LLM笔记(一)基本概念
LLMs from scratch
Developing an LLM: Building, Training, Finetuning
-
LLM 的基本概念与定义:
- LLM是深度神经网络模型,能够理解、生成和解释类似人类的语言。
- “大型”指的是模型参数数量巨大以及训练数据集的规模庞大。
- LLM通常基于Transformer架构,并通过在海量文本数据上进行下一词预测的任务进行训练。
- LLM是生成式人工智能 (Generative AI / GenAI) 的一种形式,处于人工智能 (AI) > 机器学习 (Machine Learning) > 深度学习 (Deep Learning) > LLM 的层级关系中。
-
LLM 的核心能力与学习范式 :
- 文本补全为核心,展现通用性: GPT模型虽然主要设计用于执行文本补全任务,但其能力展现出了非凡的通用性。
- 零样本与少样本学习: 这些模型擅长执行零样本学习 (zero-shot learning)(在没有任何先验特定示例的情况下,对完全陌生的任务进行泛化的能力)和少样本学习 (few-shot learning)(从用户提供的极少示例中进行学习)。
- 涌现行为 (Emergent Behavior): 模型执行其未经过专门训练的任务的能力被称为涌现行为。这种能力并非在训练过程中被明确教授,而是模型在各种不同情境下接触大量多语言数据后自然产生的结果。GPT模型能够“学习”语言之间的翻译模式并执行翻译任务,尽管它们并未针对翻译进行专门训练,这一事实彰显了这些大规模生成式语言模型的优势与能力。我们无需为每种任务使用不同的模型,就能执行各种各样的任务。
-
LLM 的应用:
- 应用广泛,包括机器翻译、文本生成(小说、代码)、情感分析、文本摘要、聊天机器人(如ChatGPT, Gemini)、知识检索等。
- 核心能力在于解析和生成文本。
-
构建、训练和应用LLM的阶段 (Phases of Building, Training, and Applying LLMs):
-
LLM的开发和应用通常遵循一个多阶段的过程,从基础构建到专业化应用。
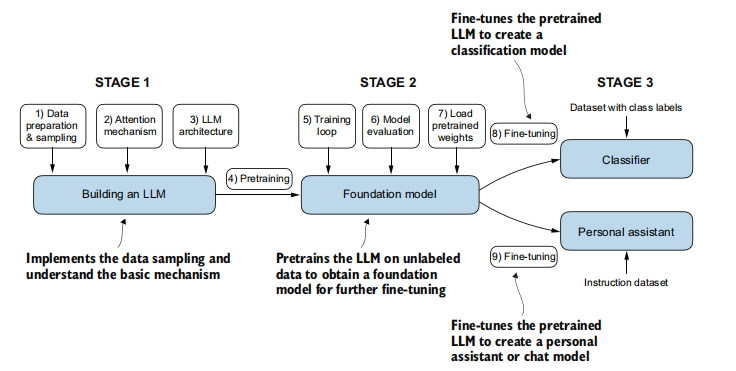
-
第一阶段:构建LLM与预训练 (Phase 1: Building the LLM and Pretraining)
- 这个阶段专注于实现数据采样技术并理解LLM开发的基本机制,最终目标是形成一个基础模型 (foundation model)。
- 数据准备与采样 (Data Preparation and Sampling): (详见第7点) 为预训练准备大规模、多样化的文本数据集。
- LLM架构设计 (LLM Architecture Design): (详见第1, 5, 8点) 选择或设计合适的模型架构,通常基于Transformer。
- 理解核心机制 (Understanding Core Mechanisms):
- 注意力机制 (Attention Mechanism): (详见第5点) 理解并实现如自注意力这样的核心组件。
- 预训练 (Pretraining): 在大规模、多样化的未标记文本数据上训练模型,使其获得对语言的广泛理解。预训练通常非常昂贵,需要大量的计算资源(如GPU/TPU)。
- 训练循环 (Training Loop): 实现并优化模型训练的迭代过程。
-
第二阶段:基础模型的评估与微调 (Phase 2: Foundation Model Evaluation and Fine-tuning)
- 这个阶段涉及在无标签数据上预训练LLM后,对形成的基础模型进行评估,并根据特定需求进行进一步的调整和优化。
- 加载预训练权重 (Loading Pretrained Weights): 可以加载已有的预训练模型权重作为起点,以节省资源和时间。
- 模型评估 (Model Evaluation): 对预训练的基础模型在标准基准测试集或特定任务上进行性能评估,以了解其通用能力和潜在瓶颈。
- 微调 (Fine-tuning): 在一个更小、针对特定任务或领域的已标记数据集上进一步训练预训练好的模型。
-
第三阶段:专业应用 (Phase 3: Specialized Applications)
- 基础模型可以通过不同方向的微调进行特化,以适应具体的应用场景:
- 分类微调 (Classification Fine-tuning): 使用包含类别标签的数据集进行微调,创建专门的分类器(例如,垃圾邮件分类、情感分析)。
- 指令微调 (Instruction Fine-tuning): 使用包含指令和对应输出的数据集进行微调,创建能够理解并执行用户指令的个人助手或聊天模型(例如,进行问答、按要求翻译、生成特定风格的文本)。
- 基础模型可以通过不同方向的微调进行特化,以适应具体的应用场景:
-
构建自定义LLM的优势:
- 针对特定领域或专有数据可能表现更好。
- 更好地控制数据隐私和安全。
- 可根据需求进行本地部署,降低对外部服务的依赖。
- 能够更灵活地调整模型架构和训练过程以满足特定需求。
-
-
Transformer 架构简介与LLM的关系 :
- 现代LLM大多依赖于2017年提出的Transformer架构。因此,“Transformer”和“大语言模型”这两个术语在文献中常被互换使用。
- 重要区分 :
- 并非所有Transformer都是大语言模型,因为Transformer也可用于计算机视觉等其他领域。
- 同样,并非所有大语言模型都基于Transformer,因为也有基于循环 (recurrent) 和卷积 (convolutional) 架构的大语言模型。这些替代方法背后的主要动机是提高大语言模型的计算效率。这些替代的大语言模型架构能否与基于Transformer的大语言模型的能力相媲美,以及它们是否会在实际中被采用,仍有待观察。
- 为简单起见,本书中使用的“大语言模型”一词特指类似于GPT的基于Transformer的大语言模型。(感兴趣的读者可在附录B中找到描述这些架构的文献参考。)
- 原始Transformer架构包含编码器 (Encoder)(处理输入文本)和解码器 (Decoder)(生成输出文本)两个子模块。
- 核心是自注意力机制 (Self-attention mechanism),允许模型在处理序列时权衡不同部分的重要性,有效捕捉长距离依赖关系。
- BERT等模型主要利用编码器部分,适用于文本分类、命名实体识别等理解型任务。
- GPT等模型主要利用解码器部分,擅长文本生成、对话等生成型任务。
-
嵌入 (Embeddings) 的概念与重要性:
- 本质: 从本质上讲,嵌入是一种从离散对象(如单词、图像甚至整个文档)到连续向量空间中的点的映射。这些向量表示旨在捕捉对象的语义关系。
- 目的: 嵌入的主要目的是将非数字数据(如文本)转换为神经网络可以有效处理和学习的数值格式。
- 类型与应用: 虽然词嵌入是最常见的文本嵌入形式,但也存在用于句子、段落或整个文档的嵌入。句子或段落嵌入是检索增强生成 (Retrieval Augmented Generation, RAG) 的常用选择。检索增强生成将生成(如生成文本)与检索(如搜索外部知识库)相结合,以便在生成文本时提取相关信息,这是一种超出本书范围的技术。由于本书的目标是训练类似GPT的大语言模型,这些模型学习一次生成一个单词,因此将专注于词嵌入。
- 维度: 词嵌入可以有不同的维度,从几十维到数千维不等。更高的维度可能会捕捉到更细微的语义关系和上下文信息,但代价是计算复杂度的增加和所需训练数据的增多。
-
大型数据集的应用与数据准备:
- LLM的强大能力得益于其在包含数十亿甚至数万亿词语的庞大数据集(如CommonCrawl, WebText2, Books, Wikipedia等公开数据集,以及可能的专有数据集)上的训练。
- 数据准备是预训练阶段的关键步骤,包括:
- 数据收集: 从多种来源获取海量文本数据。
- 数据清洗: 去除噪声、重复内容、格式转换等。
- 数据过滤: 筛选高质量、相关的文本。
- 分词 (Tokenization): 将文本切分成模型可以处理的单元(如单词、子词)。
- 数据采样 (Data Sampling): 从大规模数据集中选择合适的子集进行训练,或者在混合不同来源数据时调整其比例,以确保数据的多样性和代表性。
- 这些数据使得模型能够学习语言的句法规则、语义含义、上下文关联,甚至一定程度的常识和世界知识。
-
GPT 架构的特点:
- GPT (Generative Pre-trained Transformer) 模型通常是仅解码器 (decoder-only) 的Transformer架构,这使得其结构相比于包含编码器和解码器的完整Transformer更为简洁,特别适合生成任务。
- 它们是自回归模型 (autoregressive model),即逐个词元 (token) 地生成文本。在生成每个新词元时,模型会将先前所有已生成的词元作为上下文输入,来预测下一个最可能的词元。