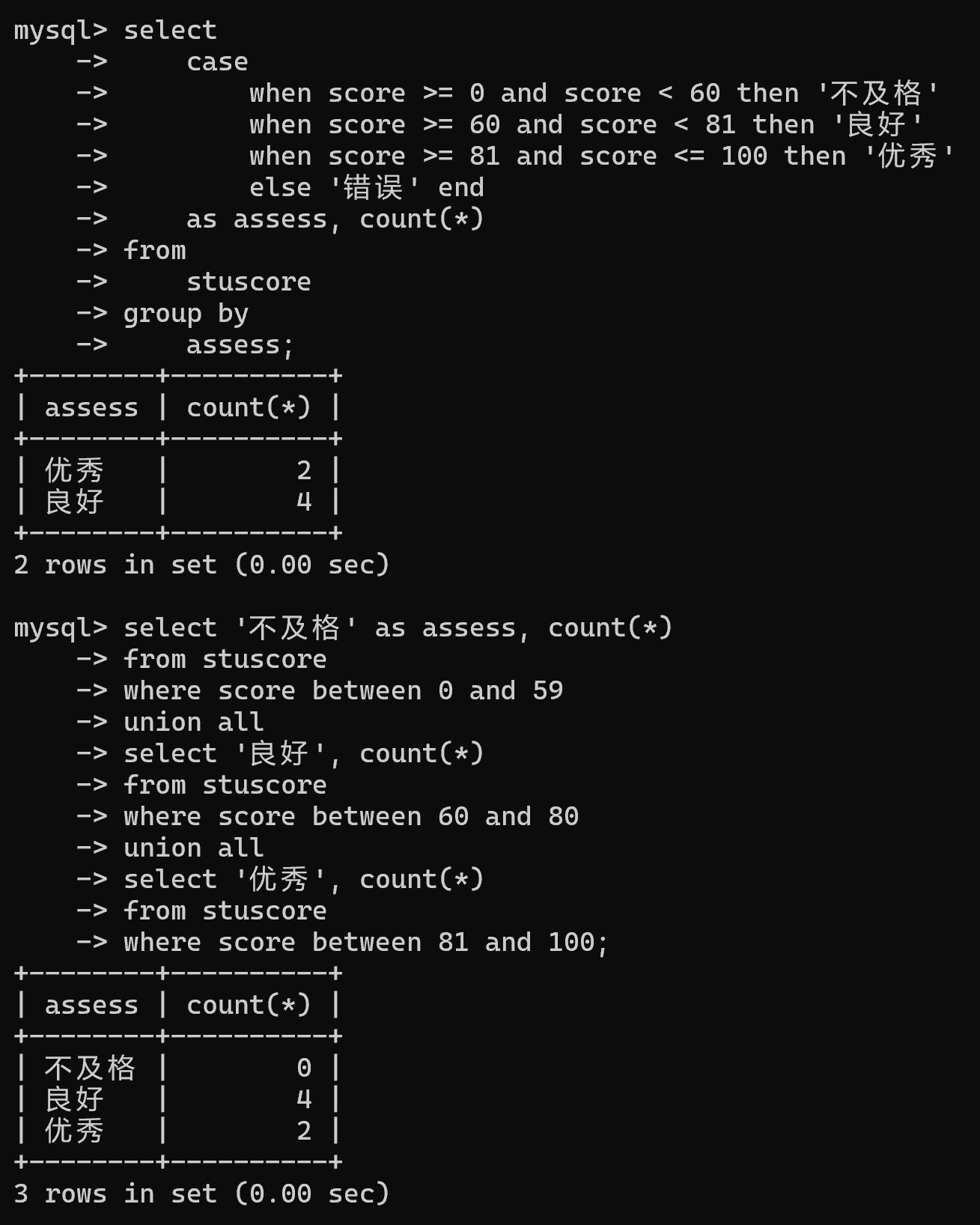
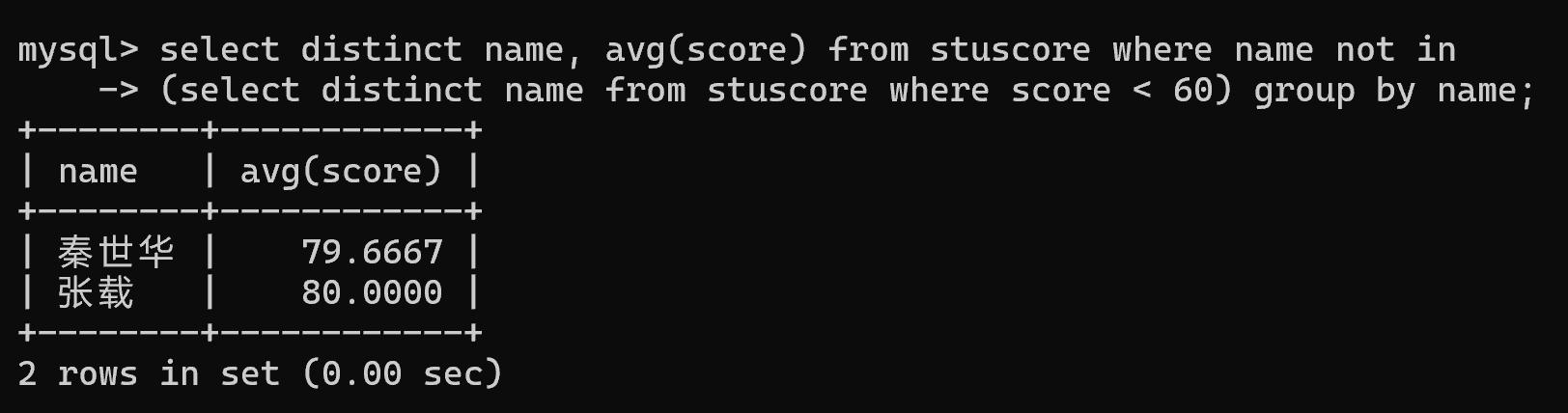
2. 计算每科都及格者的平均成绩
# 1.查询不及格者
select distinct name from stuscore where score < 60;# 2.查询每科都及格者
select distinct name, avg(score) from stuscore where name not in(select distinct name from stuscore where score < 60) group by name;
四、 综合题3(数据自行模拟)
有一个表 wcmemploy(工号、姓名、部门名、工种、薪资)。
# 初始化(自行模拟)
drop table if exists wcmemploy;create table wcmemploy(no int,name varchar(255),dname varchar(255),job varchar(255),sal double(10,2)
);insert into wcmemploy values(1, '柳芝芝', 'A', '钳工', 1500);
insert into wcmemploy values(2, '王岩明', 'A', '钳工', 2800);
insert into wcmemploy values(3, '冯刚', 'A', '油漆工', 3000);
insert into wcmemploy values(4, '赵龍', 'A', '水电工', 4500);
insert into wcmemploy values(5, '钱百道', 'B', '钳工', 1800);
insert into wcmemploy values(6, '毛自立', 'B', '钳工', 2600);
insert into wcmemploy values(7, '朱雯睿', 'B', '油漆工', 2800);
insert into wcmemploy values(8, '张怡然', 'B', '水电工', 5000);
insert into wcmemploy values(9, '孙苗', 'C', '油漆工', 6000);
insert into wcmemploy values(10, '黄山', 'C', '钳工', 2000);
insert into wcmemploy values(11, '韩小明', 'C', '水电工', 5000);
insert into wcmemploy values(12, '武政熙', 'C', '钳工', 2000);
insert into wcmemploy values(13, '阮雨薇', 'D', '水电工', 5000);
insert into wcmemploy values(14, '方则天', 'D', '油漆工', 2500);
insert into wcmemploy values(15, '李昂', 'D', '钳工', 3000);
insert into wcmemploy values(16, '佟建国', 'D', '钳工', 4000);
insert into wcmemploy values(17, '周章正', 'D', '钳工', 3300);1.请用一条SQL语句查询不同部门中担任“钳工”的职工平均工资
select dname, avg(sal) from wcmemploy where job = '钳工' group by dname;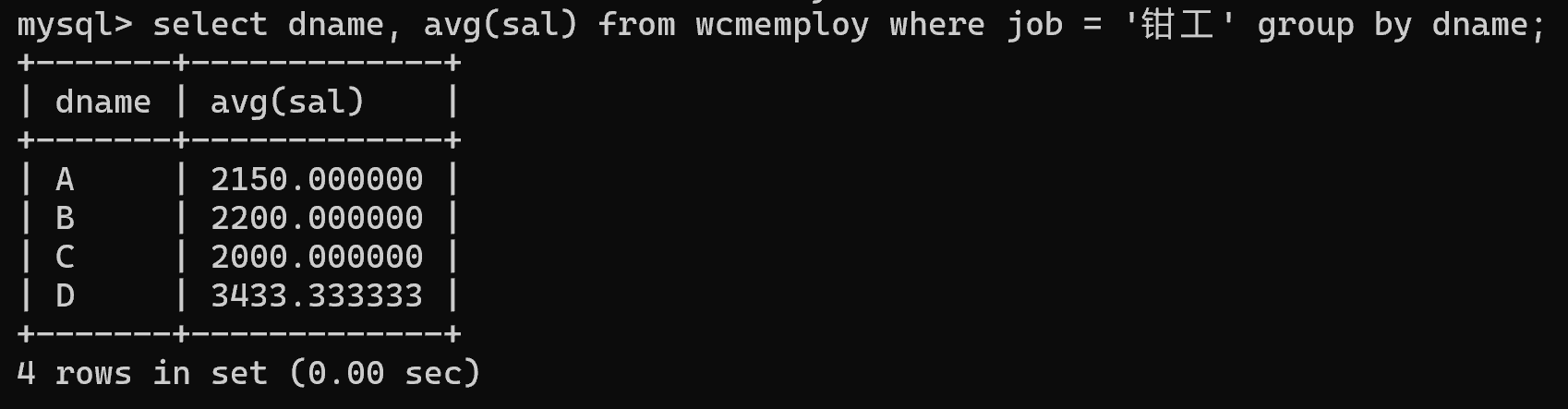
2.请用一条SQL语句查询不同部门中担任“钳工”的职工平均工资高于2000的部门
select dname, avg(sal) from wcmemploy where job = '钳工' group by dname having avg(sal) > 2000;
五、综合题4(数据自行模拟)
- employee是雇员信息表:
- 雇员姓名(主键):person_name;
- 街道:street;
- 城市:city。
- company是公司信息表:
- 公司名称(主键):company_name;
- 城市:city。
- works是雇员工作信息表:
- 雇员姓名(主键):person_name;
- 公司名称:company_name;
- 年薪:salary。
- manages是雇员工作关系表:
- 雇员姓名(主键):person_name;
- 经理姓名:manager_name。
# 初始化(数据自行模拟)
drop table if exists employee;
create table employee(`person_name` varchar(255) primary key,street varchar(255),city varchar(255)
);
insert into employee values('鲁班七号','街道1','天津');
insert into employee values('澜','街道2','天津');
insert into employee values('艾琳','街道3','天津');
insert into employee values('朵莉亚','街道4','天津');
insert into employee values('后羿','街道5','大同');
insert into employee values('妲己','街道6','北京');
insert into employee values('安琪拉','街道7','北京');
insert into employee values('刘禅','街道8','北京');
insert into employee values('蔡文姬','街道9','大同');
insert into employee values('曹操','街道10','大同');drop table if exists company;
create table company(`company_name` varchar(255) primary key,city varchar(255)
);
insert into company values('春华秋实咖啡后厨工厂', '北京');
insert into company values('御龙印刷厂', '大同');
insert into company values('木易十三炼钢厂', '天津');drop table if exists works;
create table works(`person_name` varchar(255) primary key,`company_name` varchar(255),salary double(10,2)
);
insert into works values('鲁班七号','春华秋实咖啡后厨工厂', 22000);
insert into works values('澜','春华秋实咖啡后厨工厂', 99999);
insert into works values('艾琳','春华秋实咖啡后厨工厂', 6000);
insert into works values('朵莉亚','春华秋实咖啡后厨工厂', 11000);
insert into works values('后羿','御龙印刷厂', 31000);
insert into works values('妲己','御龙印刷厂', 11000);
insert into works values('安琪拉','御龙印刷厂', 5000);
insert into works values('刘禅','御龙印刷厂', 8000);
insert into works values('蔡文姬','木易十三炼钢厂', 12000);
insert into works values('曹操','木易十三炼钢厂', 21000);drop table if exists manages;
create table manages(`person_name` varchar(255) primary key,`manager_name` varchar(255)
);
insert into manages values('鲁班七号','澜');
insert into manages values('澜','艾琳');
insert into manages values('艾琳','朵莉亚');
insert into manages values('朵莉亚','后羿');
insert into manages values('后羿','妲己');
insert into manages values('妲己','安琪拉');
insert into manages values('安琪拉','刘禅');
insert into manages values('刘禅','蔡文姬');
insert into manages values('蔡文姬','曹操');
insert into manages values('曹操',NULL);1.查询所有居住地与工作的公司在同一城市的员工的姓名
select w.person_name from works w join employee e on w.person_name = e.person_name join company c on w.company_name = c.company_name where e.city = c.city;
2. 查询比“木易十三炼钢厂”所有员工收入都高的员工姓名
-- 1.查找“木易十三炼钢厂”的最高薪资
select max(salary) from works where company_name = '木易十三炼钢厂';-- 2.查找高于该薪资的员工姓名
select person_name, salary from works where salary > (select max(salary) from works where company_name = '木易十三炼钢厂');
3.查询平均年薪在20000元以上的公司及其平均年薪
select company_name, avg(salary) as average_salary from works group by company_name having average_salary > 20000;

六、综合题5
以下是一个简化的书店订单管理系统,有四张表。
| client_id | client_name | phone | address |
|---|---|---|---|
| 1 | Zhao | 1981314520 | 海淀区 |
| 2 | Wang | 1365201314 | 朝阳区 |
| 3 | Sun | 1732513140 | 大兴区 |
| 4 | Li | 1913324567 | 东城区 |
| order_id | book_id |
|---|---|
| 11 | 21 |
| 12 | 22 |
| 13 | 23 |
| 14 | 24 |
| 15 | 21 |
| 16 | 22 |
| 17 | 23 |
| 18 | 24 |
| client_id | order_id |
|---|---|
| 1 | 11 |
| 1 | 12 |
| 2 | 13 |
| 2 | 14 |
| 3 | 15 |
| 3 | 16 |
| 4 | 17 |
| 4 | 18 |
| book_id | book_name | price |
|---|---|---|
| 21 | 管理学 | 30.00 |
| 22 | 计算机网络 | 50.00 |
| 23 | 国家地理杂志 | 90.00 |
| 24 | 西游记 | 20.00 |
# 初始化
drop table if exists client;
create table client(client_id int,client_name varchar(255),phone varchar(255),address varchar(255)
);
insert into client values(1,'Zhao', 1981314520, '海淀区');
insert into client values(2,'Wang', 1365201314, '朝阳区');
insert into client values(3,'Sun', 1732513140, '大兴区');
insert into client values(4,'Li', 1913324567, '东城区');drop table if exists `order`;
create table `order`(order_id int,book_id int
);
insert into `order` values(11,21);
insert into `order` values(12,22);
insert into `order` values(13,23);
insert into `order` values(14,24);
insert into `order` values(15,21);
insert into `order` values(16,22);
insert into `order` values(17,23);
insert into `order` values(18,24);drop table if exists clientorder;
create table clientorder(client_id int,order_id int
);
insert into clientorder values(1,11);
insert into clientorder values(1,12);
insert into clientorder values(2,13);
insert into clientorder values(2,14);
insert into clientorder values(3,15);
insert into clientorder values(3,16);
insert into clientorder values(4,17);
insert into clientorder values(4,18);drop table if exists book;
create table book(book_id int,book_name varchar(255),price double(10,2)
);
insert into book values(21, '管理学', 30);
insert into book values(22, '计算机网络', 50);
insert into book values(23, '国家地理杂志', 90);
insert into book values(24, '西游记', 20);1.查询每个客户的所有订单并按照地址排序,要求输出格式为:address client_name phone order_id
select c.address, c.client_name, c.phone, co.order_id from client c join clientorder co on c.client_id = co.client_id order by c.address;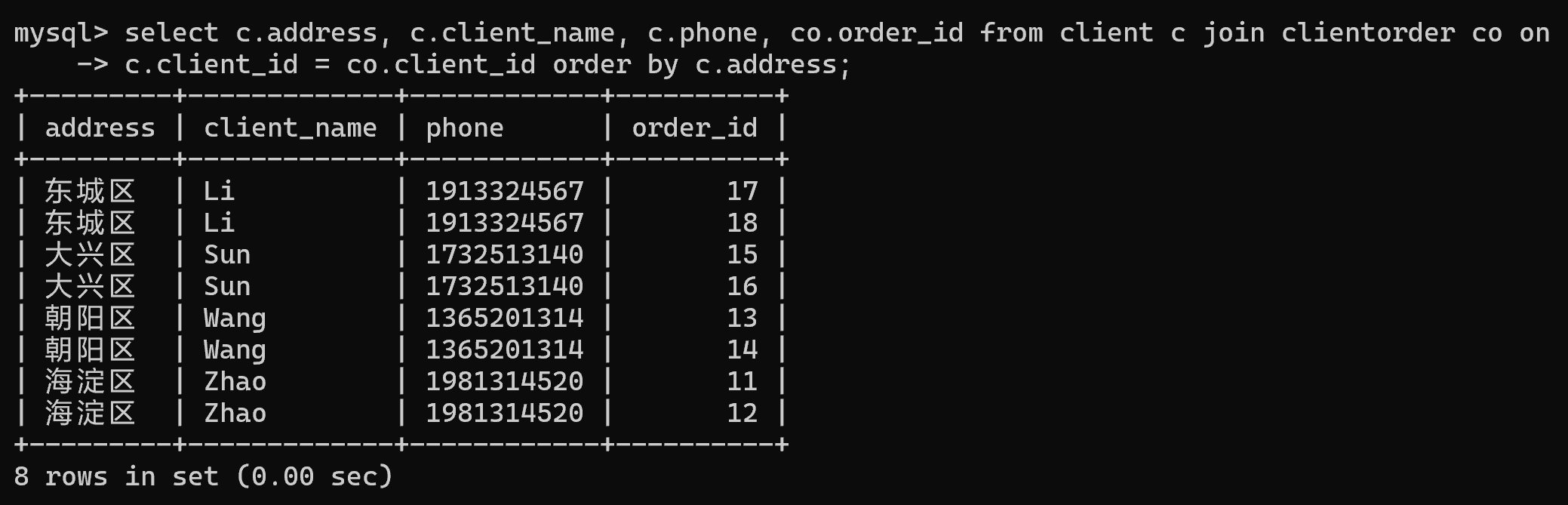
2.查询每个客户订购的图书总价,要求输出格式为:client_name total_price
-- 1.查询客户的所有订单
select c.client_name, co.order_id from client c join clientorder co on c.client_id = co.client_id;-- 2.查询客户购买的图书id
select c.client_name, co.order_id, o.book_id from client c join clientorder co on c.client_id = co.client_id join `order` o on co.order_id = o.order_id;-- 3.查询每个客户订购金额
select c.client_name, co.order_id, o.book_id, b.price from client c join clientorder co on c.client_id = co.client_id join `order` o on co.order_id = o.order_id join book b on o.book_id = b.book_id;-- 4.查询总额按照客户姓名分组
select c.client_name, sum(b.price) as total_price
from client c
join clientorder co
on c.client_id = co.client_id
join `order` o
on co.order_id = o.order_id
join book b
on o.book_id = b.book_id
group by c.client_name;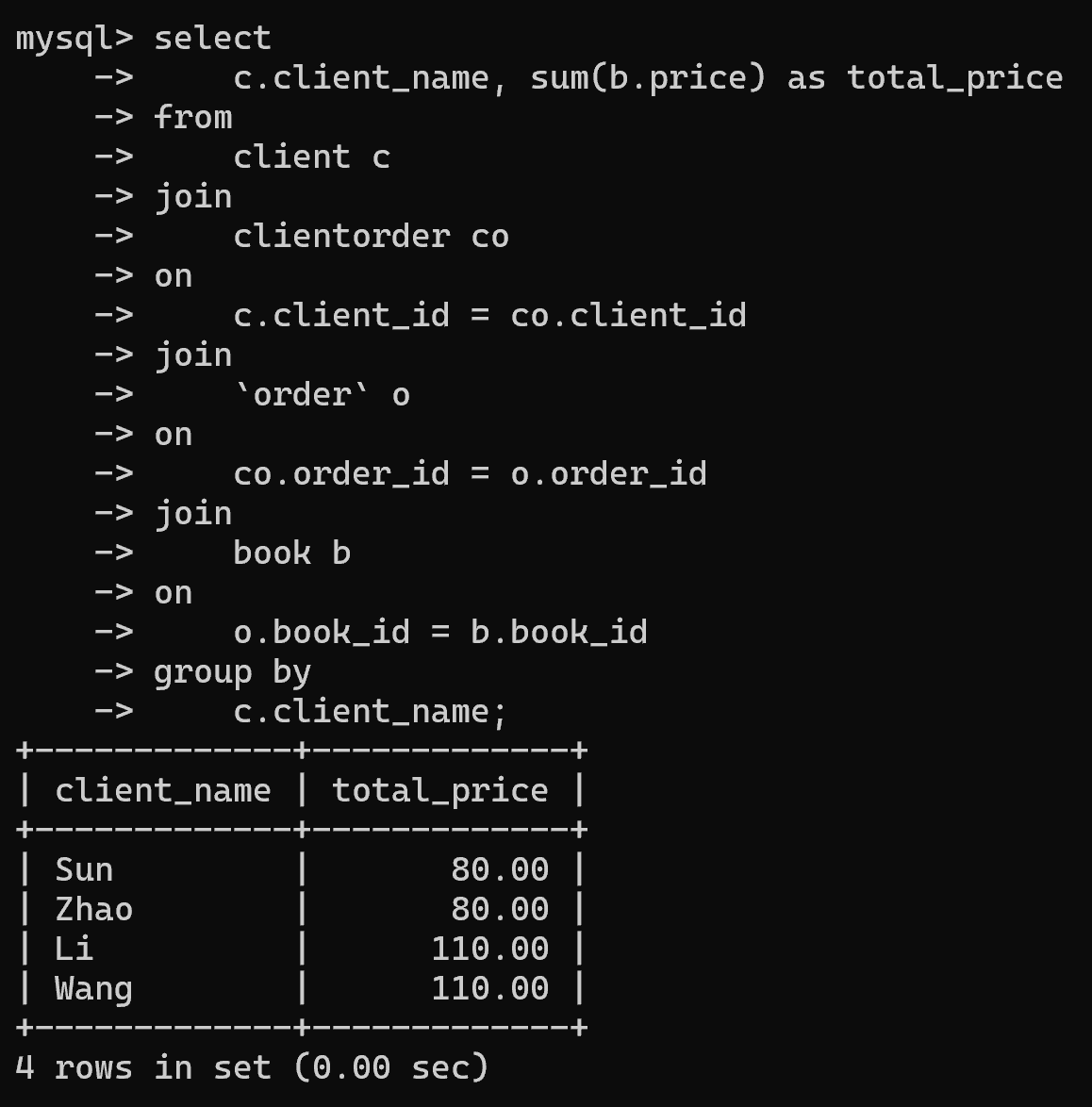
3.如果要求每个订单可以包含多种图书,应该如何修改order表的主键?
答:修改 order 表为联合主键,即将 order_id 字段和 book_id 字段都设置为主键。
4.为了保证每个订单只被一个客户拥有,应该在clientorder表上增加怎样的约束?
答:为 clientorder 表中的 order_id 字段添加唯一性约束即可。
七、综合题6(数据自行模拟)
- 学生表 student(s#:学号,sname:学生姓名,sage:学生年龄,ssex:学生性别);
- 课程表 course(c#:课程编号,cname:课程名称,t#:教师工号);
- 成绩表 sc(s#:学号,c#:课程编号,score:成绩);
- 教师表 teacher(t#:工号,tname:教师姓名)。
# 初始化(数据自行模拟)
drop table if exists student;
create table student(`s#` int,sname varchar(255),sage int,ssex char(1)
);
insert into student values(1,'学生1', 20, '男');
insert into student values(2,'学生2', 20, '男');
insert into student values(3,'学生3', 20, '男');
insert into student values(4,'学生4', 20, '男');drop table if exists course;
create table course(`c#` int,cname varchar(255),`t#` int
);
insert into course values(1,'数学',1);
insert into course values(2,'语文',1);
insert into course values(3,'英语',2);
insert into course values(4,'政治',2);drop table if exists sc;
create table sc(`s#` int,`c#` int,score int
);
insert into sc values(1,1,65);
insert into sc values(1,2,66);
insert into sc values(1,3,66);
insert into sc values(1,4,69);
insert into sc values(2,1,55);
insert into sc values(2,2,66);
insert into sc values(2,3,75);
insert into sc values(2,4,86);
insert into sc values(3,1,96);
insert into sc values(3,2,99);
insert into sc values(3,3,70);
insert into sc values(3,4,60);
insert into sc values(4,3,65);
insert into sc values(4,4,99);;drop table if exists teacher;
create table teacher(`t#` int,tname varchar(255)
);
insert into teacher values(1,'叶平');
insert into teacher values(2,'李白');1.查询1号课比2号课成绩高的学生的学号
-- 1.查询所有2号课成绩
select * from sc where `c#` = 2;-- 2.查询所有1号课成绩
select * from sc where `c#` = 1;-- 3.查询1号课成绩高于2号课最高成绩的学生学号
select a.`s#` from (select * from sc where `c#` = 2) a join (select * from sc where `c#` = 1) b on a.`s#` = b.`s#` where b.score > a.score;
2.查询平均成绩大于60分的学号和平均成绩
select `s#`, avg(score) from sc group by `s#` having avg(score) > 60;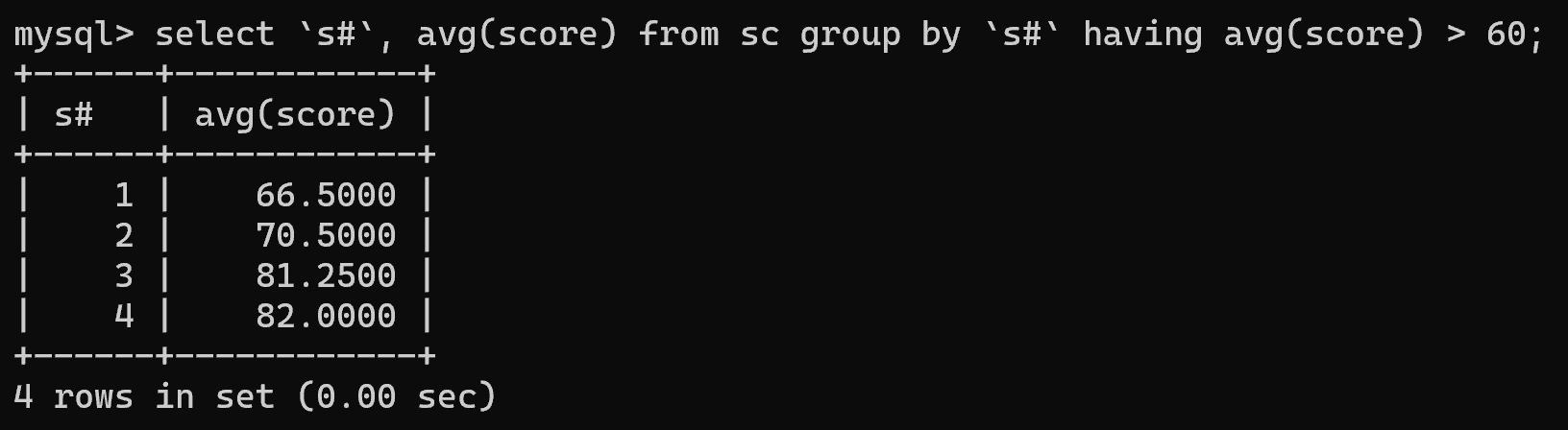
3.查询所有学生的学号、姓名、选课数、总成绩
-- 1.查询每个学生选课数、平均成绩
select `s#`, count(`c#`) as course_count, sum(score) as sum_score from sc group by `s#`;-- 2.查询学生学号、姓名、选课数、平均成绩
select s.`s#`, s.sname, a.course_count, a.sum_score
from (select `s#`, count(`c#`) as course_count, sum(score) as sum_score from sc group by `s#`) a
join student s
on s.`s#` = a.`s#`;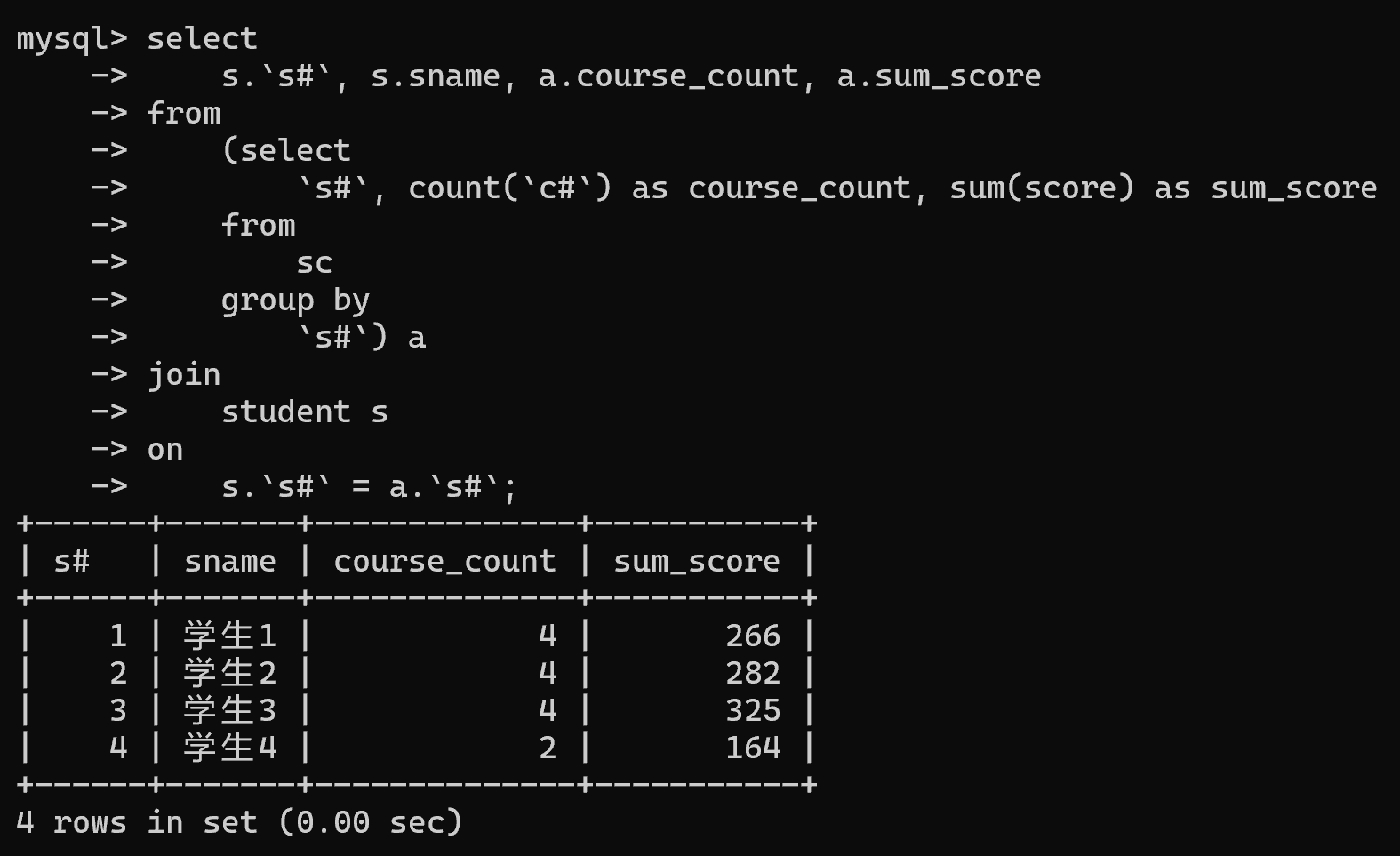
4.查询姓“李”的老师的个数
select count(*) from teacher where tname like '李%';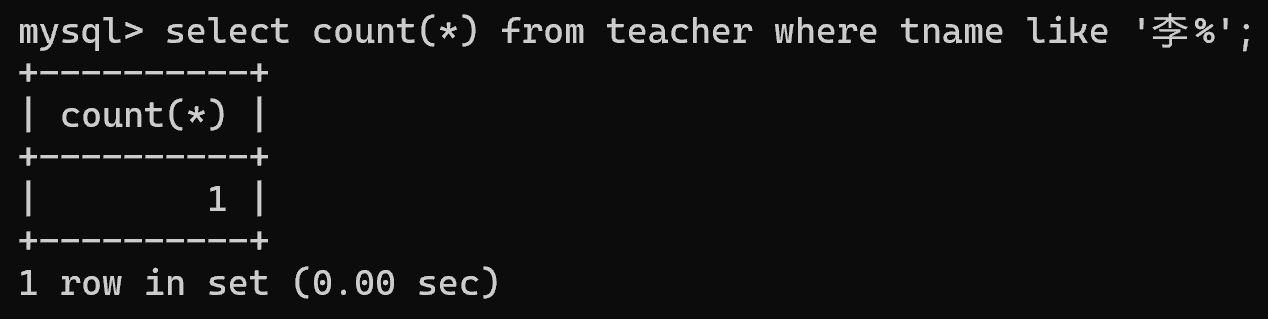
5.查询没选过“叶平”老师课的学号、姓名
-- 1.查询“叶平”老师的id
select `t#` from teacher where tname = '叶平';-- 2.查询“叶平”老师所授课程id
select `c#` from course where `t#` = (select `t#` from teacher where tname = '叶平');-- 3.查询选过“叶平”老师课程id的学生学号
select distinct `s#` from sc where `c#` in (select `c#` from course where `t#` = (select `t#` from teacher where tname = '叶平'));-- 4.查询未选过“叶平”老师课程id的学生学号
select `s#`, sname from student where `s#` not in (select distinct `s#` from sc where `c#` in (select `c#` from course where `t#` = (select `t#` from teacher where tname = '叶平')));
八、 综合题7(数据自行模拟)
- 学生表 student:
- s_id,int;
- sname,varchar。
- 课程表 class:
- c_id,int;
- cname,varchar。
- 选课表 choose_class:
- id,int;
- s_id,int;
- c_id,int;
- grade,int。
# 初始化(数据自行模拟)
drop table if exists student;
create table student(s_id int,sname varchar(255)
);
insert into student values(1,'学生1');
insert into student values(2,'学生2');
insert into student values(3,'学生3');
insert into student values(4,'学生4');drop table if exists `class`;
create table `class`(c_id varchar(255),c_name varchar(255)
);
insert into `class` values('C1', 'java');
insert into `class` values('C2', 'oracle');
insert into `class` values('C3', 'mysql');drop table if exists chosen_class;
create table chosen_class(id int,s_id int,c_id varchar(255),grade int
);
insert into chosen_class values(1,1,'C1', 66);
insert into chosen_class values(2,2,'C1', 77);
insert into chosen_class values(3,3,'C2', 88);
insert into chosen_class values(4,3,'C3', 99);
insert into chosen_class values(5,3,'C1', 22);
insert into chosen_class values(7,4,'C2', 33);
insert into chosen_class values(8,4,'C3', 56);1.查询没有选修课程编号为C1的学生姓名
-- 1.查询选修课程“C1”的学生id
select s_id from chosen_class where c_id = 'C1';-- 2.查询为选修“C1”课程的学生姓名
select sname from student where s_id not in (select s_id from chosen_class where c_id = 'C1');
2.查询每门课程的名称和平均成绩,并按照成绩排序
-- 1.查询每门课程的平均成绩
select c_id, avg(grade) as average_grade from chosen_class group by c_id;-- 2.查询每门课程的名称和平均成绩
select c.c_name, a.average_grade from (select c_id, avg(grade) as average_grade from chosen_class group by c_id) a join class c on c.c_id = a.c_id;
3.选了2门课以上的学生姓名
-- 1.查询选修2门课以上的学生id
select s_id from chosen_class group by s_id having count(c_id) > 2;-- 2.查询选修2门课以上的学生姓名
select sname from student where s_id = (select s_id from chosen_class group by s_id having count(c_id) > 2);
九、补充1:行列互换
- 行列互换即数据透视,将原本横向排列的数据透视为纵向排列的数据;
- 借助“case when”和“group by”完成。
十、通过 SQL 语句得出表中结果
# 初始化
drop table if exists t_temp;
create table t_temp(year int,season varchar(255),count int
);
insert into t_temp values(2010,'一季度',100);
insert into t_temp values(2010,'二季度',200);
insert into t_temp values(2010,'三季度',300);
insert into t_temp values(2010,'四季度',400);
insert into t_temp values(2011,'一季度',150);
insert into t_temp values(2011,'二季度',250);
insert into t_temp values(2011,'三季度',350);
insert into t_temp values(2011,'四季度',450);| year | 一季度 | 二季度 | 三季度 | 四季度 |
|---|---|---|---|---|
| 2010 | 100 | 200 | 300 | 400 |
| 2011 | 150 | 250 | 350 | 450 |
select year, max(case season when '一季度' then count else 0 end) as '一季度',max(case season when '二季度' then count else 0 end) as '二季度',max(case season when '三季度' then count else 0 end) as '三季度',max(case season when '四季度' then count else 0 end) as '四季度'
from t_temp
group byyear;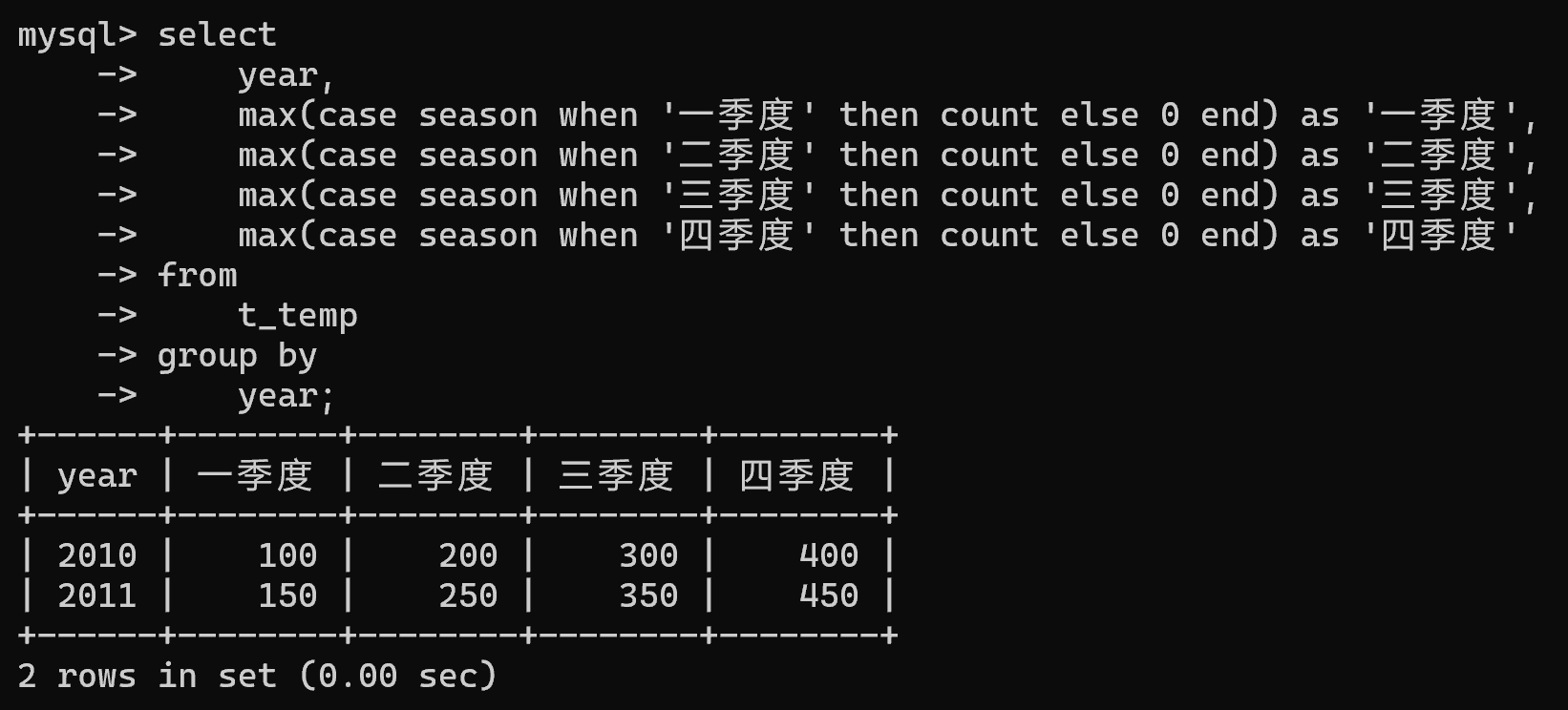
十一、补充2:窗口函数
- MySQL 8 及以上支持如下常用窗口函数:
ROW_NUMBER():排名函数,返回当前结果集中每个行的行号;
RANK():排名函数,计算分组结果中的排名,相同的行排名相同且没有空缺,下一个行排名跳过空缺;
DENSE_RANK():排名函数,计算分组结果中的排名,相同的行排名相同,排名连续,没有空缺;
NTILE():将分组结果等分为指定的组数,计算每组的大小;
LAG():返回分组内前一行的值;
LEAD():返回分组内后一行的值;
FIRST_VALUE():返回分组内第一个值;
LAST_VALUE():返回分组内最后一个值;
AVG()、SUM()、COUNT()、MIN()、MAX():聚合函数,可以配合 OVER() 进行窗口操作。
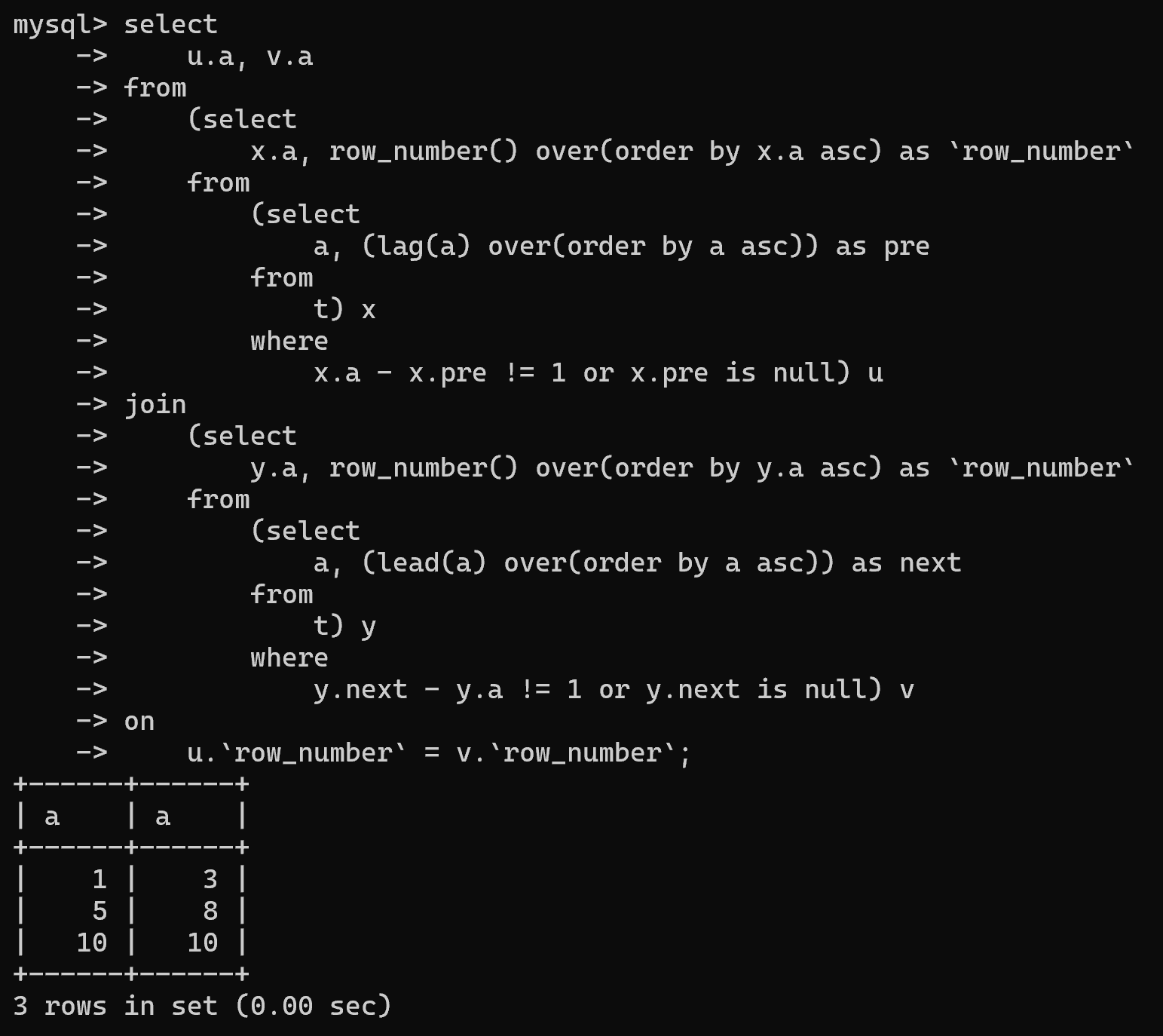
十二、有一张表有如下数据,写出一条 SQL 将数字连续性和断点展现出来
| A |
|---|
| 1 |
| 2 |
| 3 |
| 5 |
| 6 |
| 7 |
| 8 |
| 10 |
| 开始数字 | 结束数字 |
|---|---|
| 1 | 3 |
| 5 | 8 |
| 10 | 10 |
# 初始化
drop table if exists t;
create table t(A int
);
insert into t values(1);
insert into t values(2);
insert into t values(3);
insert into t values(5);
insert into t values(6);
insert into t values(7);
insert into t values(8);
insert into t values(10);
-- 1.查询 a 上一条数据
select a, (lag(a) over(order by a asc)) as pre from t;-- 2.查询开始数字并生成行号
select x.a, row_number() over(order by x.a asc) as `row_number` from (select a, (lag(a) over(order by a asc)) as pre from t) x where x.a - x.pre != 1 or x.pre is null;-- 3.查询 a 下一条数据
select a, (lead(a) over(order by a asc)) as next from t;-- 4.查询结束数字并生成行号
select y.a, row_number() over(order by y.a asc) as `row_number` from (select a, (lead(a) over(order by a asc)) as next from t) y where y.next - y.a != 1 or y.next is null;-- 5.按照行号连接
select u.a, v.a
from (select x.a, row_number() over(order by x.a asc) as `row_number` from (select a, (lag(a) over(order by a asc)) as pre from t) x where x.a - x.pre != 1 or x.pre is null) u
join (select y.a, row_number() over(order by y.a asc) as `row_number` from (select a, (lead(a) over(order by a asc)) as next from t) y where y.next - y.a != 1 or y.next is null) v
on u.`row_number` = v.`row_number`;