fcQCA模糊集定性比较分析法-学习笔记
模糊集定性比较分析(fsQCA,Fuzzy-set Qualitative Comparative Analysis) 是一种结合了定性和定量元素的研究方法,用于分析中小样本数据中的复杂因果关系。
1. 理解基础概念
QCA的核心思想:
基于集合论和布尔代数,关注条件(变量)的组合如何导致结果(而非单一变量的独立效应)。
区分必要性条件(必须存在的条件)和充分性条件(足以导致结果的条件)。
fsQCA的特点:
使用模糊集(0到1之间的隶属度),允许更精细的校准(如“部分隶属”)。
适用于案例数量较少(通常10~50个)但变量较多的研究。
1.1 集合论
论点:男人会长小JJ。
同义表达:
如果是一个男人,那么他会长小JJ。
长小JJ是男人的一个充分条件。
长小JJ是男人的一个子集。
1.2 模糊集
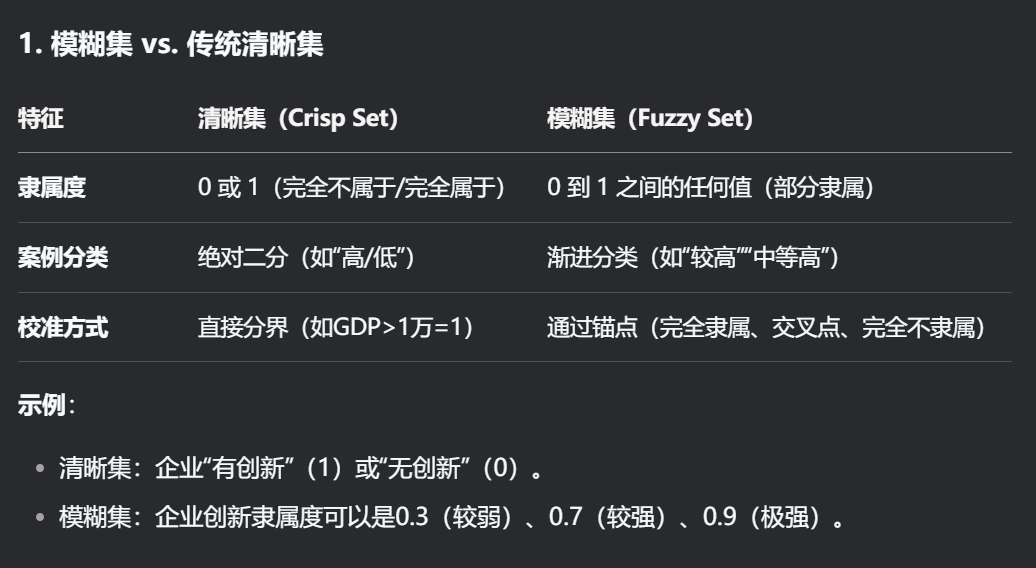
1.3 为什么需要“模糊”?
解决传统QCA的局限:
-
清晰集(csQCA) 要求严格二分,但现实中的社会现象(如“民主程度”“创新能力”)往往是渐进的。
-
模糊集 更贴合实际,允许“部分隶属”(如一个国家“某种程度上是民主的”)。
捕捉复杂因果关系
-
可分析条件不同程度的组合(如“高R&D投入+中等培训” vs. “中等R&D投入+高培训”)。
-
避免因粗暴二分导致信息丢失。
2 方法适用范围
fsQCA 适合研究中小样本(比如10-50个案例)中多个条件如何组合导致结果,尤其当这些条件不是独立起作用,而是依赖组合(比如‘高研发+低竞争’比单独某个因素更重要)。
类比:
回归分析像做菜时单独尝盐、糖的效果(线性关系)。
fsQCA像尝一道菜的整体味道(盐+糖+火候的组合效应)。
案例:研究“学生成绩优秀的原因”
适用 fsQCA 的情况:
样本:20个学生。
条件:学习时间(小时)、动机(评分1-5)、教师反馈(评分1-5)→ 需要模糊校准。
问题:是“高动机+中等反馈”还是“中等动机+高学习时间”更有效?
3.fsQCA的步骤
3.1 条件选择与模型构建
根据理论框架、参考权威文献的选择。
3.2 案例选择
基于已构建的研究框架,我首先确定研究样本,随后开展数据收集工作。在具体实施过程中,我通常根据框架中的研究结果和条件变量,设计相应的问卷量表来系统性地收集所需数据。
3.3 条件与结果校准
这部分比较重要。一般有两种
- 直接校准:人工设定锚点(适合理论明确时)。
# R语言示例:校准R&D投入
data$R_D_fs <- calibrate(data$R_D, thresholds = "e=0.05, c=0.10, i=0.20") # e=完全不隶属, c=交叉点, i=完全隶属
- 分位数校准:用数据分布(如P95=完全隶属,P50=交叉点,P5=完全不隶属)。
thresholds <- quantile(data$R_D, probs = c(0.05, 0.50, 0.95))
data$R_D_fs <- calibrate(data$R_D, thresholds = thresholds)
3.4 必要性分析
必要性分析是检查某个条件是否必须存在才能导致结果发生,就像‘氧气对火灾是必要的’(没有氧气一定没火灾,但有氧气不一定有火灾)

3.5 组态分析
下面两个部分,以及可视化,移步B站
总体讲解
图表美化