阿里云 dataworks maxcompute创建python脚本实现列转行 脚本demo示例。
问题 需要将如下数据结构实现,列转行。tag_group_name列转化为行。对应的列值就是 tag_name。(列转行不理解的同学好好思考一下)
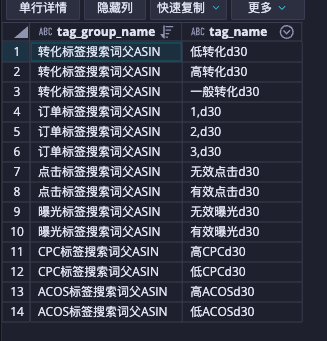
效果 已实现列转行
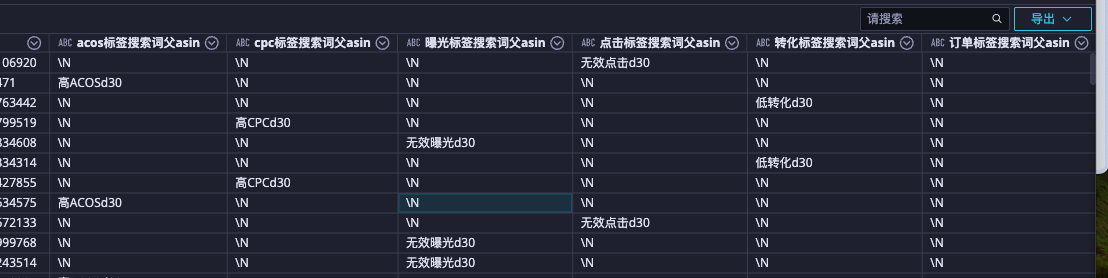
如下代码可以直接使用、本人已测试
'''PyODPS 3
请确保不要使用从 MaxCompute下载数据来处理。下载数据操作常包括Table/Instance的open_reader以及 DataFrame的to_pandas方法。
推荐使用 PyODPS DataFrame(从 MaxCompute 表创建)和MaxCompute SQL来处理数据。
更详细的内容可以参考:https://help.aliyun.com/document_detail/90481.html
'''
from odps import ODPS
from odps.df import DataFrame
import pandas as pd
from odps import options# 临时表
sql_str='''drop table if exists temp_lgr_label1; create table if not exists temp_lgr_label1 as select * from temp_lgr_label3WHERE top_parent_asin is not null'''odps.execute_sql(sql_str,hints={ "odps.sql.submit.mode" : "script"})# 取数
ref_df= DataFrame(o.get_table(name='temp_lgr_label1'))# 透视
# columns 需要列转行的列名
# values 列明对应的值标签值
ref_df2=ref_df.pivot(rows=[
'tenant_id','profile_id',"marketplace_id","seller_id","campaign_id","ad_group_id",'top_parent_asin','search_term',"keyword"], columns='tag_group_name', values='tag_name')# 持久化(将数据存储到另一个表中、无需自己建设表啊)
ref_df2.persist('temp_lgr_label2')特殊情况(如下问题都是本人实际工作中遇到,希望可以帮助到你)
问题1 如下原底表中存在行值是相同的情况,是无法实现行转列的。程序会报错,并且提示是哪条数据存在这样的问题。

解决方案
在底表中新增一个随机数字段,可以实现行专列
-- 解决列重复问题
concat(from_unixtime(unix_timestamp()),'_',cast(floor(rand() * 1000000) as string)) keyword
问题2 如果存在列名中包含特殊字符如下
‘+’, ‘-’, ‘.’, ‘*’, ‘?’, ‘(’, ‘)’, ‘[’, ‘]’, ‘~’, ‘|’, ‘$’,‘【’,‘】’
解决方案 通过如下逻辑可以进行解决
REGEXP_REPLACE(tag_group_name, '[\\+\\-\\.\\*\\?\\(\\)\\[\\]\\{\\}\\~\\|\\\\\\/\\$\\x{3010}\\x{3011}]', '')