【MySQL】(11) 索引
一、什么是索引
不同的数据结构组织数据的方式不同,导致查询数据的时间复杂度、空间复杂度不同。索引就是 MySQL 的一种用于提高查询效率的数据结构。
类似于字典中的目录,有笔画、偏旁、拼音三种文字查询方式,这就是三种索引。
每更新、删除、增加数据,同时也会变更所有的索引。因此,虽然索引可以提高查询效率,但在数据增删改时,过多的索引会导致效率低下。在应用程序中,查询的频率远远大于增删改的频率,使用索引是必要的。
二、使用哪种数据结构作为索引
1、Hash
虽然 Hash 的查询时间复杂度为 O(1),但它仅支持等值查找(where id = 1),不支持范围查找和排序(两个相邻数据对应的 Hash 值是无序的)。
2、二叉搜索树
N个节点,在树平衡时(AVL),最坏查询时间复杂度为 O(logN),极端情况单边树是 O(N)。支持范围查找(中序遍历)。
但当 N 很大时,树非常高,磁盘 IO 次数过多(每通过父节点访问一次子节点,就会访问一次磁盘,磁盘 IO 是影响数据库效率的主要因素),导致搜索效率低下。且查询不同值的 IO 次数不稳定(处于树的层数不一样)。
3、N叉搜索树
如B树(平衡N叉树),树高相对二叉树降低很多,但是范围查找仍然要遍历树,进行多次磁盘 IO,效率不够高。且非节点节点存储数据,导致存储键和指针的空间减小,及分支减少,树高增加。
4、B+树
这是 MySQL 的索引的数据结构,支持范围查找,查询的时间复杂度为 O(logN),树高较小可控制 IO 次数。
与 B 树的区别:
- 叶子节点可访问兄弟节点,MySQL 组织叶子节点使用的双向循环链表。(范围查找不用跨越层级而访问磁盘 IO)
- 相同树高下,查询任意元素的时间复杂度一样,性能稳定。
- 非叶子节点仅存数据的引用,叶子节点存储真实数据,一个非叶子节点能有更多分支。

三、页
1、什么是页
在 MySQL 中,若用 InnoDB 存储引擎,.idb 文件就是存储一个表的数据和索引信息的文件。

数据以页为单位进行存储,也是内存与磁盘交互的最小单元,每次至少读取一页,16KB。页内的地址是连续的,这样设计是因为:
- 时间局部性:当前访问的数据,很有可能再次被访问。
- 空间局部性:很有可能访问当前访问数据的邻近位置的数据。
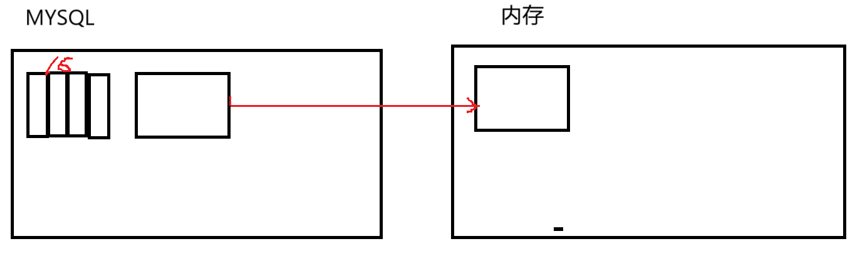
若下次查询的数据在当前页中,就直接从内存读取,减少访问磁盘,提高性能。
2、页的基本结构
MySQL 中有多种页,最常用的是索引页和数据页,结构如下:页头+数据主体+页尾。
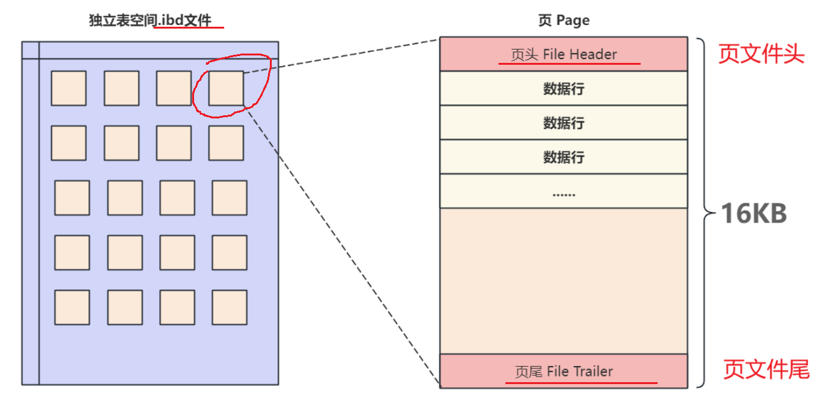
2.1、页头和页尾
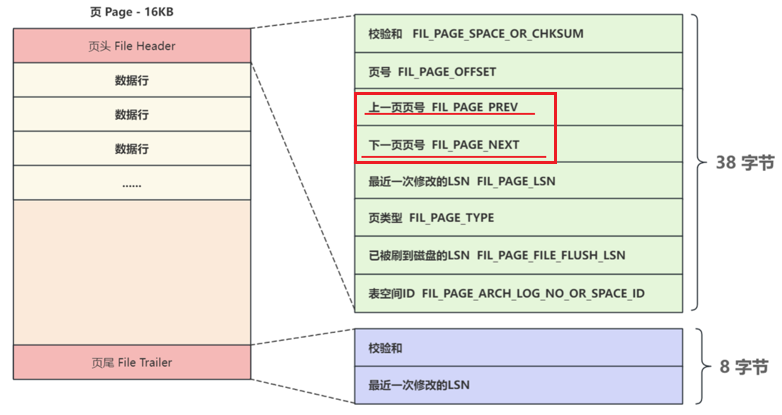
主要关注上一页页号和下一页页号,构成双向链表,即 B+ 树中的非叶子节点存储的数据是页。
2.2、页的主体
最大行、最小行标识数据行从哪开始,到哪结束。next_record 记录下一个数据行的地址偏移量,整个主体构成单向链表:
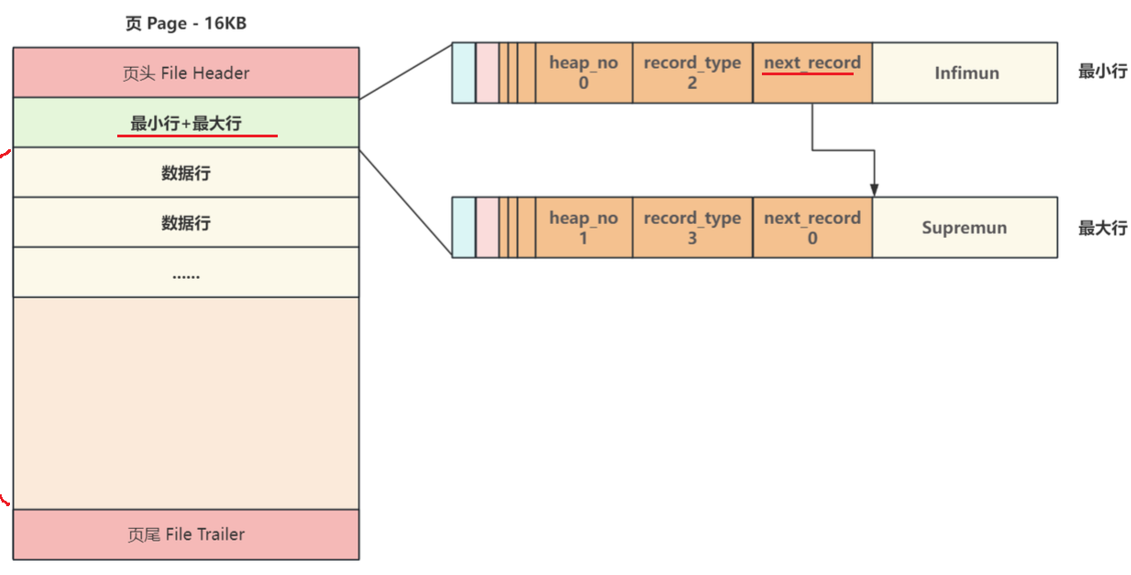
当有多条数据行,按照主键从小到大进行连接:
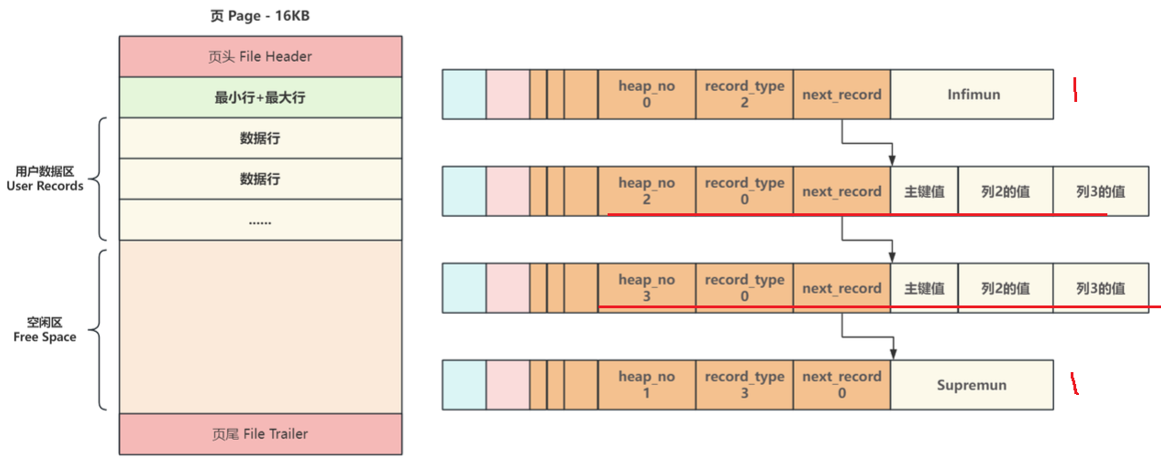
2.3、页目录
一个页有 16 KB,可能会存储上百条数据行,在页内逐行遍历查找效率低下,因此引出页目录。将最小行单独为一组,剩余的每 8 条为一组,页目录中的每个槽存储每组最后一条数据行的主键。
页内查询时,先根据数据行的主键值在页目录里进行二分查找,找到对应槽,因为对应槽存储的每组最后一条数据的主键,我们想从组内第一条开始遍历,就找到对应槽的前一个槽,遍历查找数据:
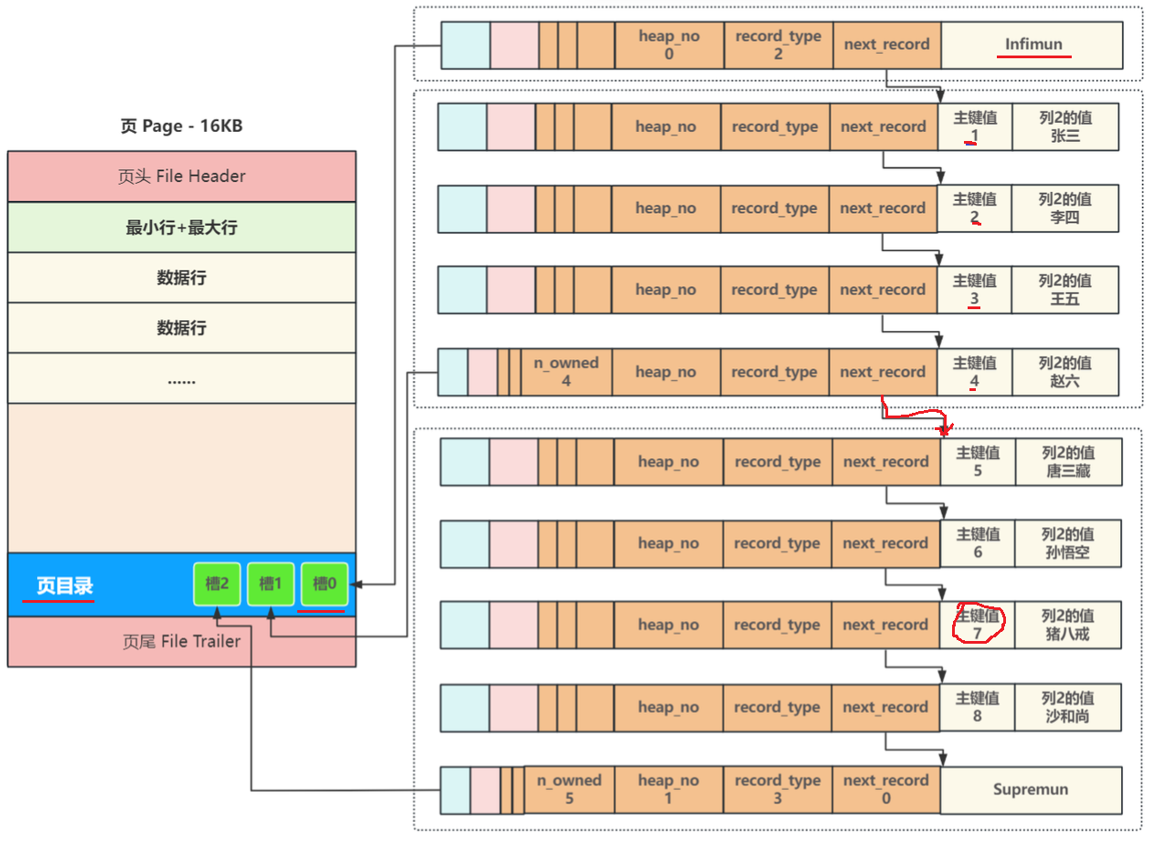
2.4、数据页头
保存当前页数据的相关信息。
四、B+树在 MySQL 索引中的应用
1、B+ 树构建示例
创建主键为 1~ 16 的B+树,m = 3 个分支,一个节点最多存 m-1 = 2 条数据,分裂后左边存 m/2 = 1条数据 ,在叶子节点中插入:
插入 1、2:
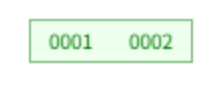
插入 3:分裂,2 提上去,叶子节点中保留。
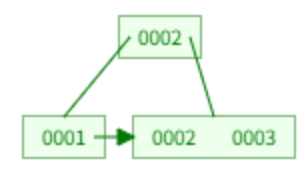
插入 4:分裂,3 提上去。
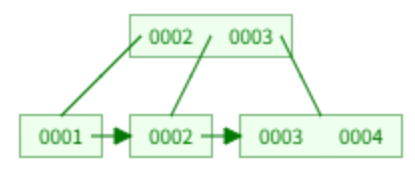
插入 5:分裂,4 提上去,再分裂,3 提上去,3 不保留。
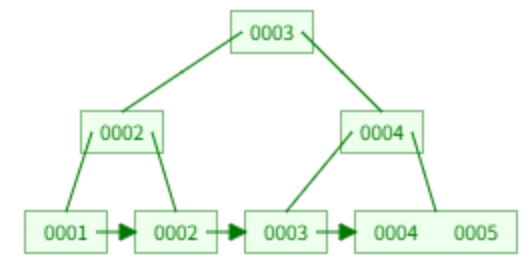
2、在 B+ 树中查询一条记录
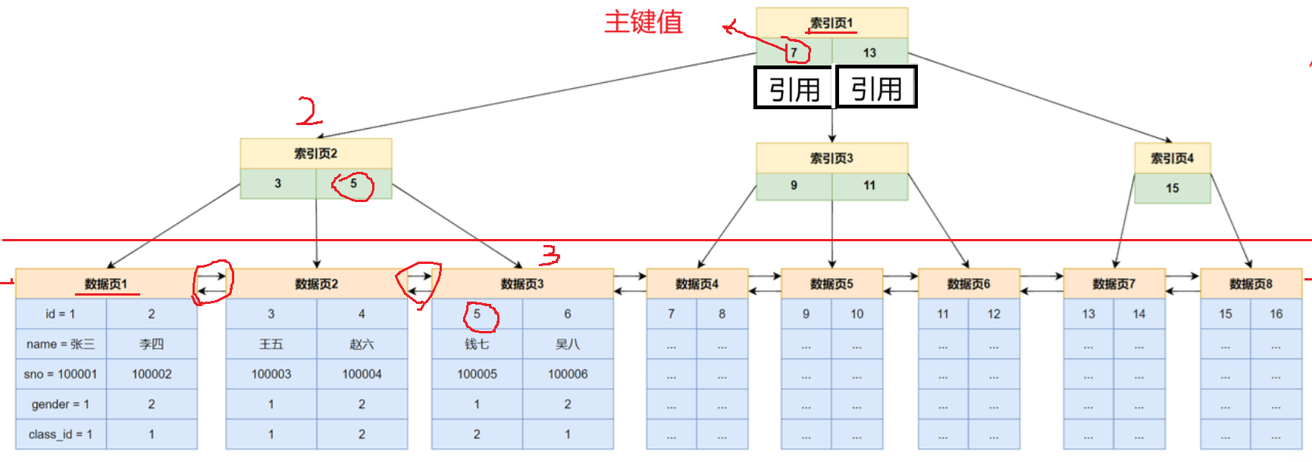
查找主键为 4 的记录:
- 找到 id = 4 所在数据页。
访问根节点的索引页1,4 < 7 》访问左节点的索引页 2,3 < 4 < 5 》 访问中间叶子节点的数据页2。共进行 3 次磁盘 IO。
- 在数据页中查找数据行。
3、计算 3 层高的 B+ 树最多可以存放多少记录
- 索引页大小为 16 KB,假设有 n 个度,即 n 个引用(6字节),n-1 个主键(8字节),16 * 1024 = 6*n + 8*(n-1),n ≈ 1170 个分支。
- 数据页大小为 16 KB,假设一条数据 1KB,那么可以存 16 条数据。
- 3层树高:1170 ^ (3 -1) * 16 = 2190,2400。
2 万多条数据,3 次磁盘 IO 即可实现查询,且性能稳定。
五、索引分类
1、主键索引
给表创建主键,会自动生成主键索引,InnoDB 将它作为聚集索引(数据的物理存储结构与列值(这里是主键)顺序一致)。由于一个表只能有一个物理存储顺序,因此一个表只有一个聚集索引。聚集索引可以直接通过索引值(主键)找到数据行。
建议一表一主键,没有唯一且非空列作为主键,就添加自增列。
一个表可以有多个非聚集索引,后面说的都是非聚集索引。
2、普通索引
索引列可以是复合的,若是复合的,会按照索引列创建顺序排列,先按列1的排序,再按列2的排序。索引树中,索引页存储的是索引列值、子节点引用。数据页存储的是索引列值、主键值。
3、唯一索引
索引列是唯一的,其它跟普通索引一样。
4、全文搜索
索引列是文本类型(char、varchar、text),仅 MyISAM、InnoDB 支持。
5、聚集索引和非聚集索引
聚集索引:
- 一表必有一个,是表的物理存储结构。
- 没有主键,默认用第一个唯一、非空列。
- 没有合适的唯一列,自动生成 ROW_ID 自增。
非聚集索引:
- 又称二级索引,数据页必存储主键列或者指定列。
- 回表查询:拿着在非聚集索引树中查找到的主键,回到聚集索引树中查询完整的数据行内容。
列如下图查询语句:会先用 class_id 和 name 复合索引,在索引树中查找到 class_id、name、主键,再用主键到主键索引树查找 *。
![]()
6、索引覆盖
需要查询的列,刚好是非聚集索引的数据页存储的列,可以直接返回数据,不用回表查询。

六、索引的使用
1、对比是否使用索引对查询效率的影响
当给表创建主键、外键、唯一键时,会自动生成对应的索引。
我们是 mysql 自带的 world 数据库中的 city 表,创建表时有主键、外键约束:
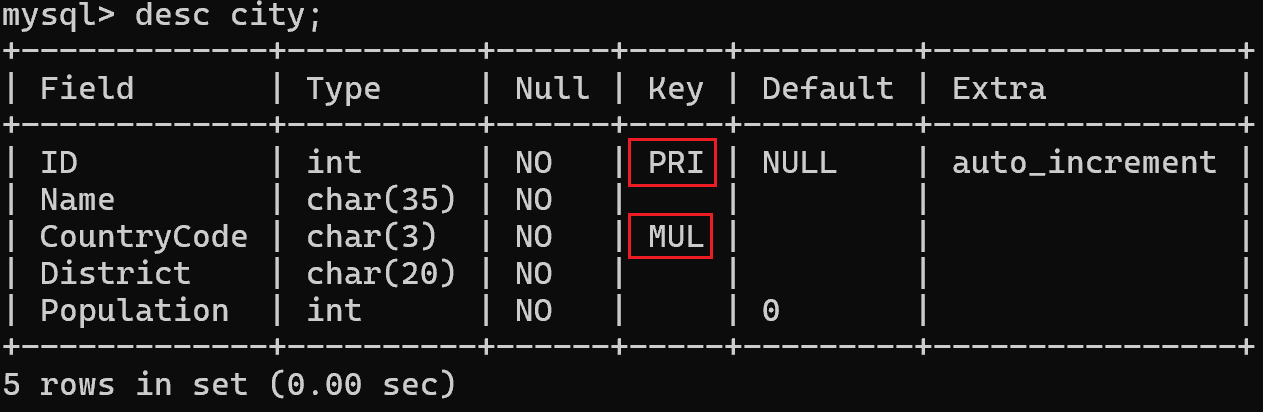
自动创建了对应的索引:
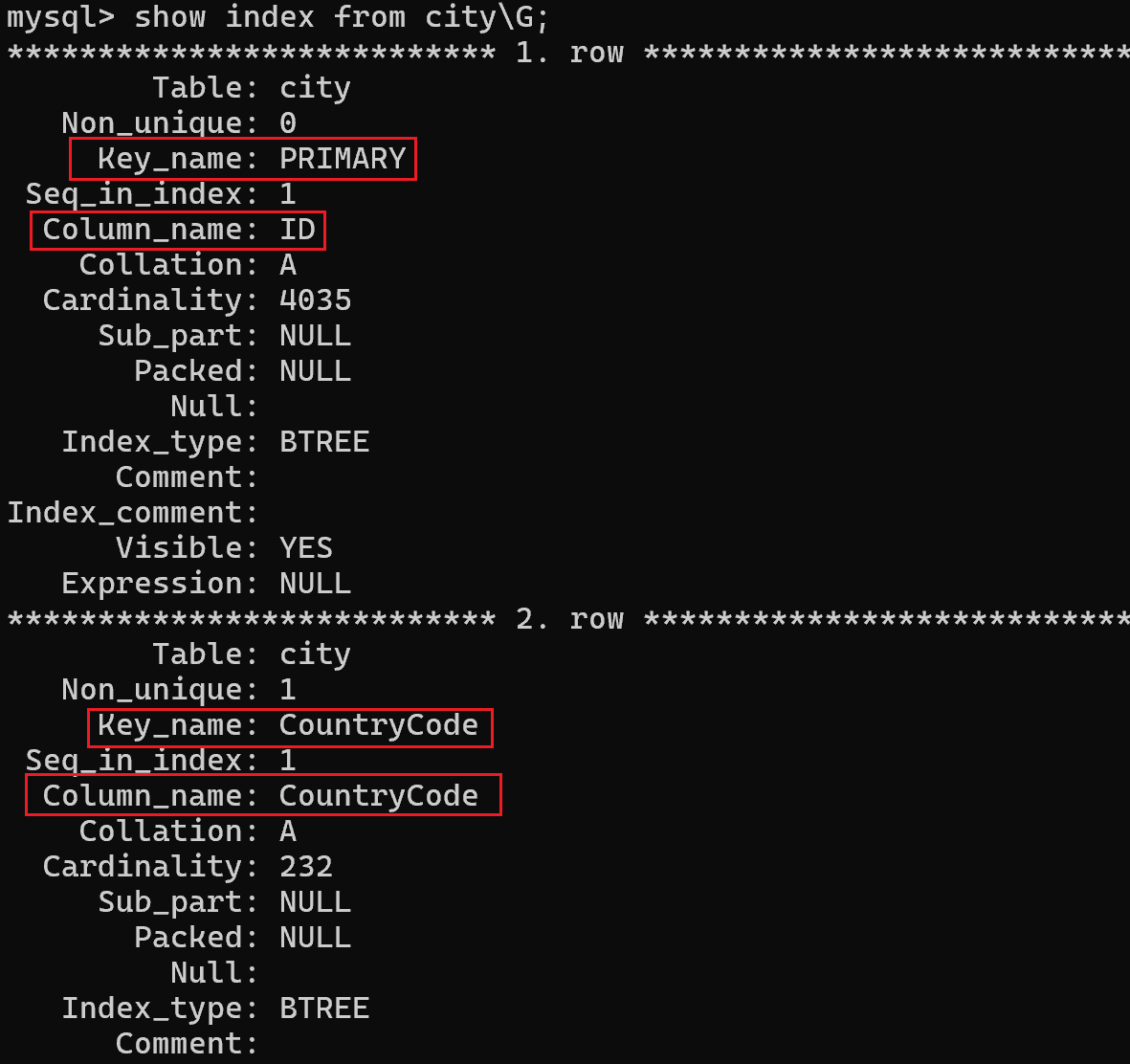
现查询一条信息:
![]()
不使用索引:
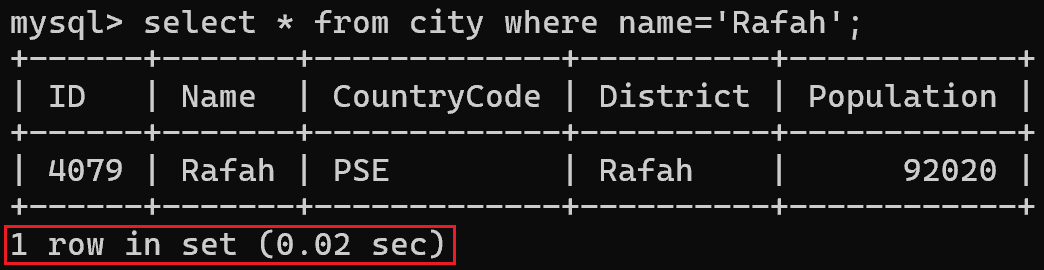
使用索引:
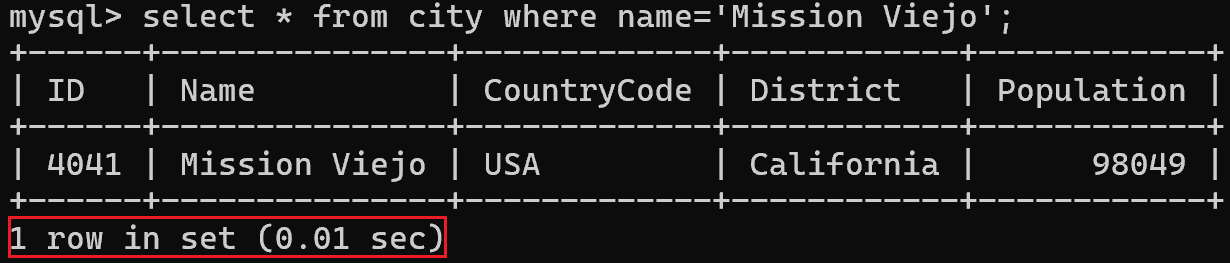
这个表数据量小,效果不明显。当数据量庞大时,这个差距非常大。
2、索引的创建
查询 SQL 语法文档:MySQL :: MySQL 8.0 Reference Manual :: 15 SQL Statements
2.1、主键索引
创建主键,自动生成主键索引,三种方式:
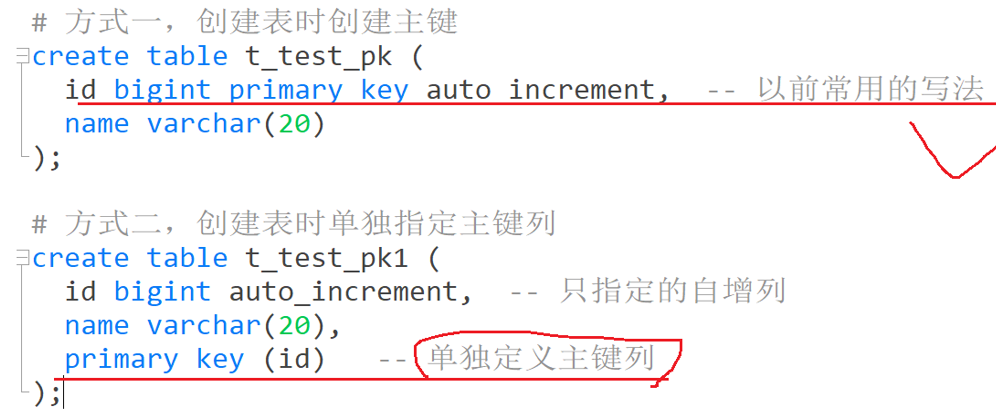
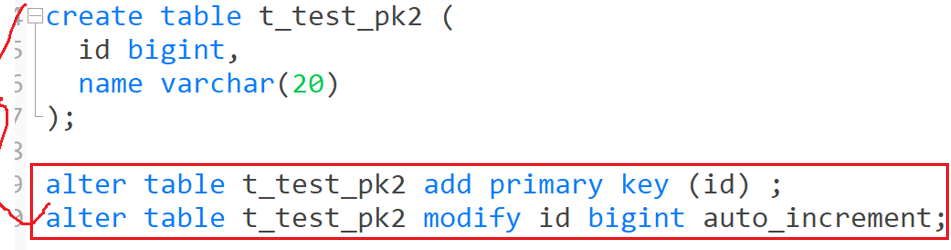
alter 语句查询文档:

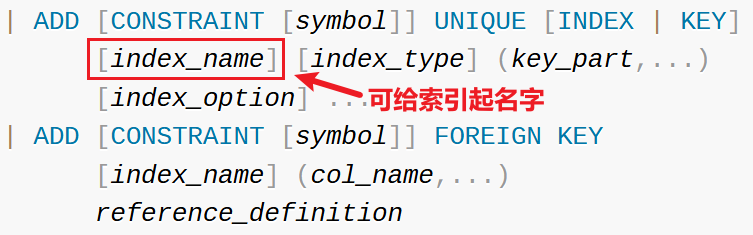
CONSTRAINT 表示指定一个唯一的约束名 symbol,index_name 是索引名。总结:
![]()
![]()
2.2、唯一索引
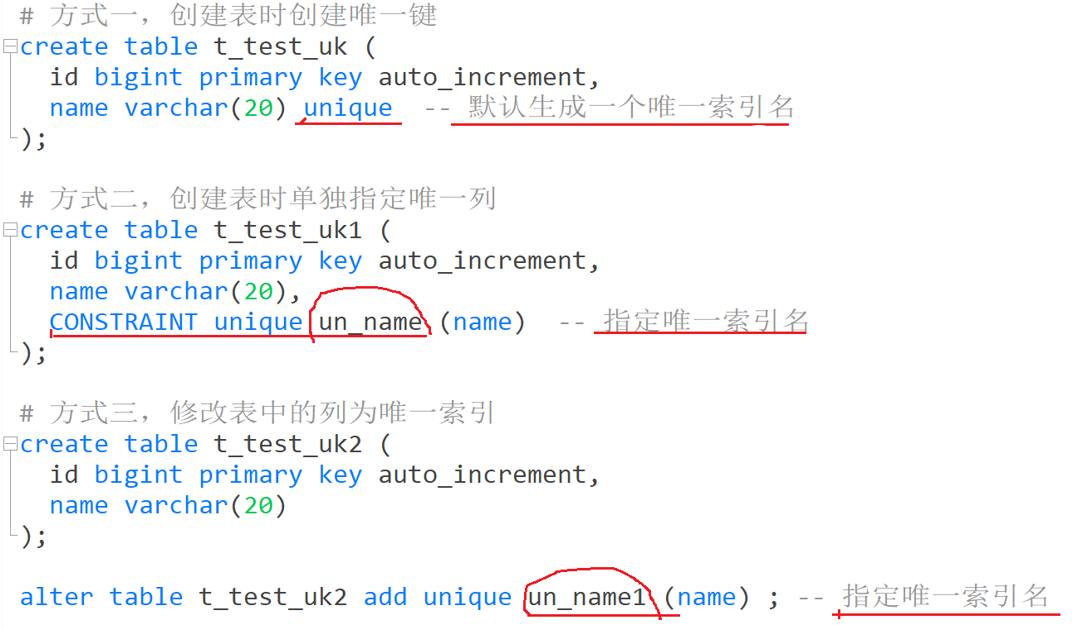
不给索引指定名字,会默认生成一个唯一的索引名。
2.3、外键索引
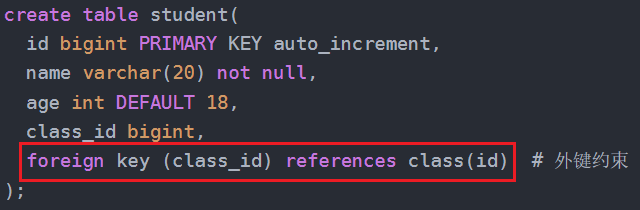
总结:
alter table 表名
add [constraint [约束名]] primary key/unique [index [索引名]] [索引数据结构] (索引列1[,...]);alter table 表名
add [constraint [约束名]] foreign key [index [索引名]] [索引数据结构] (索引列1[,...])
reference 主表名(引用列1[,...]);
2.4、普通索引

创建时机:
- 某列是频繁查询的列,或者出现慢查询,在该列上创建普通索引。
- 数据库迭代过程中达到数据量(约超过十几万)创建(维护索引树需要时间成本,数据量小时,全表扫描可能比索引更快)。
2.5、注意事项
- 高频查询、慢查询列上创建索引。
- 过多或不适合的索引会影响性能:占用存储空间;添加、修改、删除数据也会更新对应的索引。
3、索引的删除
3.1、主键索引
因为一表只有一个主键,所以不用指定索引名。
![]()
如果主键列是自增的,需要先把自增去掉。
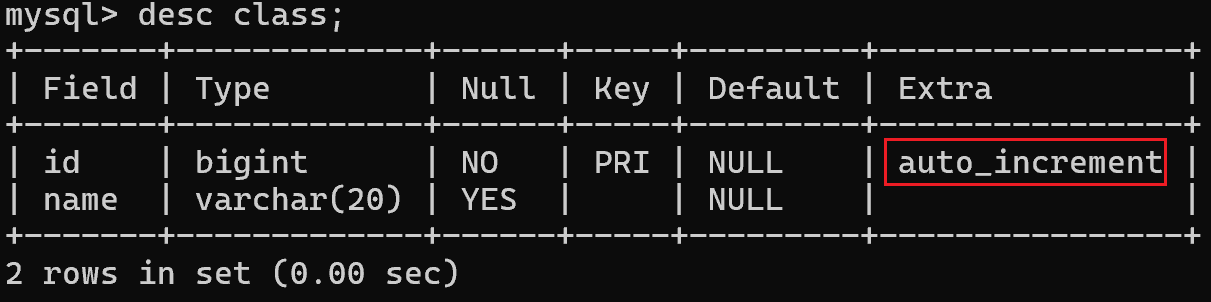
删除失败:

去掉自增:
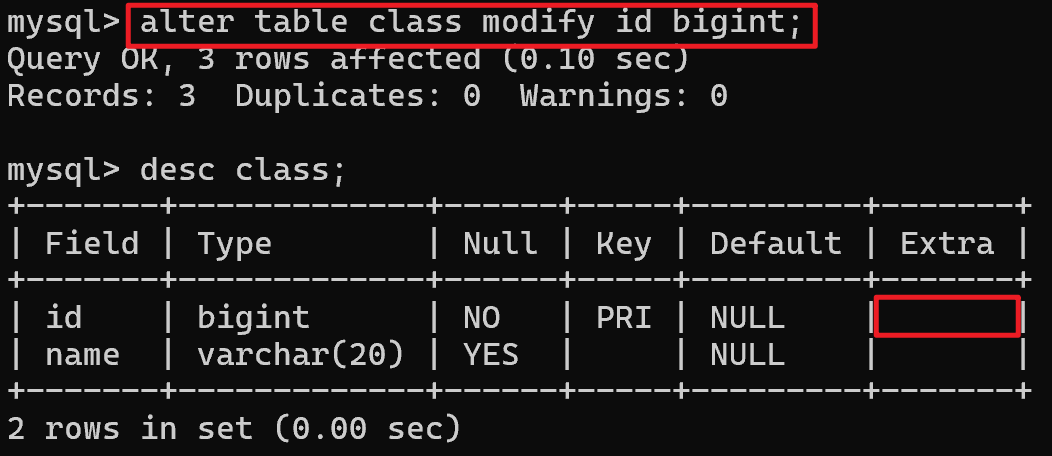
删除主键索引:
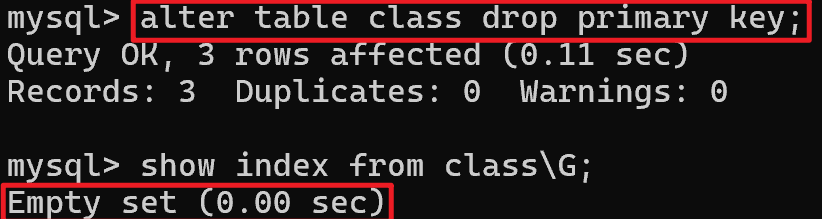
3.2、其它索引
![]()
4、判断查询是否使用了索引
4.1、根据执行时间判断
现有一张数据量达十几万的表:
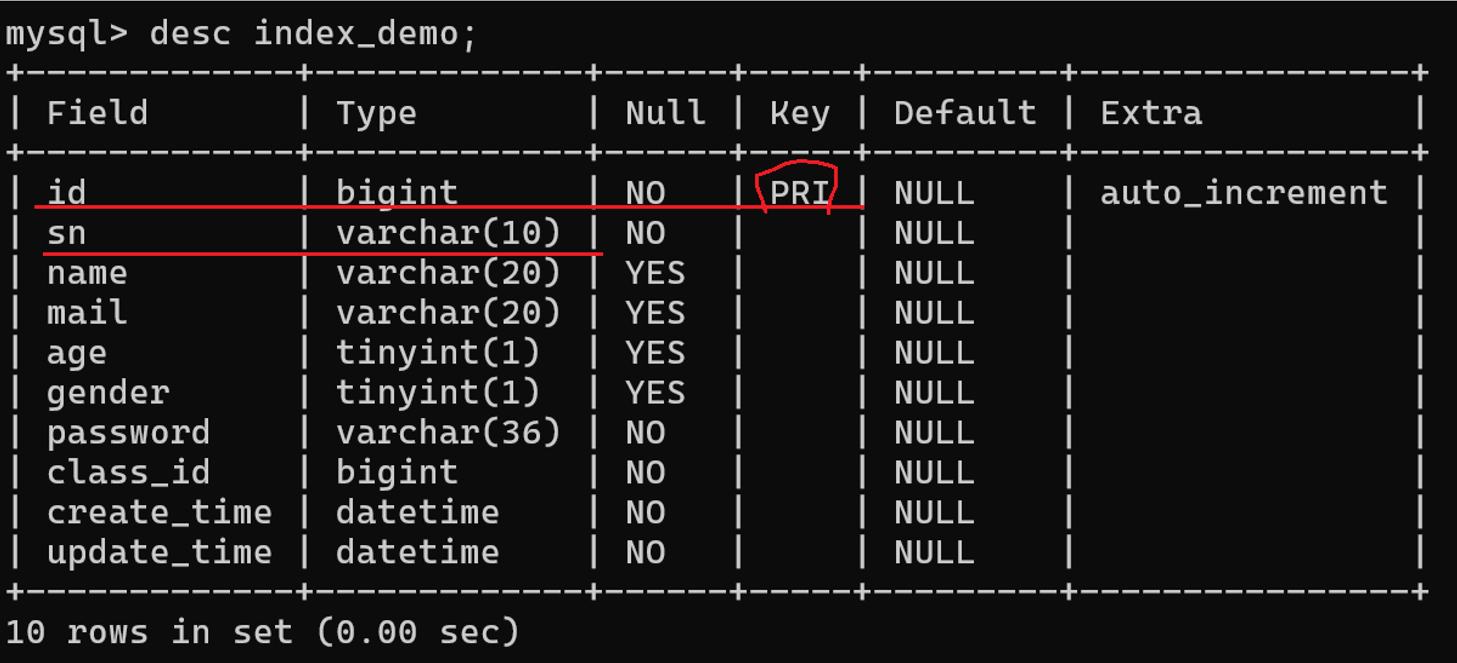
根据索引(主键id)和不根据索引(学号sn)查询(仅是单表查询,耗时就很久):
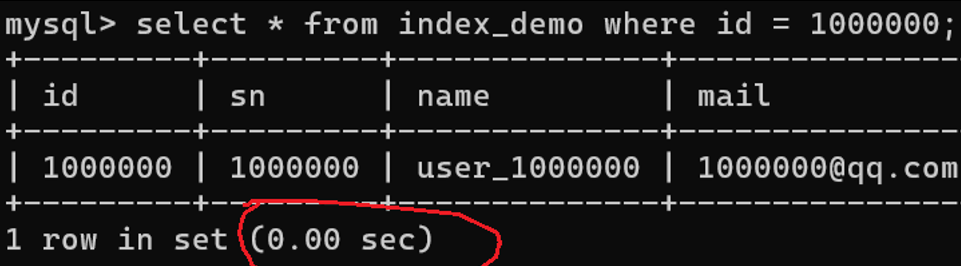
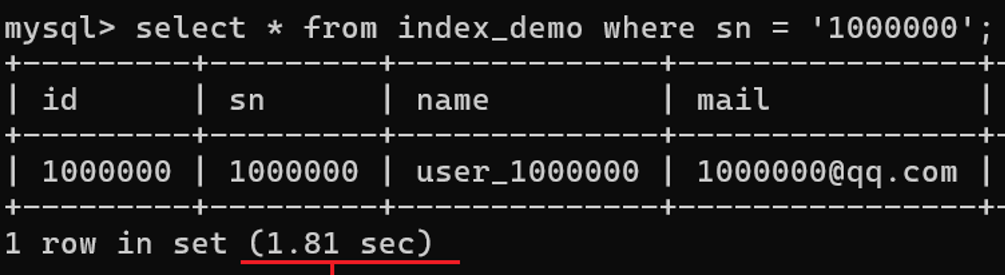
现在创建一个 sn 索引,可以看到数据量庞大创建索引也很慢:

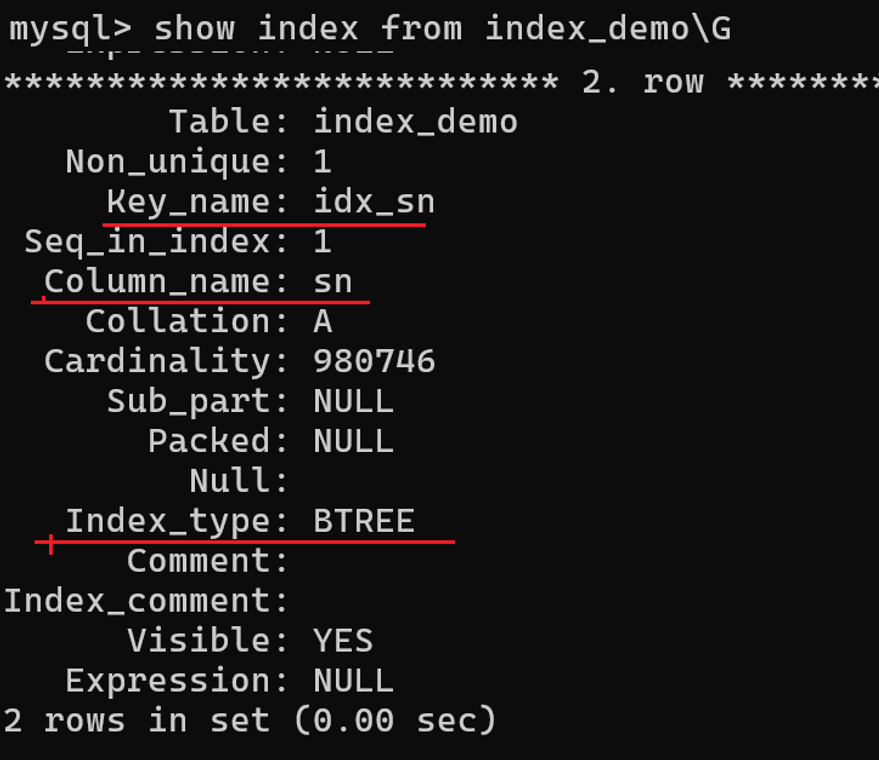
索引建议的命名规则(索引类型+索引列名):

查询该索引:
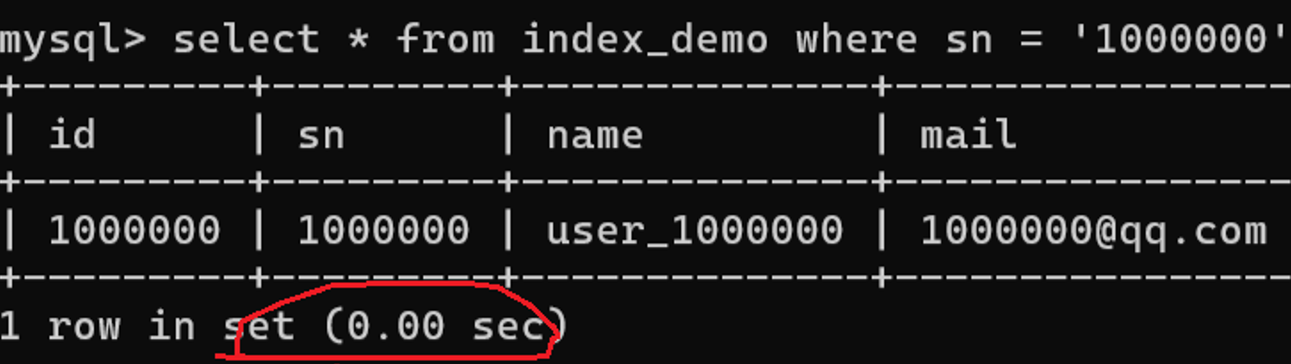
使用创建好的普通索引查询,效率明显提高:
如果是复合索引,索引列会有一个序列号,表示排序的优先级:
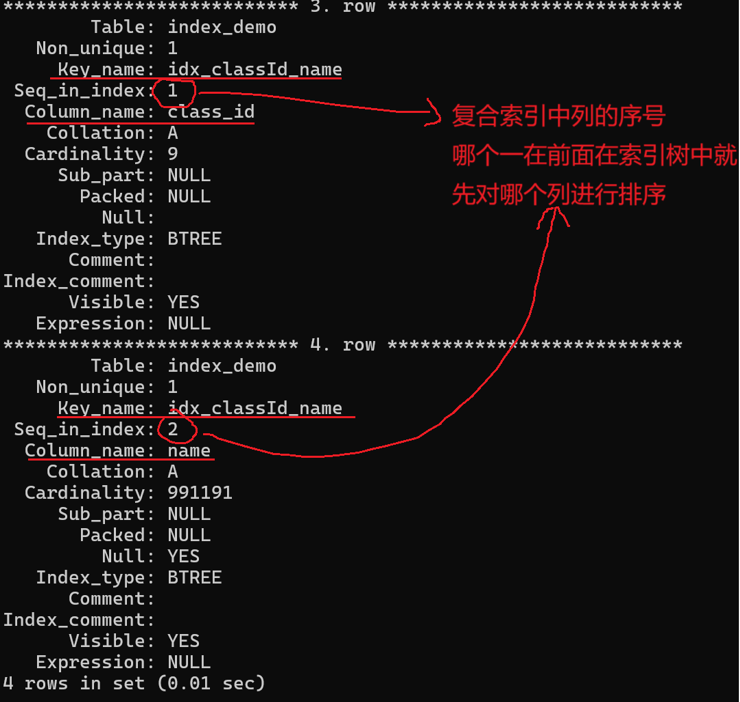
查询时,查询条件包含 [列1] / [列1,列2]... 时索引生效。复合索引遵守最左原则,不可跳过左边的列使用右边的列。
如直接使用列2查询,索引失效:
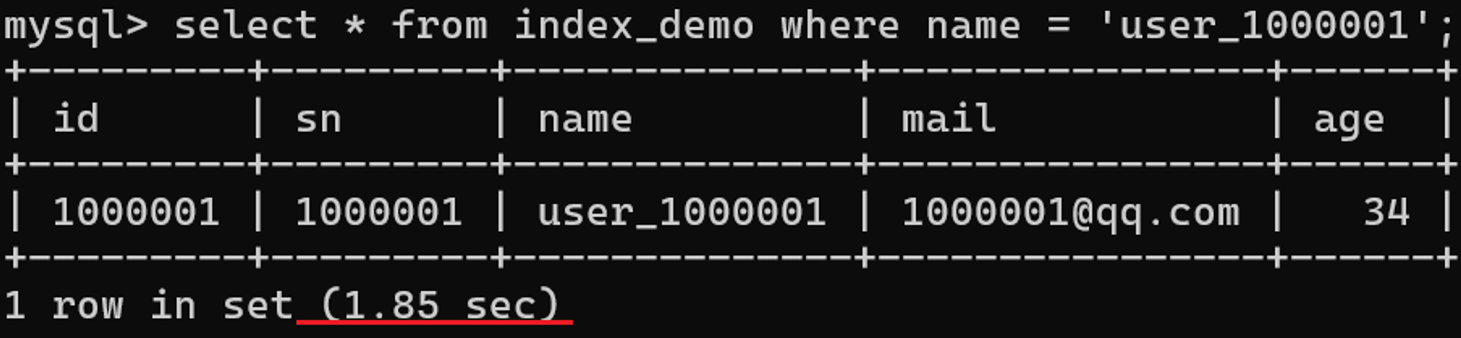
4.2、根据执行计划判断
从时间上判断不一定准确,更好的办法是使用执行计划。
语法:在 SQL 语句前加 explain。
使用普通索引:

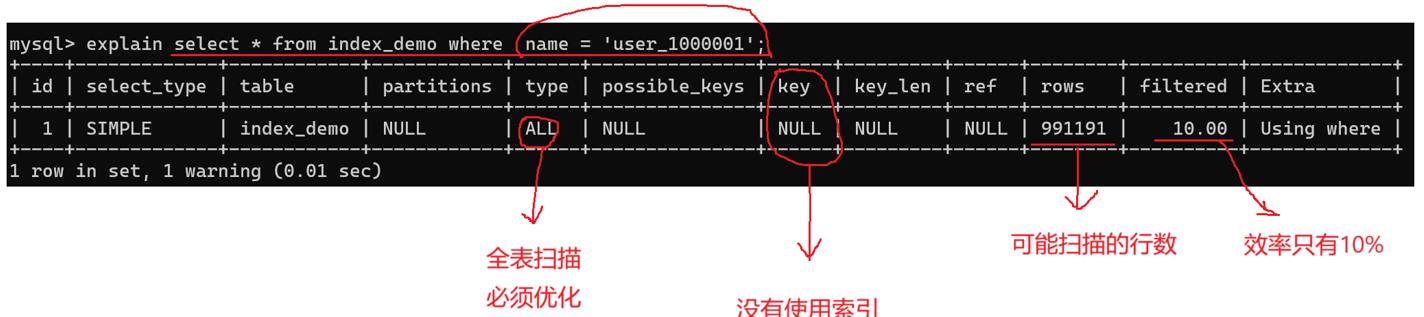
观察真实使用索引情况 key,判断是否使用索引。
type 类型:

不使用索引(Using where 表示可通过 where 获得查询列):
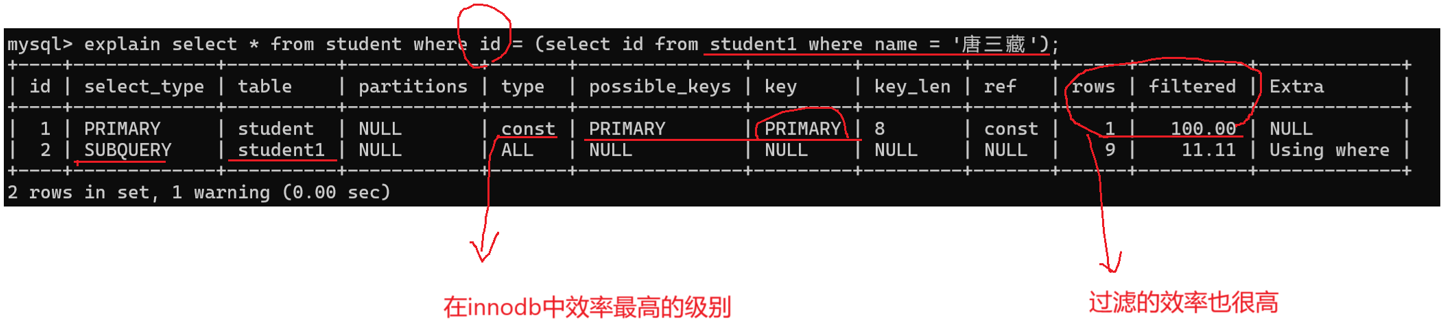
包含子查询,且外层语句使用主键查询(type 是 const 级别,效率高):
覆盖查询(Using index 表示通过索引树就能获得查询列):

回表查询(NULL,不能直接通过索引树获得查询列):
