Qwen集成clickhouse实现RAG
一、RAG概要
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合了信息检索技术与语言生成模型的人工智能技术。旨在通过检索相关文档来增强大模型的生成能力,从而提高预测的质量和准确性。RAG模型在生成文本或回答问题时,会先从一个庞大的文档集合中检索相关信息,然后利用这些信息来指导文本的生成。
1、RAG的作用
通用大模型存在知识局限性、幻觉问题、数据安全等问题,解决这些问题目前主流的有两种方式,大模型微调和RAG,大模型微调实时性较差,训练成本较高,准确率高,而RAG恰恰相反,虽然准确率不如微调,但是对于小企业来说,经济实惠。
(1) 知识的局限性
模型自身的知识完全源于它的训练数据,而现有的主流大模型的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的。
(2)幻觉问题
所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它经常会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。
(3)数据安全性
对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
2、RAG工作原理
RAG工作总体来说,分索引和检索两个阶段
(1)索引阶段
索引阶段主要是准备数据:数据提取——>文本分割——>向量化(embedding)——>数据入库
Indexing
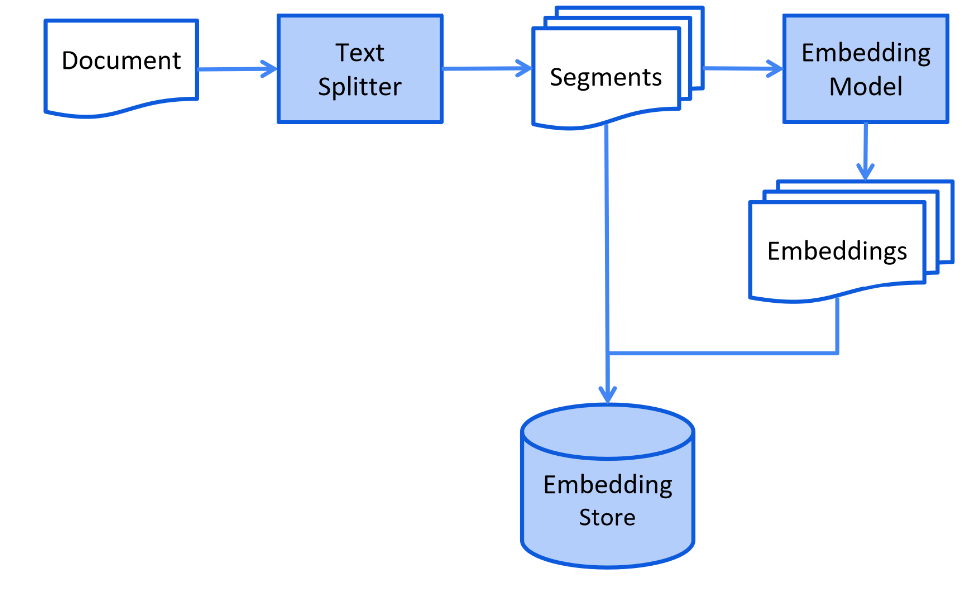
(2)检索阶段
检索阶段主要是应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM返回
Retrieval
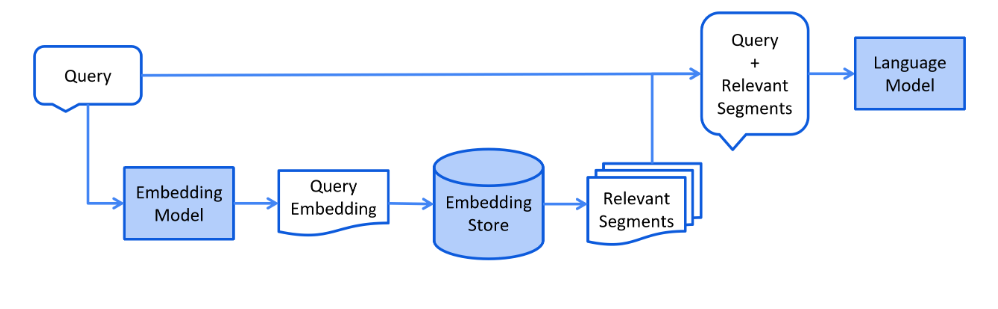
二、实现案例
1、集成RAG相关框架
jar包依赖
implementation group: 'dev.langchain4j', name: 'langchain4j-spring-boot-starter', version: '1.0.0-beta4'// **** langchain4j整合千问dashscopeimplementation group: 'dev.langchain4j', name: 'langchain4j-community-dashscope-spring-boot-starter', version: '1.0.0-beta4'/// **** langchain4j整合RAGimplementation group: 'dev.langchain4j', name: 'langchain4j-easy-rag', version: '1.0.0-beta4'/// **** langchain4j整合clickhouseimplementation group: 'dev.langchain4j', name: 'langchain4j-community-clickhouse', version: '1.0.0-beta4'yaml配置
langchain4j:## https://docs.langchain4j.dev/integrations/language-models/dashscopecommunity:dashscope:chat-model:api-key: 百炼平台申请model-name: qwen-plusembedding-model:api-key: 百炼平台申请model-name: text-embedding-v32、向量数据库存储配置
@Configuration
public class ChatRagConf {@Beanpublic ClickHouseEmbeddingStore clickHouseEmbeddingStore(QwenEmbeddingModel embeddingModel){Map<String, ClickHouseDataType> metadataTypeMap = new HashMap<>();ClickHouseSettings settings = ClickHouseSettings.builder().url("http://192.168.109.200:8123").table("rag_table").username("rag").password("123456").dimension(embeddingModel.dimension()).metadataTypeMap(metadataTypeMap).build();return ClickHouseEmbeddingStore.builder().settings(settings).build();}@Beanpublic ContentRetriever contentRetriever(QwenEmbeddingModel embeddingModel){return EmbeddingStoreContentRetriever.builder().embeddingStore(clickHouseEmbeddingStore(embeddingModel)).embeddingModel(embeddingModel).maxResults(1) // 相似度匹配.minScore(0.5).build();}}@AiService
public interface DashScopeAssistant {@SystemMessage("Answer using slang")String chat(@MemoryId String chatId, @UserMessage String userMessage);}
private final ClickHouseEmbeddingStore clickHouseEmbeddingStore;private final QwenEmbeddingModel embeddingModel;private final DashScopeAssistant assistant;private final Logger LOGGER = LoggerFactory.getLogger(DashScopeRagService.class);@Autowiredpublic DashScopeRagService(QwenChatModel qwenChatModel,QwenEmbeddingModel embeddingModel, ClickHouseEmbeddingStore clickHouseEmbeddingStore,ContentRetriever contentRetriever) {this.clickHouseEmbeddingStore = clickHouseEmbeddingStore;this.embeddingModel = embeddingModel;assistant = AiServices.builder(DashScopeAssistant.class).chatModel(qwenChatModel).contentRetriever(contentRetriever).chatMemoryProvider(memoryId ->MessageWindowChatMemory.builder().id(memoryId).maxMessages(10).chatMemoryStore(new InMemoryChatMemoryStore()).build()).build();}3、私域数据向量化
/*** 将大模型外部的知识库文本生成向量存入向量数据库*/public void textSegmentEmbeddingStore(){///TextSegment textSegment1 = TextSegment.from("金庸、古龙、梁羽生、温瑞安被称为武侠四大家");TextSegment textSegment2 = TextSegment.from("古龙小说三大元素:江湖、美酒、美人。");TextSegment textSegment3 = TextSegment.from("金庸侠之大者为国为民");clickHouseEmbeddingStore.add(embeddingModel.embed(textSegment1).content(),textSegment1);clickHouseEmbeddingStore.add(embeddingModel.embed(textSegment2).content(),textSegment2);clickHouseEmbeddingStore.add(embeddingModel.embed(textSegment3).content(),textSegment3);}查询clickhouse向量化后的数据
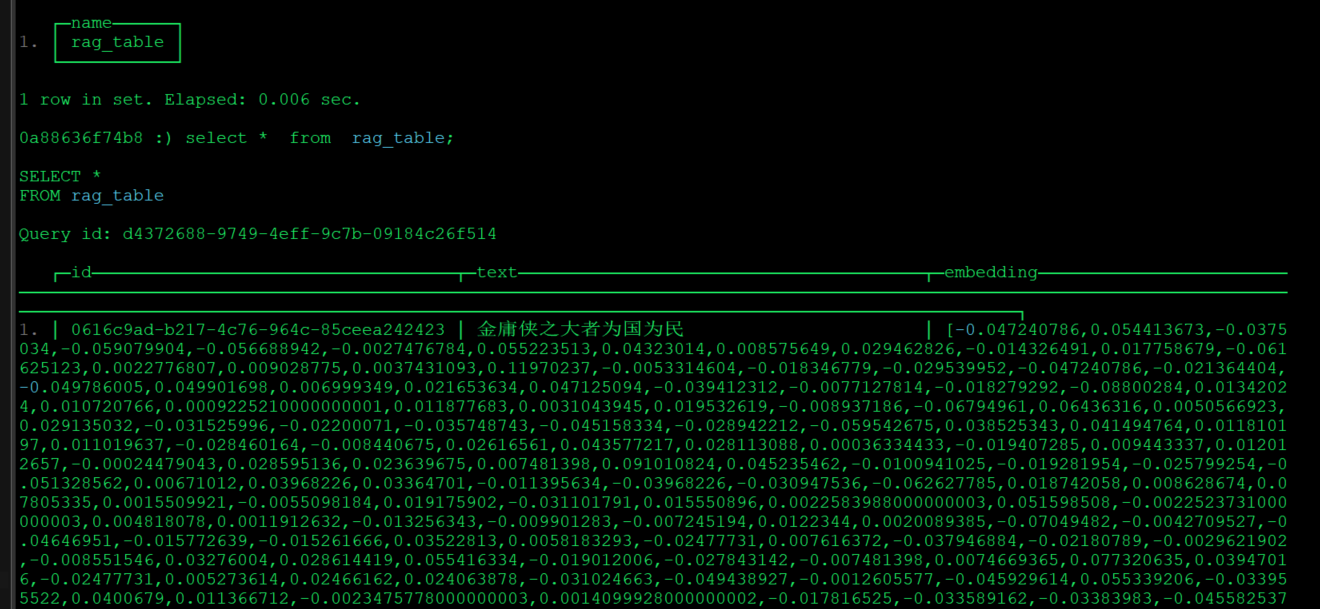
4、向量检索
public void chatRAG(String memoryId,String prompt){LOGGER.info("chatRAG start ======");String answer = assistant.chat(memoryId,prompt);LOGGER.info("chatRAG answer ======{}",answer);}
chatRAG("103","请介绍武侠三大家"); 大模型返回结果