IP数据报
IP数据报组成
IP数据报(IP Datagram)是网络中传输数据的基本单位。
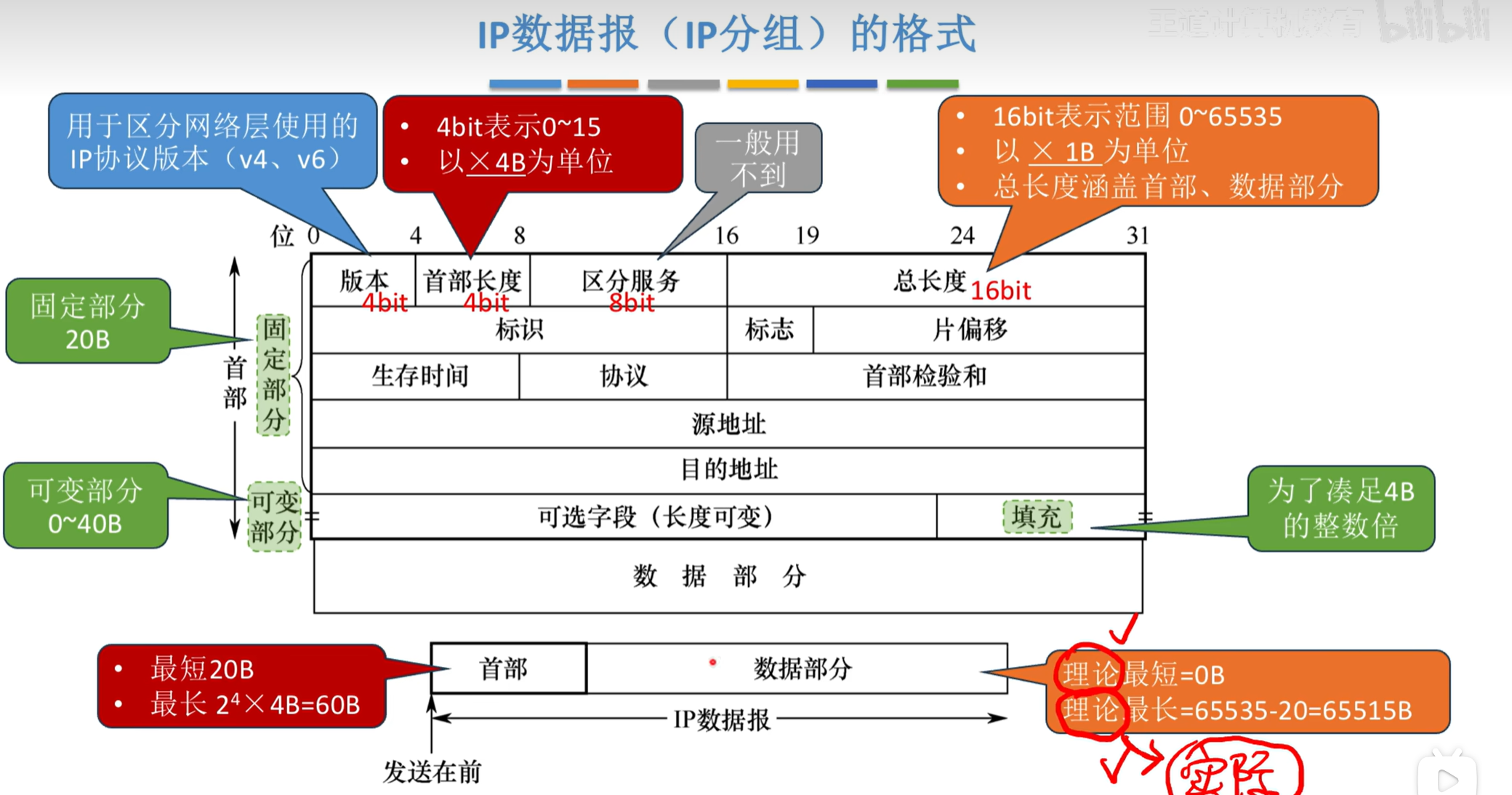
IP数据报头部
版本(Version)
4bit
告诉我们使用的是哪种IP协议。IPv4版本是“4”,IPv6版本是“6”。
头部长度(IHL,Internet Header Length)
4bit
表示IP数据报头部的长度,单位是32位(4字节)
比如:头部长度为“5”,表示头部有5个32位(5 * 4字节)。
服务类型(TOS,Type of Service)
8bit
总长度(Total Length)
16bit
整个IP数据报的长度,包括头部和数据部分,单位是字节。
比如:如果总长度是“1500字节”,那么数据包的大小就是1500字节。
标识符(Identification)
每个数据报都有一个唯一的ID,用于当数据报被分段 (IP数据报大于MTU)时,帮助接收端正确地把这些分段重新组合成完整的数据包。
标识符(Identification)字段 是一个 16 位的数字
比如:如果一个数据报被分成了多个小分段,它们会使用相同的标识符来标记属于同一个数据报。
标志(Flags)
用来指示数据包是否被分段,以及是否还有后续的分段。常见的标志有“更多分段”(More Fragment)标志。
比如:如果有“更多分段”标志,表示这不是数据包的最后一部分。
IP标志字段一共有3位(bit):但实际上只用到了中间两位,如下:
| 名称 | 位置 | 含义 | 通俗解释 |
|---|---|---|---|
| 第0位 | 保留位 | 一般是0 | 没啥用,先放着 |
| 第1位 | DF(Don't Fragment) | 不许分段 | 如果设置了这个为1,路由器不能对数据包切片 |
| 第2位 | MF(More Fragments) | 后面还有分段 | 如果这个为1,说明还有“下一段”数据 |
分段偏移(Fragment Offset)
网络中,IP数据报有最大大小限制(MTU),当数据太大,就要被“切片”——也就是分段传输。
每一段都需要带一个“偏移量”,告诉接收方:我是哪一段,拼到原始数据的哪里去。
假设原始数据有 4000字节,但网络限制每个IP数据包最多只能传 1500字节。
IP协议就会把它分成三段:
| 段号 | 数据大小 | 分段偏移(单位是8字节) | 实际字节范围 |
|---|---|---|---|
| 第1段 | 1480字节 | 0 | 第0到1479字节 |
| 第2段 | 1480字节 | 185(=1480/8) | 第1480到2959字节 |
| 第3段 | 1040字节 | 370(=2960/8) | 第2960到3999字节 |
注意:分段偏移是按8字节为单位的,不是直接表示字节位置。每个分片的数据部分(不是总长度)必须是 8 字节的整数倍(8 的倍数),除了最后一个分片可以不是。
生存时间(TTL,Time to Live)
TTL 是一个数字,表示最多可以经过多少个路由器。限制数据包在网络中的生命时间
。每经过一个路由器,TTL值就减少1。当TTL值为0时,数据包会被丢弃(丢弃它的路由器会发送一个 ICMP 错误报文),防止在网络中无限循环。
协议(Protocol)
标识数据部分使用的上层协议。例如,如果是TCP协议,它会标识为6;如果是UDP协议,它会标识为17。
头部校验和(Header Checksum)
用来检查IP头部是否发生了错误。如果计算的校验和与接收到的校验和不匹配,说明数据包头部有错误。
比如:它可以帮助网络设备确保头部数据没有损坏。
源IP地址(Source IP Address)
表示数据包的发送者IP地址。
比如:如果源IP是“192.168.1.1”,说明这个数据包是从IP为“192.168.1.1”的设备发出的。
目标IP地址(Destination IP Address)
表示数据包的接收者IP地址。
比如:如果目标IP是“10.0.0.2”,说明数据包的目的地是IP为“10.0.0.2”的设备。
选项(Options)(可选)
有时可以在头部加上一些特殊的选项,如安全设置、时间戳等。这部分通常不是很常用。
比如:某些网络可能要求对数据包进行时间戳记录。
填充(Padding)
如果头部需要调整为32位的倍数,填充字段会添加额外的零,确保头部的总长度是4的倍数。
IP数据部分
IP数据报分片问题

| 字段 | 含义 |
|---|---|
| Identification | 所有分片有相同值,接收端靠它来识别“属于同一个原始数据包” |
| Fragment Offset | 分片在原始数据中的起始位置,单位是 8 字节 |
| MF(More Fragments) | 如果还有后续分片,就设为 1;最后一片设为 0 |
| Total Length | 每个分片自身的总长度(= IP头 + 数据部分) |
| 规则 | 说明 |
|---|---|
| 除最后一片外,每个分片数据部分长度必须是 8 的整数倍 | 因为偏移量单位是 8 字节 |
| 所有分片都必须带 IP 头 | 每个都是一个合法 IP 数据报 |
| 接收端根据:源地址 + 标识符 + 偏移量 来重组数据 | |
| 最后一片的 MF = 0,表示结束 |