无废话离线大模型安装
本文以qwen大模型为例,为大家展示大模型的离线安装过程,希望大家能够举一反三,快速掌握大模型离线部署的方法。
本文本硬件环境:
- ubuntu2204
- anaconda3
一、安装anaconda
1.下载安装脚本
#下载安装脚本
wget https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh

2.安装anaconda
sh Anaconda3-2022.10-Linux-x86_64.sh
执行上面的脚本后,会输出linsens信息,按q退出,进入下面的提示界面,直接按回车。
接下来输入yes
继续回车。

接下来提示是否初始化anaconda,输入yes,回车。
出现下图输出后,说明anaconda已经安装成功。
重启系统,conda就可以使用了。
按照我的习惯通过conda config --set auto_activate_base false禁用自启base环境,因为我的服务器上大都存在多个虚拟环境。
conda config --set auto_activate_base false
二、暴力安装大模型
1.创建虚拟环境
使用下面的命令创建一个名为qwen的虚拟环境,并指定python的大版本为3.10。
conda create -n qwen python=3.10
出现提示时直接回车进行即可。
👿 创建虚拟环境时,python的版本非常重要,要仔细阅读你要安装的大模型的model card,或github上的说明,如果非官方推荐的python版本可能会给你后续的使用带来无尽的折磨。
虚拟环境创建成功后,启动新创建的虚拟环境。
conda activate qwen
使用命令conda env list可以查看系统中所有的虚拟环境。
2.运行大模型
新建一个文件夹,用来放大模型的一些代码,进入这个文件夹。
接下来就要暴力安装运行大模型了,这里所说的暴力就是直接运行大模型,遇到什么错误解决什么错误。
在当前文件夹下新建一个quickstart.py文件,输入以下内容。
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B"model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)prompt = "Give me a short introduction to large language model."
messages = [{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)generated_ids = model.generate(**model_inputs,max_new_tokens=512
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
准备好梯子,使用以下命令运行这个quickstart.py脚本。
python quickstart.py
2.1 安装transformers
不出意外的话脚本会报错,如下图所示。

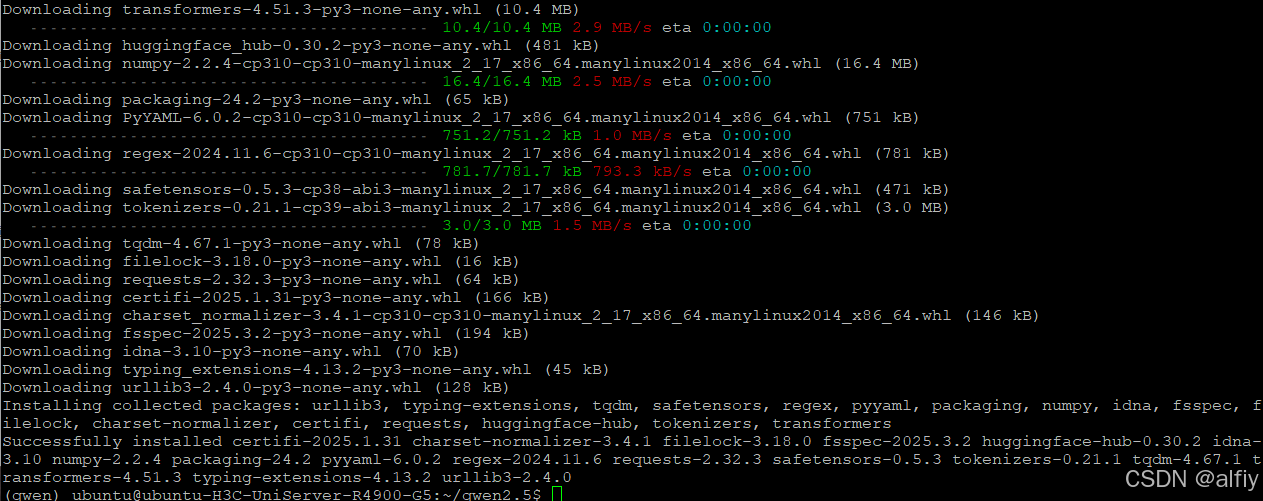
上图报错信息说明当前虚拟环境中没有transformers,使用下面的命令安装transformers.
pip install transformers
出现下图没有报错信息,说明transformers安装成功。
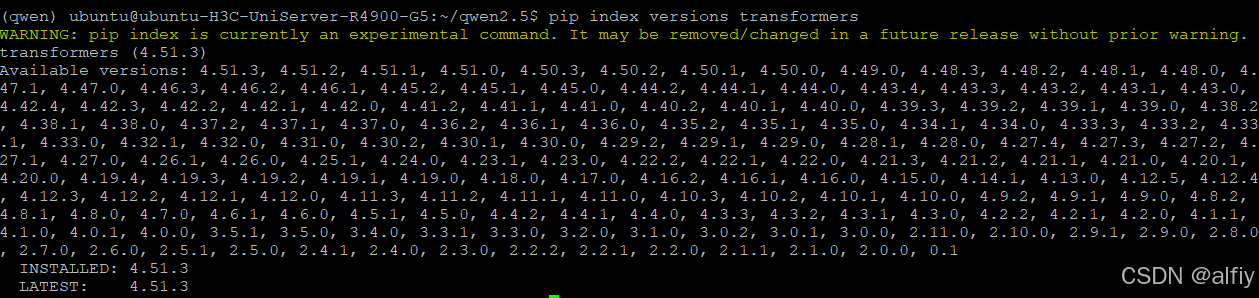
👿 有些模型对transformers的版本也是有要求的,要仔细阅读模型的相关资料。使用命令pip index versions <pip 包名>查看pip包中所包含的所有transformers的版本,然后使用命令pip install <pip包>==<版本号>来安装指定的版本。
2.2 安装torch
继续运行脚本,继续报错。

这次报错信息是缺少torch,使用下面的命令安装torch。
pip install torch

2.3 安装accelerate
继续运行脚本,继续报错:

根据错误提示可以看出缺少accelerate
安装accelerate
pip install accelerate

2.4 下载并运行大模型
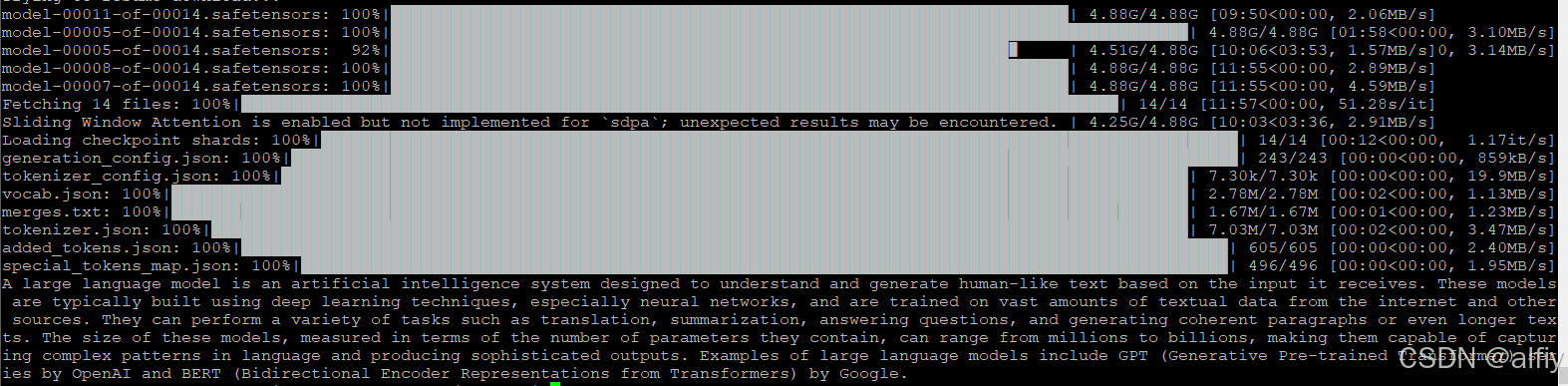
通过前面的安装,脚本已经不再报错了,出现下图所示,说明开始下载模型权重了,等下载完成后就能运行模型了。

👿 由于需要从huggingface网站上拉取模型,这个过程需要准备好了。
模型权重下载完毕,我们的quickstart.py脚本会打印一段话,下图说明模型权重已经下载并正常运行了。
三、使用VLLM运行模型
安装vllm
pip install vllm
使用vllm serve命令启动模型
vllm serve "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B" --tensor-parallel-size 4
使用上面的命令启动DeepSeek-R1-Distill-Qwen-32B大模型时竟然报错了,说是显存不足,不会吧我这可是四张4090啊?好吧研究一下问题出在哪里吧。
找到大模型的配置文件config.json,以下是DeepSeek-R1-Distill-Qwen-32B的配置文件。
{"architectures": ["Qwen2ForCausalLM"],"attention_dropout": 0.0,"bos_token_id": 151643,"eos_token_id": 151643,"hidden_act": "silu","hidden_size": 5120,"initializer_range": 0.02,"intermediate_size": 27648,"max_position_embeddings": 131072,"max_window_layers": 64,"model_type": "qwen2","num_attention_heads": 40,"num_hidden_layers": 64,"num_key_value_heads": 8,"rms_norm_eps": 1e-05,"rope_theta": 1000000.0,"sliding_window": 131072,"tie_word_embeddings": false,"torch_dtype": "bfloat16","transformers_version": "4.43.1","use_cache": true,"use_sliding_window": false,"vocab_size": 152064
}
请大家注意这一个配置 “max_position_embeddings”: 131072,,这里是配置模型支持的最大上下文长度的,这个值越大,所需的显存就越高,虽然我有4张4090,但还是跑不起32B模型的原因就在这里,调小这个值再次运行32B的模型,直到模型能够正常运行。
以下是我通过反复调整`max_position_embeddings’值后正常运行大模型的命令。
vllm serve "deepseek-ai/DeepSeek-R1-Distill-Qwen-32B" --tensor-parallel-size 4 --max-model-len 49152
👿 可以直接修改config.json配置文件,也可以在启动命令中指定参数。
📓 也可以将 “use_sliding_window”: false,修改成 “use_sliding_window”: true,
四、使用离线模型
使用huggingface-cli命令下载模型到本地。
huggingface-cli download DeepSeek-R1-Distill-Qwen-32B --local-dir ./DeepSeek-R1-Distill-Qwen-32B
编写启动脚本startDeepSeek.sh。
#!/bin/bash# 激活 Conda 环境
source /home/ubuntu/anaconda3/bin/activate qwen# 确保激活成功
if [ $? -ne 0 ]; thenecho "Failed to activate Conda environment 'qwen'"exit 1
fi# 启动vllm serve
nohup vllm serve "/home/ubuntu/deepseek/DeepSeek-R1-Distill-Qwen-32B" --tensor-parallel-size 4 --max-model-len 49152 --enable-auto-tool-choice --tool-call-parser hermes > /dev/null 2>error.log &
给脚本添加可执行权限
sudo chmod +x startDeepSeek.sh
新建一个管理大模型的服务deepseek.service。
sudo vim /lib/systemd/system/deepseek.service
添加以下内容
[Unit]
Description=DeepSeek-R1-Distill-Qwen-32B
After=network.target[Service]
Type=oneshot
ExecStart=/home/ubuntu/deepseek/startDeepSeek.sh
RemainAfterExit=yes[Install]
WantedBy=multi-user.target重载daemon-reload
sudo systemctl daemon-reload
使用systemctl就可以启动和关闭模型服务了。
sudo systemctl start deepseek
sudo systemctl stop deepseek
如果经过你的测试,离线模型没什么问题,就可以把你自定义的启动模型的服务添加到开机自启了。
systemctl enable deepseek
好了今天的分享就到这里,大家有问题在留言区留言问我,如果我有时间会回复大家的。