深度学习优化器详解:SGD、Adam与AdamW
优化算法详解:SGD、Adam与AdamW
一、SGD(随机梯度下降)
1.1 核心思想
SGD是最基础的优化算法,每次迭代仅使用单个样本或小批量样本计算梯度并更新参数。其核心公式为:
θ = θ - η * ∇θ J(θ; x_i)
其中η是学习率,∇θ J是损失函数对参数的梯度。
1.2 特点与局限
- 优点:计算效率高,适合大规模数据集;通过随机性可能跳出局部极小值。
- 缺点:
- 学习率固定,需手动调整;
- 梯度更新方向震荡严重,收敛速度慢;
- 对稀疏特征不友好。
二、Adam(自适应矩估计)
2.1 核心思想
Adam结合了动量法(Momentum)和RMSProp思想,通过动态调整每个参数的学习率实现自适应优化。其关键步骤如下:
- 一阶动量(均值):
m_t = β₁m_{t-1} + (1-β₁)g_t - 二阶动量(方差):
v_t = β₂v_{t-1} + (1-β₂)g_t² - 偏差修正:
m̂_t = m_t/(1-β₁^t),v̂_t = v_t/(1-β₂^t) - 参数更新:
θ_t = θ_{t-1} - η * m̂_t/(√v̂_t + ε)
其中β₁≈0.9,β₂≈0.999,ε防止除零。
2.2 优势与不足
- 优点:
- 自适应学习率,减少超参数调优;
- 适合非平稳目标和非凸优化问题;
- 对内存需求低。
- 缺点:
- 权重衰减实现方式可能导致参数收缩不足;
- 某些场景下泛化性能不如SGD。
三、AdamW(解耦权重衰减的Adam)
3.1 改进核心
AdamW将权重衰减(L2正则化)与梯度更新解耦,解决了Adam中权重衰减与自适应学习率耦合导致的优化偏差问题。其更新公式为:
θ_t = θ_{t-1} - η * (m̂_t/(√v̂_t + ε) + λθ_{t-1})
其中λ是独立的权重衰减系数。
3.2 关键改进点
- 权重衰减独立作用于参数更新,而非混入梯度计算;
- 提升模型泛化能力,尤其在深度网络中表现更优;
- 学习率调整更稳定,适合大规模预训练模型。
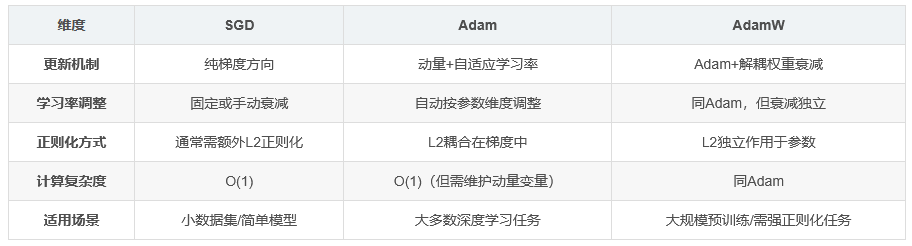
四、三者的核心区别
| 维度 | SGD | Adam | AdamW |
|---|---|---|---|
| 更新机制 | 纯梯度方向 | 动量+自适应学习率 | Adam+解耦权重衰减 |
| 学习率调整 | 固定或手动衰减 | 自动按参数维度调整 | 同Adam,但衰减独立 |
| 正则化方式 | 通常需额外L2正则化 | L2耦合在梯度中 | L2独立作用于参数 |
| 计算复杂度 | O(1) | O(1)(但需维护动量变量) | 同Adam |
| 适用场景 | 小数据集/简单模型 | 大多数深度学习任务 | 大规模预训练/需强正则化任务 |
五、实践建议
- SGD:适合数据量小、模型简单的场景,需配合学习率调度器;
- Adam:默认选择,快速收敛且调参简单,但需注意可能过拟合;
- AdamW:推荐用于Transformer、大语言模型等需要精细正则化控制的场景。