卷积神经网络基础(九)
之前已经学习过SGD这种方法,虽然实现简单,但是有时候却难以达到最低点。接下来我们要学习一种新的方法:Momentum。
目录
6.1.4 Momentum
6.1.5 AdaGrad
6.1.4 Momentum
Momentum就是“动量”的意思,和物理相关。数学式表达如下:
(1)
(2)
和之前学过的SGD一样,W表示要更新的权重参数,表示损失函数关于W的梯度,η表示学习率。这里出现了一个新的变量v,对应物理学的速度。上述(1)式表示物体在梯度方向上的受力,在力的作用下物体速度增加了这一物理法则。Momentum方法给人的感觉就是小球在地面上滚动。
示意图如下:

式中有αv这一项,物体不受任何力时,该项会使物体逐渐减速,(α设定为小于1的值)对应物理上的地面摩擦或空气阻力。下面是Momentum的代码实现:
class Momentum:def __init__(self, lr=0.01, momentum=0.9):self.lr = lrself.momentum = momentumself.v = Nonedef update(self, params, grads):if self.v is None:self.v = {}for key, val in params.items():self.v[key] = np.zeros_like(val)for key in params.keys():self.v[key] = self.momentum*self.v[key] - self.lr*grads[key]params[key] += self.v[key实例变量v保存物体速度。初始化时,v中什么都不保存,但当第一次调用update()时,v会以字典性变量的形式保存与参数结构相同的数据。剩余的代码部分就是将式(1)(2)表达出来。
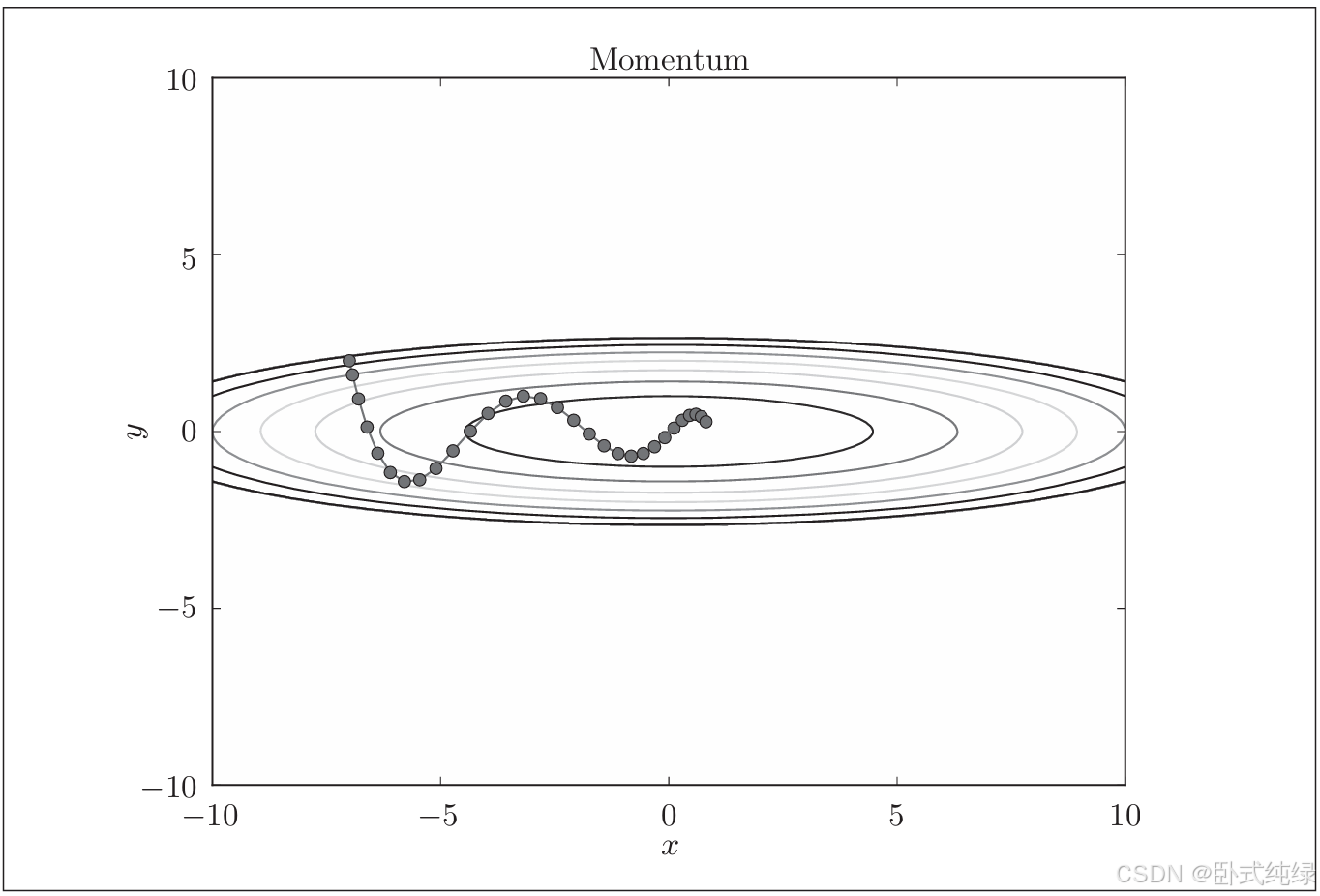
就像上述的示意图一样,更新路径就像小球在碗中滚动一样,和SGD相比,我们发现“之”字形的程度减轻了。这是因为虽然x轴方向受力较小,但一直在一个方向上受力,所以会朝同一个方向有一定的加速。反过来,y轴方向的受力较大,但是因为交互性地受到正方向和反方向的力,会互相抵消,所以y轴方向的速度不稳定。因此,和SGD相比,可以更快地朝x轴方向靠近,减弱“之”字形的变动程度。
基于Momentum的最优化更新路径如下所示:
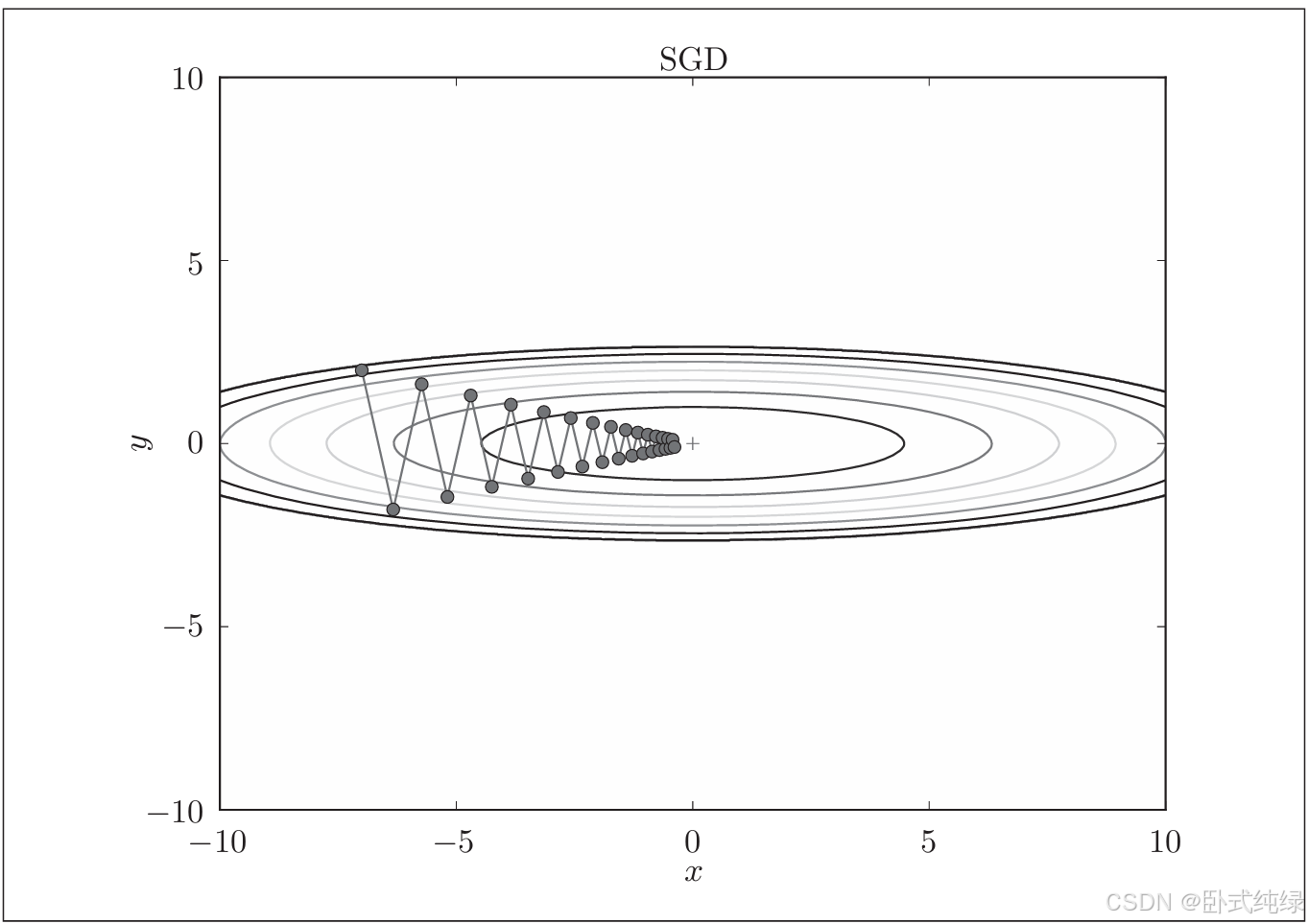
我们再来看看SGD方法的更新路径:
6.1.5 AdaGrad
神经网络的学习过程中,学习率η的值很重要,如果过小,则导致学习花费过长时间,收敛较慢,反之过大则会导致发散,而无法正确学习。有一种技巧称为学习率衰减(learning rate decay)的方法,随着学习进行,使学习率逐渐减小。实际上,刚开始“多”学,然后逐渐减少学的方法,在神经网络中经常使用。
逐渐减小学习率的想法,相当于将“全体”参数的学习率值一起降低。而AdaGrad进一步发展了这个方法。针对单个的参数,赋予其“定制”的值。
AdaGrad会为每个参数适当地调整学习率,与此同时进行学习(Ada来自英文单词Adaptive,适当的)。下面用数学方法表示更新方法:
(3)
(4)
和前面SGD一样,W表示要更新的权重参数,表示损失函数关于W的梯度,η表示学习率。这里出现了新变量h,如(3)所示,它保存了以前所有梯度值的平方和。然后在更新参数时乘以
就可以调整学习的尺度,也就是说,可以按照参数的元素进行学习率的衰减,使变动大的参数学习率逐渐减小。

接下来实现AdaGrad,其实现过程如下:
class AdaGrad:def __init__(self, lr=0.01):self.lr = lrself.h = Nonedef update(self, params, grads):if self.h is None:self.h = {}for key, val in params.items():self.h[key] = np.zeros_like(val)for key in params.keys():self.h[key] += grads[key] * grads[key]params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)这里需要注意的是,最后一行加上了微小值1e-7.这是为了防止当self.h[key]中有0时,将0当作除数的情况。在很多深度学习的框架中,这个微小值也可以设定为参数,但我们使用1e-7这个固定值。AdaGrad解决最优化问题的结果如图所示:
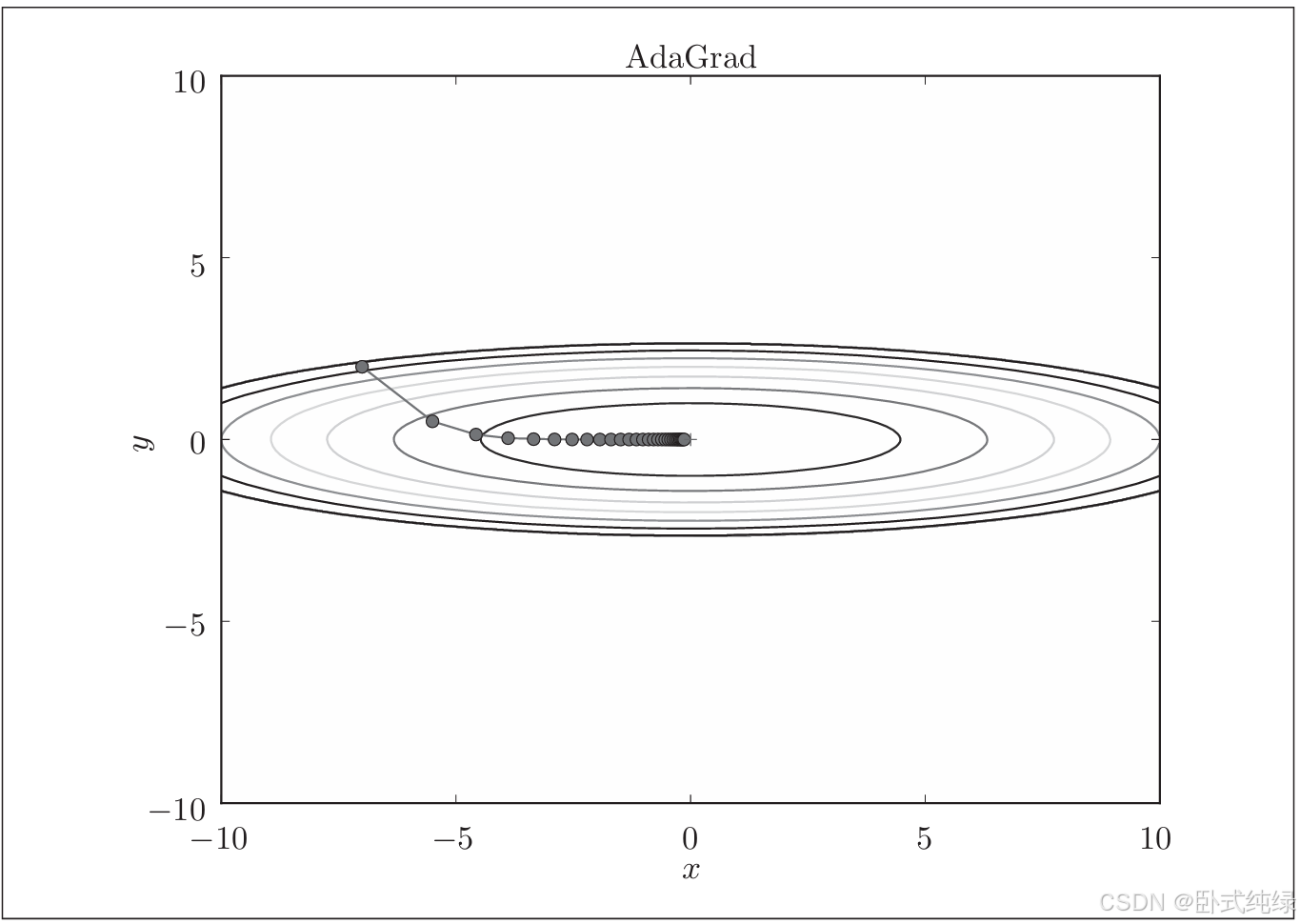
由图可知,函数的取值高效地向着最小值移动,由于y轴方向上的梯度较大,因此刚开始变动较大,但是后面会根据这个较大的变动按比例调整,减小更新的步伐。因此y轴方向上的更新程度会被减弱,之字形的变动程度有所衰减。