大语言模型(LLM)本身是无状态的,怎么固化记忆
大语言模型(LLM)本身是无状态的,无法直接“记住”历史对话或用户特定信息
大语言模型(LLM)本身是无状态的,无法直接“记住”历史对话或用户特定信息,但可以通过架构改进、外部记忆整合、训练方法优化等方案实现上下文记忆能力。
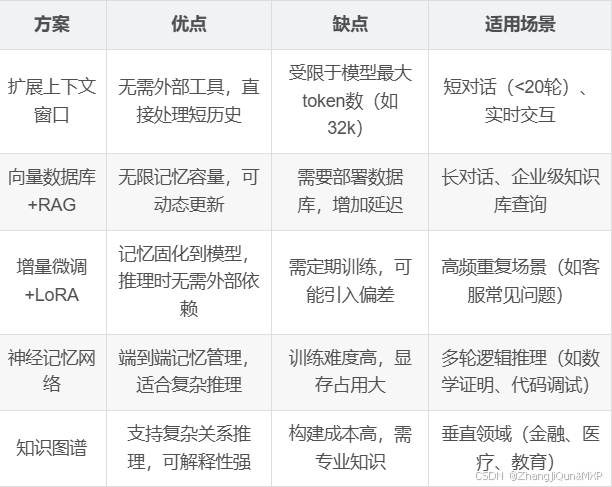
一、模型内部记忆增强:让LLM“记住”对话历史
1. 扩展上下文窗口(模型架构优化)
- 技术原理:
通过改进Transformer架构,增加模型可处理的上下文长度,直接将历史对话包含在输入中(即“隐性记忆”)。- 位置编码优化:如RoPE(旋转位置编码)支持更长序列,GPT-4支持8k~32k tokens,Claude 3支持100k tokens。
- 分层注意力:如LongNet、HydraNets,