CVPR自适应卷积的高效实现:小核大感受野提升复杂场景下图像重建精度
关注gongzhonghao【CVPR顶会精选】
还在用“古板”的固定卷积?现在都流行自适应卷积了!它就像给模型装上了“自动调焦镜头”,遇到猫就细致勾毛发,遇到车就大范围看车身。CVPR上越来越多论文在玩这一招,不仅精度飙升,还能应对各种奇葩场景。医学图像?搞定。自动驾驶?没问题。视频理解?安排!一句话——自适应卷积就是卷积界的“变形金刚”,哪里需要就变哪里。今天小图给大家精选3篇CVPR有关自动驾驶方向的论文,供大家参考和借鉴。
论文一:A Universal Scale-Adaptive Deformable Transformer for Image Restoration across Diverse Artifacts
方法:
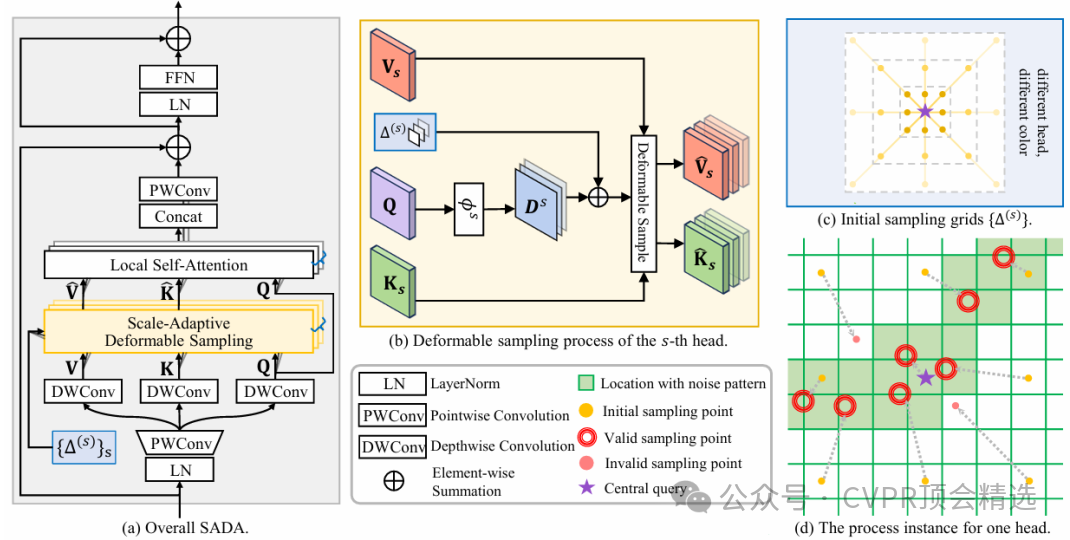
模型以分层Transformer为骨干,首先提取多尺度特征并估计一张隐式尺度图,将其作为条件信号驱动后续模块的采样位置与感受野自适应变化。随后,尺度增强可变形卷积利用尺度图调制偏移场与采样核,在受污染区域进行更密集与跨尺度的特征聚合,同时抑制干净区域的过度修复以避免伪影放大。最后,尺度自适应注意力在窗口化局部注意与稀疏全局注意间进行软融合,按区域难度自适应分配上下文长度与计算资源,实现纹理细节、长程结构和重复性伪影的协同恢复。

创新点:
在可变形卷积中显式引入尺度调制,依据对象/伪影大小自适应调整采样偏移与权重,精准覆盖不同尺度的伪影区域。
通过可学习的尺度门控在局部与全局注意范围间动态切换,既保细节纹理又修复长程结构与周期性伪影。
提出通用复原框架:单一模型统一处理多类结构化伪影,减少任务特定设计与调参负担,同时在参数与计算开销可控的前提下保持高性能。
论文链接:
https://cvpr.thecvf.com/virtual/2025/poster/33696
图灵学术论文辅导
论文二:Semantic Library Adaptation: LoRA Retrieval and Fusion for Open-Vocabulary Semantic Segmentation
方法:
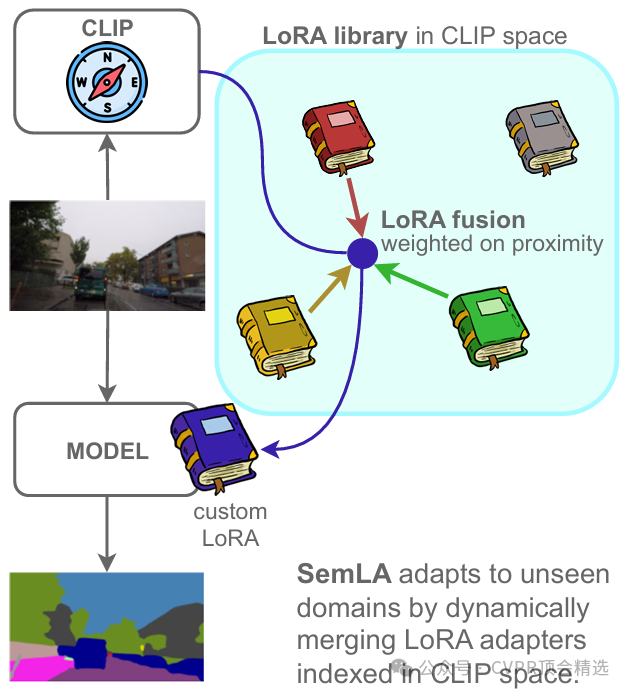
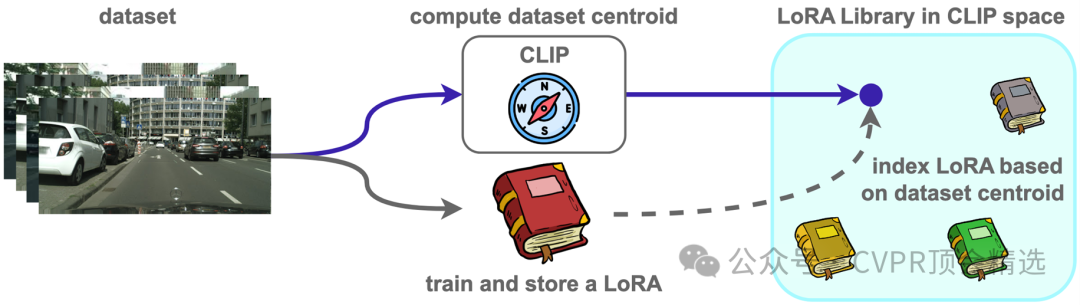
作者首先离线构建覆盖常见概念与域偏移的语义LoRA库,并为每个LoRA建立轻量语义索引与元数据以支持快速检索和组合。随后,系统依据测试图像与目标开放词表的语义相似度检索出一小组候选LoRA,并为不同层级与空间位置估计自适应融合权重,实现对域偏移与类别差异的精准对齐。最后,将加权后的LoRA注入到冻结的分割主干中完成预测,从而在多域场景下稳健提升开放词表分割性能与泛化能力。
创新点:
将跨数据集类别训练得到的LoRA标准化存储为可检索的“语义模块”,用检索替代再训练,显著降低适应成本。
基于图像-文本共同语义空间的相似度,动态挑选与当前图像和开放词表最相关的少量LoRA,抑制无关适配器引入的噪声。
设计输入相关的软融合权重,在层/通道或空间维度上整合多LoRA,使适配既能全局对齐域偏移,又能局部细化边界,同时保持基座模型冻结稳定。
论文链接:
https://arxiv.org/abs/2503.21780
图灵学术论文辅导
论文三:ShiftwiseConv: Small Convolutional Kernel with Large Kernel Effect
方法:
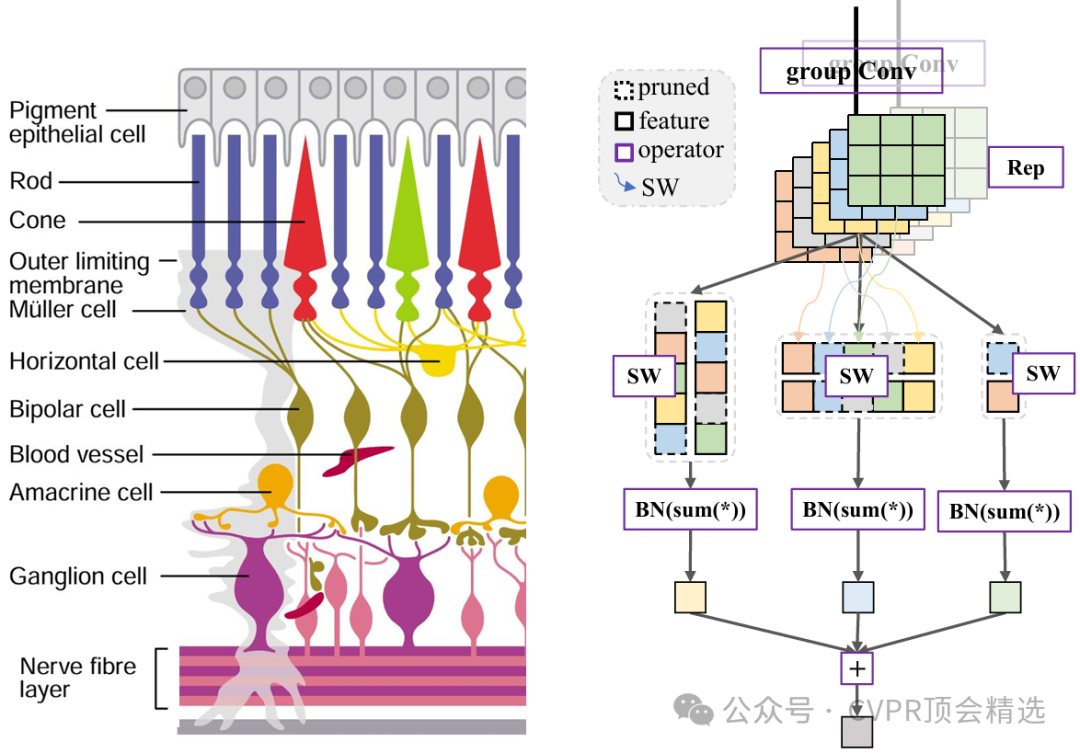
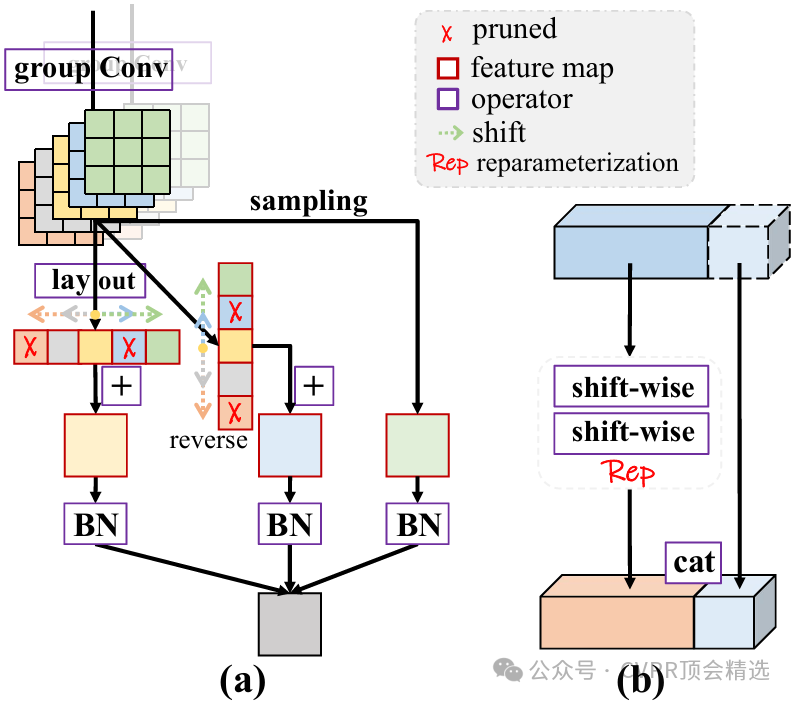
文章整体框架先对特征通道进行分组,每组特征以不同方向和步长进行空间移位操作,等价于在特征图上低成本扩展了信息的覆盖范围;移位后的特征通过轻量化的点卷积融合,增强通道间和空间上的表达与交互,避免信息丢失或冗余;整个Shiftwise卷积模块可直接集成进各类视觉主干网络,无需复杂调参或额外训练技巧,即可在分类、检测、分割等任务中获得显著性能提升。
创新点:
Shiftwise卷积通过通道分组的空间移位操作,极大扩展了小卷积核的有效感受野,实现大核效果但几乎不增加参数。
多方向、多尺度的移位策略让模型能灵活捕捉各种空间结构和细节,显著提升特征表达能力。
该方法天然即插即用,可快速替换传统卷积模块,兼具高精度、低计算和稳定训练优势,适用广泛视觉场景。
论文链接:
https://arxiv.org/abs/2401.12736
本文选自gongzhonghao【CVPR顶会精选】