【MySQL】存储过程,存储函数,触发器
目录
准备工作
一. 存储过程
1.1.什么是存储过程
1.2.创建存储过程
1.3.创建只显示大于等于指定值的记录的存储过程
1.4.显示,删除存储过程
二. 存储函数
2.1.什么是存储函数
2.2.使用存储函数
2.2.1.使用存储函数之前
2.2.2.使用存储函数计算标准体重
2.2.3.返回记录平均值的存储函数
2.3.显示和删除存储函数
三. 触发器
3.1.什么是触发器
3.2.创建触发器
3.2.1.触发器被触发的时机
3.2.2.创建触发器
3.3.触发器的内容
3.4.确认和删除触发器
3.4.1. 查看所有触发器
3.4.2.删除触发器
准备工作
我们得先创建好两个表tb和tb1
-- 如果表已存在则删除
DROP TABLE IF EXISTS `tb1`;-- 创建 tb1 表(员工信息表)
CREATE TABLE `tb1` (`empid` VARCHAR(4) PRIMARY KEY COMMENT '员工编号',`name` VARCHAR(50) COMMENT '员工姓名',`age` INT COMMENT '员工年龄'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;-- 插入员工数据(注意:没有 A105)
INSERT INTO `tb1` (`empid`, `name`, `age`) VALUES
('A101', '佐藤', 40),
('A102', '高桥', 28),
('A103', '中川', 20),
('A104', '渡边', 23),
('A105', '西泽',35);-- 如果表已存在则删除
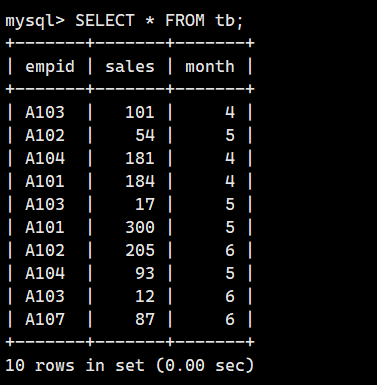
DROP TABLE IF EXISTS `tb`;-- 创建 tb 表(销售信息表)
CREATE TABLE `tb` (`empid` VARCHAR(4) COMMENT '员工编号(关联 tb1.empid)',`sales` INT COMMENT '销售额',`month` INT COMMENT '月份'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;-- 插入销售数据(包含 A107,但 tb1 中无对应员工)
INSERT INTO `tb` (`empid`, `sales`, `month`) VALUES
('A103', 101, 4),
('A102', 54, 5),
('A104', 181, 4),
('A101', 184, 4),
('A103', 17, 5),
('A101', 300, 5),
('A102', 205, 6),
('A104', 93, 5),
('A103', 12, 6),
('A107', 87, 6);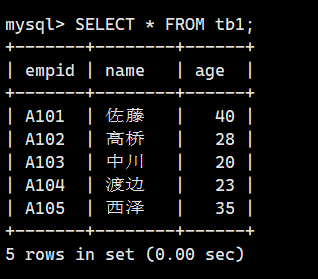
我们现在开始进入正题
一. 存储过程
1.1.什么是存储过程
MySQL存储过程是一种预先编写并存储在数据库中的可重复使用的SQL代码块,它能够通过一个名称被调用执行。
存储过程可以包含复杂的逻辑操作,如条件判断、循环、变量操作等,允许将一系列SQL语句组合成一个单元,以便在需要时高效执行。
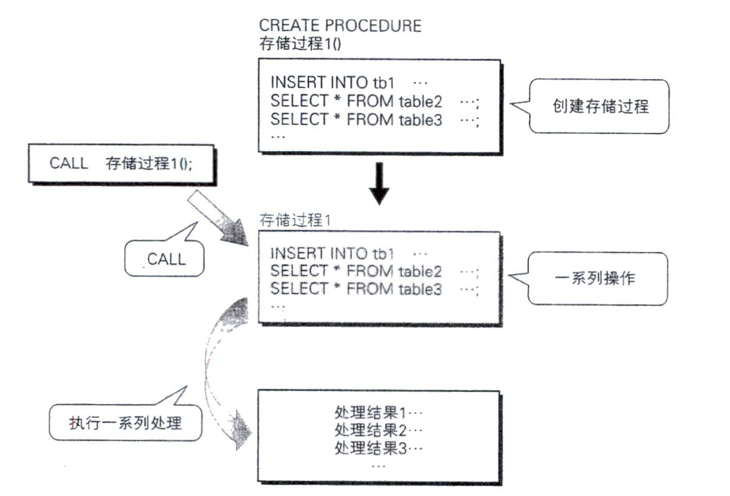
换句话说,就是将多个 SQL 语句组合成一个只需要使用命令“CALL xx”就能执行的集合,该集合就称为存储过程(stored procedure )。
“存储”( stored)表示保存,“过程”(procedure)表示步骤。也就是说,存储过程是将一系列步骤归纳并存储起来的集合
与直接在应用程序中编写SQL语句相比,存储过程将业务逻辑封装在数据库层,提升了代码的模块化和可维护性。
由于可以自动执行许多事先准备好的命令,所以处理效率很高。
但是,在存储了重要数据的数据库中,执行没有经过充分验证的存储过程是非常危险的,这一点需要我们牢记。
存储过程乍一看让人觉得有些难以理解,但只要学会了它的使用方法,用起来就会非常方便。
下面是作为示例创建的存储过程的主体。
SELECT * FROM tb;
SELECT * FROM tb1;上面的示例中只列出了两个很普通的 SQL语句。
当然,我们也可以根据需要编写任意数量的SQL语句,还可以执行编程语言中常见的处理,比如使用变量、使用IF和 CASE作为条件分支以及使用 WHILE 和 REPEAT 反复处理等。
1.2.创建存储过程
当创建存储过程时,我们需要像下面这样执行 CREATE PROCEDURE 命令。
CREATE PROCEDURE 存储过程名 ( )
BEGINSQL 语句 1SQL 语句 2
END从 BEGIN 到 END 为止的内容是存储过程的主体。
在开头加上 BEGIN,在结尾加上 END,这么做可以明确表示“从这里到这里是存储过程的命令”。
因为存储过程的内容是“普通的 SQL 语句”,所以需要在命令的末尾添加分隔符“;”。
也就是说,当创建上面我们说的那个示例介绍的存储过程时,主体部分需要像下面这样描述。
BEGIN
SELECT * FROM tb;
SELECT * FROM tbl;
END可是这样一来,在创建存储过程的时候就会输入分隔符“;”。在这种情况下,CREATE PROCEDURE 命令就会在存储过程不完整的状态下执行。因为在 MySQL 监视器中一旦输入了分隔符,不管是什么内容,都会先执行分隔符之前的部分。
- 修改分隔符的设置
在存储过程不完整的状态下执行命令会带来一些麻烦,因此我们需要改变环境设置,在输入了最后的 END 之后再执行 CREATE PROCEDURE 命令。
因此,在创建存储过程时,需要事先将分隔符从“;”修改为其他符号,一般使用“//”。
我们可以使用 delimiter 命令将分隔符修改为“//”。
将分隔符修改为“//”
delimiter //如果将分隔符设置为“//”,那么即使在创建存储过程的途中输入了“;”也不会发生任何问题。
在 END 之后输入“//”,这时就会执行 CREATE PROCEDURE 命令。
存储过程创建结束后,使用“delimiter ;”将分隔符恢复为原始设置。
下面我们来实际操作一下。
创建一个执行“SELECT * FROM tb;”和“SELECT * FROM tb1;”的存储过程 pr1。
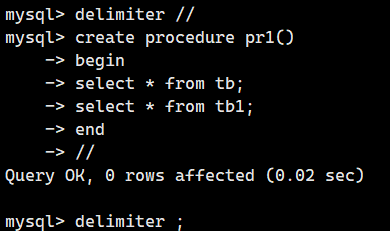
最后的“delimiter ;”是把分隔符恢复为“;”的命令。不要忘记恢复分隔符。
另外,一定要在存储过程名的后面加上()。之后会介绍将值作为参数放在存储过程中的示例,但即使不输入值也必须加上()。
- 执行存储过程
这样就创建好了存储过程 pr1 。下面我们来试着使用这个存储过程。执行存储过程需要使用 CALL 命令。
CALL 存储过程名;调用上一节创建的 prl 。
CALL pr1;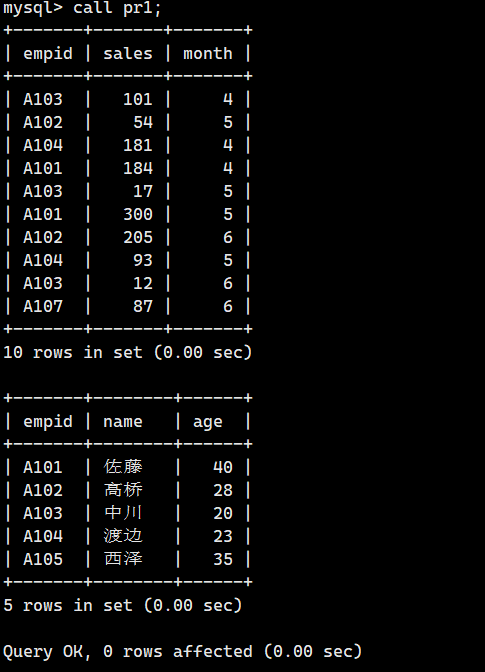
也是成功连续执行了“SELECT * FROM tb;”和“SELECT * FROM tb1;”这两条命令
1.3.创建只显示大于等于指定值的记录的存储过程
接下来试着创建带参数(→ 8.2.2 节)的存储过程。将需要处理的数据指定为()中的参数,并执行存储过程。
在存储过程中,我们可以像下面这样编写参数。
CREATE PROCEDURE 存储过程名 (参数名 数据类型);这里,我们来创建一个“显示销售额大于等于指定值的记录”的基本存储过程。
例如,当向存储过程 prpr 中指定整数类型参数 d 时,存储过程就可以编写为 PROCEDURE pr (d INT)。参数 d 在 SQL 语句中的编写方式与普通数值相同。
例如,当处理下面这种情况时,
- 显示表中 sales 大于等于参数 d 的记录
SQL 语句可以编写成如下形式。
SELECT * FROM tb WHERE sales>=d;下面我们就创建存储过程pr2。如果指定整数类型的参数d的值执行该存储过程,表tb中销售额大于等于d的记录就会显示出来。
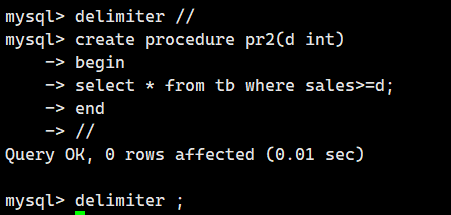
下面我们就试着把200指定为参数来执行存储过程pr2。
call pr2(200);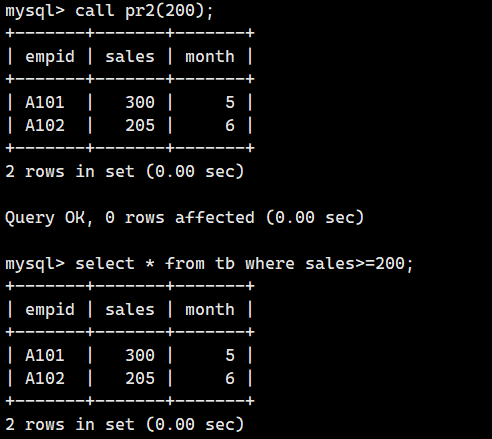
1.4.显示,删除存储过程
我们可以使用下面这个命令来显示存储过程的内容
show create procedure 存储过程名;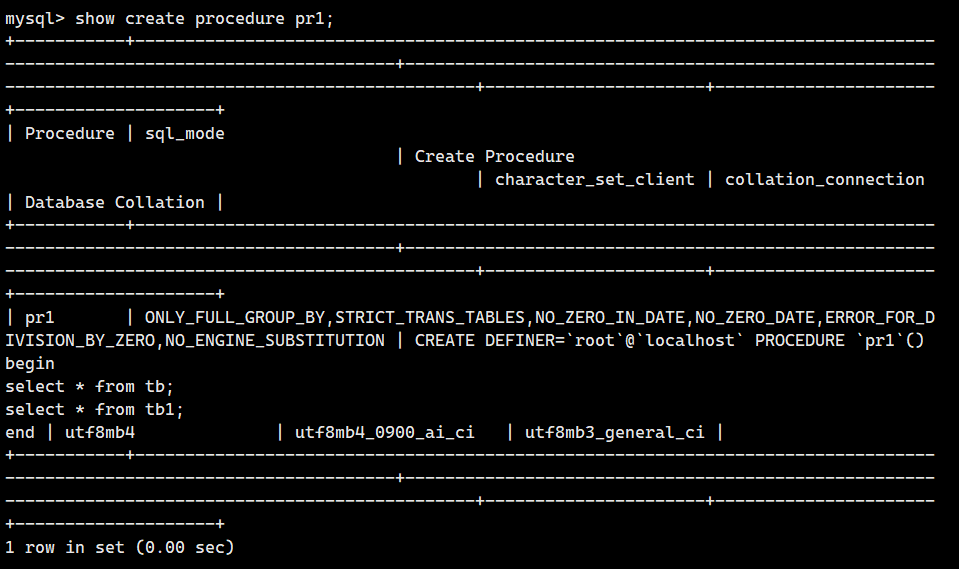
- 删除存储过程
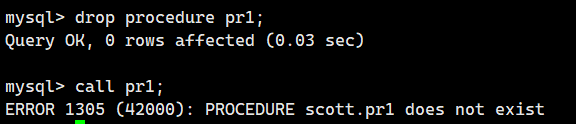
和删除数据库,表格,视图一样,我们可以使用drop命令删除存储过程
drop procedure 存储过程名;下面的执行结果表示删除了存储过程pr1
二. 存储函数
说明一下:存储函数只能在mysql5.0以及更高的版本中使用
2.1.什么是存储函数
如图所示, 存储函数(storedf Unction)的思考方式和操作方法与存储过程基本相同,与 存储过程唯一不同的一点是,存储函数在执行后会返回—个值。
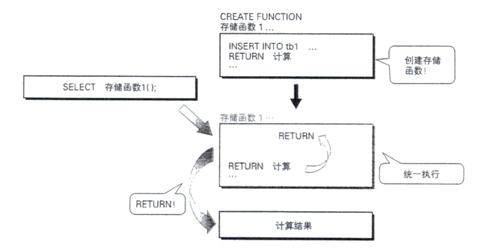
正如它的名字所表达的那样,存储函数可以作为函数工作。
虽然 MySQL 中有许多函数,但使用存储函数可以创建自定义的函数。所以存储函数也称为用户自定义函数。
存储函数返回的值可以在 SELECT 和 UPDATE 等命令中和普通函数一样使用。
我们可以使用以下语句创建存储函数。
CREATE FUNCTION 存储函数名(参数 数据类型)RETURNS 返回值的数据类型
BEGIN
SQL 语句
RETURN 返回值:表达式
END和存储过程一样,我们可以在()内指定参数。即使没有指定参数,也必须加上()。
例如,当创建了名为 f_u 的存储函数时,f_u() 本身将返回存储函数中 RETURN x x 的 x x 部分。
2.2.使用存储函数
2.2.1.使用存储函数之前
在使用存储函数之前需要修改一处设置。
存储函数有可能对复制和数据的恢复产生影响。
因此,参数 log_bin_trust_function_creators 的初始值被设置为 0,这样就不能使用存储函数了。
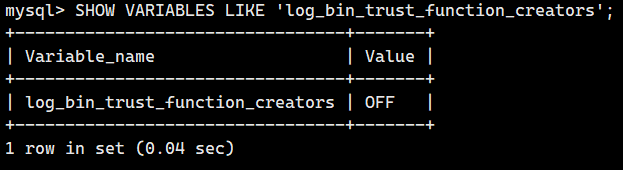
要想使用存储函数,就需要执行下面的操作修改此设置。
当然,在我介绍的范围内修改这个设置不会产生任何问题,请大家放心。
- 临时设置(重启失效)
-- 启用存储函数创建权限
SET GLOBAL log_bin_trust_function_creators = 1;
-- 验证设置是否生效
SHOW VARIABLES LIKE 'log_bin_trust_function_creators';- 永久设置(需修改配置文件)
编辑 MySQL 配置文件(如 my.cnf 或 my.ini):
log_bin_trust_function_creators = 1重启 MySQL 服务:
systemctl restart mysql我们这里只使用临时修改的方式来修改log_bin_trust_function_creators
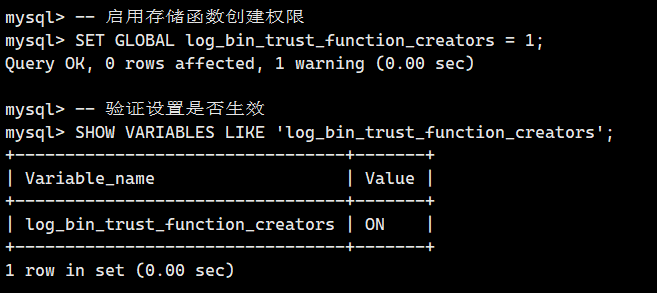
如果 log_bin_trust_function_creators 被设置成了 ON,就可以使用存储函数了。
另外,如果我们采用临时修改的方式的话,重新启动 MySQL,log_bin_trust_function_creators 的值将变回 OFF。如果想使用存储函数,就需要再次执行上述操作。
当然,也可以通过在 MySQL 的配置文件中或者在启动 MySQL 时指定相应的内容,让 log_bin_trust_function_creators 的值始终为 ON。
慎重起见,本书没有修改配置文件,而是通过修改 log_bin_trust_function_creators 的值进行了设置。
另外,使用存储函数还需要相应的权限。即使设置 log_bin_trust_function_creators=1,用户仍需具备 CREATE ROUTINE 权限才能创建存储函数。普通用户可能需要额外授权。
大家使用的 root 用户中已经包含了这个权限(Super 权限),但是普通用户就需要额外添加权限了。
2.2.2.使用存储函数计算标准体重
光看文字介绍可能不太容易理解存储函数。虽然和数据库这个主题不太相符,不过这里作为练习,我们来试着计算一下自己的标准体重。
如果 BMI=22 为标准体重,则有如下等式。
标准体重 = 身高(cm)× 身高(cm)× 22/10000
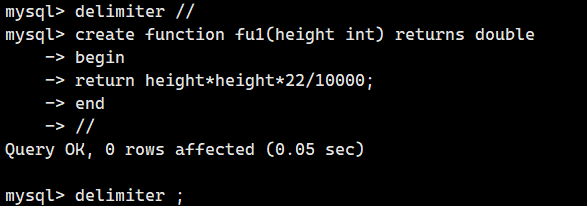
我们试着使用这个等式来创建存储函数 fun。
这里我们把以厘米为单位的身高值作为参数,并指定参数名为 height,类型为整数类型。
我们需要使用下面的命令在存储函数 fun 中指定 INT 类型的参数。
CREATE FUNCTION fun(height INT)存储函数自身会返回值。因此,必须对存储函数自身返回值的数值类型进行指定。
存储函数 fun 返回的是包含小数的标准体重,所以我们将存储函数 fun 返回值的数据类型指定为可以处理小数部分的 DOUBLE 类型。
具体命令如下所示。
CREATE FUNCTION fun(height INT) RETURNS DOUBLE接着在存储函数中,对输入的 height 值取平方,再乘以 22,然后除以 10000,最后通过 RETURN 返回计算出来的值。这部分内容需要用到如下命令。
RETURN height * height *22/10000;下面试着创建一个自定义的标准体重处理函数。创建以厘米为单位的身高值指定给参数height后,就能返回标准体重的存储函数fu1。
下面我们试着按身高180cm来计算一下标准体重。
这次让fu1作为函数来返回值。因此我们不使用 CALL,而是使用 SELECT命令来显示 fu1()的值。()内输人的参数值为180。
SELECT fu1(180);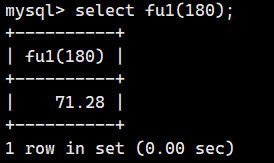
2.2.3.返回记录平均值的存储函数
试着创建一个存储函数来返回某列中数据的平均值。事先创建好这样的函数,使用的时域就会非常方便。
以下内容用于创建存储函数 `fu2` 来返回表中中列 `sales` 的平均值。
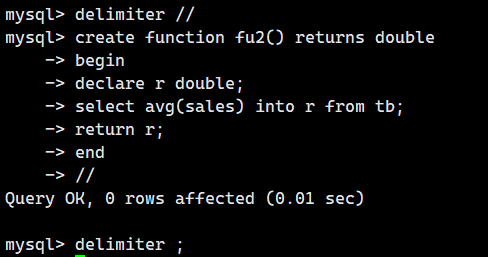
编程经验少的人可能不太明白变量的相关处理,这里我们先创建好这个存储函数。
变量的含义将在后面进行介绍。
目的部分与前一节一样,它用于定义存储函数 `fu2` 的返回值为 `DOUBLE` 类型。
CREATE FUNCTION fuz() RETURNS DOUBLE 平均值需要通过 `SELECT AVG()` 来计算。这个值必须赋给变量。我们可以把变量理解为“保管值的箱子”。要想使用变量,就需要事先通过 `DECLARE` 定义变量。
- 通过 DECLARE 定义变量
DECLARE 变量名 数据类型; 这里我们把变量名设置成了 `r`。平均值会输入到变量 `r` 中。为了能够处理小数部分,我们将数据类型指定为 `DOUBLE` 类型。
将变量 `r` 定义为 `DOUBLE` 类型的命令,即
DECLARE r DOUBLE; 下面的 SQL 语句用于从表中提取列 `sales` 的平均值。
SELECT AVG(sales) FROM tb; 把 `AVG(sales)` 赋给 `DECLARE` 中定义的变量 `r` 时需要使用 `INTO`。
于是,SQL 语句就变成了下面这部分
SELECT AVG(sales) INTO r FROM tb; 这样,平均值就输入到了变量 `r` 中。我们可以使用`RETURN` 让这个平均值作为存储函数的值返回。
return r;我们来使用一下
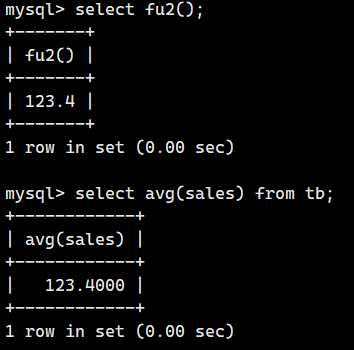
2.3.显示和删除存储函数
这个和上面的存储过程基本上是一模一样的。
- 查看存储函数
show create function 存储函数名;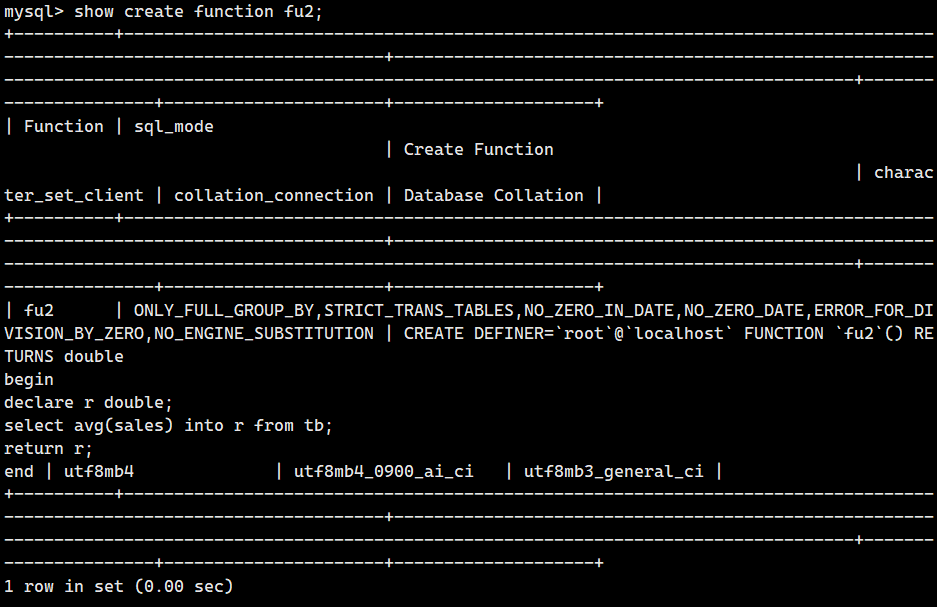
- 删除存储函数
drop function 存储函数名;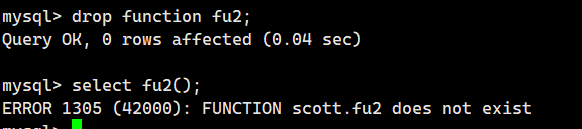
三. 触发器
3.1.什么是触发器
触发器(trigger)是一种对表执行某操作后会触发执行其他命令的机制。
当执行 INSERT、UPDATE 和 DELETE 等命令时,作为触发器提前设置好的操作也会被执行例如,创建一个触发器,当某表的记录发生更新时,就以此为契机将更新的内容记录到另一个表中。

触发器也常作为处理的记录或者处理失败时的备份使用。
触发器是一个非常强大的功能,只通过文字介绍很难了解到这个功能有哪些优点。
我们先创建一个触发器来体验一下。这里我们来创建一个“如果删除了表中的记录,被删除的记录就会复制到其他表中”的触发器。
也就是说,如果对表tb1执行“DELETE FROM tb1…;”命令,被删除的记录就会全部插人到表 tb1 _fom 中。
这样一来,我们就可以随时恢复已删除的记录了。
请事先创建一个空表tb1_from 用于插入表 tb1 中删除的记录。我们可以通过复制表 tb1 的列结构来创建这个表.
create table tb1_from like tb1;
3.2.创建触发器
3.2.1.触发器被触发的时机
- 触发器的触发时机
触发器可以在以下两种时机执行:
-
BEFORE:在对表进行 INSERT、UPDATE、DELETE 操作之前触发。
-
AFTER:在对表进行 INSERT、UPDATE、DELETE 操作之后触发。
- 访问新旧列值
通过 OLD 和 NEW 关键字可以访问操作前后的列值:
-
OLD.列名:获取操作前的列值(适用于 UPDATE 和 DELETE)。
-
NEW.列名:获取操作后的列值(适用于 INSERT 和 UPDATE)。
- 不同命令下 OLD/NEW 的可用性
| 命令 | BEFORE 触发时(OLD) | AFTER 触发时(NEW) |
|---|---|---|
| INSERT | ×(不可用) | ○(可用) |
| DELETE | ○(可用) | ×(不可用) |
| UPDATE | ○(可用) | ○(可用) |
3.2.2.创建触发器
实际操作一下会更容易理解。创建触发器的具体命令如下所示。
格式:创建触发器
CREATE TRIGGER 触发器名 BEFORE (或者 AFTER) DELETE 等命令
ON 表名 FOR EACH ROW
BEGIN
使用更新前 (OLD, 列名) 或者更新后 (NEW, 列名) 的处理
END在触发器主体的描述中,各个命令的末尾需要加上“.”。
与创建存储过程时相同,我们需要事先将分隔符改为“//”等。
下面来创建将表 tb1 中删除的记录插入到表 tb1_from 中的触发器。
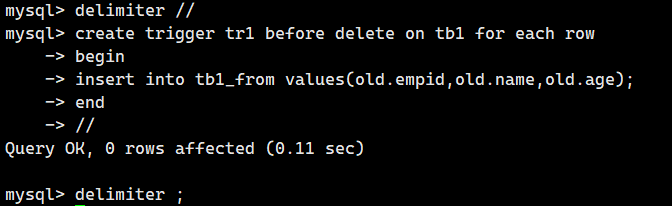
触发器创建成功了。
我们先来体验一下触发器的效果。
现在,表 tb1 中删除的记录应该能够插入到表 tb1_from 中了。不管是 1 条记录还是 2 条记录,触发器都会进行处理,所以我们干脆把所有记录都删掉,然后使用 “SELECT * FROM tb1;” 命令确认记录是否真的被删除了。
DELETE FROM tb1;
select * from tb1;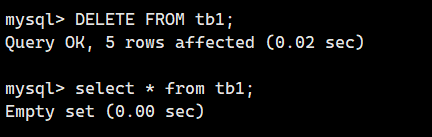
执行结果中显示了 Empty set,没有显示任何记录。表 tb1 中已经没有记录了。那么,设置的触发器是否正常工作了呢?下面,我们来看一下表 tb1_from 中的内容。
SELECT * FROM tb1_from;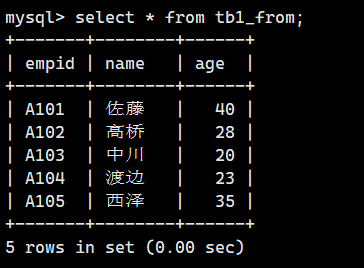
和我们预想的一样,删除的记录插入到了表 tb1_from 中。(SELECT 显示的顺序可能会发生改变。)
由此可见,触发器正常工作了。
在没有正常工作的情况下,请确认一下输入历史。大多是编写错误所致。我们可以使用 SHOW 命令来确认触发器的内容。如果发现触发器 tr1 的内容有问题,请使用 “DROP TRIGGER trl;” 予以删除,然后重新创建触发器。
下面将插入到表 tbl_from 中的记录恢复到原来的表 tbl 中。我们可以使用下面的命令进行复制。
INSERT INTO tb1 SELECT * FROM tb1_from;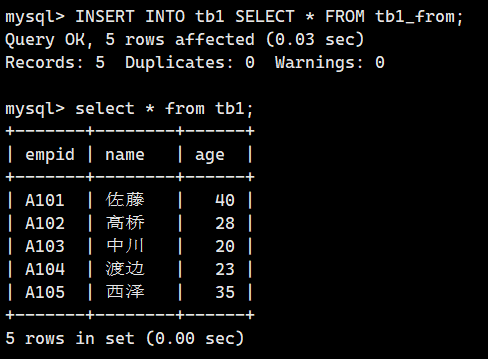
3.3.触发器的内容
下面看一下触发器的内容。
CREATE TRIGGER trl BEFORE DELETE ON tbl FOR EACH ROW
BEGIN
INSERT INTO tbl_from VALUES(OLD.empid,OLD.name,OLD.age);
END
//首先为表 tbl 的 DELETE 命令设置触发器 tr1。for each row就是对每一行都生效
因为要对删除之前(BEFORE)的值进行 INSERT,所以 CREATE TRIGGER 的部分需要编写成下面这样。
CREATE TRIGGER tr1 BEFORE DELETE ON tbl FOR EACH ROW提取删除记录前(BEFORE)的列值(OLD. 列名),并将其插入表 tb1_from 中。表 tb1_from 由列 empid、列 name 和列 age 组成,所以删除记录前的列值分别为 OLD.empid、OLD.name 和 OLD.age。
因为要使用 INSERT 命令将这些列值插入到表 tb1_from 中,所以触发器需要描述成下面这样。
INSERT INTO tb1_from VALUES(OLD.empid,OLD.name,OLD.age);该触发器的主体部分用 BEGIN 和 END 括了起来。
3.4.确认和删除触发器
3.4.1. 查看所有触发器
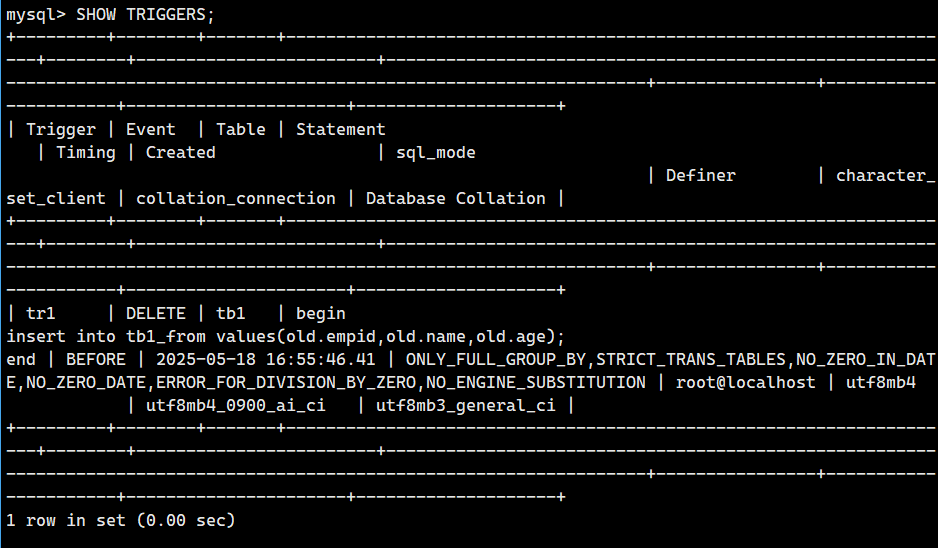
使用 SHOW TRIGGERS 命令可以列出当前数据库中的所有触发器及其基本信息:
SHOW TRIGGERS;输出字段说明
| 字段 | 含义 |
|---|---|
Trigger | 触发器名称(例如 trl)。 |
Event | 触发事件(如 DELETE、INSERT、UPDATE)。 |
Table | 触发器关联的表名(例如 tbl)。 |
Statement | 触发器执行的逻辑语句(例如 INSERT INTO tbl_from ...)。 |
Timing | 触发时机(BEFORE 或 AFTER)。 |
Created | 触发器创建时间。 |
sql_mode | 触发器创建时的 SQL 模式。 |
Definer | 触发器的创建者(用户和主机)。 |
3.4.2.删除触发器
为了防止意外执行处理’我们需要删除不需要的触发器。
drop tigger 触发器名;试着触发器tr1,请执行以下操作
drop trigger tr1;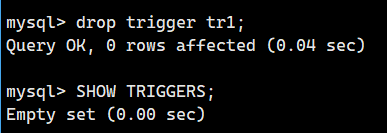
这样子触发器tr1就被删除了。