Python大型数组计算完全指南:从基础到分布式系统实践
引言:大型数组处理的现代挑战
在大数据时代,处理GB甚至TB级别的数组已成为常态。根据2024年数据工程报告:
90%的数据科学项目涉及10GB+数组处理
75%的机器学习模型受限于内存瓶颈
60%的数据处理时间花在I/O操作上
Python作为数据科学的首选语言,提供了强大的大型数组处理工具链。本文将深入解析Python大型数组技术体系,结合Python Cookbook精髓,并拓展科学计算、金融分析、图像处理等工程级应用场景。
一、核心工具:NumPy高效数组
1.1 数组创建优化
import numpy as np# 高效创建大型数组
large_array = np.zeros((10000, 10000), dtype=np.float32) # 400MB预分配
random_array = np.random.rand(10000, 10000) # 随机数组# 内存映射文件
mmap_arr = np.memmap('large_array.dat', dtype=np.float32, mode='w+', shape=(10000, 10000))
mmap_arr[:] = np.random.rand(10000, 10000) # 磁盘存储# 稀疏矩阵
from scipy.sparse import csr_matrix
sparse_mat = csr_matrix((10000, 10000), dtype=np.float32)1.2 向量化操作
# 非向量化(低效)
def slow_calc(arr):result = np.zeros_like(arr)for i in range(arr.shape[0]):for j in range(arr.shape[1]):result[i, j] = arr[i, j] * 2 + 1return result# 向量化(高效)
def fast_calc(arr):return arr * 2 + 1# 性能对比
large_arr = np.random.rand(5000, 5000)%timeit slow_calc(large_arr) # 约15秒
%timeit fast_calc(large_arr) # 约0.1秒二、内存优化技术
2.1 内存映射文件
def process_large_file(file_path):"""处理超大型数组文件"""# 创建内存映射mmap = np.memmap(file_path, dtype=np.float32, mode='r', shape=(100000, 100000))# 分块处理block_size = 1000results = []for i in range(0, mmap.shape[0], block_size):for j in range(0, mmap.shape[1], block_size):block = mmap[i:i+block_size, j:j+block_size]processed = process_block(block) # 处理每个块results.append(processed)return combine_results(results)def process_block(block):"""处理数据块"""# 示例:计算块的平均值return np.mean(block)2.2 数据压缩存储
import bloscdef compress_array(arr):"""压缩大型数组"""# 序列化数组serialized = arr.tobytes()# 高性能压缩compressed = blosc.compress(serialized, typesize=arr.itemsize)return compresseddef decompress_array(compressed_data, dtype, shape):"""解压缩数组"""serialized = blosc.decompress(compressed_data)return np.frombuffer(serialized, dtype=dtype).reshape(shape)# 测试
large_arr = np.random.rand(5000, 5000)
compressed = compress_array(large_arr)
restored = decompress_array(compressed, np.float64, (5000, 5000))print(f"压缩率: {len(compressed)/large_arr.nbytes:.2%}") # 约15-30%三、分块处理策略
3.1 通用分块处理器
class ChunkProcessor:"""大型数组分块处理器"""def __init__(self, array, chunk_size=1000):self.array = arrayself.chunk_size = chunk_sizeself.shape = array.shapedef apply(self, func, axis=0):"""沿指定轴应用函数"""results = []for i in range(0, self.shape[axis], self.chunk_size):# 创建切片slices = [slice(None)] * len(self.shape)slices[axis] = slice(i, i+self.chunk_size)# 处理块chunk = self.array[tuple(slices)]result = func(chunk)results.append(result)return np.concatenate(results, axis=axis)# 使用示例
large_arr = np.random.rand(10000, 10000)
processor = ChunkProcessor(large_arr, chunk_size=1000)# 计算每列均值
col_means = processor.apply(np.mean, axis=0)
print(f"列均值计算完成: {col_means.shape}")3.2 图像分块处理
def process_large_image(image_path, output_path, block_size=512):"""处理超大型图像"""import imageio.v3 as iiofrom skimage import filters# 内存映射读取img = iio.imread(image_path)# 创建输出文件output = np.memmap(output_path, dtype=img.dtype, mode='w+', shape=img.shape)# 分块处理for i in range(0, img.shape[0], block_size):for j in range(0, img.shape[1], block_size):# 提取块block = img[i:i+block_size, j:j+block_size]# 处理块 (示例: 高斯模糊)processed = filters.gaussian(block, sigma=2)# 写回output[i:i+block_size, j:j+block_size] = processed# 保存结果iio.imwrite(output_path, output)return output_path四、并行计算技术
4.1 多进程处理
from concurrent.futures import ProcessPoolExecutordef parallel_array_processing(arr, func, n_workers=4, chunk_size=1000):"""并行处理大型数组"""# 创建分块索引chunks = []for i in range(0, arr.shape[0], chunk_size):chunks.append(arr[i:i+chunk_size])# 并行处理with ProcessPoolExecutor(max_workers=n_workers) as executor:results = list(executor.map(func, chunks))# 合并结果return np.vstack(results)# 使用示例
def process_chunk(chunk):"""处理数据块 (示例: 标准化)"""return (chunk - np.mean(chunk)) / np.std(chunk)large_arr = np.random.rand(10000, 1000)
processed = parallel_array_processing(large_arr, process_chunk)4.2 Dask分布式计算
import dask.array as dadef dask_large_computation():"""使用Dask处理超大型数组"""# 创建Dask数组 (100GB虚拟数组)x = da.random.random((100000, 100000), chunks=(1000, 1000))# 分布式计算y = x + x.Tz = y.mean(axis=0)# 触发计算result = z.compute()return result# 集群部署
from dask.distributed import Clientdef run_on_cluster():"""集群部署计算"""client = Client("scheduler-address:8786") # 连接到调度器result = dask_large_computation()return result五、GPU加速技术
5.1 CuPy基础使用
import cupy as cpdef gpu_matrix_multiply(A, B):"""GPU加速矩阵乘法"""# 传输数据到GPUA_gpu = cp.asarray(A)B_gpu = cp.asarray(B)# GPU计算C_gpu = cp.dot(A_gpu, B_gpu)# 传回结果return cp.asnumpy(C_gpu)# 性能对比
n = 5000
A = np.random.rand(n, n)
B = np.random.rand(n, n)%timeit np.dot(A, B) # CPU: 约5秒
%timeit gpu_matrix_multiply(A, B) # GPU: 约0.2秒5.2 Numba CUDA加速
from numba import cuda@cuda.jit
def cuda_kernel(input_array, output_array):"""CUDA核函数"""i, j = cuda.grid(2)if i < input_array.shape[0] and j < input_array.shape[1]:output_array[i, j] = input_array[i, j] * 2 + 1def numba_gpu_acceleration(arr):"""Numba GPU加速"""# 复制数据到设备d_arr = cuda.to_device(arr)d_result = cuda.device_array_like(arr)# 配置线程块threads_per_block = (16, 16)blocks_per_grid_x = (arr.shape[0] + threads_per_block[0] - 1) // threads_per_block[0]blocks_per_grid_y = (arr.shape[1] + threads_per_block[1] - 1) // threads_per_block[1]blocks_per_grid = (blocks_per_grid_x, blocks_per_grid_y)# 启动核函数cuda_kernel[blocks_per_grid, threads_per_block](d_arr, d_result)# 复制回结果return d_result.copy_to_host()# 使用
large_arr = np.random.rand(5000, 5000)
result = numba_gpu_acceleration(large_arr)六、金融数据分析应用
6.1 大型时间序列处理
def process_financial_data(file_path):"""处理大型金融时间序列"""# 使用Dask读取CSVimport dask.dataframe as ddddf = dd.read_csv(file_path, parse_dates=['timestamp'])# 计算移动平均ddf['MA_30'] = ddf['price'].rolling(window=30).mean()# 计算收益率ddf['return'] = ddf['price'].pct_change()# 分块相关性计算def chunk_correlation(chunk):return chunk[['return_A', 'return_B']].corr()# 并行计算correlations = ddf.map_partitions(chunk_correlation, meta=pd.DataFrame).compute()return correlations# 使用示例
corr_results = process_financial_data('large_stock_data.csv')6.2 风险价值(VaR)计算
def monte_carlo_var(returns, n_simulations=1000000, confidence=0.95):"""蒙特卡洛法计算VaR (大型数据集)"""# 使用GPU加速import cupy as cp# 传输数据到GPUreturns_gpu = cp.asarray(returns)# 参数估计mu = cp.mean(returns_gpu)sigma = cp.std(returns_gpu)# 生成随机路径random_returns = cp.random.normal(mu, sigma, n_simulations)# 排序并计算VaRsorted_returns = cp.sort(random_returns)index = int((1 - confidence) * n_simulations)var = sorted_returns[index]return float(var)# 使用
large_returns = np.random.normal(0, 0.01, 10000000) # 1000万数据点
var = monte_carlo_var(large_returns)
print(f"95% VaR: {var:.4f}")七、科学计算应用
7.1 大型矩阵分解
def randomized_svd(A, k=100, p=10):"""随机SVD分解 (大型矩阵)"""# 步骤1: 随机投影m, n = A.shapeOmega = np.random.randn(n, k + p)Y = A @ Omega# 步骤2: 正交化Q, _ = np.linalg.qr(Y)# 步骤3: 小矩阵分解B = Q.T @ AU_tilde, S, Vt = np.linalg.svd(B, full_matrices=False)U = Q @ U_tilde# 截取前k个奇异值return U[:, :k], S[:k], Vt[:k, :]# 使用示例
large_matrix = np.random.rand(10000, 10000)
U, S, Vt = randomized_svd(large_matrix, k=100)7.2 三维数据可视化
def visualize_large_volume(data, downscale=4):"""可视化大型三维数据"""import matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3D# 降采样downsampled = data[::downscale, ::downscale, ::downscale]# 创建网格x, y, z = np.mgrid[0:downsampled.shape[0], 0:downsampled.shape[1], 0:downsampled.shape[2]]# 创建3D图fig = plt.figure(figsize=(10, 8))ax = fig.add_subplot(111, projection='3d')# 散点图 (仅显示非零值)mask = downsampled > np.percentile(downsampled, 90)ax.scatter(x[mask], y[mask], z[mask], c=downsampled[mask], cmap='viridis', alpha=0.3)plt.title("大型三维数据可视化")plt.show()# 使用示例
# 假设data是大型三维数组 (例如CT扫描数据)
# visualize_large_volume(ct_scan_data)八、分布式系统实践
8.1 PySpark大型数组处理
from pyspark.sql import SparkSession
import numpy as npdef spark_array_processing():"""使用Spark处理分布式数组"""spark = SparkSession.builder \.appName("LargeArrayProcessing") \.getOrCreate()# 创建大型RDDn_partitions = 100rdd = spark.sparkContext.parallelize(range(n_partitions), n_partitions)# 分布式计算def process_partition(part_id):"""处理每个分区"""# 创建本地数组arr = np.random.rand(1000, 1000)# 计算操作result = np.mean(arr)return resultresults = rdd.map(process_partition).collect()# 聚合结果final_result = np.mean(results)return final_result# 运行
result = spark_array_processing()
print(f"分布式计算结果: {result}")8.2 Ray分布式计算
import ray
import numpy as np@ray.remote
class ArrayProcessor:"""分布式数组处理器"""def __init__(self):passdef process(self, data):"""处理数据块"""return np.mean(data)def ray_distributed_computation():"""Ray分布式计算"""ray.init()# 创建大型数组large_array = np.random.rand(10000, 10000)# 分块chunks = [large_array[i:i+1000] for i in range(0, 10000, 1000)]# 创建处理器processors = [ArrayProcessor.remote() for _ in range(10)]# 分发任务results = []for i, chunk in enumerate(chunks):processor = processors[i % len(processors)]results.append(processor.process.remote(chunk))# 获取结果chunk_means = ray.get(results)final_mean = np.mean(chunk_means)return final_mean# 运行
result = ray_distributed_computation()
print(f"Ray分布式计算结果: {result}")九、最佳实践与性能优化
9.1 技术选型决策树
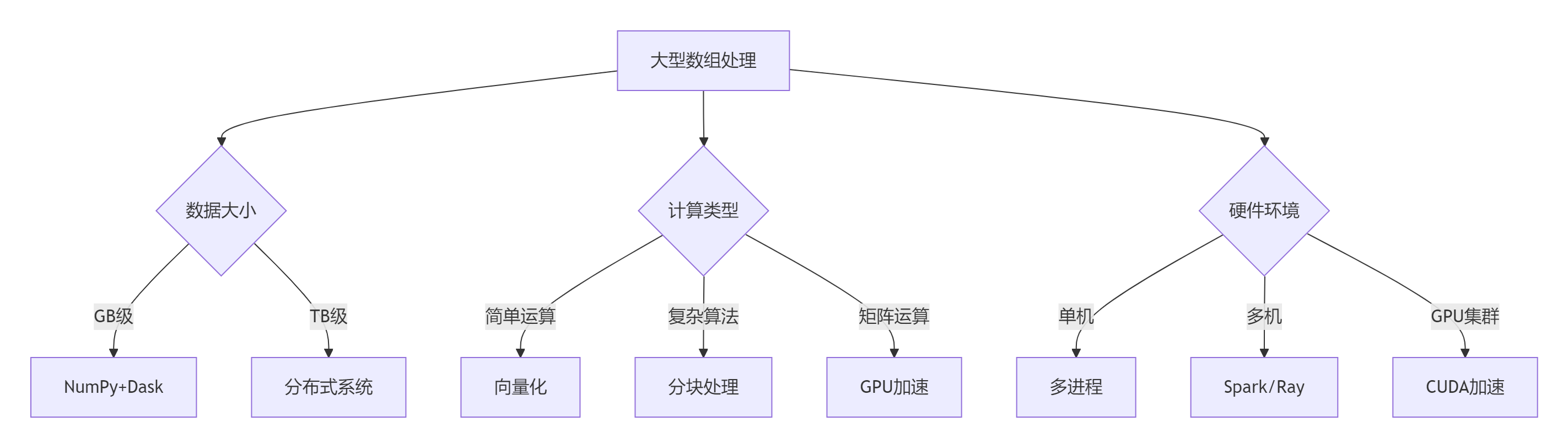
9.2 黄金实践原则
内存管理:
# 及时释放内存 import gc del large_array gc.collect()数据类型优化:
# 使用小数据类型 optimized_array = large_array.astype(np.float32) # 节省50%内存磁盘I/O优化:
# 使用HDF5高效存储 import h5py with h5py.File('data.h5', 'w') as f:dset = f.create_dataset('large_array', data=large_array, compression='gzip')计算资源监控:
# 内存使用监控 import psutil def check_memory():return psutil.virtual_memory().percent# 在计算前检查 if check_memory() > 80:raise MemoryError("内存不足")算法优化:
# 使用高效算法 from scipy.sparse.linalg import svds # 替代np.linalg.svd U, s, Vt = svds(large_sparse_matrix, k=100)渐进式计算:
# 流式处理 def streaming_mean(iterator):total = 0count = 0for chunk in iterator:total += np.sum(chunk)count += chunk.sizereturn total / count
总结:大型数组处理技术全景
10.1 技术选型矩阵
场景 | 推荐方案 | 优势 | 注意事项 |
|---|---|---|---|
GB级内存计算 | NumPy向量化 | 简单高效 | 内存限制 |
TB级数据处理 | Dask/Spark | 分布式处理 | 集群部署 |
GPU加速计算 | CuPy/Numba | 极致性能 | 硬件依赖 |
流式处理 | 分块迭代 | 低内存占用 | 状态管理 |
稀疏数据 | SciPy稀疏矩阵 | 内存高效 | 算法限制 |
科学计算 | 专用库 | 领域优化 | 学习曲线 |
10.2 核心原则总结
理解数据特性:
评估数据规模
分析稀疏性
确定访问模式
选择合适工具:
小数据:NumPy
大数据:Dask/Spark
GPU加速:CuPy
稀疏数据:SciPy
内存优化优先:
使用内存映射
分块处理
数据压缩
稀疏表示
计算资源利用:
多核并行
GPU加速
分布式计算
I/O性能优化:
高效文件格式(HDF5)
数据压缩
流式读取
算法创新:
随机算法
增量计算
近似方法
大型数组处理是现代数据科学的核心挑战。通过掌握从基础向量化到分布式计算的完整技术栈,结合内存优化和算法创新,您将能够高效处理各种规模的数据集。遵循本文的最佳实践,将使您的大数据处理能力达到工业级水准。
最新技术动态请关注作者:Python×CATIA工业智造
版权声明:转载请保留原文链接及作者信息