scikit-learn在无监督学习算法的应用
哈喽,我是我不是小upper~
前几天,写了一篇对scikit-learn在监督学习算法的应用详解,今天来说说关于sklearn在无监督算法方面的案例。
稍微接触过机器学习的朋友就知道,无监督学习是在没有标签的数据上进行训练的。其主要目的可能包括聚类、降维、生成模型等。
以下是 6 个重要的无监督学习算法,这些算法都可以通过使用sklearn(Scikit-learn)库在Python中很好地处理:
-
K-Means 聚类
-
层次聚类
-
DBSCAN
-
主成分分析
-
独立成分分析
-
高斯混合模型
K-Means 聚类
在数据挖掘和机器学习领域,K-Means 聚类是一种广泛使用的无监督学习算法,主要用于将数据集中的样本划分为多个不同的组(即聚类),使得同一组内的数据点具有较高的相似性,而不同组之间的数据点差异较大。下面我们将详细介绍 K-Means 聚类的实现过程。
首先,我们需要导入必要的 Python 库并准备好用于分析的数据集。这里我们将使用 sklearn 库中自带的鸢尾花数据集(Iris dataset)进行演示。该数据集包含了 150 个样本,每个样本有 4 个特征,分别是花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)和花瓣宽度(petal width),这些特征可以帮助我们对鸢尾花的品种进行分类。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
from time import time# 加载鸢尾花数据集
iris = load_iris()
# 将数据转换为 DataFrame 格式,方便后续处理
data = pd.DataFrame(data= np.c_[iris['data'], iris['target']],columns= iris['feature_names'] + ['target'])
# 查看数据集的基本信息
print("数据基本信息:")
data.info()
# 查看数据集行数和列数
rows, columns = data.shape# 提取用于聚类的特征,这里选择花萼长度、花萼宽度和花瓣长度这三个特征
X = data.iloc[:, [0, 1, 2]].values # 0: sepal length, 1: sepal width, 2: petal length
接下来,我们需要对数据进行标准化处理。由于 K-Means 聚类是基于距离计算的算法,如果各个特征的量纲不同,可能会导致某些特征对聚类结果的影响过大。例如,一个特征的取值范围在 0 到 1 之间,而另一个特征的取值范围在 0 到 1000 之间,那么后者在计算距离时的影响会远大于前者。为了避免这种情况,我们使用 StandardScaler 对数据进行标准化处理,将每个特征转换为均值为 0,标准差为 1 的标准正态分布。
# 数据标准化
scaler = StandardScaler()
scaled_data = scaler.fit_transform(X)在进行 K-Means 聚类之前,我们需要确定一个合适的聚类数量 K。这里我们使用轮廓系数(Silhouette Score)来帮助我们选择最优的 K 值。轮廓系数是衡量聚类质量的一个指标,它的取值范围在 -1 到 1 之间。对于每个样本,轮廓系数计算其与同一聚类内其他样本的平均距离(a)和与最近的另一个聚类中样本的平均距离(b),然后用公式:
计算得到。
一个高的轮廓系数表示样本点离自己所属的聚类较近,而离其他聚类较远,说明聚类效果较好。
# 确定最优的 K 值
k_values = range(2, 11) # 尝试 K 从 2 到 10
silhouette_scores = []# 计算不同 K 值下的轮廓系数
for k in k_values:kmeans = KMeans(n_clusters=k, random_state=42)cluster_labels = kmeans.fit_predict(scaled_data)silhouette_avg = silhouette_score(scaled_data, cluster_labels)silhouette_scores.append(silhouette_avg)print(f"For k={k}, the average silhouette_score is : {silhouette_avg}")# 绘制轮廓系数图
plt.plot(k_values, silhouette_scores, marker='o')
plt.title('Silhouette Score for Different k')
plt.xlabel('Number of clusters (k)')
plt.ylabel('Silhouette Score')
plt.grid(True)
plt.show()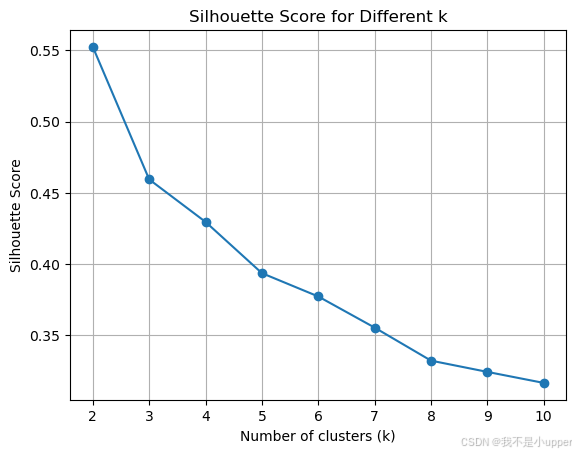
通过观察轮廓系数图,我们可以选择轮廓系数最高的 K 值作为最优的聚类数量。在这个例子中,我们假设选择 K=3 进行模型训练。
# 模型训练与聚类
k = 3 # 根据轮廓系数图选择合适的 K 值
kmeans = KMeans(n_clusters=k, random_state=42)
clusters = kmeans.fit_predict(scaled_data)# 可视化聚类结果(这里仅展示前两个特征的二维投影)
plt.figure(figsize=(10, 7))# 绘制每个聚类的散点图
for i in range(k):plt.scatter(scaled_data[clusters == i, 0], scaled_data[clusters == i, 1], s=50, label=f'Cluster {i+1}')# 绘制聚类中心
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=300, c='red', marker='*', label='Centroids')plt.title('K-Means Clustering Results')
plt.xlabel('Sepal Length (scaled)')
plt.ylabel('Sepal Width (scaled)')
plt.legend()
plt.grid(True)
plt.show()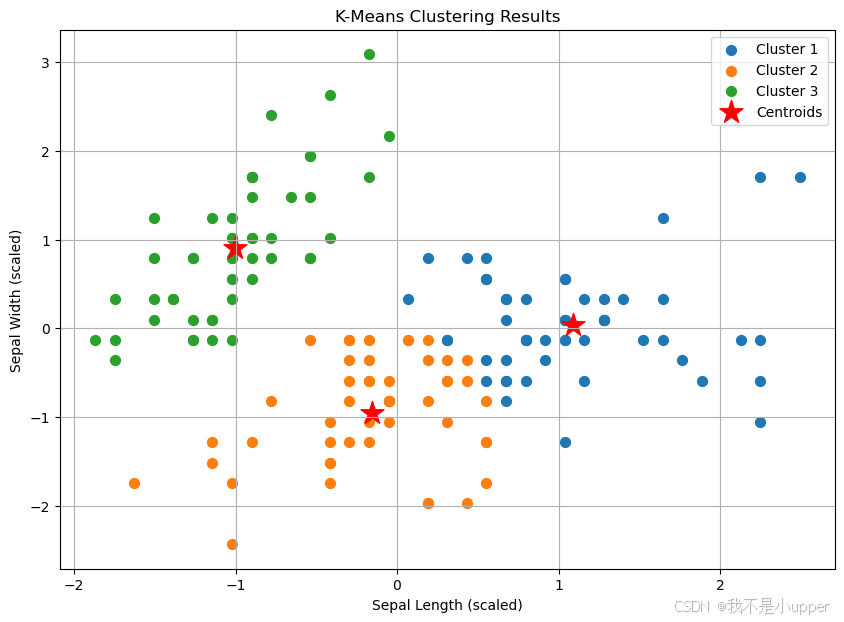
在得到聚类结果后,我们可以对各个聚类进行分析和解读。例如,在这个鸢尾花数据集的聚类结果中,我们可以根据每个聚类的中心点位置以及样本分布情况,推测出每个聚类可能代表的鸢尾花品种特征。
需要注意的是,在实际项目中,选择合适的 K 值不仅仅依赖于轮廓系数等数学指标,还需要结合业务背景和领域知识。同时,聚类结果的解读也需要深入理解数据的含义和业务目标,以便为决策提供有价值的信息。
此外,K-Means 算法虽然简单高效,但也存在一些局限性,例如对初始聚类中心的选择敏感,可能会陷入局部最优解;对异常值比较敏感;无法很好地处理非球形分布的数据等。在实际应用中,可以考虑使用一些改进的 K-Means 算法,如 K-Means++(改进初始中心的选择方法),或者尝试其他聚类算法,如 DBSCAN、高斯混合模型等,以获得更好的聚类效果。
层次聚类
在数据分析领域,层次聚类(Hierarchical Clustering)是一种通过构建数据点之间的层次结构来揭示数据内在群集结构的无监督学习方法。它不需要预先指定聚类数量,而是根据数据点之间的相似性或距离,自底向上(凝聚型)或自顶向下(分裂型)地逐步合并或拆分聚类,最终形成树状结构的聚类谱系图( dendrogram )。以下将使用 sklearn 库中自带的鸢尾花数据集( Iris dataset ),详细介绍层次聚类的实现过程。
数据准备与标准化
我们继续使用鸢尾花数据集,该数据集包含花萼长度、花萼宽度、花瓣长度和花瓣宽度 4 个特征。为了便于展示,这里选取前 3 个特征(花萼长度、花萼宽度、花瓣长度)进行分析:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import load_iris# 加载鸢尾花数据集
iris = load_iris()
data = pd.DataFrame(data=iris.data, columns=iris.feature_names[:4]) # 选取前4个特征由于层次聚类基于距离计算(如欧几里得距离),为避免不同特征量纲对结果的影响,需对数据进行标准化处理:
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)构建层次聚类模型与树状图
层次聚类通过 链接方法(Linkage Methods) 定义聚类间的距离,常见方法包括:
- Ward 法:最小化合并后聚类内的方差,适用于正态分布数据。
- 单链接(Single Linkage):以两个聚类中距离最近的点作为聚类间距离,易形成链式结构。
- 全链接(Complete Linkage):以两个聚类中距离最远的点作为聚类间距离,倾向于形成紧凑聚类。
此处使用 Ward 法 构建层次聚类模型,并通过 dendrogram 函数绘制树状图:
# 使用 Ward 链接方法计算层次聚类
linked = linkage(scaled_data, method='ward', metric='euclidean') # metric 指定距离度量方式# 绘制树状图
plt.figure(figsize=(10, 7))
dendrogram(linked,orientation='top', # 树状图方向(从上到下)distance_sort='descending', # 按距离降序排列节点show_leaf_counts=True, # 显示叶子节点(数据点)数量leaf_rotation=90, # 旋转叶子节点标签防止重叠labels=data.index # 为叶子节点添加样本索引标签(可选)
)
plt.title('Hierarchical Clustering Dendrogram (Ward Method)')
plt.xlabel('Data Points')
plt.ylabel('Distance')
plt.show()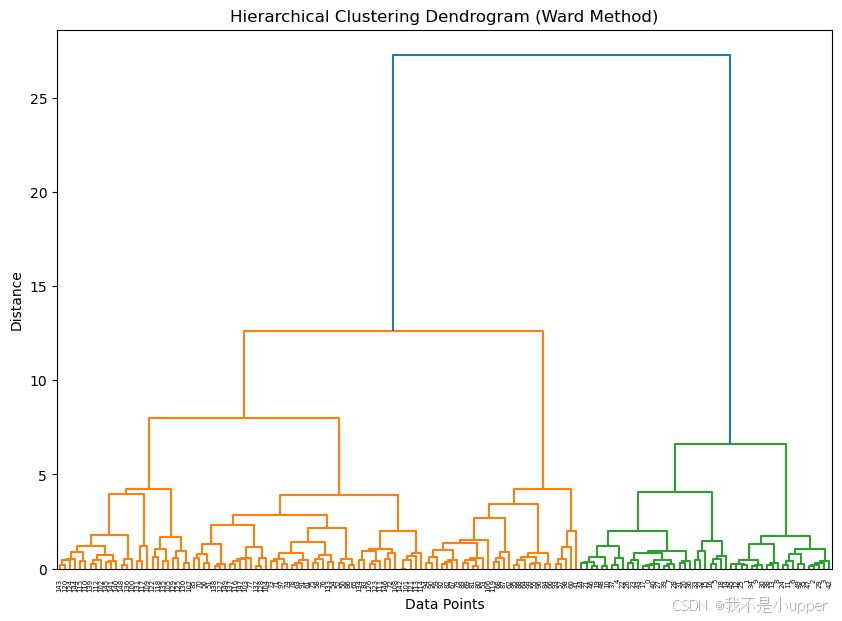
树状图解读:
- 横轴表示数据点(或聚类),纵轴表示聚类间的距离。
- 每个数据点初始为独立聚类,随着距离阈值降低,相邻聚类逐步合并。
- 树状图中的垂直线高度表示聚类合并时的距离,可通过观察 “肘部”(距离突然增大的位置)判断合适的聚类数量。
模型训练与结果可视化
根据树状图中聚类合并的趋势,选择合适的聚类数量(如 \(k=3\) ),使用 AgglomerativeClustering 类进行聚类:
# 定义层次聚类模型(凝聚型,自底向上合并)
cluster = AgglomerativeClustering(n_clusters=3, # 指定聚类数量linkage='ward', # 链接方法(Ward 法)metric='euclidean' # 距离度量方式(欧几里得距离)
)# 训练模型并获取聚类标签
cluster_labels = cluster.fit_predict(scaled_data)# 可视化聚类结果(仅展示前两个特征:花萼长度 vs. 花萼宽度)
plt.figure(figsize=(10, 7))
plt.scatter(scaled_data[:, 0], # 花萼长度(标准化后)scaled_data[:, 1], # 花萼宽度(标准化后)c=cluster_labels, # 颜色区分聚类cmap='rainbow',edgecolor='k',s=60
)
plt.title('Hierarchical Clustering Results (k=3)')
plt.xlabel('Sepal Length (Scaled)')
plt.ylabel('Sepal Width (Scaled)')
plt.legend(title='Cluster Labels')
plt.grid(True)
plt.show()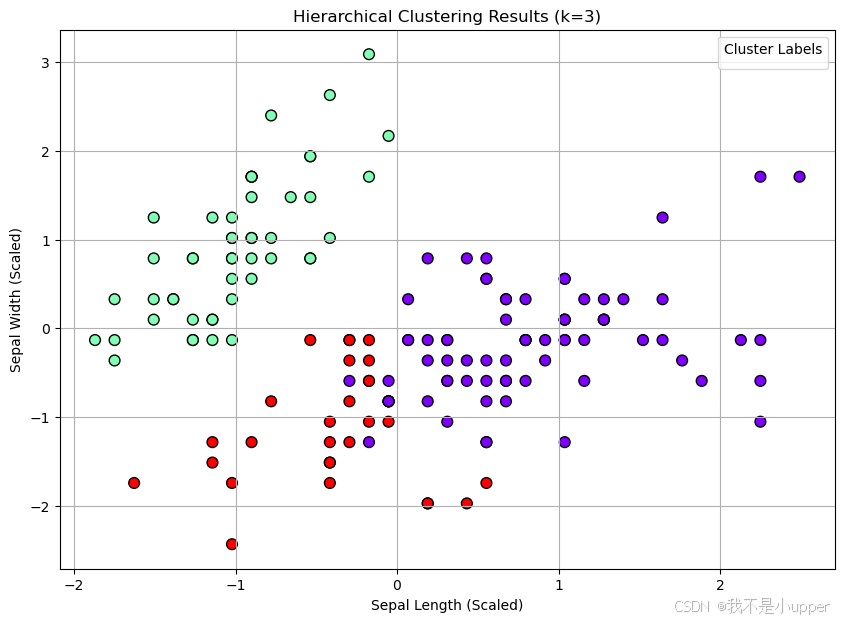
关键参数与注意事项
-
距离度量(Affinity):
affinity参数指定距离计算方式,常见选项包括:euclidean:欧几里得距离(默认),适用于连续型数据。manhattan:曼哈顿距离,对异常值鲁棒性更强。cosine:余弦相似度,适用于文本或高维数据。
-
链接方法(Linkage):
linkage参数决定聚类间距离的计算方式,除ward外,还可选择single(单链接)、complete(全链接)等,不同方法会影响聚类形状和紧凑性。
-
聚类数量选择:
- 树状图中 “肘部” 对应的距离阈值可作为聚类数量的参考(如某高度处合并距离显著增大,说明此时分割的聚类间差异较大)。
- 也可结合业务需求或轮廓系数(Silhouette Score)等指标辅助决策。
与 K-Means 聚类的对比
- 层次聚类:无需预设聚类数量,适合探索性分析,结果以树状图呈现,可直观展示数据层次结构,但计算复杂度较高(尤其对大规模数据)。
- K-Means:需预设聚类数量,计算效率高,适用于大规模数据,但对初始中心敏感,可能陷入局部最优。
在实际应用中,可结合两种方法:先用层次聚类探索数据结构、确定合理聚类数量,再用 K-Means 对大规模数据进行高效聚类。通过以上步骤,层次聚类能够帮助我们从数据中挖掘出隐含的层次化群集结构,可以为后续的数据分析和业务决策提供有力支持。
DBSCAN
在无监督学习领域,DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,能够有效识别数据集中的密集区域(聚类)和低密度区域(噪声点)。与 K-Means、层次聚类等算法不同,DBSCAN 无需预先指定聚类数量,且能够发现任意形状的聚类,尤其适合处理非球形分布的数据。以下将使用 sklearn 库中自带的鸢尾花数据集(Iris dataset),详细演示 DBSCAN 算法的实现流程。
数据准备与标准化
我们继续使用鸢尾花数据集,选取前两个特征(花萼长度、花萼宽度)进行分析,以便于二维可视化:
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import DBSCAN
from sklearn.metrics import silhouette_score
from sklearn.datasets import load_iris# 加载鸢尾花数据集
iris = load_iris()
data = pd.DataFrame(iris.data, columns=iris.feature_names[:4]) # 选取前4个特征:花萼长度、花萼宽度由于 DBSCAN 基于距离计算(默认使用欧几里得距离),为确保特征权重一致,需对数据进行标准化处理:
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)DBSCAN 模型构建与训练
DBSCAN 算法有两个核心参数:
eps(邻域半径):定义样本点的邻域范围,即某样本点的邻域是以该点为中心、半径为eps的区域。min_samples(最小样本数):定义一个核心点的条件,即邻域内至少包含min_samples个样本点(包括自身)。
算法逻辑:
- 核心点:若某样本点的邻域内包含至少
min_samples个样本,则该点为核心点。 - 密度直达:若样本点
B在核心点A的邻域内,则称B从A密度直达。 - 密度可达:若存在一系列核心点
A→C→B,使得C从A密度直达,B从C密度直达,则称B从A密度可达。 - 密度相连:若存在核心点
O,使得样本点A和B均从O密度可达,则称A和B密度相连。 - 聚类:由密度相连的样本点构成的最大集合称为一个聚类。
- 噪声点:不属于任何聚类的样本点(即无法从任何核心点密度可达的点)。
模型实现:
# 实例化DBSCAN模型(需调参确定合适的eps和min_samples)
dbscan = DBSCAN(eps=0.8, min_samples=5) # 示例参数,实际需调整# 训练模型并获取聚类标签(标签-1表示噪声点)
clusters = dbscan.fit_predict(scaled_data)# 计算轮廓系数(排除噪声点对评分的影响)
# 提取有效聚类标签(非-1的样本)
valid_labels = clusters != -1
if np.any(valid_labels):silhouette_avg = silhouette_score(scaled_data[valid_labels], clusters[valid_labels])print(f'Silhouette Score (excluding noise): {silhouette_avg:.2f}')
else:print('No valid clusters found.')结果可视化与分析
使用散点图可视化聚类结果,不同颜色代表不同聚类,黑色点表示噪声点:
# 可视化聚类结果
plt.figure(figsize=(10, 7))# 绘制聚类点
for cluster_label in np.unique(clusters):if cluster_label == -1:# 噪声点用黑色表示plt.scatter(scaled_data[clusters == cluster_label, 0], scaled_data[clusters == cluster_label, 1],c='black', label='Noise', s=60)else:# 聚类点用彩色表示plt.scatter(scaled_data[clusters == cluster_label, 0], scaled_data[clusters == cluster_label, 1],c=plt.cm.plasma(cluster_label / np.max(clusters)), label=f'Cluster {cluster_label}', s=60, edgecolor='k')plt.title('DBSCAN Clustering Results')
plt.xlabel('Sepal Length (Scaled)')
plt.ylabel('Sepal Width (Scaled)')
plt.legend()
plt.grid(True)
plt.show()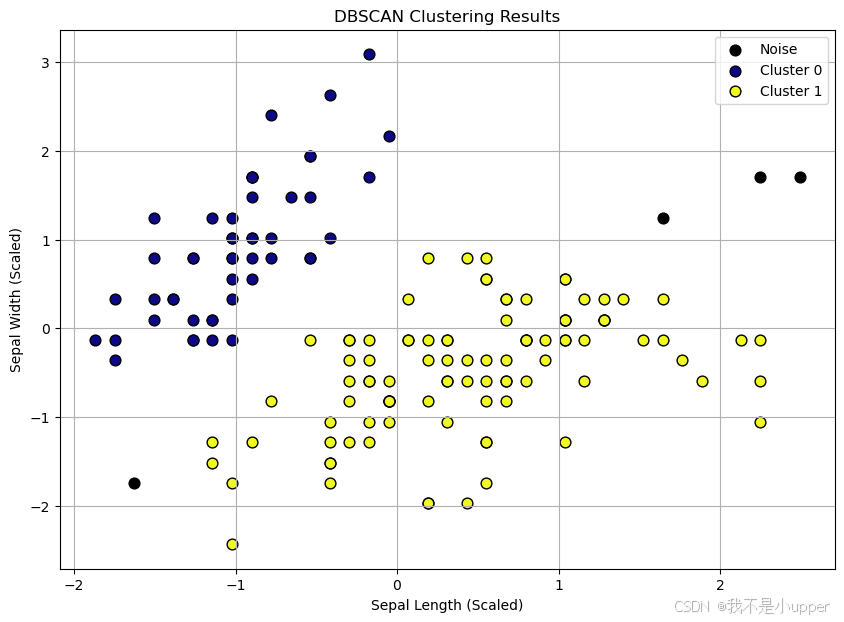
结果解读:
- 轮廓系数:取值范围为 [-1, 1],值越接近 1 表示聚类内样本越紧凑、聚类间分离度越好;值为负数表示样本可能被错误分类。由于 DBSCAN 允许噪声点存在,计算轮廓系数时需排除标签为 - 1 的样本,以避免噪声对评分的干扰。
- 聚类形状:DBSCAN 能识别非球形聚类(如带状、环形等),而 K-Means 等基于距离中心的算法难以处理此类结构。
- 噪声点:图中黑色点为 DBSCAN 识别出的噪声点,这些点通常位于低密度区域,不属于任何聚类。
关键参数调参与注意事项
-
参数选择方法:
- k - 距离图(k-Distance Graph):对于每个样本点,计算其到第
k近邻的距离(k通常取min_samples),绘制距离排序图。选择曲线中 “肘部”(距离突然增大的点)对应的距离作为eps的参考值。 - 网格搜索:通过交叉验证尝试不同的
eps和min_samples组合,结合轮廓系数或业务需求选择最优参数。
- k - 距离图(k-Distance Graph):对于每个样本点,计算其到第
-
标准化的必要性:
- DBSCAN 对特征量纲敏感,例如未标准化时,数值范围大的特征会主导距离计算。因此,标准化是 DBSCAN 预处理的必要步骤。
-
处理密度不均数据:
- 若数据中存在密度差异较大的区域,DBSCAN 可能无法同时识别所有聚类(低密度区域的聚类可能被误判为噪声)。此时可尝试:
- 调整参数
eps和min_samples(如对低密度区域降低min_samples)。 - 使用基于密度可达的改进算法(如 HDBSCAN)。
- 调整参数
- 若数据中存在密度差异较大的区域,DBSCAN 可能无法同时识别所有聚类(低密度区域的聚类可能被误判为噪声)。此时可尝试:
-
噪声点的处理:
- 噪声点的标签为 - 1,在业务分析中需结合领域知识判断其是否为真实噪声(如异常数据)或因参数设置不当导致的误判。
DBSCAN 的优缺点
- 优点:
- 无需预设聚类数量,自动识别噪声点。
- 适用于发现任意形状的聚类,对非球形数据效果优于 K-Means。
- 缺点:
- 对参数
eps和min_samples敏感,需反复调参。 - 对高维数据性能下降(距离度量在高维空间中意义减弱)。
- 密度均匀性要求较高,难以处理密度差异大的数据集。
- 对参数
通过以上步骤,DBSCAN 能够有效挖掘数据中基于密度的聚类结构,为复杂数据分布的分析提供了灵活的解决方案。在实际应用中,建议结合数据探索和多次参数调整,以充分发挥算法的优势。
主成分分析
主成分分析(Principal Component Analysis,PCA)是一种广泛应用于高维数据降维和可视化的无监督学习技术。其核心思想是通过线性变换将原始高维数据投影到一组正交的低维主轴(即主成分)上,使得投影后的数据尽可能保留原始数据的方差(信息),从而在减少维度的同时避免关键信息的丢失。以下将结合 sklearn 库中自带的鸢尾花数据集(Iris dataset),详细介绍 PCA 的实现过程。
数据准备与标准化
我们使用经典的鸢尾花数据集,该数据集包含 150 个样本,每个样本有 4 个特征:花萼长度(Sepal Length)、花萼宽度(Sepal Width)、花瓣长度(Petal Length)和花瓣宽度(Petal Width)。我们的目标是将这 4 维数据降维到 2 维,以便于可视化和分析。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征矩阵,形状为 (150, 4)
y = iris.target # 类别标签,形状为 (150,)
feature_names = iris.feature_names # 特征名称列表由于 PCA 对数据的尺度敏感(例如,数值范围较大的特征可能主导方差计算),因此需要先对数据进行标准化处理,使每个特征的均值为 0,标准差为 1:
# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)模型训练与主成分提取
使用 PCA 类对标准化后的数据进行降维。n_components=2 表示我们希望将数据投影到前两个主成分上,这两个主成分将构成新的 2 维特征空间:
# 初始化 PCA 模型,指定保留 2 个主成分
pca = PCA(n_components=2)
# 拟合模型并转换数据
X_pca = pca.fit_transform(X_scaled)关键原理:
- 主成分是原始特征的线性组合,彼此正交(即不相关)。
- 第一个主成分(PC1)捕获原始数据中最大的方差,第二个主成分(PC2)捕获剩余方差中最大的部分,以此类推。
- 降维后的维度 k 通常由 “累计解释方差比例” 决定,例如保留累计方差贡献率达 95% 的主成分。
数据可视化
将降维后的数据在 2 维空间中可视化,观察不同类别样本在主成分上的分布情况:
plt.figure(figsize=(8, 6))# 遍历不同类别,用不同颜色绘制散点图
for target in np.unique(y):mask = y == targetplt.scatter(X_pca[mask, 0], # 第一主成分X_pca[mask, 1], # 第二主成分label=iris.target_names[target],s=80,edgecolor='k')# 添加图例、坐标轴标签和标题
plt.legend(loc='upper right', fontsize='large')
plt.xlabel(f'Principal Component 1 (Variance Explained: {pca.explained_variance_ratio_[0]:.3f})')
plt.ylabel(f'Principal Component 2 (Variance Explained: {pca.explained_variance_ratio_[1]:.3f})')
plt.title('2D Projection of Iris Dataset via PCA')
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()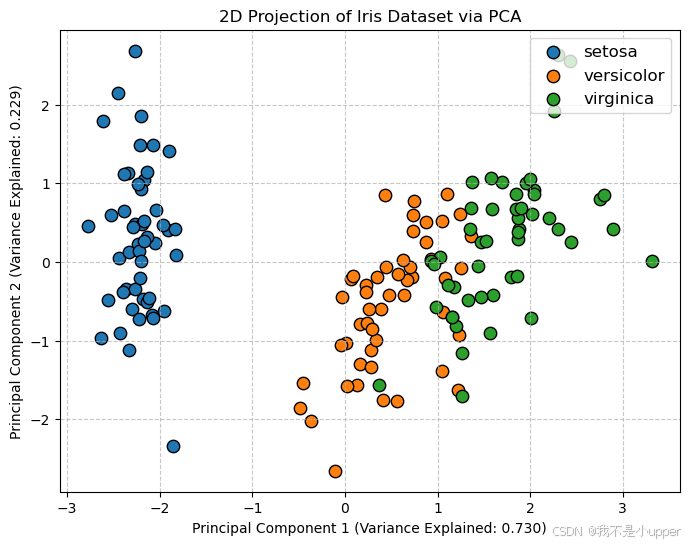
可视化解读:
- 第一主成分(PC1)和第二主成分(PC2)分别对应新的坐标轴,样本点在该空间中的位置反映了其在原始特征上的综合表现。
- 不同颜色的点代表鸢尾花的不同类别(山鸢尾、变色鸢尾、维吉尼亚鸢尾)。从图中可以看到,前两个主成分能够较好地将山鸢尾与其他两类区分开,但变色鸢尾和维吉尼亚鸢尾仍有部分重叠,说明这两类在原始特征上的差异可能需要更多主成分来区分。
解释方差分析
通过 explained_variance_ratio_ 属性可以查看每个主成分解释的方差比例,即该主成分捕获的原始数据方差占总方差的比例:
explained_variance = pca.explained_variance_ratio_
print(f"各主成分解释的方差比例: {np.round(explained_variance, 3)}")
print(f"累计解释方差比例: {np.round(np.sum(explained_variance), 3)}")
- 上述结果表明,第一主成分解释了原始数据 72.7% 的方差,第二主成分解释了 23% 的方差,两者累计保留了约 95.7% 的方差。这说明降维到 2 维后,数据的主要信息已被保留,适合用于可视化和后续分析。
关键注意事项
- 标准化的必要性:若原始特征量纲不同(如收入以 “元” 为单位,年龄以 “岁” 为单位),必须进行标准化,否则 PCA 结果会偏向数值范围大的特征。
- 主成分数量选择:
- 直接指定目标维度(如
n_components=2)。 - 通过累计方差贡献率确定(如
n_components=0.95表示保留累计方差达 95% 的主成分)。
- 直接指定目标维度(如
- 主成分的可解释性:主成分是原始特征的线性组合,可通过
pca.components_查看每个主成分中各原始特征的权重,从而分析其物理意义(例如,PC1 可能主要由花瓣长度和花瓣宽度主导)。
PCA 的应用场景
- 数据可视化:将高维数据降维到 2 维或 3 维,便于通过散点图、三维图观察数据分布。
- 去除噪声:过滤掉解释方差较低的主成分,保留主要信息,减少冗余。
- 机器学习预处理:降低数据维度,加速模型训练(如支持向量机、神经网络),避免 “维数灾难”。
通过以上步骤,PCA 能够高效地将高维数据映射到低维空间,在保留关键信息的同时简化数据结构,是数据分析和机器学习中不可或缺的工具。
独立成分分析
独立成分分析(Independent Component Analysis,ICA)是一种用于从混合信号中提取独立原始信号的无监督学习技术,其核心目标是在仅观测到混合信号的情况下,实现 “盲源分离”(Blind Source Separation),即恢复出相互独立的原始信号。以下将通过生成虚拟混合信号的示例,结合 Python 代码详细介绍 ICA 的原理与实现过程。
数据准备:生成混合信号
假设我们有两个相互独立的原始信号,通过一个未知的混合矩阵线性组合成观测到的混合信号。我们的任务是仅利用混合信号数据,通过 ICA 算法恢复出原始信号。
import numpy as np
from sklearn.decomposition import FastICA
import matplotlib.pyplot as plt# 生成两个独立的原始信号
np.random.seed(42) # 固定随机种子确保可复现性
n_samples = 1000 # 样本点数# 信号 1:服从均匀分布的随机噪声(非高斯分布)
signal_1 = np.random.rand(n_samples)
# 信号 2:正弦波信号(周期性信号,与信号 1 独立)
signal_2 = np.sin(np.linspace(0, 10 * np.pi, n_samples)) # 构建混合矩阵(未知的线性混合系数)
mixing_matrix = np.array([[2, 1], [1, 2]]) # 2x2 矩阵,每行对应一个混合信号的线性组合系数# 生成混合信号(每行是一个混合信号,每列是一个样本点)
original_signals = np.vstack((signal_1, signal_2)) # 原始信号矩阵,形状为 (2, 1000)
mixed_signals = np.dot(mixing_matrix, original_signals).T # 混合信号矩阵,形状为 (1000, 2)关键说明:
- 独立性假设:ICA 要求原始信号之间相互独立(如随机噪声与正弦波),这是算法能够分离信号的前提。
- 混合过程:混合信号是原始信号的线性组合,数学上可表示为:
- \(\mathbf{X} = \mathbf{A} \mathbf{S}\),其中 \(\mathbf{X}\) 是混合信号矩阵,\(\mathbf{A}\) 是混合矩阵,\(\mathbf{S}\) 是原始信号矩阵。
ICA 模型训练与信号分离
使用 sklearn 中的 FastICA 算法(基于快速定点法的 ICA 实现)来拟合混合信号数据,恢复原始信号:
# 初始化 ICA 模型,指定恢复的独立成分数量(等于原始信号数量)
ica = FastICA(n_components=2, random_state=42) # n_components 需与原始信号数一致# 训练模型并分离信号
recovered_signals = ica.fit_transform(mixed_signals) # 输出形状为 (1000, 2)- 通常选择使 AIC/BIC 最小的成分数量。
-
协方差类型:
covariance_type参数控制成分协方差矩阵的约束:'full':每个成分有独立的协方差矩阵(最灵活)。'tied':所有成分共享相同的协方差矩阵。'diag':每个成分有对角协方差矩阵(方差独立)。'spherical':每个成分有单一方差参数。
-
初始化与稳定性:
- GMM 对初始值敏感,可通过
n_init参数设置多次初始化并选择最优结果。 - 对于高维数据,可先使用 PCA 降维以提高稳定性。
- GMM 对初始值敏感,可通过
GMM 的应用场景
- 聚类:通过成分标签将数据点分配到不同簇(soft clustering)。
- 异常检测:低概率区域的样本可被视为异常。
- 密度估计:对复杂分布进行建模,用于生成新样本。
通过以上步骤,GMM 能够有效捕捉数据中的多峰分布特性,是数据建模和分析的强大工具。
最后
今天演示了关于scikit-learn在无监督学习方面的使用。后续会出scikit-learn在其他方面的使用,大家可以关注起来!