随机数种子seed和相关系数ρ
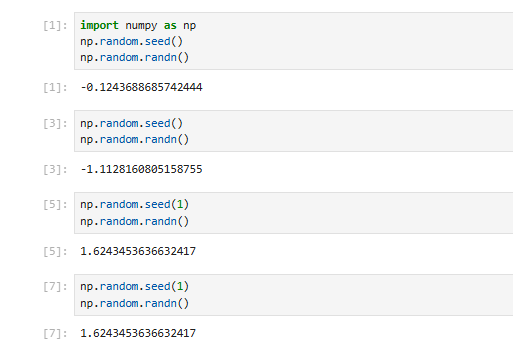
1. 随机数种子
计算机生成的随机数,其实并不是真正的随机数,而是使用特定算法生成的“伪随机数”。
这样我们就会面对两个问题:
(1)如果初始状态值一样,那么按照同样的算法得到的“随机数”结果应该是一样的。这样就不能表现出“随机”的效果。
(2)很多随机实验,有时候可能会需要再现之前的实验结果,我们正好又希望,每次实验生成的随机数都是一样的。
为了解决这个问题,引入了“种子”的概念。在生成随机数之前,先定义一个“种子”,如果这个种子是一样的,那么每次随机数的生成结果也都是一样的,这样我们便可以重复再现同一个随机实验。如果“种子”不一样,那么每次随机数生成结果都不一样,这样我们就可以大量使用不同的随机数进行实验。
在NumPy里面,可以使用seed函数来定义种子。调用seed(),会根据系统提供的数据进行随机初始化,也就是每次得到的随机数都会不一样。调用seed(x)的时候,计算机会根据x值进行初始化,如果x值是同一个x值,那么随机得到的结果也是一样的。
2. 相关系数
两个随机变量之间的相关性与独立性是统计学研究的一个非常重要的话题。
假设有两个随机变量x和y,满足如下条件:x=0.5y+ε,其中ε~N(0,0.5)
观察这两个随机变量可以发现,x与y有一定的“线性”关联性,但它们各自却有一定的随机性。统计上用协方差来描述这种“线性”关联性,公式如下:
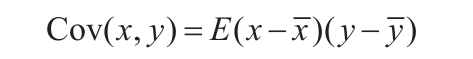
先按照上述公式生成10 000个随机数:
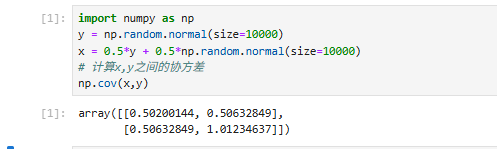
得到的结果是一个协方差矩阵。协方差矩阵的一般形式是:
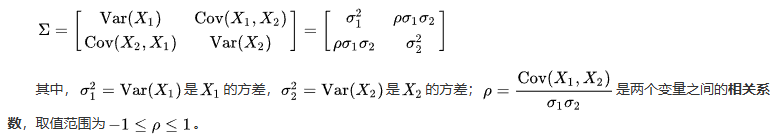
也就是左上角的数是变量x的方差,右下角的数是变量y的方差(主对角线上的两个数)
斜对角线上的两个数是变量x和y的协方差,协方差描述了两个变量之间的线性相关性。
用协方差描述相关性存在一个问题,即会受到随机变量的量纲影响。比如,如果我们想要衡量教育年限和薪资的水平,将教育年限的单位换为天,同时将薪资水平的单位从元换成角,那么协方差将会完全不同。
为了避免这种量纲上的区别造成的差异,统计学中引入了皮尔逊相关系数(Pearson Correlation Coefficient)。
计算公式如下:
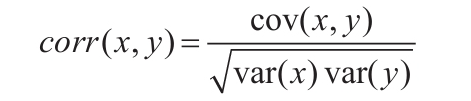
还是用上述生成的随机数来进行计算:

可以看到,斜对角线上的数值代表了两个变量的相关系数值。这个数值区间为[-1,1],且完全不受量纲影响。
理论上来讲,只要两个随机变量存在这种线性相关性,相关系数就不会为0。
如果两个变量之间存在非线性相关(如quardratic、exponential、logarithmic等关系),则相关系数将无法捕捉到这种线性相关。
可以从公式中推测的是,只要两个随机变量存在的函数关系能够被线性逼近,则两个随机变量的相关系数就不会为0。