DS新论文解读(2)

上一章忘了说论文名字了,是上图这个名字
我们继续,上一章阅读地址:
dsv3新论文解读(1)
这论文剩下部分值得说的我觉得主要就是他们Infra通信的设计
先看一个图
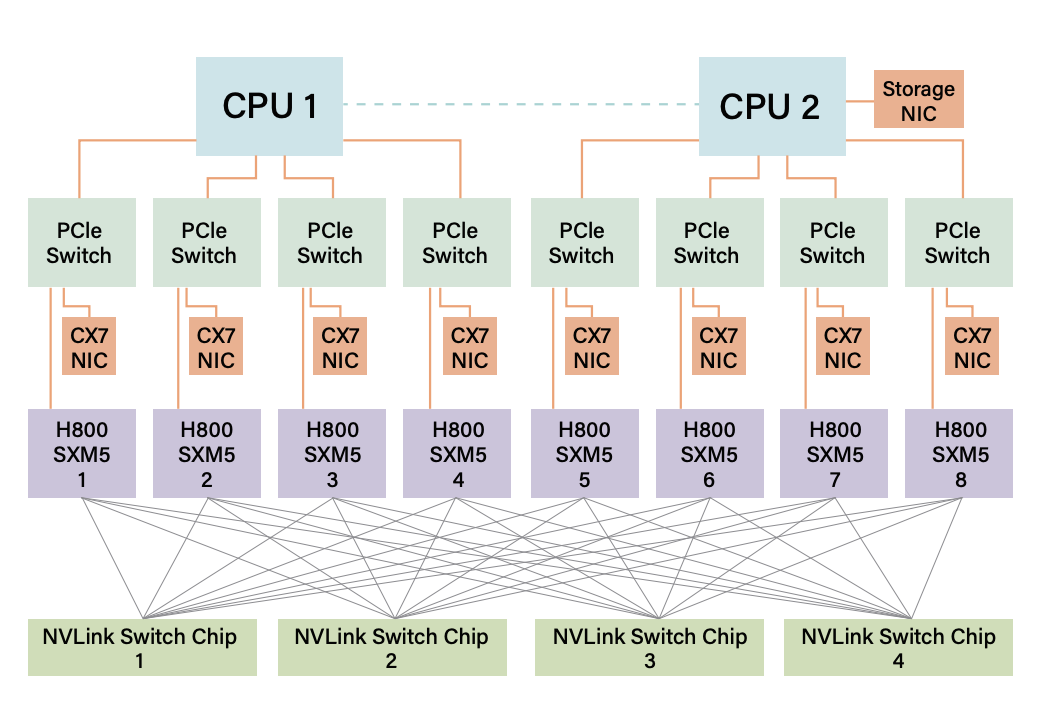
这个是一个标准的h800 8卡with 8cx7 nic的图,2个cpu,每个cpu管着4个pcie,每个pcie连接 网卡(cx7 400g)和 gpu卡(这里是h800),负责gpu的流量要找本机以外的gpu通信
也就是node0的gpu0要是node1的gpu0,或者gpu1 通信,它就需要把数据先发给pcie在发给cx7 然后再发到ib或者roce交换机上,再发到对端的node1,再进行一次反操作,这个东西,看起来就很费延迟对吧?
那就尽量走nvlink
这里面有几个可以考虑的点
-
cpu-gpu的nvlink,它应该是没买gracecpu,它用的是800,所以这个没法做到
-
(Model Co-Design: Node-Limited Routing)提到,在他们的节点限制路由策略中,会利用节点内 NVLink 的更高带宽进行数据转发:“通过利用更高的 NVLink 带宽,路由到同一节点的令牌可以通过 IB 发送一次,然后通过 NVLink 转发到其他节点内的 GPU。” 这体现了在实际设计中,当有选择时,会优先利用 NVLink 的高带宽特性进行节点内 GPU 间通信。
这两个好理解一点
还有一个和上一篇文章一样,能看出来DS他们对硬件设计的野心很大
论文中第 4.5.2 节提出了一个建议:“I/O Die Chiplet 集成”
那么什么是“I/O Die Chiplet 集成”?
这个概念是基于现代处理器和加速器设计中越来越流行的 Chiplet(小芯片)架构。
传统单片设计 (Monolithic Die):过去,一个复杂的芯片(如CPU或GPU)通常是在一整块硅片上制造出来的。
Chiplet 设计:现在,为了提高良率、灵活性和成本效益,设计师倾向于将一个大芯片的功能拆分成多个较小的、专门化的“小芯片”(Chiplets)。这些 Chiplets 可以在同一封装基板上被紧密地互连起来,共同构成一个完整的系统。
I/O Die (输入/输出小芯片):在 Chiplet 设计中,常常会有一个专门的 I/O Die。这个小芯片负责处理整个封装体的大部分或全部对外输入输出接口,比如连接内存的控制器、连接其他设备的 PCIe 控制器、以及其他各种 I/O 接口。
将 NIC 集成到 I/O Die 中:论文的建议是,不再将网络接口卡 (NIC) 做成一个独立的、插在主板 PCIe 插槽上的卡,而是将 NIC 的核心功能直接集成到处理器的 I/O Die 这个小芯片上,或者做成一个与 I/O Die 通过极高带宽、极低延迟接口紧密相连的专用网络 Chiplet。
同一封装内连接到计算 Die:集成了 NIC 功能的 I/O Die 会通过封装内部的、非常短的高速互连通道直接连接到计算 Die。
那么回到我们的考虑,为什么这种集成方式能“显著减少通信延迟并缓解 PCIe 带宽争用”呢?
与传统的 PCIe 连接方式(即计算核心通过主板上的 PCIe 插槽连接外部独立的 NIC 卡)相比,这种集成方式有以下优势:
显著减少通信延迟:
物理距离大大缩短:信号在芯片封装内部传输的距离远小于跨越主板到 PCIe 插槽的距离。更短的距离意味着更低的信号传播延迟。
更高效的内部互连协议:封装内部的 Chiplet间互连可以使用比通用 PCIe 协议更专用、更低开销的通信协议。PCIe 协议为了兼容性和长距离传输,本身带有一定的协议开销(如包头、状态管理、错误校验等)。内部互连可以更精简。
可能避免额外的 PCIe 组件:传统的 PCIe 路径可能需要经过主板上的 PCIe Retimer(信号中继器)或 PCIe Switch(交换芯片),这些都会引入额外的延迟。封装内集成可以实现更直接的连接。
缓解 PCIe 带宽争用:
专用高带宽路径:计算 Die 与包含 NIC 功能的 I/O Die 之间的封装内互连通道,可以设计得比标准的 PCIe x16 (有人抬杠说我要乘160呢?你出去,这里不合适和你)链路更宽、更快,为网络数据提供一条专用的、高吞吐量的“高速公路”。
减轻外部 PCIe 总线压力:当 NIC 功能集成在处理器封装内并直接服务于计算 Die 时,计算 Die 与网络之间的数据交换主要通过这个内部高速通道进行。这样,处理器对外的 PCIe 通道(用于连接其他外设、存储等)的带宽就不会被网络 I/O 大量占用,从而减少了争用。
更直接的访问:计算 Die 可以更直接、更高效地访问网络功能,数据不需要在多个芯片和总线之间进行多次周转。
但是为什么现在硬件厂商不这么做?
个大硬件厂商:我又能卖算力卡,又能卖网卡,我赚两份钱,我听你BB?你TM算老几?
当然也客观存在这需求和市场的roi平衡的问题。
我们继续
另外一个值得说的就剩下网络了
除了能用NVlink尽量用NVlink以外,虽然H800的NVlink确实比H100/200差多了,严格版本跟A100差不多,但是也比PCIE要强好几倍,所以他们训练的时候尽量不用TP,但是NVlink还是起了很大作用的,能不走pcie,尽量不走,但是如果跨机器通信比如任何的集合通信,还是绕不过PCIE---IB----PCIE--CPU---GPU这条路径的
这条路径其实有一个大问题,就是多对1,比如all-gather的时候,会有很大瓶颈。所以DS它们改了传统的胖树FAT tree网络(一般企业其实现在如果为了clos也就是2层网络,我们姑且就当无阻塞的spine-leaf来看)。改成了分平面的spine-left的 MPFT
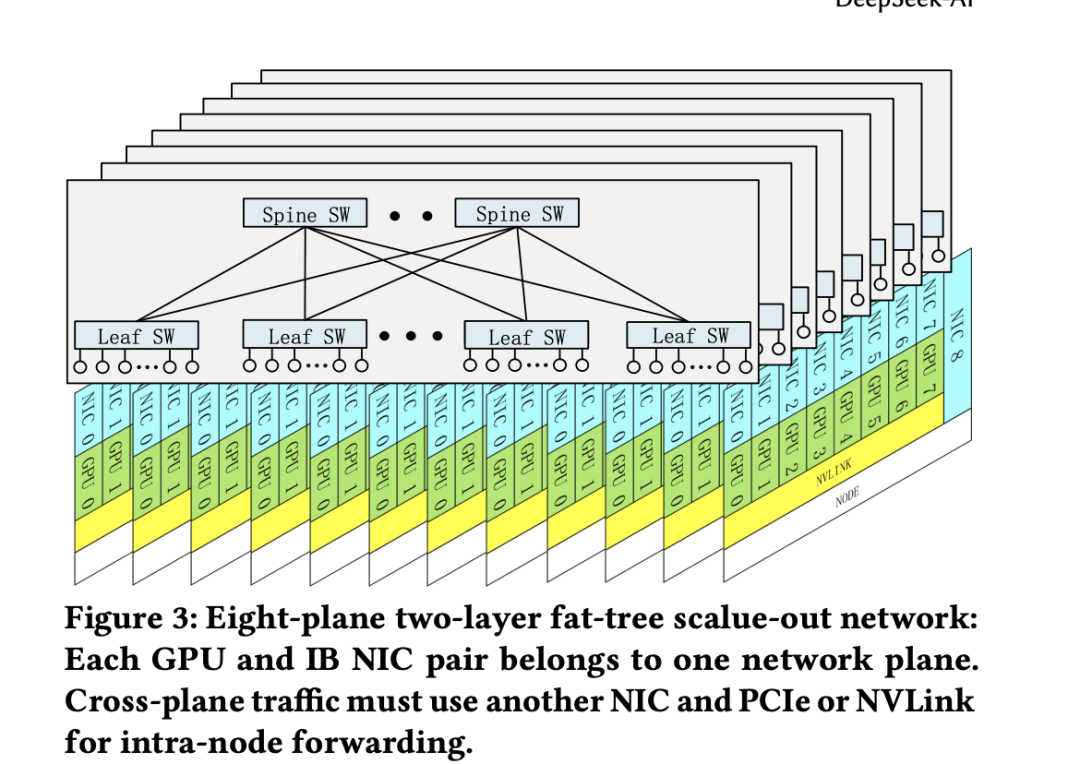
如上图画的,正常我们部署DC内不AI网络的时候
leaf就不说了。spine一般都是复用的,而且必须要有连接,比如你从一个leaf要去的另一个leaf switch 它俩挂在不通的spine下,你的包是过不去的(这个和tcp或者ib就无关了,就是无力上过不去)
那它这么设计的目的其实刚才也讲了,就是为了缓解并发多对1,或者多对对的压力,把流量固定在一个平面内,比如上图
每个node有8块gpu,每个gpu对应一块nic(IB或者roce)
那node0的gpu0发给自己内部机器的gpu1-7就nvlink就完事了
但是node0的gpu0要发node1的gpu0的话,你就必须走gpu---pcie--cpu---pcie--nic--ib--对面 这条路
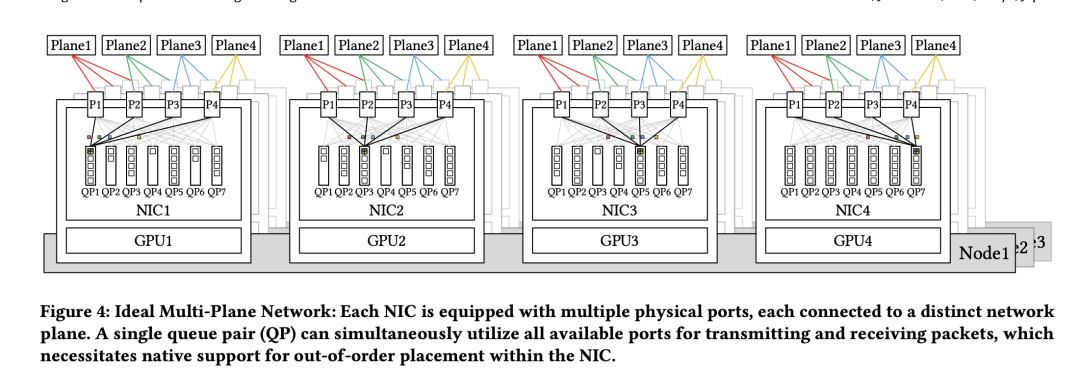
但是由于平面的隔离,如上图,每个QP就自己玩自己的(QP是ib
的概念,你要是不懂就当乘tcp的socket来看就好理解了)。相当于至少给你减少了7/8的流量,对pcie和 ib交换机的压力那都是显著的减轻的
那么问题来了,如果node0的gpu0要发流量给gou1的gpu1怎么办???
平面是完全隔离的,按说就过不去了
这个时候nvlink又上场了,借用它的快速,低延迟的能力
这个路径变成了:
1-数据在 Node0 的 GPU0 上准备好。
2-由于目标 Node1 的 GPU1 是通过平面1接入网络的,如果 Node0 希望通过平面1将数据发送给 Node1 的 GPU1,那么数据不能直接从 Node0 的 NIC0 (平面0) 发出。
3-根据论文的“跨平面流量”规则,Node0 的 GPU0 需要将数据在节点内部通过高速互联(NVLink )传递给 Node0 的 GPU1(因为 Node0 的 GPU1 配对的是 NIC1,NIC1 连接到平面1)。
4-然后,Node0 的 GPU1 将数据交给其配对的 NIC1。
5-Node0 的 NIC1 通过**外部IB网络(平面1)**将数据发送到 Node1 的 NIC1。
6-Node1 的 NIC1 接收数据后,传递给 Node1 的 GPU1
多平面胖树MPFT网络的优势:
多轨胖树 (MRFT) 的子集:MRFT(Multi-Rail Fat-Tree, MRFT) 是Nvidia做DGCX pod的推荐,MPFT 拓扑是更广泛的多轨胖树 架构的一个特定子集(我之前说过DS大多数时候,不做什么新东西,主要是按着老的feature进行优化是它们的核心能力)。因此,NVIDIA 和 NCCL 为多轨网络开发的现有优化(如 NCCL 的 PXN 技术,用于处理平面间隔离问题)可以无缝地应用于 MPFT,这也就不用DS它们为了这个事情来现改集合通信了。
成本效益 (Cost Efficiency):MPFT 使得使用两层胖树 (FT2) 拓扑就能支持超过1万个端点,与三层胖树 比如MRFT标准的(FT3) 相比显著降低了网络成本。其每端点成本甚至略优于成本效益较高的 Slim Fly (SF) 拓扑。
流量隔离 (Traffic Isolation):每个平面独立运行,一个平面的拥塞不会影响其他平面,提高了整体网络稳定性。
延迟降低 (Latency Reduction):两层拓扑通常比三层胖树具有更低的延迟,特别适合延迟敏感的应用,如 MoE 模型的训练和推理。
鲁棒性 :理想情况下,多端口 NIC 提供多个上行链路,单个端口故障不会中断连接,可以实现快速透明的故障恢复。但论文也指出,由于当前 400G NDR InfiniBand 的限制,他以后上CX8的时候,也许就不这么考虑了,页说不定。跨平面通信需要节点内转发,这会在推理时引入额外延迟。如果未来硬件能实现之前讨论的纵向与横向网络融合,这种延迟可以显著降低。
性能分析 :
为了验证 MPFT 设计的有效性,团队在集群上进行了实际实验,比较了 MPFT 和单平面多轨胖树 (Single-Plane Multi-Rail Fat Tree, MRFT) 的性能。
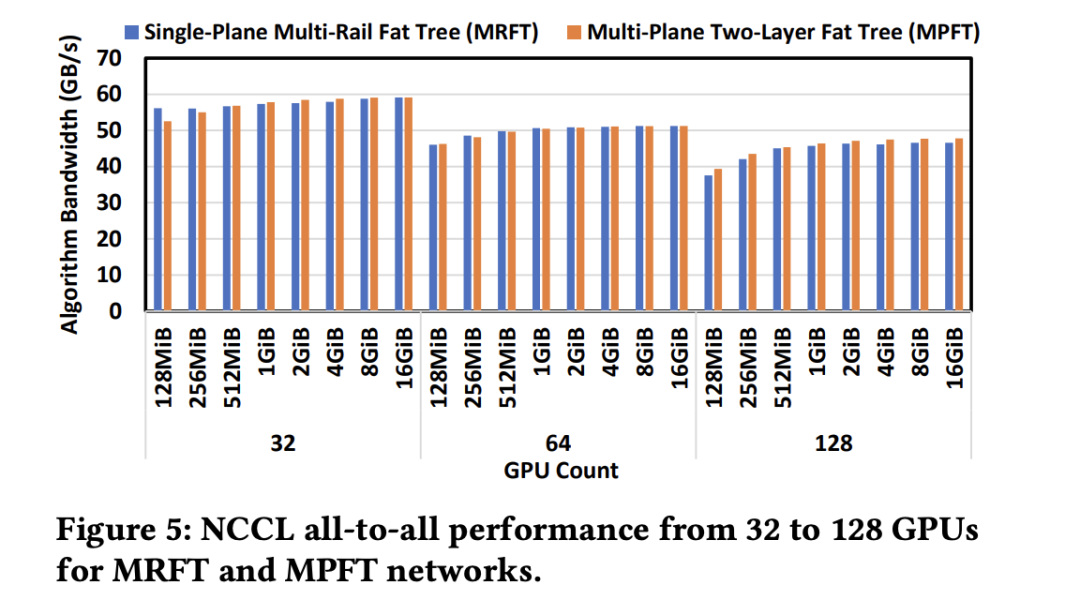
All-to-All 通信和 EP 场景:实验结果如上图显示,MPFT 网络的 all-to-all 性能与 MRFT 非常相似。这归功于 NCCL 的 PXN 机制,该机制通过 NVLink 优化了多轨拓扑中的流量转发,MPFT 也从中受益。
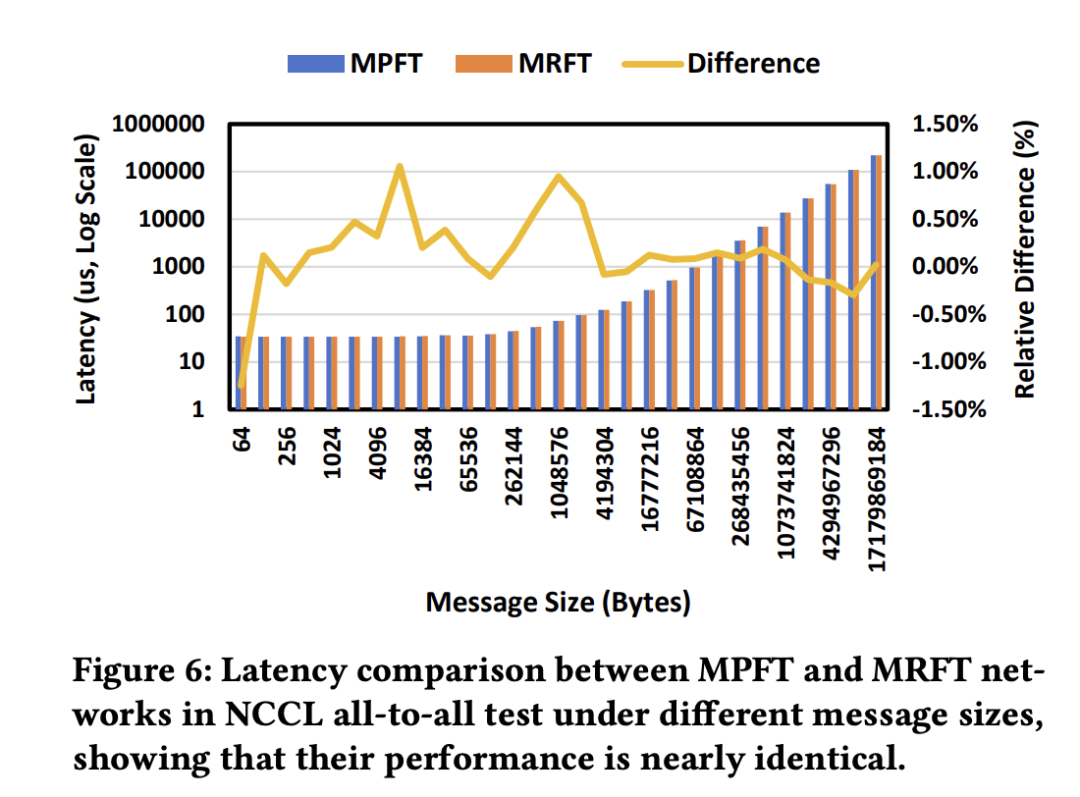
如上图在16个GPU上进行的 all-to-all 通信测试显示,不同消息大小下,MPFT 和 MRFT 之间的延迟差异可以忽略不计。
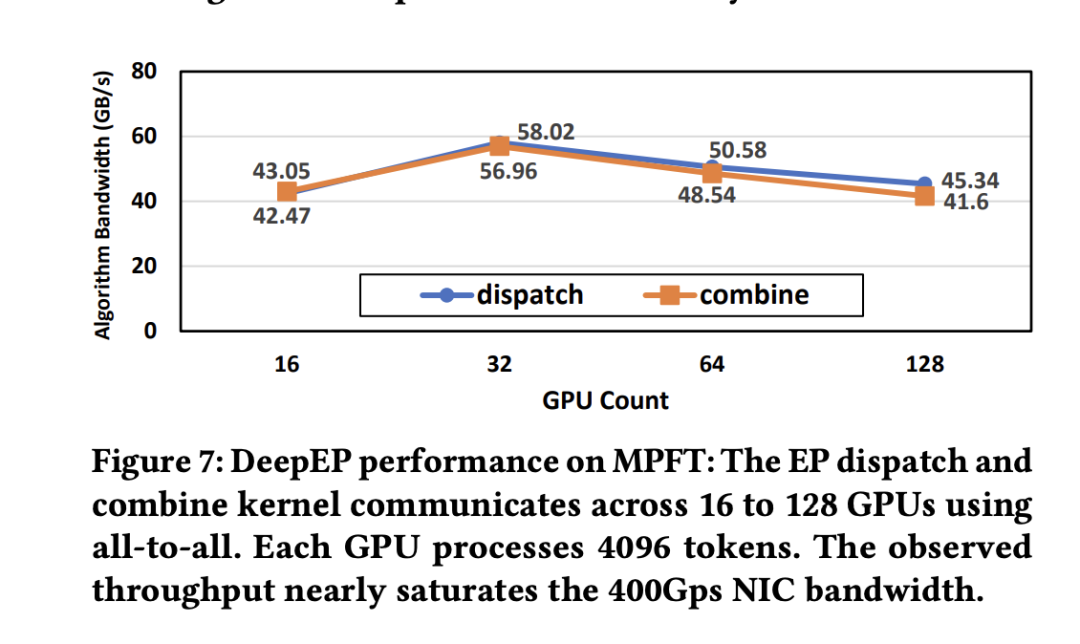
DeepEP 性能:在 MPFT 上测试 EP 通信模式,如上图,每个 GPU 实现了超过 40GB/s 的高带宽,满足了训练需求。
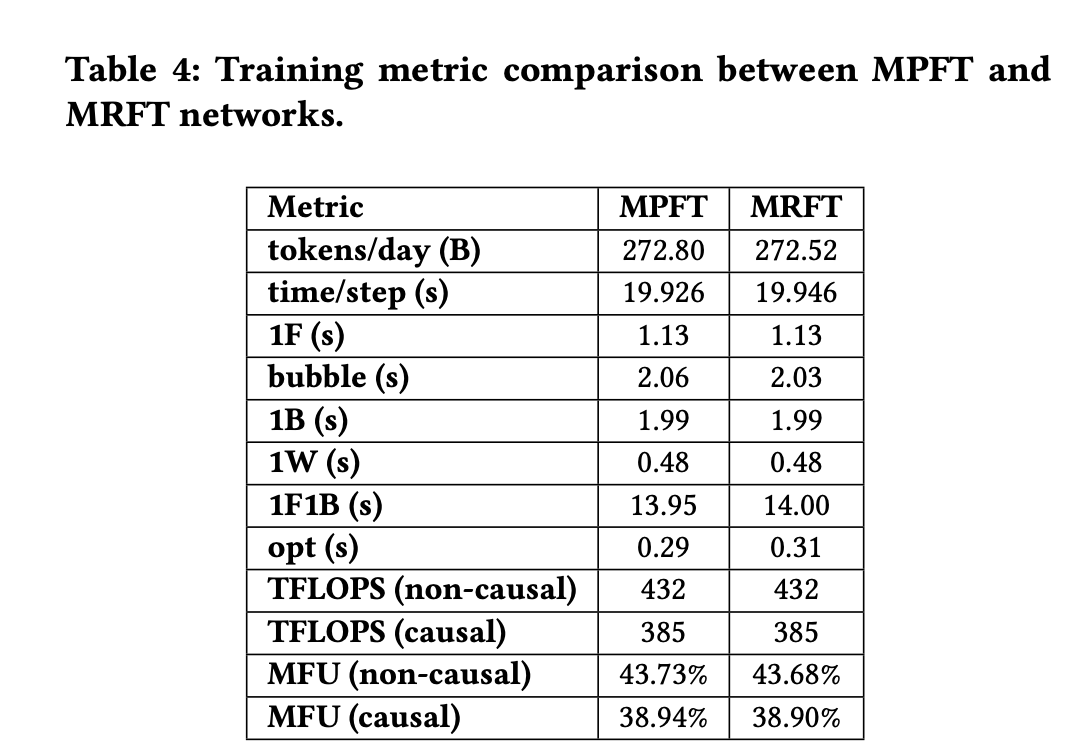
DeepSeek-V3 模型训练吞吐量:在2048个GPU上训练V3模型时,MPFT 和 MRFT 的性能指标(如每日处理 token 数、每步时间、各阶段耗时、TFLOPS、MFU等,见上表)几乎相同,观察到的差异在正常波动和测量误差范围内。
所以就是便宜的方案也能干MRFT的事(DS主打便宜高效率,这个是一直贯穿始终的研究)
剩下其他的什么MLA,MTP,MOE啥的我以前都讲过了,大家感兴趣可以翻我以前的文章,这个论文就解读完了。
下次见。