通俗解释Transformer在处理序列问题高效的原因(个人理解)
Transformer出现的背景
- CNN 的全局关联缺陷卷积神经网络(CNN)通过多层堆叠扩大感受野,但在自然语言处理中存在本质局限:
- 局部操作的语义割裂:每个卷积核仅处理固定窗口(如 3-5 词),需 12 层以上网络才能覆盖 50 词以上序列
- 位置信息的间接表征:依赖人为设计的位置嵌入(如 Word2Vec 的滑动窗口),无法直接建模非连续词间的语义关联
- RNN/LSTM 的序列依赖困境循环神经网络(RNN)及其改进版本(LSTM/GRU)在处理长序列时存在两大核心问题:
- 时序处理的串行化限制:依赖隐状态逐层传递,无法并行计算,训练效率随序列长度呈线性下降
- 长距离依赖衰减:即使引入门控机制,梯度消失问题仍导致超过 200 词的序列出现显著语义损耗
- 前向和反向传播:RNN 需要按时间步展开,前向和反向传播计算更加复杂,而 Transformer 则因其结构使得前向和反向传播更加高效和简洁
Transformer的结构解释
任务 处理灾区求救信号,生成救援指令:
输入信号(Encoder):
“山区公路积雪3米,断电,50人被困,急需发电机和医疗队”
输出指令(Decoder):
“派3台除雪车至A7公路,医疗队随行,协调电力公司恢复供电”
1. Encoder-Decoder 结构
Transformer 包含编码器和解码器两个主要部分。编码器负责接收输入序列,提取特征,生成一系列向量表示,解码器则根据这些向量表示生成输出序列。
Encoder-Decoder 结构 → 指挥中心与执行部门
- Encoder(情报分析组):
负责解读所有求救信息,提炼关键情报(积雪深度、断电位置、人数)。
就像指挥部里的地图标记员,把杂乱信息转化成标准标签。
- 输入:原始求救信号 “山区公路积雪3米,断电,50人被困,急需发电机和医疗队”
- 处理流程:
- 多头注意力:
- 交通组发现"积雪3米"和"公路"强相关 → 标记为道路封锁
- 医疗组关联"50人被困"和"医疗队" → 标记为大规模伤员
- FFN深化处理:
- 输入"积雪3米" → 匹配预案库 → 输出"需重型除雪车"
- 输出:一组带有完整语义的向量(即情报地图):
{ “位置”: “山区A7公路”, “灾情”: [“道路封锁-重型”, “电力中断”, “50人-紧急医疗”] }
- Decoder(救援调度组):
根据Encoder的情报+已派出的救援记录(如"已派2台除雪车"),动态生成新指令。
就像调度主任,边看地图边拿对讲机指挥。
- 输入:Encoder的情报地图 + 已生成的指令前缀(逐步生成)
- 分步生成示例:
- 初始输入:[开始]
- Decoder查询情报地图,发现最高优先级是"道路封锁" → 生成"派3台除雪车"
- 输入:[开始] + “派3台除雪车”
- 结合"位置:山区A7公路" → 生成"至A7公路"
- 输入:[开始] + “派3台除雪车至A7公路”
- 检查"50人-紧急医疗" → 追加"医疗队随行"
- 最终输出:
“派3台除雪车至A7公路,医疗队随行,协调电力公司恢复供电”
2. 多头自注意力机制(Multi-head Self-Attention)
这是 Transformer 的核心技术,允许模型在计算每个单词的表示时,同时关注输入序列中的不同位置。这种机制通过多个’头’(head)并行计算注意力(attention),然后将它们的结果合并,既增强了模型的表达能力,又保留了位置信息。
多头自注意力 → 多部门交叉验证情报
自注意力机制的作用是让模型动态计算句子中每个词与其他词的关系权重,从而决定在处理当前词时应该“关注”哪些其他词。
在上述示例中,假设是你来拨打报警电话(输入pompt)那么可能是这样的:
“你好,110吗,我在路上遭遇了雪灾,雪已经可以完全盖住我开的车了,现在车已经熄火了,温度太低基本上已经没电了,我附近大概有50个人左右,可能已经有人被埋了,你们快来救人”
比较上述示例: “山区公路积雪3米,断电,50人被困,急需发电机和医疗队” 在我们自己描述这一问题时,会引入一些人的表达习惯,信息密度较低
- 多头自注意力:
- 交通组同时分析"积雪3米"和"公路"→ 需要除雪车
- 医疗组关联"50人被困"和"医疗队"→ 需增派医生 就像多个专家小组用不同视角分析同一份数据,避免片面决策。
自注意力机制会自动学习这些关联权重,而不是依赖固定规则。
自注意力通过Query(Q)、Key(K)、Value(V)三个矩阵运算来计算词与词之间的相关性:
- Query(Q):当前词(如 “积雪3米”)的“提问”,表示它想关注哪些信息。
- Key(K):所有词的“索引”,用于匹配Query。
- Value(V):所有词的“实际内容”,用于加权求和。
2.1 计算过程
- 相似度计算(Q·K):计算当前词(Q)与其他词(K)的关联程度。
- 例如,“积雪3米” 的Query 和 “公路” 的Key 会有较高的点积值(因为它们相关)。
- Softmax归一化:转换成概率分布(权重)。
- 加权求和(Attention Output):用权重对Value(V)进行加权,得到当前词的最终表示。
公式:

2.2 通俗理解-并行计算
单头自注意力就像一个专家分析灾情,可能只关注某一方面(如交通)。而多头自注意力相当于多个专家团队(交通组、医疗组、电力组)同时分析同一份数据,各自关注不同方面的关联,最后汇总结果。
救灾示例:
- 交通组(Head 1):关注 “积雪3米” 和 “公路” → 计算除雪车需求
- 医疗组(Head 2):关注 “50人被困” 和 “山区” → 计算医疗队规模
- 电力组(Head 3):关注 “断电” 和 “发电机” → 计算电力恢复方案
最后,所有组的结论拼接(Concatenate)起来,形成更全面的决策。
2.3 学术视角
- 多头拆分:
- 输入的Q、K、V 被线性投影到多个(如8个)不同的子空间(使用不同的权重矩阵 WiQ,WiK,WiV)。
- 每个头独立计算注意力:
![[图片]](https://i-blog.csdnimg.cn/direct/f2b92604db8c499aaa38f7ca9d604f2a.png)
- 多头合并:
- 所有头的输出拼接后,再经过一次线性变换得到最终结果:
![[图片]](https://i-blog.csdnimg.cn/direct/09c43a046a904f5e986ec8f245902af2.png)
2.4 在示例中的完整流程
假设输入句子:
“山区公路积雪3米,断电,50人被困”
(1) 单头自注意力(简化版)
- 计算Q、K、V:
- 对每个词(如 “积雪3米”)生成Query、Key、Value。
- 计算注意力权重:
- “积雪3米” 的Query 会和 “公路” 的Key 计算高分值(强相关)。
- “积雪3米” 和 “断电” 的关联可能较低。
- 加权求和:
- “积雪3米” 的新表示 = 0.6 * “公路” + 0.3 * “山区” + 0.1 * “断电” (2)多头自注意力
- Head 1(交通视角):
- “积雪3米” 关注 “公路” → 输出 “需除雪车”
- Head 2(医疗视角):
- “50人被困” 关注 “山区” → 输出 “需大规模医疗队”
- Head 3(电力视角):
- “断电” 关注 “发电机” → 输出 “需紧急供电”
最终拼接:
Output=Concat(“需除雪车”,“需医疗队”,“需供电”)→综合决策Output=Concat(“需除雪车”,“需医疗队”,“需供电”)→综合决策
3. 位置编码(Positional Encoding)
由于 Transformer 是无序列化的(no recurrence),需要通过加入位置编码来引入位置信息,使模型能够区分序列中不同位置的元素。位置编码一般是基于正弦和余弦函数的,为每个位置生成独特的编码。
位置编码 → 灾情坐标标签 即使求救信号乱序: “断电,山区50人被困,积雪…”
通过位置编码(像给灾情GPS打坐标),模型仍知道"山区"是核心位置,"断电"是附属状态。
3.1 为什么需要位置编码
自注意力的缺陷:排列不变性
自注意力机制(Self-Attention)在计算时,词的顺序不影响其权重计算。也就是说,以下两个句子在自注意力看来是等价的:
- “公路积雪3米”
- “积雪3米公路”
但在现实中,词序至关重要(如 “先救援再评估” vs “先评估再救援” 完全不同)。
救灾示例:
- 输入 “A区雪崩,B区塌方” 和 “B区塌方,A区雪崩” 在自注意力看来是相同的,但实际上救援优先级完全不同!
- Transformer需要额外信息来感知词序,这就是位置编码的作用。 学术视角:序列建模的挑战 传统RNN/LSTM通过递归计算隐式编码位置信息(第t个词的隐藏状态依赖第t−1个词)。但Transformer的自注意力是并行计算的,没有天然的顺序概念,因此必须显式注入位置信息。
3.2 位置编码的解决方案
基本思路
在输入词嵌入(Word Embedding)上直接叠加位置信息,使得模型能区分:
- “公路(位置1)积雪(位置2)3米(位置3)”
- “积雪(位置1)公路(位置2)3米(位置3)”
两种主流方法
- 可学习的位置编码(Learned Positional Embedding)
- 直接训练一个位置嵌入矩阵(类似词嵌入)。
- 缺点:难以泛化到比训练更长的序列。
- 固定公式的位置编码(Sinusoidal Positional Encoding)
- 使用正弦/余弦函数生成位置编码(Transformer论文采用的方法)。
- 优点:可以扩展到任意长度序列。
计算公式

- 不同频率的正弦/余弦函数:低频(长周期)编码粗粒度位置,高频(短周期)编码细粒度位置。
![[图片]](https://i-blog.csdnimg.cn/direct/e4e71f5caf9b494a90851da59fdf426b.png)
4. 前馈神经网络(Feed-Forward Neural Networks) FFN
每个编码器和解码器层中都有一个基于位置的前馈神经网络,通常由两个全连接层组成,能够自动调整其参数,如加深网络学习更复杂的模式。
前馈神经网络 → 专业处置预案
Encoder提炼的情报(如"积雪3米"),会交给FFN这个预案库匹配具体行动:
- 输入:积雪深度3米
- 输出:需派出重型除雪车(轻型只能处理1米积雪)
就像预存的救灾手册,把抽象数据转化成具体设备型号。
4.1 基本定义
- FFN是Transformer中每个Encoder/Decoder层的核心组件之一,接收自注意力层的输出,进行非线性变换。其结构非常简单:
![[图片]](https://i-blog.csdnimg.cn/direct/08c1ffe8de1144429c3ad0cf1ecc48fa.png)
- 输入:自注意力输出的单个位置的向量(如 “积雪3米” 的编码向量)。
- 输出:同一位置的增强版表示。
- 关键特点
- 逐位置独立计算:每个词的FFN计算互不干扰(与自注意力的全局交互互补)。
- 两层全连接+ReLU:引入非线性,扩展模型容量。
- 维度变化:通常中间层维度更大(如输入512维→中间2048维→输出512维)。
- 为什么需要FFN
- 自注意力是线性变换+加权求和,缺乏复杂非线性映射能力。
- FFN通过ReLU激活函数和隐藏层,赋予模型分层次处理特征的能力(类似CNN中的卷积核堆叠)。
FFN就像救灾指挥中心的标准化预案执行器:
- 输入:自注意力分析的灾情摘要(如"积雪3米+公路")。
- 处理:通过非线性变换匹配具体行动(“派重型除雪车”)。
- 输出:机器可执行的精准指令,确保救援措施不偏离实际需求。
RNN用于处理序列数据的时间依赖关系,而FFN则用于对RNN的输出进行进一步的特征提取和分类
拓展:为什么都说Transformer的核心是self-attachment,而不是FFN?
![[图片]](https://i-blog.csdnimg.cn/direct/3388a1f00d1943d58fe977bd92f463d3.png)
4.2 技术细节
- 维度扩展设计
- 典型配置:输入512维 → 中间2048维 → 输出512维。
- 为什么扩展维度? 更大的中间层可以学习更复杂的特征组合(如积雪深度+公路类型+温度的综合判断)。
- 与残差连接的协作
FFN通常与残差连接(Add & Norm)配合:
![[图片]](https://i-blog.csdnimg.cn/direct/73069fc520a545748f0031e620a02254.png)
- 残差连接:防止梯度消失,保留原始信息(如确保"积雪"的语义不丢失)。
- LayerNorm:稳定训练,加速收敛。
4.3 完整示例
输入句子:“山区公路积雪3米,断电”
- 自注意力层:
- 计算"积雪3米"与"公路"的高权重,输出关联向量。
- FFN处理"积雪3米":
- 第一层:ReLU(0.3深度 + 0.7类型 - 0.2*海拔) → 激活值=1.2
- 第二层:1.2 * [重型设备权重] → 输出"重型除雪车"编码。
- 残差连接:
- 原始"积雪3米"向量 + FFN输出 → 最终增强表示。
5. 残差连接(Residual Connection)与层归一化(Layer Normalization)
每一个子层(如自注意力层和前馈神经网络层)之后都有一个残差连接和层归一化。这些技术可以加速网络的训练并提高模型的稳定性和收敛速度。
残差连接 → 抗通讯干扰 指挥中心电台可能受暴风雪干扰,导致指令断断续续。残差连接确保: 原始信号(“断电”) →
干扰后(“电…断”) → 仍能还原关键信息 就像通讯员重复确认:“您是说电力中断对吗?”
5.1 残差连接(Residual Connection)
(1) 核心思想:信息高速公路
学术定义:将模块的输入直接加到输出上,形成“短路”连接:
![[图片]](https://i-blog.csdnimg.cn/direct/b3dab2e59c98450486b096e67bf07462.png)
(其中SubLayer可以是自注意力或FFN)
救灾类比:
假设指挥中心处理灾情报告时:
- 原始报告(输入x):“A区积雪3米”
- 分析结果(SubLayer(x)):“需派除雪车”
- 残差输出:“A区积雪3米 + 需派除雪车” 为什么重要?
- 防止信息在深层网络中丢失(如“积雪3米”这一关键数据被误删)。
- 让梯度可以直接回传,缓解梯度消失问题。
(2) 数学性质
- 梯度传导:反向传播时,梯度可通过残差路径“无损”回传:
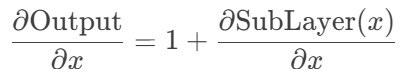
- 即使SubLayer的梯度趋近于0,总梯度仍能保持≥1。
(3) 救灾示例
- 无残差连接: 多次分析后,原始信息可能被覆盖: “积雪3米” → “需除雪” → “调车辆” → “协调司机”(最终丢失了关键数字“3米”)
- 有残差连接: 每步保留原始信息: “积雪3米” → [“积雪3米” + “需除雪”] → [“积雪3米” + “调3吨车”]
5.2 层归一化(Layer Normalization)
(1) 核心思想:稳定信号强度
学术定义:对单样本所有特征维度做归一化:
![[图片]](https://i-blog.csdnimg.cn/direct/1d3c2613d9b54de4bbe655ef85ae7616.png)
- μ,σ:该样本所有维度的均值/方差
- γ,β:可学习的缩放和偏移参数
救灾类比:
- 问题:不同灾情报告的数值尺度差异大(如积雪深度=3米 vs 被困人数=50人)。
- 解决:归一化到同一尺度,避免某些特征(如人数)主导模型。
- 结果:"积雪3米"和"50人"被统一到[-1,1]范围,模型更稳定。
(2) 与BatchNorm的区别
(3) 救灾示例
- 输入:[积雪深度=3, 断电电压=0, 被困人数=50]
- 计算:
![[图片]](https://i-blog.csdnimg.cn/direct/d83db79656054204b48c8243d2c898ac.png)
总结
- Encoder-Decoder结构
Encoder将输入序列(如求救信号)压缩为高维语义向量,Decoder基于该向量逐步生成目标序列(如救援指令),实现「情报分析」到「任务执行」的分工协作。 - 多头自注意力(Multi-Head Attention)
通过多组并行注意力机制(如交通组、医疗组、电力组)同时分析输入的不同关联模式,提升模型对复杂语义的捕捉能力。 - 位置编码(Positional Encoding)
为词嵌入添加正弦/余弦位置信号,使模型感知词序(如灾情报告的优先级),解决自注意力机制的排列不变性问题。 - 前馈神经网络(FFN)
对自注意力输出做非线性变换(如匹配救灾预案),将抽象特征转化为具体指令(如“积雪3米→派重型除雪车”)。 - 残差连接(Residual Connection)
将模块输入直接叠加到输出上(如保留原始灾情描述),防止深层网络中的信息丢失和梯度消失。 - 层归一化(Layer Normalization)
对单样本所有特征做归一化(如统一“积雪深度”和“被困人数”的数值范围),稳定训练并加速收敛。