利用AI进行ArcGISPro进行数据库的相关处理?
相关解释:无论是对ArcGIS还是ArcGISPro进行地理相关操作,都是会用到Python支持的库arcpy,ArcGIS和ArcGISPro都是自带arcpy,如果想要将此库安装到pycharm中,则需要将pycharm编译器设置为ArcGIS或ArcGISPro自带的Python编译器。ArcGIS的Python一般为Python2,而ArcGISPro的Python为Python3,语法有些差异。假如自己想将arcpy安装到自己想要的Python环境中,不一定会成功(自己试过),如果谁有更好的方法,欢迎分享。
问题描述:
在一个gdb数据库中,有许多的点、线、面矢量图层和对应同名的表,需要将表中的个别字段中的数值,更新复制到同名的点、线、面矢量图层属性表对应的字段中。除后面两个字符其他名称都一致。左为数据库、中间为表的属性表、右为同名矢量图层属性表,将中的属性表对应字段更新复制到右对应属性表字段。
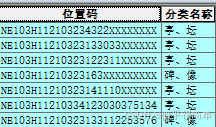
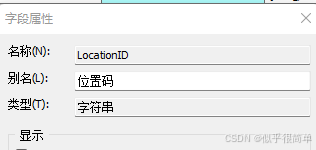
注意事项:在ArcGIS和ArcGISPro中,“位置码” 叫做字段的别名,不是字段可用代码操作的名称,需要用字段真正的名称才能进行代码操作。
想要实现上述操作,常规的就是在ArcGIS或者ArcGISPro进行属性表的链接,数量少的话还行,但是面临数量多的情况下会很烦人的。还有些对软件比较熟的话,会进行模型的搭建,和工具箱和Python工具箱的创建。我只介绍如何在"AI+pycharm"进行处理,不介绍工具箱,如果感兴趣的话,请在评论区留言,我会给出具体方法。
我们要想快速解决上述问题或者类似问题,就可以随便找个AI,GPT、豆包、元宝等等,将我们的问题描述清楚,一定要将逻辑关系描述清楚。
示例:我是一个ArcGIS开发者,我有个ArcGIS的gdb数据库,里面有多个表数据、点、线、面的矢量图层,表的名称与点、线、面的矢量图层的名称除最后两个字符一致,例如A_BLD_FFC是表名、A_BLD_FFC_A是面名称、A_BLD_FFC_P是点名称。请遍历整个gdb数据库,匹配与表名除最后两个字符外相同名称的点、线、面图层,将表名中的"LocationID"、"ClassName"字段里面的数值,复制更新到同名的点、线、面矢量图层对应的"LocationID"、"ClassName"字段里面的数值,“位置码”为字段“LocationID”的别名,“分类名称”为字段“ClassName”的别名,用Python3语法,给出能在pycharm中运行的代码和ArcGIS工具箱代码。
此时你只需要将数据库的路径改成自己的gdb路径,路径尽量不要出现中文字符,其实也可以出现中文字符,只是有些人的pycharm设置的编码有问题
import arcpy
import osdef sync_table_to_features(gdb_path):"""将gdb数据库中表的"LocationID"和"ClassName"字段值同步到对应矢量图层的相同字段- LocationID:别名"位置码"- ClassName:别名"分类名称"参数:gdb_path: gdb数据库的路径"""# 设置工作空间arcpy.env.workspace = gdb_patharcpy.env.overwriteOutput = Truetry:# 获取所有的表tables = arcpy.ListTables()if not tables:print("没有找到任何表")return# 遍历每个表for table in tables:print(f"正在处理表: {table}")# 获取表字段列表table_fields = [f.name for f in arcpy.ListFields(table)]# 检查表是否有必要的字段required_fields = ["LocationID", "ClassName"]missing_fields = [f for f in required_fields if f not in table_fields]if missing_fields:print(f"警告: 表 {table} 中缺少以下字段,跳过该表: {', '.join(missing_fields)}")continue# 查找对应的点、线、面图层(名称格式:表名_A(面)、表名_P(点)等)related_feature_classes = []# 获取所有要素类feature_classes = []datasets = arcpy.ListDatasets(feature_type='feature')datasets = [''] + datasets if datasets is not None else ['']for ds in datasets:for fc in arcpy.ListFeatureClasses(feature_dataset=ds):feature_classes.append(os.path.join(ds, fc))# 匹配相关的要素类for fc in feature_classes:fc_name = os.path.basename(fc)# 检查要素类名称是否以表名开头,且长度比表名多2个字符if len(fc_name) == len(table) + 2 and fc_name.startswith(table):related_feature_classes.append(fc)if not related_feature_classes:print(f"没有找到与表 {table} 相关的要素类")continue# 处理每个相关的要素类for fc in related_feature_classes:print(f" 正在同步要素类: {fc}")# 检查要素类是否有必要的字段fc_fields = [f.name for f in arcpy.ListFields(fc)]fc_missing_fields = [f for f in required_fields if f not in fc_fields]if fc_missing_fields:print(f" 警告: 要素类 {fc} 中缺少以下字段,跳过该要素类: {', '.join(fc_missing_fields)}")continuetry:# 读取表中的字段值,假设通过OID关联with arcpy.da.SearchCursor(table, ["OID@", "LocationID", "ClassName"]) as src_cursor:# 创建字典存储需要同步的值,键为OIDdata_dict = {row[0]: {"LocationID": row[1],"ClassName": row[2]} for row in src_cursor}# 更新要素类中的字段值updated_count = 0with arcpy.da.UpdateCursor(fc, ["OID@", "LocationID", "ClassName"]) as upd_cursor:for row in upd_cursor:oid = row[0]if oid in data_dict:# 更新位置码row[1] = data_dict[oid]["LocationID"]# 更新分类名称row[2] = data_dict[oid]["ClassName"]upd_cursor.updateRow(row)updated_count += 1print(f" 成功更新了 {updated_count} 条记录,同步了LocationID和ClassName字段")except Exception as e:print(f" 更新要素类 {fc} 时出错: {str(e)}")except Exception as e:print(f"处理过程中出错: {str(e)}")if __name__ == "__main__":# 请替换为您的gdb数据库路径gdb_path = r"C:\path\to\your\database.gdb"sync_table_to_features(gdb_path)print("处理完成")
假如你有很多个gdb,可以将gdb都放到一个文件夹中进行批量处理
import arcpy
import os
import globdef sync_table_to_features(gdb_path):"""Sync 'LocationID' and 'ClassName' fields from tables to corresponding feature classes in a GDB"""arcpy.env.workspace = gdb_patharcpy.env.overwriteOutput = Truetry:tables = arcpy.ListTables()if not tables:print(f"No tables found in {gdb_path}")returnfor table in tables:print(f"Processing table: {table}")table_fields = [f.name for f in arcpy.ListFields(table)]required_fields = ["LocationID", "ClassName"]missing_fields = [f for f in required_fields if f not in table_fields]if missing_fields:print(f"Warning: Table {table} missing required fields: {', '.join(missing_fields)}. Skipping.")continuerelated_feature_classes = []feature_classes = []datasets = arcpy.ListDatasets(feature_type='feature')datasets = [''] + datasets if datasets is not None else ['']for ds in datasets:for fc in arcpy.ListFeatureClasses(feature_dataset=ds):feature_classes.append(os.path.join(ds, fc))for fc in feature_classes:fc_name = os.path.basename(fc)if len(fc_name) == len(table) + 2 and fc_name.startswith(table):related_feature_classes.append(fc)if not related_feature_classes:print(f"No related feature classes found for table {table}")continuefor fc in related_feature_classes:print(f" Syncing feature class: {fc}")fc_fields = [f.name for f in arcpy.ListFields(fc)]fc_missing_fields = [f for f in required_fields if f not in fc_fields]if fc_missing_fields:print(f" Warning: Feature class {fc} missing fields: {', '.join(fc_missing_fields)}. Skipping.")continuetry:with arcpy.da.SearchCursor(table, ["OID@", "LocationID", "ClassName"]) as src_cursor:data_dict = {row[0]: {"LocationID": row[1],"ClassName": row[2]} for row in src_cursor}updated_count = 0with arcpy.da.UpdateCursor(fc, ["OID@", "LocationID", "ClassName"]) as upd_cursor:for row in upd_cursor:oid = row[0]if oid in data_dict:row[1] = data_dict[oid]["LocationID"]row[2] = data_dict[oid]["ClassName"]upd_cursor.updateRow(row)updated_count += 1print(f" Successfully updated {updated_count} records")except Exception as e:print(f" Error updating feature class {fc}: {str(e)}")except Exception as e:print(f"Error processing GDB {gdb_path}: {str(e)}")def batch_process_gdbs(parent_folder):"""Process all GDBs in the specified folder"""# Find all GDBs in the parent foldergdb_paths = glob.glob(os.path.join(parent_folder, "*.gdb"))if not gdb_paths:print(f"No GDB files found in {parent_folder}")returnprint(f"Found {len(gdb_paths)} GDB files. Starting processing...")for gdb_path in gdb_paths:print(f"\nProcessing GDB: {gdb_path}")sync_table_to_features(gdb_path)print("\nBatch processing completed")if __name__ == "__main__":# Replace with your parent folder path containing GDBsparent_folder = r"C:\path\to\your\gdb_folder"batch_process_gdbs(parent_folder)
其实还可以利用PySide6进行窗体程序的开发生成,但是进行打包的时候,别人如果想用你的程序ArcGIS或ArcGISPro版本必须一致,这就很鸡肋。
注:时代发展很快,要学会用AI进行处理工作上的任务,现在不会用AI的人注定会被淘汰,但也不能绝对的依赖AI(这是我对自己说的话)