LTX-Videov本地部署教程:时空扩散+多尺度渲染,重塑AI视频研究范式
一、简介
ComfyUI 是一个强大的、模块化的 Stable Diffusion 界面与后端项目。该用户界面将允许用户使用基于图形/节点/流程图的界面设计和执行高级稳定的扩散管道。该项目部分其它特点如下:
- 目前全面支持
SD1.x,SD2.x,SDXL,SD3,Stable Video Diffusion和Stable Cascade - 命令行选项:
--lowvram使其在显存小于 1GB 的 GPU 上运行(在显存较低的 GPU 上自动启用) - 即使没有 GPU,也可以工作:
--cpu(慢) - 可以加载
ckpt、safetensors和diffusers models/checkpoints。独立 VAE 和 CLIP 模型 - 从生成的 PNG 文件加载完整的工作流程(带有种子)
- 将工作流程保存/加载为 Json 文件
LTX-Video 是第一个基于 DiT 的视频生成模型,能够实时生成高质量的视频。它以比观看速度更快的速度生成 30 FPS、分辨率为 1216×704 的视频。该模型在包含多样视频的大规模数据集上进行训练,生成具有逼真和多样化内容的高分辨率视频。 我们为文本到视频以及图像 + 文本到视频的用例提供了模型。
模型详情
- 开发方: Lightricks
- 模型类型: 基于扩散的文本到视频和图像到视频生成模型
二、本地部署
| 环境 | 版本号 |
|---|---|
| Python | =3.12 |
| PyTorch | =2.5.1 |
| cuda | =12.4 |
| Ubtuntu | 22.4.0 |
1.安装 Miniconda
步骤 1:更新系统
首先,更新您的系统软件包:
sudo apt update
sudo apt upgrade -y
步骤 2:下载 Miniconda 安装脚本
访问 Miniconda 的官方网站或使用以下命令直接下载最新版本的安装脚本(以 Python 3 为例):
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
步骤 3:验证安装脚本的完整性(可选)
下载 SHA256 校验和文件并验证安装包的完整性:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh.sha256
sha256sum Miniconda3-latest-Linux-x86_64.sh
比较输出的校验和与.sha256 文件中的值是否一致,确保文件未被篡改。
步骤 4:运行安装脚本
为安装脚本添加执行权限:
chmod +x Miniconda3-latest-Linux-x86_64.sh
运行安装脚本:
./Miniconda3-latest-Linux-x86_64.sh
步骤 5:按照提示完成安装
安装过程中,您需要:
阅读许可协议 :按 Enter 键逐页阅读,或者按 Q 退出阅读。
接受许可协议 :输入 yes 并按 Enter。
选择安装路径 :默认路径为/home/您的用户名/miniconda3,直接按 Enter 即可,或输入自定义路径。
是否初始化 Miniconda :输入 yes 将 Miniconda 添加到您的 PATH 环境变量中。
步骤 6:激活 Miniconda 环境
安装完成后,使环境变量生效:
source ~/.bashrc
步骤 7:验证安装是否成功
检查 conda 版本:
conda --version
步骤 8:更新 conda(推荐)
为了获得最新功能和修复,更新 conda:
conda update conda
2.部署ComfyUI
2.1克隆代码仓库
git clone https://github.com/comfyanonymous/ComfyUI.git
2.2 安装依赖
- 创建conda虚拟环境
conda create -n comfyenv
conda activate comfyenv
- 安装PyTorch
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
- 安装依赖
cd ComfyUI
pip install -r requirements.txt
- 安装ComfyUI Manager
#进入插件的文件
cd /ComfyUI/custom_nodes/
#下载ComfyUI Manager
git clone https://github.com/Comfy-Org/ComfyUI-Manager.git
3.下载模型
推荐在魔搭社区中下载模型
#启动虚拟环境
conda activate comfyenv
#进入项目文件
cd ComfyUI
#下载modelscope
pip install modelscope
#下载模型文件到指定文件夹
modelscope download --model Lightricks/LTX-Video ltxv-2b-0.9.6-dev-04-25.safetensors --local_dir /models/checkpoints/
#下载t5xxxl_fp16到指定文件夹
modelscope download --model muse/t5xxl_fp16 t5xxl_fp16.safetensors --local_dir /models/text_encoders/
模型网址:
LTX-Video: LTX-Video · 模型库
t5xxl_fp16: t5xxl_fp16 · 模型库
模型名称:
ltxv-2b-0.9.6-dev-04-25.safetensors
模型放置路径:ComfyUI/models/checkpoints
t5xxl_fp16.safetensors
模型放置路径:ComfyUI/models/text_encoders
4.启动ComfyUI
python main.py
输入网址进入ComfyUI:
http://127.0.0.1:8188
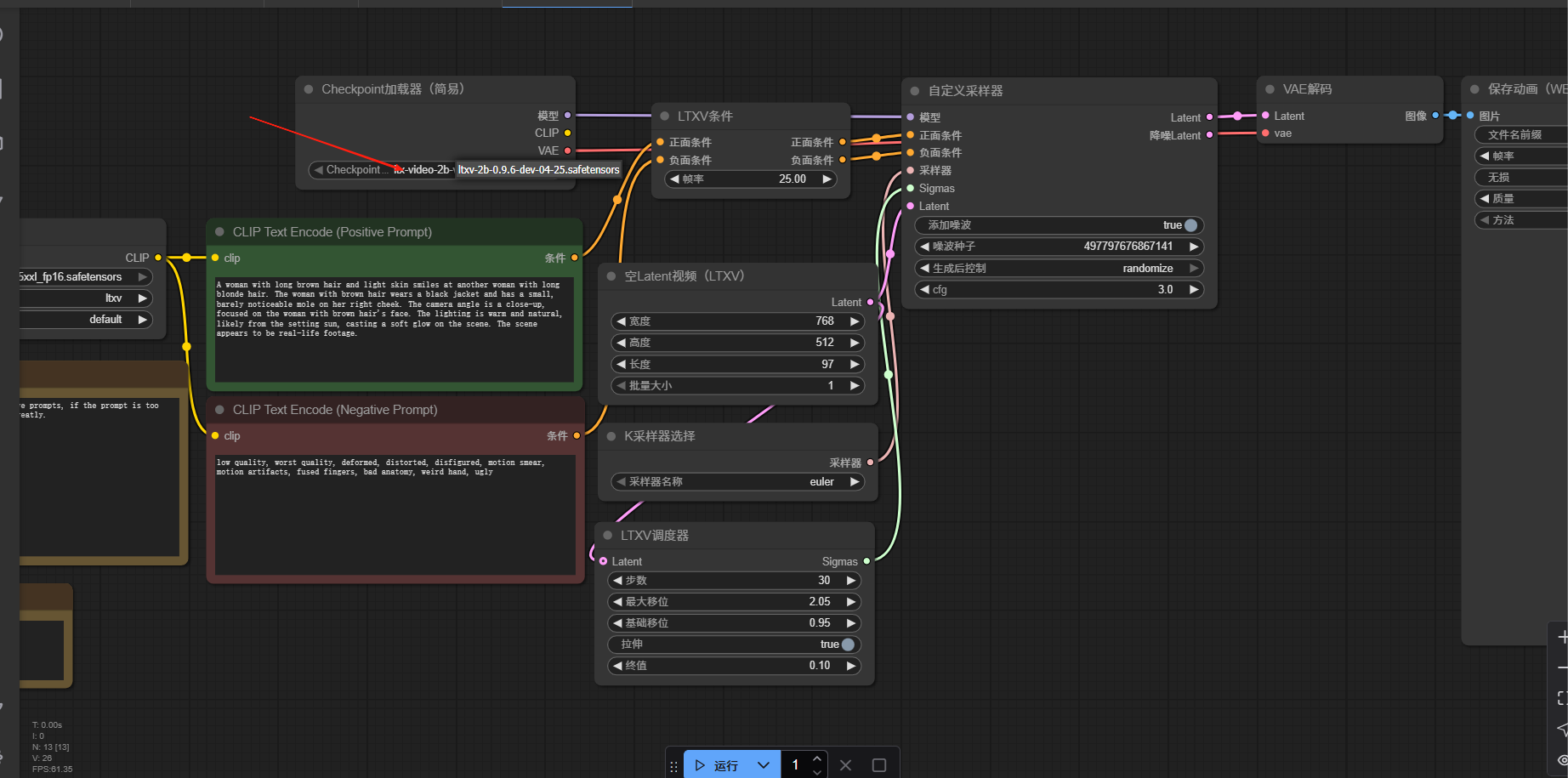
5.使用LTX-Video工作流
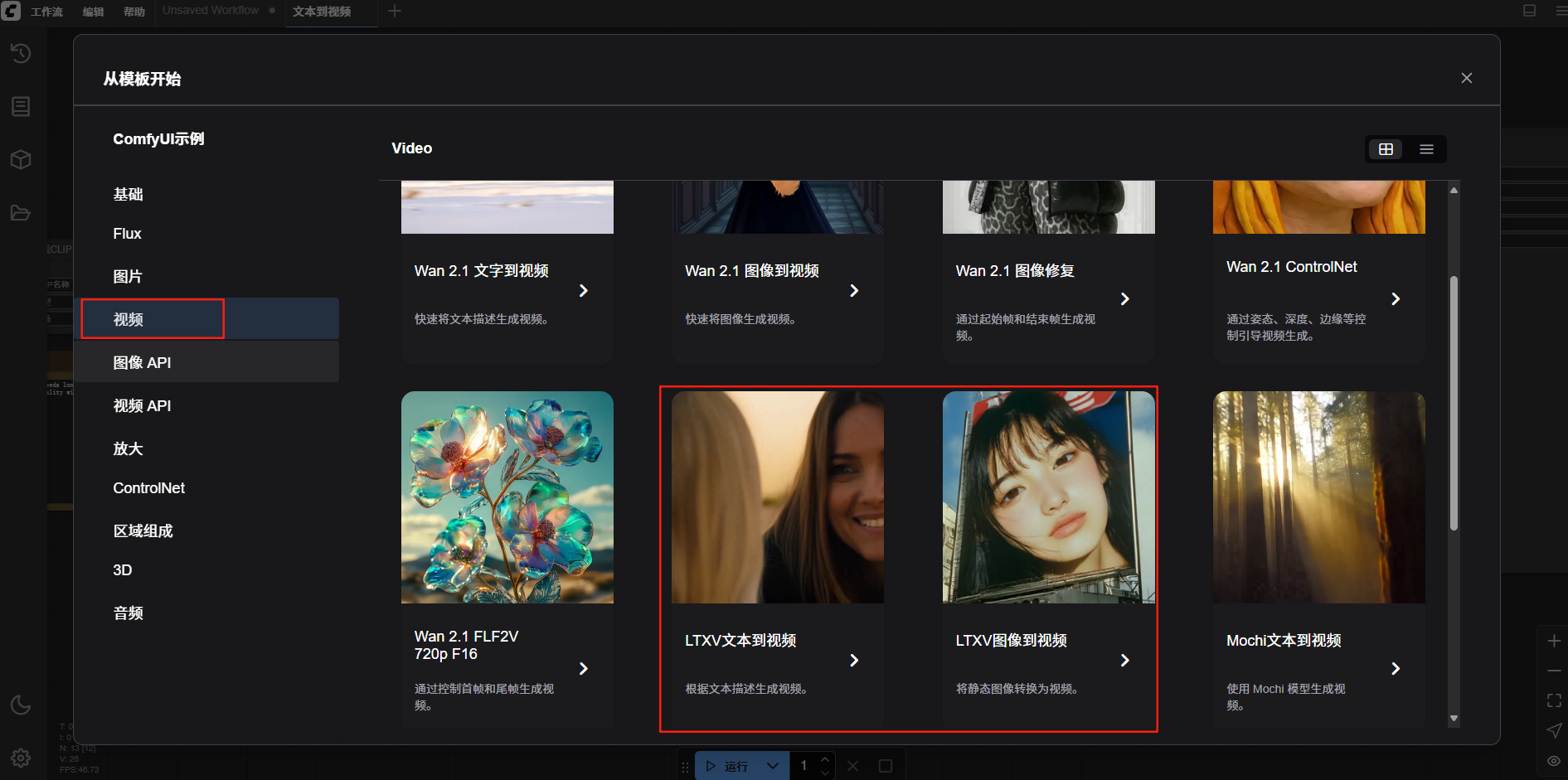
在模板页面中点击视频,选择LTXV文本到视频和LTXV图片都视频的任意一个即可使用
若提示确实模型可将提示页面关掉使用下面的步骤
点击模板工作流中箭头所指的位置,选择之前使用下载的模型